
Maison >Java >javaDidacticiel >Comment implémenter le cache multi-niveaux Redis basé sur Java
Comment implémenter le cache multi-niveaux Redis basé sur Java

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-13 19:52:171253parcourir
1. Mise en cache à plusieurs niveaux
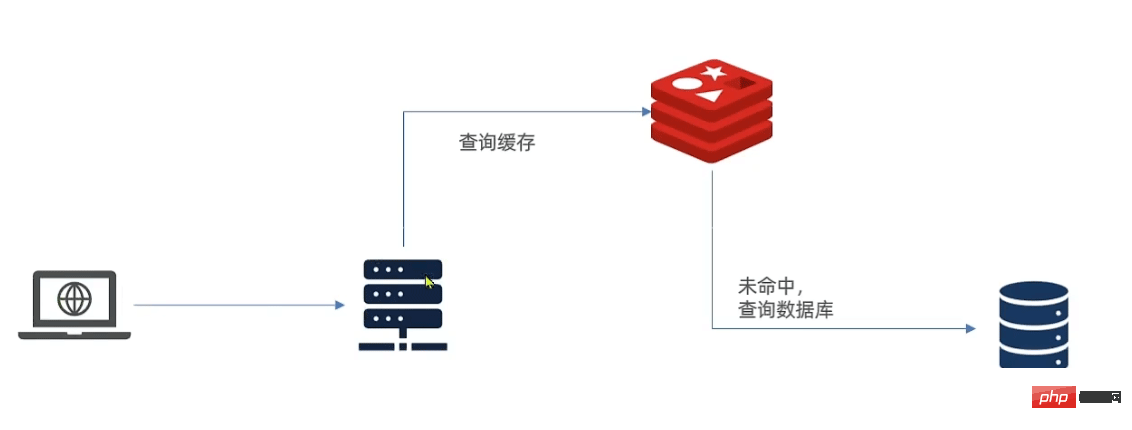
1. Schéma de mise en cache traditionnel
Une fois que la requête atteint Tomcat, elle va d'abord à Redis pour obtenir le cache. Si elle échoue, elle va à MySQL pour l'obtenir
2. Schéma de mise en cache à plusieurs niveaux
tomcatLe nombre de requêtes simultanées est beaucoup plus petit que celui de Redis, donc Tomcat deviendra un goulot d'étranglementUtilisez chaque lien de traitement des requêtes pour ajouter du cache respectivement afin de réduire la pression sur Tomcat et améliorer les performances du service
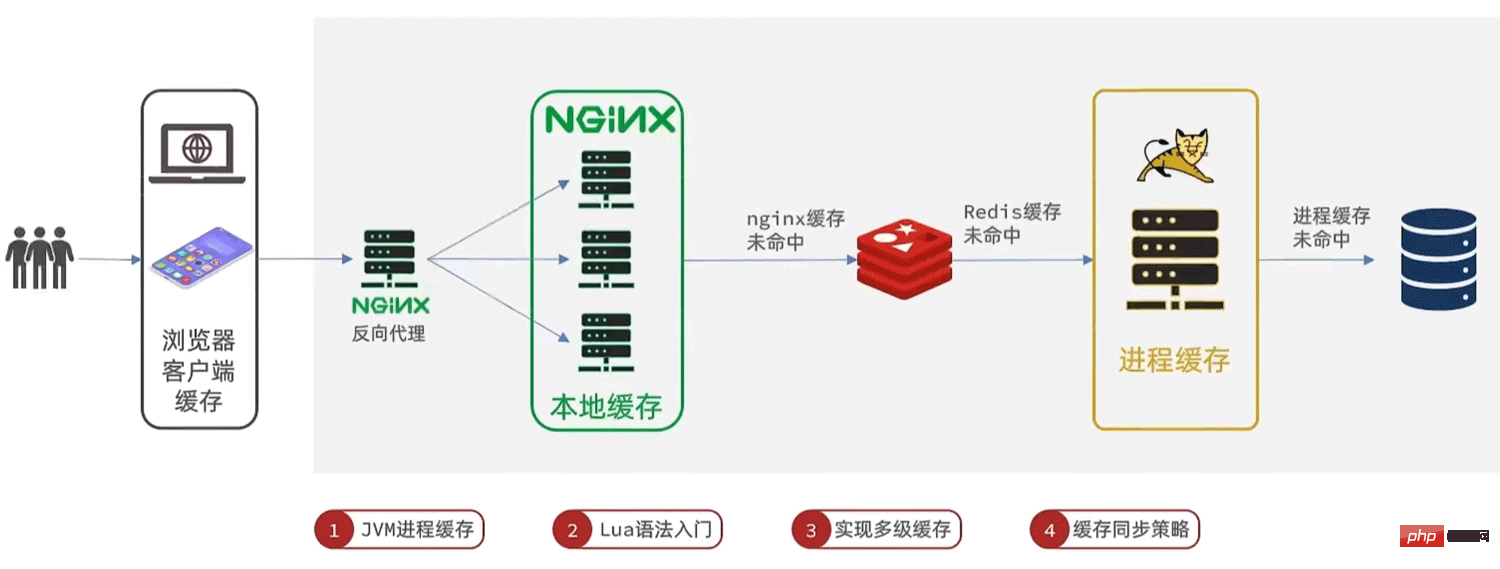
2. Cache local JVM
Le cache est stocké dans la mémoire et la vitesse de lecture des données est rapide, ce qui peut réduire considérablement l'accès à la base de données et réduire la pression sur la base de données
Cache distribué, tel que redis
- Avantages : Grande capacité de stockage, bonne fiabilité, peut être utilisé en partage dans le cluster
- Inconvénients : Il y a une surcharge réseau pour accéder au cache
- Scénario : Grande quantité de données mises en cache, élevée fiabilité, données qui doivent être partagées dans le cluster
Traitement du cache local, tel que HashMap, GuavaCache
- Avantages : Lecture de la mémoire locale, pas de surcharge réseau, plus rapide
- Inconvénients : capacité de stockage limitée, faible fiabilité (comme perdu après redémarrage), ne peut pas être partagé dans le cluster
- Scénario : exigences de performances élevées, petite quantité de données en cache
1 Cas pratique
Caffeine est une bibliothèque de cache local hautes performances développée sur base java8 qui fournit. taux de réussite presque optimal
Ceci est actuellement utilisé pour le cache interne du printemps
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.0.5</version>
</dependency>package com.erick.cache;
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.time.Duration;
public final class CacheUtil {
private static int expireSeconds = 2;
public static Cache<String, String> cacheWithExpireSeconds;
private static int maxPairs = 1;
public static Cache<String, String> cacheWithMaxPairs;
static {
/*过期策略,写完60s后过期*/
cacheWithExpireSeconds = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(expireSeconds))
.build();
/*过期策略,达到最大值后删除
* 1. 并不会立即删除,等一会儿才会删除
* 2. 会将之前存储的数据删除掉*/
cacheWithMaxPairs = Caffeine.newBuilder()
.maximumSize(maxPairs)
.build();
}
/*从缓存中获取数据
* 1. 如果缓存中有,则直接从缓存中返回
* 2. 如果缓存中没有,则去数据查询并返回结果*/
public static String getKeyWithExpire(String key) {
return cacheWithExpireSeconds.get(key, value -> {
return getResultFromDB();
});
}
public static String getKeyWithMaxPair(String key) {
return cacheWithMaxPairs.get(key, value -> {
return getResultFromDB();
});
}
private static String getResultFromDB() {
System.out.println("数据库查询");
return "db result";
}
}package com.erick.cache;
import java.util.concurrent.TimeUnit;
public class Test {
@org.junit.Test
public void test01() throws InterruptedException {
CacheUtil.cacheWithExpireSeconds.put("name", "erick");
System.out.println(CacheUtil.getKeyWithExpire("name"));
TimeUnit.SECONDS.sleep(3);
System.out.println(CacheUtil.getKeyWithExpire("name"));
}
@org.junit.Test
public void test02() throws InterruptedException {
CacheUtil.cacheWithMaxPairs.put("name", "erick");
CacheUtil.cacheWithMaxPairs.put("age", "12");
System.out.println(CacheUtil.getKeyWithMaxPair("name"));
System.out.println(CacheUtil.getKeyWithMaxPair("age"));
TimeUnit.SECONDS.sleep(2);
System.out.println(CacheUtil.getKeyWithMaxPair("name")); // 查询不到了
System.out.println(CacheUtil.getKeyWithMaxPair("age"));
}
}3. Propriétés de cohérence du cache
1.1.1 Définir la période de validité
- Définir la période de validité de. le cache et le supprime automatiquement après expiration. Il peut être mis à jour lors d'une nouvelle requête
- Avantages : Simple et pratique
- Inconvénients : Mauvaise rapidité, le cache peut être incohérent avant son expiration
- Scénario : Entreprise avec une faible fréquence de mise à jour et de faibles exigences de rapidité
- Modifier directement le cache en modifiant la base de données
- Avantages : intrusion de code, forte cohérence entre cache et base de données
- Inconvénients : saisie de code, couplage élevé
- Scénario : Mettre en cache des données avec des exigences élevées de cohérence et d'invalidité
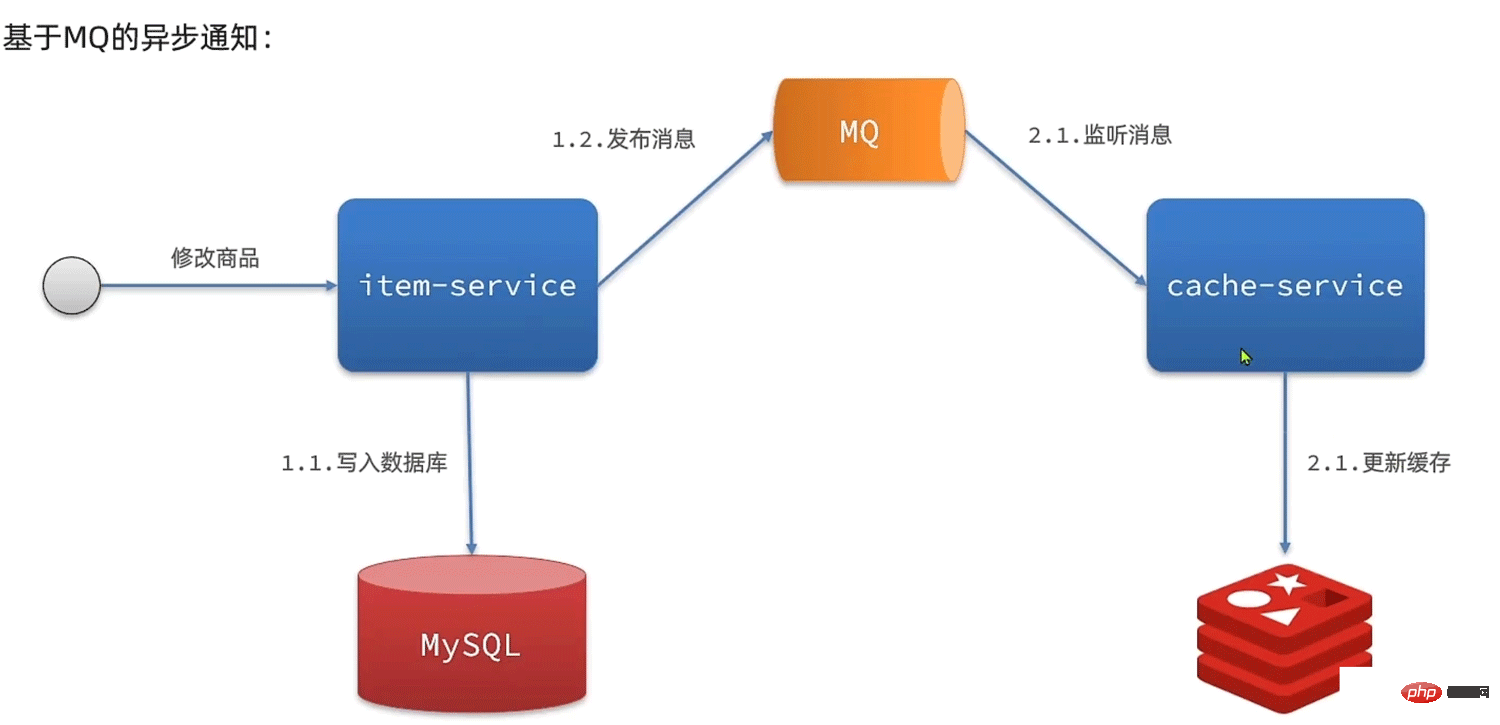
- 1.3 Notification asynchrone
- Envoyer des notifications d'événements lorsque la base de données est modifiée et que les services associés modifient les données mises en cache après l'avoir écoutée
- Avantages : faible couplage, peut être notifié en même temps Plusieurs services de cache
- Inconvénients : Rapidité, il peut y avoir des problèmes d'incohérence du cache
- Scénario : La rapidité est moyenne, plusieurs services doivent être synchronisés
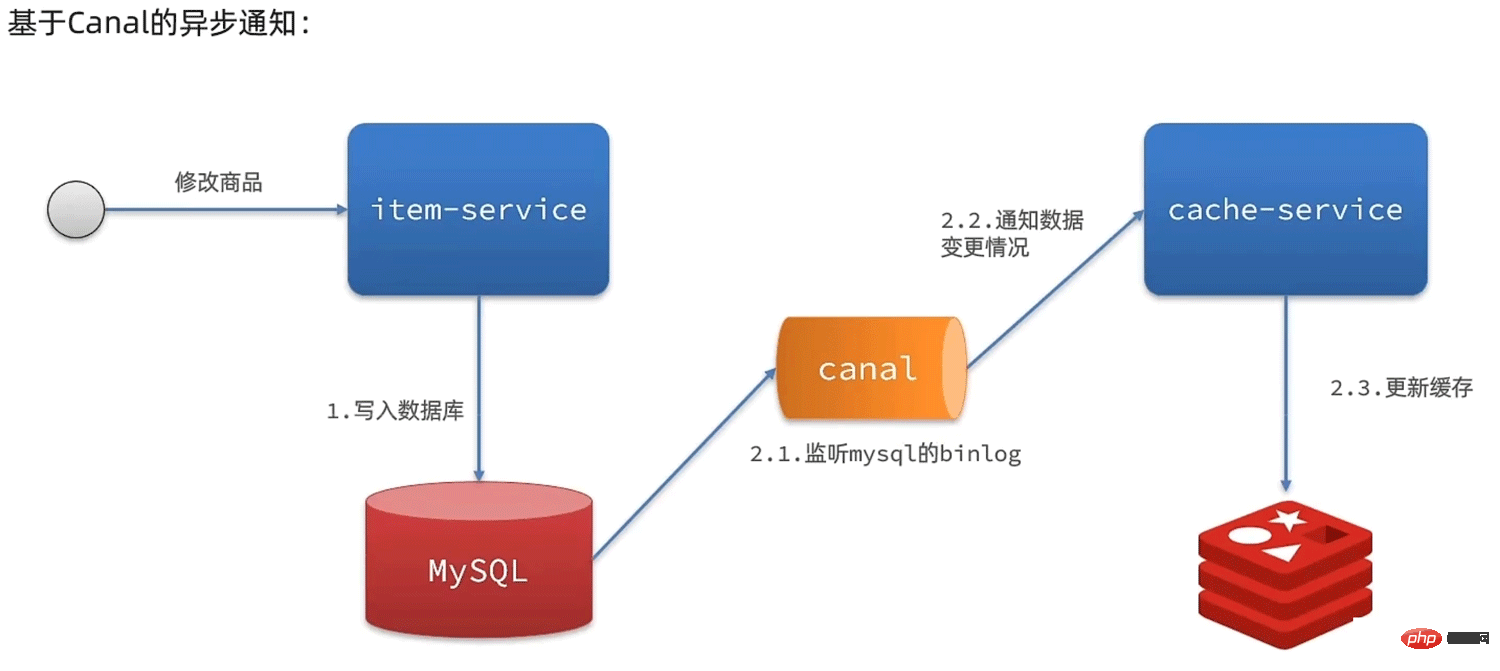 2. Basé sur Canal La notification asynchrone
2. Basé sur Canal La notification asynchrone
- est un projet open source sous Alibaba, développé sur la base de Java
- Basé sur l'analyse incrémentielle des journaux de base de données, fournissant un abonnement et une consommation de données incrémentielles
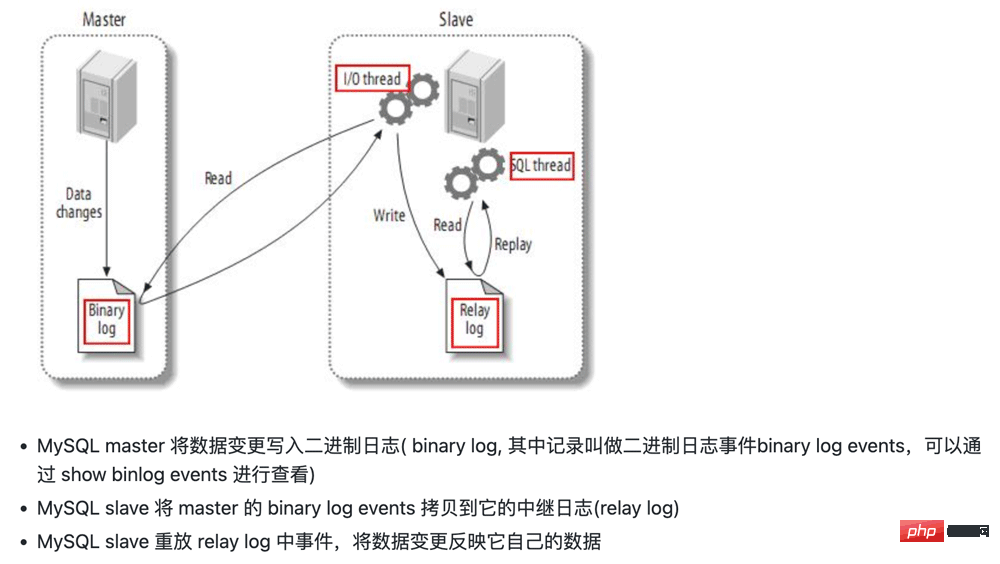
- basé sur l'idée de sauvegarde maître-esclave de mysql
- Réplication maître-esclave mysql 2.1
 Principe de fonctionnement du canal 2.2
Principe de fonctionnement du canal 2.2
- canal simule le protocole d'interaction de l'esclave MySQL, se déguise en esclave MySQL, envoie le protocole de vidage vers le maître MySQL
- Le maître MySQL reçoit une demande de vidage, commencez à pousser le journal binaire vers l'esclave (c'est-à-dire le canal)
- canal analyse l'objet du journal binaire (à l'origine un flux d'octets)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!