
Maison >Java >javaDidacticiel >Comment implémenter l'arborescence des préfixes en Java
Comment implémenter l'arborescence des préfixes en Java

- PHPzavant
- 2023-05-13 14:43:131899parcourir
1. Arbre de préfixes
1. Qu'est-ce qu'un arbre de préfixes
L'arbre de dictionnaire (arbre de Trie) est une structure de données en forme d'arborescence qui est souvent utilisée pour le stockage et la recherche de chaînes. L'idée principale de l'arborescence du dictionnaire est d'utiliser des préfixes communs entre les chaînes pour économiser de l'espace de stockage et améliorer l'efficacité des requêtes. C'est un multi-arbre, chaque nœud représente le préfixe d'une chaîne, et le chemin du nœud racine au nœud feuille constitue une chaîne.
Le nœud racine de l'arborescence du dictionnaire ne contient pas de caractères. Chaque nœud enfant représente un caractère. Les caractères sur le chemin du nœud racine à n'importe quel nœud sont connectés à la chaîne représentée par le nœud. Chaque nœud peut stocker une ou plusieurs chaînes, généralement en utilisant un indicateur pour indiquer si la chaîne représentée par un nœud existe. Lorsque vous avez besoin de rechercher une chaîne dans un ensemble de chaînes, vous pouvez utiliser une arborescence de dictionnaire pour réaliser des opérations de recherche efficaces.
2. Exemple d'arbre de préfixes
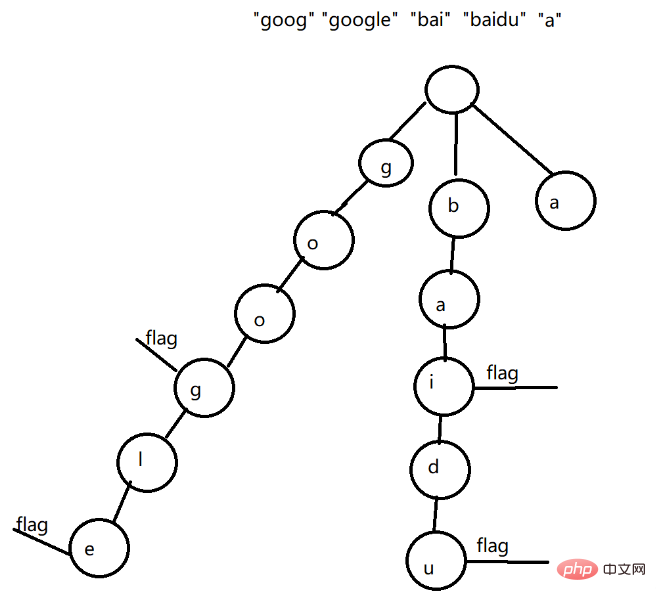
Par exemple, créez un arbre de préfixes pour le tableau de chaînes {"goog", "google", "bai", "baidu", "a"} À ce stade, nous pouvons clairement. voir le préfixe Quelques caractéristiques de l'arbre :
Le nœud racine ne sauvegarde pas les caractères
L'arbre des préfixes est un arbre multi-fork
Chaque nœud de l'arbre des préfixes enregistre un caractère
Chaînes avec le même préfixe Enregistrées sur le même chemin
La fin de la chaîne a également un signe de fin sur l'arbre des préfixes
2. Implémentation de l'arbre des préfixes
La question 208 sur le sujet consiste à implémenter l'arbre de préfixes :Likou
1. La structure de données de l'arbre de préfixes
Lors de l'écriture du code, je préfère utiliser des tables de hachage pour stocker les informations sur les nœuds. Certains peuvent également utiliser des tableaux pour stocker les informations sur les nœuds. C'est la même chose
public class Trie {
Map<Character, Trie> next;
boolean isEnd;
public Trie() {
this.next = new HashMap<>();
this.isEnd = false;
}
public void insert(String word) {
}
public boolean search(String word) {
return false;
}
public boolean startsWith(String prefix) {
return false;
}
}2. Insérer une chaîne
public void insert(String word) {
Trie trie = this;//获得根结点
for (char c : word.toCharArray()) {
if (trie.next.get(c) == null) {//当前结点不存在
trie.next.put(c, new Trie());//创建当前结点
}
trie = trie.next.get(c);//得到字符c的结点,继续向下遍历
}
trie.isEnd = true;
}3. Rechercher une chaîne
public boolean search(String word) {
Trie trie = this;//获得根结点
for (char c : word.toCharArray()) {
if (trie.next.get(c) == null) {//当前结点不存在
return false;
}
trie = trie.next.get(c);//得到字符c的结点,继续向下遍历
}
return trie.isEnd;
}4 Trouver un préfixe
public boolean startsWith(String prefix) {
Trie trie = this;//获得根结点
for (char c : prefix.toCharArray()) {
if (trie.next.get(c) == null) {//当前结点不存在
return false;
}
trie = trie.next.get(c);//得到字符c的结点,继续向下遍历
}
return true;
}L'étape suivante consiste à répondre à quelques questions sur les arbres de préfixes
3. 1. Description de la question
Donne un tableau de chaînes
et ajoute progressivement une lettre aux autres mots du dictionnaire.words 组成的一本英语词典。返回words 中最长的一个单词,该单词是由wordsS'il y a plusieurs réponses réalisables, le mot avec le plus petit ordre lexicographique parmi les réponses sera renvoyé. S'il n'y a pas de réponse, une chaîne vide est renvoyée.
Liqun : Liqun
2. Analyse du problème
Il s'agit d'une question typique sur l'arbre de préfixes, mais cette question a des exigences particulières. La réponse renvoyée est :
1. Le mot le plus long
2. Ce mot est composé progressivement. en d'autres termes
3. La même longueur renvoie l'ordre lexicographique le plus petit
Nous devons donc modifier le code correspondant de l'arborescence des préfixes. Le code pour insérer les chaînes une par une reste inchangé. .Il doit être dans trie.next.get(c) == null et ajouter une condition pour juger comme faux, c'est-à-dire que chaque nœud doit avoir un indicateur vrai, indiquant qu'il y a un mot dans chaque nœud. pour former le mot le plus long (mot du nœud feuille)
3 Implémentation du code
class Solution {
public String longestWord(String[] words) {
Trie trie = new Trie();
for (String word : words) {
trie.insert(word);
}
String longest = "";
for (String word : words) {
if (trie.search(word)) {
if (word.length() > longest.length() || ((word.length() == longest.length()) && (word.compareTo(longest) < 0))) {
longest = word;
}
}
}
return longest;
}
}
class Trie {
Map<Character, Trie> next;
boolean isEnd;
public Trie() {
this.next = new HashMap<>();
this.isEnd = false;
}
public void insert(String word) {
Trie trie = this;//获得根结点
for (char c : word.toCharArray()) {
if (trie.next.get(c) == null) {//当前结点不存在
trie.next.put(c, new Trie());//创建当前结点
}
trie = trie.next.get(c);//得到字符c的结点,继续向下遍历
}
trie.isEnd = true;
}
public boolean search(String word) {
Trie trie = this;//获得根结点
for (char c : word.toCharArray()) {
if (trie.next.get(c) == null || !trie.next.get(c).isEnd) {//当前结点不存在
return false;
}
trie = trie.next.get(c);//得到字符c的结点,继续向下遍历
}
return trie.isEnd;
}
}.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!