
Maison >développement back-end >Tutoriel Python >Comment construire un arbre de décision en Python
Comment construire un arbre de décision en Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-13 11:22:052554parcourir
Arbres de décision
Les arbres de décision font partie intégrante des méthodes d'apprentissage supervisé les plus puissantes disponibles aujourd'hui. Un arbre de décision est essentiellement un organigramme d'un arbre binaire dans lequel chaque nœud divise un ensemble d'observations en fonction d'une variable caractéristique.
Le but d'un arbre de décision est de diviser les données en groupes de telle sorte que chaque élément d'un groupe appartient à la même catégorie. Les arbres de décision peuvent également être utilisés pour approximer des variables cibles continues. Dans ce cas, l’arbre sera divisé de telle sorte que chaque groupe ait la plus petite erreur quadratique moyenne.
Une propriété importante des arbres de décision est qu'ils sont facilement interprétables. Vous n'avez pas du tout besoin d'être familier avec les techniques d'apprentissage automatique pour comprendre ce que font les arbres de décision. Les diagrammes d’arbre de décision sont faciles à interpréter.
Avantages et inconvénients
Les avantages de la méthode de l'arbre de décision sont :
Les arbres de décision peuvent générer des règles compréhensibles.
Les arbres de décision effectuent une classification sans nécessiter beaucoup de calculs.
Les arbres de décision peuvent gérer à la fois des variables continues et catégorielles.
Les arbres de décision fournissent une indication claire quels champs sont les plus importants.
Les inconvénients de la méthode de l'arbre de décision sont :
Les arbres de décision ne sont pas très adaptés aux tâches d'estimation où le but est de prédire des valeurs d'attributs continues.
Les arbres de décision sont sujets à des erreurs dans les problèmes de classification avec de nombreuses classes et peu d'échantillons de formation.
La formation des arbres de décision peut être coûteuse en termes de calcul. Le processus de génération d’arbres de décision est très coûteux en termes de calcul. À chaque nœud, chaque champ de division candidat doit être trié pour trouver sa meilleure division. Dans certains algorithmes, utilisant des combinaisons de champs, il faut rechercher la meilleure combinaison de poids. Les algorithmes d’élagage peuvent également être coûteux car de nombreux sous-arbres candidats doivent être formés et comparés.
Python Decision Tree
Python est un langage de programmation à usage général qui fournit de puissants packages et outils d'apprentissage automatique pour les scientifiques des données. Dans cet article, nous utiliserons scikit-learn, le package d'apprentissage automatique le plus célèbre de Python, pour créer un modèle d'arbre de décision. Nous allons créer le modèle à l'aide de l'algorithme "DecisionTreeClassifier" fourni par scikit learn puis visualiser le modèle à l'aide de la fonction "plot_tree".
Étape 1 : Importer le package
Les principaux logiciels que nous utilisons pour construire le modèle sont pandas, scikit learn et NumPy. Suivez le code pour importer les packages requis en python.
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20)
Après avoir importé tous les packages nécessaires à la construction de notre modèle, il est temps d'importer les données et d'effectuer une EDA dessus.
Étape 2 : Importer des données et EDA
Dans cette étape, nous utiliserons le package "Pandas" fourni en python pour importer et faire de l'EDA dessus. Nous construirons notre modèle d'arbre de décision sur un ensemble de données de médicaments prescrits aux patients en fonction de critères spécifiques. Importons les données en utilisant Python !
Implémentation Python :
df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold']))
Sortie :
Age Sex BP Cholesterol Na_to_K Drug 0 23 F HIGH HIGH 25.355 drugY 1 47 M LOW HIGH 13.093 drugC 2 47 M LOW HIGH 10.114 drugC 3 28 F NORMAL HIGH 7.798 drugX 4 61 F LOW HIGH 18.043 drugY
Maintenant, nous avons une idée claire de l'ensemble de données. Après avoir importé les données, utilisons la fonction "info" pour obtenir des informations de base sur les données. Les informations fournies par cette fonction incluent le nombre d'entrées, le numéro d'index, le nom de la colonne, le nombre de valeurs non nulles, le type d'attribut, etc.
Implémentation Python :
df.info()
Sortie :
<class> RangeIndex: 200 entries, 0 to 199 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 200 non-null int64 1 Sex 200 non-null object 2 BP 200 non-null object 3 Cholesterol 200 non-null object 4 Na_to_K 200 non-null float64 5 Drug 200 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 9.5+ KB</class>
Étape 3 : Traitement des données
Nous pouvons voir que des attributs tels que le sexe, la tension artérielle et le cholestérol sont de nature catégorielle et de type objet. Le problème est que l'algorithme d'arbre de décision dans scikit-learn ne prend pas en charge, par nature, les variables X (caractéristiques) étant de type « objet ». Il est donc nécessaire de convertir ces valeurs « objets » en valeurs « binaires ». Utilisons python pour implémenter
Implémentation Python :
for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold']))
Sortie :
Age Sex BP Cholesterol Na_to_K Drug 0 23 1 2 1 25.355 drugY 1 47 1 0 1 13.093 drugC 2 47 1 0 1 10.114 drugC 3 28 1 1 1 7.798 drugX 4 61 1 0 1 18.043 drugY .. ... ... .. ... ... ... 195 56 1 0 1 11.567 drugC 196 16 1 0 1 12.006 drugC 197 52 1 1 1 9.894 drugX 198 23 1 1 1 14.020 drugX 199 40 1 0 1 11.349 drugX [200 rows x 6 columns]
Nous pouvons observer que toutes les valeurs « objet » sont traitées en valeurs « binaires » pour représenter des données catégorielles. Par exemple, dans l'attribut cholestérol, les valeurs indiquant « faible » sont traitées comme 0 et les valeurs « élevées » sont traitées comme 1. Nous sommes maintenant prêts à créer les variables dépendantes et indépendantes à partir des données.
Étape 4 : Divisez les données
Après avoir traité nos données dans la structure correcte, nous configurons maintenant la variable "X" (variable indépendante), la variable "Y" (variable dépendante). Implémentons-le en python
Implémentation Python :
X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold']))
Sortie :
X variable samples : [[ 1. 2. 23. 1. 25.355] [ 1. 0. 47. 1. 13.093] [ 1. 0. 47. 1. 10.114] [ 1. 1. 28. 1. 7.798] [ 1. 0. 61. 1. 18.043]] Y variable samples : ['drugY' 'drugC' 'drugC' 'drugX' 'drugY']
Nous pouvons maintenant utiliser l'algorithme « train_test_split » dans scikit learn pour diviser les données en un ensemble d'entraînement et un ensemble de test, qui contiennent le X et Oui, nous avons défini la variable. Suivez le code pour diviser les données en python.
Implémentation Python :
X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'black')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'black')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'black')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'black'))
Sortie :
X_train shape : (160, 5) X_test shape : (40, 5) y_train shape : (160,) y_test shape : (40,)
Nous avons maintenant tous les composants pour construire un modèle d'arbre de décision. Alors, allons-y et construisons notre modèle en python.
Étape 5 : Construire un modèle et une prédiction
Avec l'aide de l'algorithme "DecisionTreeClassifier" fourni par le package scikit-learn, il est possible de construire un arbre de décision. Ensuite, nous pouvons utiliser notre modèle entraîné pour prédire nos données. Enfin, la précision de nos résultats de prédiction peut être calculée à l'aide de la métrique d'évaluation « Précision ». Utilisons Python pour terminer ce processus !
Implémentation de Python :
model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold']))
Sortie :
Accuracy of the model is 88%
在代码的第一步中,我们定义了一个名为“model”变量的变量,我们在其中存储DecisionTreeClassifier模型。接下来,我们将使用我们的训练集对模型进行拟合和训练。之后,我们定义了一个变量,称为“pred_model”变量,其中我们将模型预测的所有值存储在数据上。最后,我们计算了我们的预测值与实际值的精度,其准确率为88%。
步骤6:可视化模型
现在我们有了决策树模型,让我们利用python中scikit learn包提供的“plot_tree”函数来可视化它。按照代码从python中的决策树模型生成一个漂亮的树图。
Python实现:
feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')
输出:
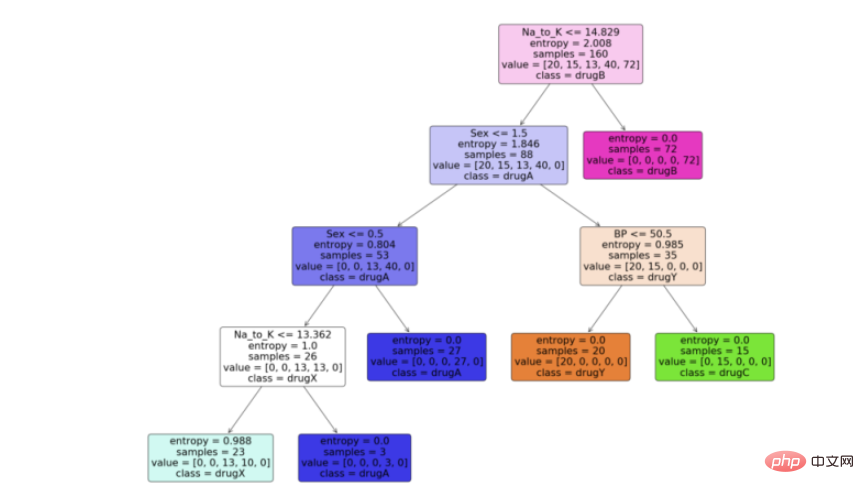
结论
有很多技术和其他算法用于优化决策树和避免过拟合,比如剪枝。虽然决策树通常是不稳定的,这意味着数据的微小变化会导致最优树结构的巨大变化,但其简单性使其成为广泛应用的有力候选。在神经网络流行之前,决策树是机器学习中最先进的算法。其他一些集成模型,比如随机森林模型,比普通决策树模型更强大。
决策树由于其简单性和可解释性而非常强大。决策树和随机森林在用户注册建模、信用评分、故障预测、医疗诊断等领域有着广泛的应用。我为本文提供了完整的代码。
完整代码:
import pandas as pd # 数据处理 import numpy as np # 使用数组 import matplotlib.pyplot as plt # 可视化 from matplotlib import rcParams # 图大小 from termcolor import colored as cl # 文本自定义 from sklearn.tree import DecisionTreeClassifier as dtc # 树算法 from sklearn.model_selection import train_test_split # 拆分数据 from sklearn.metrics import accuracy_score # 模型准确度 from sklearn.tree import plot_tree # 树图 rcParams['figure.figsize'] = (25, 20) df = pd.read_csv('drug.csv') df.drop('Unnamed: 0', axis = 1, inplace = True) print(cl(df.head(), attrs = ['bold'])) df.info() for i in df.Sex.values: if i == 'M': df.Sex.replace(i, 0, inplace = True) else: df.Sex.replace(i, 1, inplace = True) for i in df.BP.values: if i == 'LOW': df.BP.replace(i, 0, inplace = True) elif i == 'NORMAL': df.BP.replace(i, 1, inplace = True) elif i == 'HIGH': df.BP.replace(i, 2, inplace = True) for i in df.Cholesterol.values: if i == 'LOW': df.Cholesterol.replace(i, 0, inplace = True) else: df.Cholesterol.replace(i, 1, inplace = True) print(cl(df, attrs = ['bold'])) X_var = df[['Sex', 'BP', 'Age', 'Cholesterol', 'Na_to_K']].values # 自变量 y_var = df['Drug'].values # 因变量 print(cl('X variable samples : {}'.format(X_var[:5]), attrs = ['bold'])) print(cl('Y variable samples : {}'.format(y_var[:5]), attrs = ['bold'])) X_train, X_test, y_train, y_test = train_test_split(X_var, y_var, test_size = 0.2, random_state = 0) print(cl('X_train shape : {}'.format(X_train.shape), attrs = ['bold'], color = 'red')) print(cl('X_test shape : {}'.format(X_test.shape), attrs = ['bold'], color = 'red')) print(cl('y_train shape : {}'.format(y_train.shape), attrs = ['bold'], color = 'green')) print(cl('y_test shape : {}'.format(y_test.shape), attrs = ['bold'], color = 'green')) model = dtc(criterion = 'entropy', max_depth = 4) model.fit(X_train, y_train) pred_model = model.predict(X_test) print(cl('Accuracy of the model is {:.0%}'.format(accuracy_score(y_test, pred_model)), attrs = ['bold'])) feature_names = df.columns[:5] target_names = df['Drug'].unique().tolist() plot_tree(model, feature_names = feature_names, class_names = target_names, filled = True, rounded = True) plt.savefig('tree_visualization.png')Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!