
Maison >développement back-end >Tutoriel Python >La combinaison parfaite de Python et Excel : résumé des opérations courantes (analyse de cas détaillée)
La combinaison parfaite de Python et Excel : résumé des opérations courantes (analyse de cas détaillée)

- PHPzavant
- 2023-05-13 10:40:061103parcourir

Texte
Dans le passé, le mot anglais correspondant à l'analyse commerciale était Business Analysis, et l'outil d'analyse que tout le monde utilisait était Excel. Plus tard, la quantité de données a augmenté et Excel ne pouvait pas les gérer (le nombre maximum de lignes). pris en charge par Excel est de 1 048 576 lignes). Les gens commencent à se tourner vers des outils d'analyse tels que Python et R. À l'heure actuelle, le mot correspondant à l'analyse commerciale est Business Analytics.
En fait, les directives d'utilisation de Python et d'Excel sont les mêmes, elles sont [Nous ne nous répétons pas], qui consiste à remplacer autant que possible les opérations mécaniques et le travail manuel pur par des opérations plus pratiques.
L'utilisation de Python pour l'analyse des données est indissociable du célèbre package pandas. Après de nombreuses versions d'optimisation itérative, l'écosystème actuel de pandas est assez complet. Le site officiel propose également une comparaison entre celui-ci et d'autres outils d'analyse :

. Cet article utilise principalement des pandas. La bibliothèque utilisée pour le dessin est plotly. Les fonctions courantes d'Excel implémentées sont :
- Interaction entre Python et Excel
- Fonction vlookup
- Tableau croisé dynamique
- Dessin
Si vous la découvrez dans le futur Nous reviendrons pour continuer la mise à jour et ajouter plus de fonctions Excel. Avant de commencer, chargez d'abord le package pandas comme d'habitude :
import numpy as np
import pandas as pd
pd.set_option('max_columns', 10)
pd.set_option('max_rows', 20)
pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法Interaction entre Python et Excel
Les quatre fonctions les plus couramment utilisées liées aux E/S Excel dans pandas sont read_csv/ read_excel/ to_csv/ to_excel, et elles ont toutes des paramètres spécifiques. . Paramètres, vous pouvez personnaliser les effets de lecture et d'exportation souhaités.
Par exemple, si vous souhaitez lire la partie supérieure gauche d'un tel tableau :
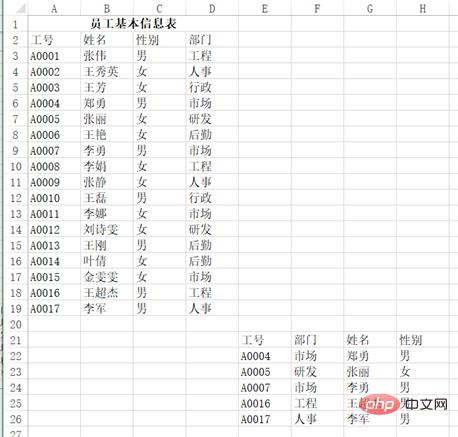
vous pouvez utiliser pd.read_excel("test.xlsx", header=1, nrows=17, usecols=3), et le résultat est renvoyé :
df Out[]: 工号 姓名 性别部门 0 A0001 张伟男工程 1 A0002王秀英女人事 2 A0003 王芳女行政 3 A0004 郑勇男市场 4 A0005 张丽女研发 5 A0006 王艳女后勤 6 A0007 李勇男市场 7 A0008 李娟女工程 8 A0009 张静女人事 9 A0010 王磊男行政 10A0011 李娜女市场 11A0012刘诗雯女研发 12A0013 王刚男后勤 13A0014 叶倩女后勤 14A0015金雯雯女市场 15A0016王超杰男工程 16A0017 李军男人事
Il en va de même pour la fonction de sortie. Vous pouvez contrôler le nombre de colonnes à utiliser, s'il faut indexer et comment placer le titre.
Fonction vlookup
vlookup est connue comme l'un des artefacts d'Excel et a un large éventail d'utilisations. Les exemples suivants proviennent de Douban. Les 10 utilisations les plus couramment utilisées de la fonction VLOOKUP en connaissez-vous ? Cas 1
Question : A3 : La zone de cellule B7 est une table de recherche de notes par lettres, indiquant qu'un score inférieur à 60 est le grade E, 60 à 69 est le grade D, 70 à 79 est le grade C, 80 à 89 est le grade B et un score de 90 ou plus correspond à la note A. D:G est répertorié comme tableau des résultats des tests chinois pour la classe 1, niveau 2. Comment renvoyer la note alphabétique en fonction du score chinois ?
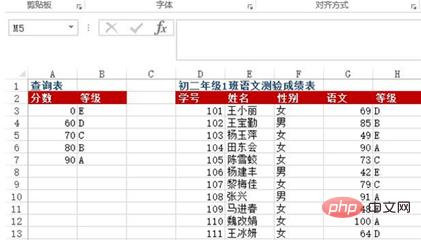 Méthode : saisissez =VLOOKUP(G3, $A$3:$B$7, 2) dans la zone de cellule H3:H13
Méthode : saisissez =VLOOKUP(G3, $A$3:$B$7, 2) dans la zone de cellule H3:H13
Implémentation Python :
df = pd.read_excel("test.xlsx", sheet_name=0)
def grade_to_point(x):
if x >= 90:
return 'A'
elif x >= 80:
return 'B'
elif x >= 70:
return 'C'
elif x >= 60:
return 'D'
else:
return 'E'
df['等级'] = df['语文'].apply(grade_to_point)
df
Out[]:
学号 姓名 性别 语文 等级
0 101王小丽女 69D
1 102王宝勤男 85B
2 103杨玉萍女 49E
3 104田东会女 90A
4 105陈雪蛟女 73C
5 106杨建丰男 42E
6 107黎梅佳女 79C
7 108 张兴 男 91A
8 109马进春女 48E
9 110魏改娟女100A
10111王冰研女 64DCas 2
Question : Comment rechercher dans la feuille 1 Quoi le montant de l'amortissement mensuel est-il sous le numéro correspondant dans le plan d'amortissement ? (Requête croisée).

 Méthode : Entrez =VLOOKUP(A2, Depreciation Schedule!A$2:$G$12, 7, 0) dans les cellules C2:C4 de la feuille 1.
Méthode : Entrez =VLOOKUP(A2, Depreciation Schedule!A$2:$G$12, 7, 0) dans les cellules C2:C4 de la feuille 1.
Implémentation Python : utilisez simplement la fusion pour connecter les deux tables en fonction de leurs numéros.
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1
df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')
Out[]:
编号 资产名称月折旧额
0YT001电动门 1399
1YT005桑塔纳轿车1147
2YT008打印机51Cas trois
Problème : similaire au cas deux, mais cette fois, une recherche approximative doit être utilisée.
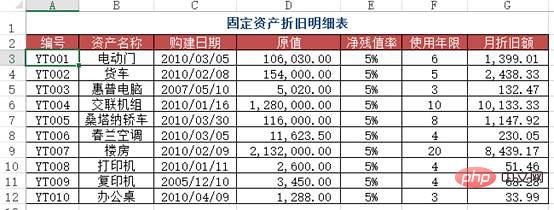
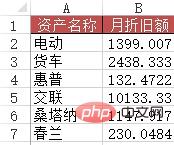 Méthode : Saisissez la formule =VLOOKUP(A2&"*", plan d'amortissement !$B$2:$G$12, 6, 0) dans la zone B2:B7.
Méthode : Saisissez la formule =VLOOKUP(A2&"*", plan d'amortissement !$B$2:$G$12, 6, 0) dans la zone B2:B7.
Implémentation de Python : celle-ci est plus gênante que la précédente et nécessite certaines compétences d'utilisation des pandas.
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表
df3['月折旧额'] = 0
for i in range(len(df3['资产名称'])):
df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3
Out[]:
资产名称 月折旧额
0 电动 1399
1 货车 2438
2 惠普132
3 交联10133
4桑塔纳 1147
5 春兰230Cas 4
Problème : lors de la saisie des informations sur les données dans Excel, afin d'améliorer l'efficacité du travail, l'utilisateur espère afficher automatiquement le reste des informations dans l'enregistrement en saisissant les mots-clés des données, par exemple en saisissant le. Le numéro d'employé de l'employé affichera automatiquement l'employé. Si vous entrez le numéro de matériel, le nom du produit, le prix unitaire, etc. du matériel seront automatiquement affichés.
Comme le montre la figure, le tableau source des données contient les informations de base de tous les employés d'une certaine unité. Dans la feuille de calcul « Tableau des statistiques de congés des employés pour mars 2010 », lorsque le numéro d'employé est saisi dans la colonne A, comment réaliser. le nom de l'employé correspondant, saisir automatiquement des informations telles que le numéro d'identification, le service, le poste, la date d'adhésion, etc. ? De plus, recherchez sur le compte public Linux pour savoir comment répondre « git books » en arrière-plan et obtenez un coffret cadeau surprise.
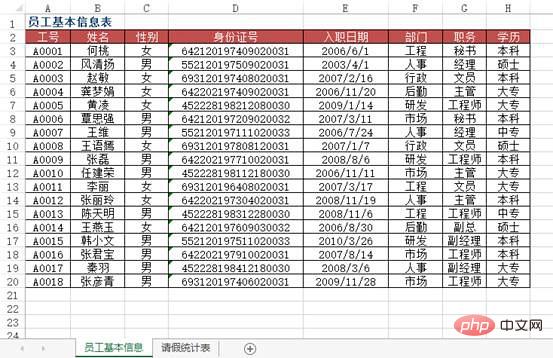
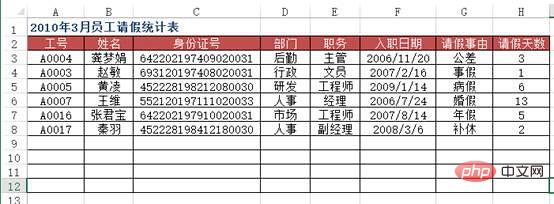
方法:使用VLOOKUP+MATCH函数,在“2010年3月员工请假统计表”工作表中选择B3:F8单元格区域,输入下列公式=IF($A3="","",VLOOKUP($A3,员工基本信息!$A:$H,MATCH(B$2,员工基本信息!$2:$2,0),0)),按下【Ctrl+Enter】组合键结束。
python实现:上面的Excel的方法用得很灵活,但是pandas的想法和操作更简单方便些。
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')
df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')
df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')
Out[]:
工号 姓名部门 职务 入职日期
0A0004龚梦娟后勤 主管 2006-11-20
1A0003 赵敏行政 文员 2007-02-16
2A0005 黄凌研发工程师 2009-01-14
3A0007 王维人事 经理 2006-07-24
4A0016张君宝市场工程师 2007-08-14
5A0017 秦羽人事副经理 2008-03-06案例五
问题:用VLOOKUP函数实现批量查找,VLOOKUP函数一般情况下只能查找一个,那么多项应该怎么查找呢?如下图,如何把张一的消费额全部列出?
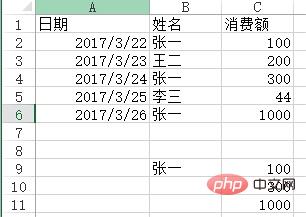
方法:在C9:C11单元格里面输入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。
python实现:vlookup函数有两个不足(或者算是特点吧),一个是被查找的值一定要在区域里的第一列,另一个是只能查找一个值,剩余的即便能匹配也不去查找了,这两点都能通过灵活应用if和indirect函数来解决,不过pandas能做得更直白一些。
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')
df6[df6['姓名'] == '张一'][['姓名', '消费额']]
Out[]:
姓名 消费额
0张一 100
2张一 300
4张一1000数据透视表
数据透视表是Excel的另一个神器,本质上是一系列的表格重组整合的过程。这里用的案例来自知乎,Excel数据透视表有什么用途:(https://www.zhihu.com/question/22484899/answer/39933218 )
问题:需要汇总各个区域,每个月的销售额与成本总计,并同时算出利润。
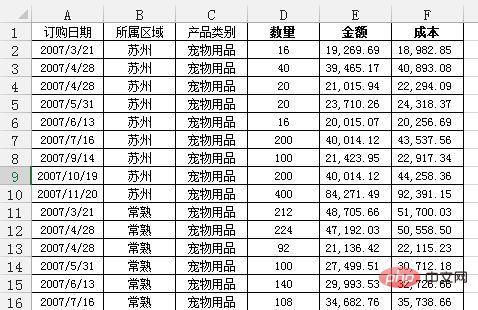
通过Excel的数据透视表的操作最终实现了下面这样的效果:
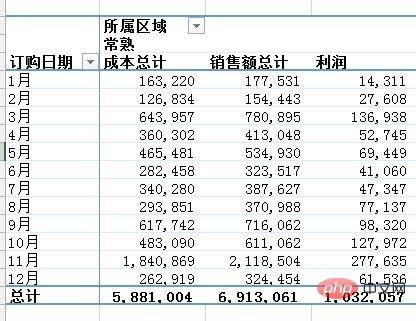
python实现:对于这样的分组的任务,首先想到的就是pandas的groupby,代码写起来也简单,思路就是把刚才Excel的点鼠标的操作反映到代码命令上:
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')
df['订购月份'] = df['订购日期'].apply(lambda x:x.month)
df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')
df2['利润'] = df2['销售额'] - df2['成本']
df2
Out[]:
销售额 成本利润
订购月份 所属区域
1南京134313.61 94967.8439345.77
常熟177531.47163220.0714311.40
无锡316418.09231822.2884595.81
昆山159183.35145403.3213780.03
苏州287253.99238812.0348441.96
2南京187129.13138530.4248598.71
常熟154442.74126834.3727608.37
无锡464012.20376134.9887877.22
昆山102324.46 86244.5216079.94
苏州105940.34 91419.5414520.80
...... ...
11 南京286329.88221687.1164642.77
常熟 2118503.54 1840868.53 277635.01
无锡633915.41536866.7797048.64
昆山351023.24342420.18 8603.06
苏州 1269351.39 1144809.83 124541.56
12 南京894522.06808959.3285562.74
常熟324454.49262918.8161535.68
无锡 1040127.19856816.72 183310.48
昆山 1096212.75951652.87 144559.87
苏州347939.30302154.2545785.05
[60 rows x 3 columns]也可以使用pandas里的pivot_table函数来实现:
df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum') df3['利润'] = df3['销售额'] - df3['成本'] df3 Out[]: 成本销售额利润 订购月份 所属区域 1南京 94967.84134313.6139345.77 常熟163220.07177531.4714311.40 无锡231822.28316418.0984595.81 昆山145403.32159183.3513780.03 苏州238812.03287253.9948441.96 2南京138530.42187129.1348598.71 常熟126834.37154442.7427608.37 无锡376134.98464012.2087877.22 昆山 86244.52102324.4616079.94 苏州 91419.54105940.3414520.80 ...... ... 11 南京221687.11286329.8864642.77 常熟 1840868.53 2118503.54 277635.01 无锡536866.77633915.4197048.64 昆山342420.18351023.24 8603.06 苏州 1144809.83 1269351.39 124541.56 12 南京808959.32894522.0685562.74 常熟262918.81324454.4961535.68 无锡856816.72 1040127.19 183310.48 昆山951652.87 1096212.75 144559.87 苏州302154.25347939.3045785.05 [60 rows x 3 columns]
pandas的pivot_table的参数index/ columns/ values和Excel里的参数是对应上的(当然,我这话说了等于没说,数据透视表里不就是行/列/值吗还能有啥。)
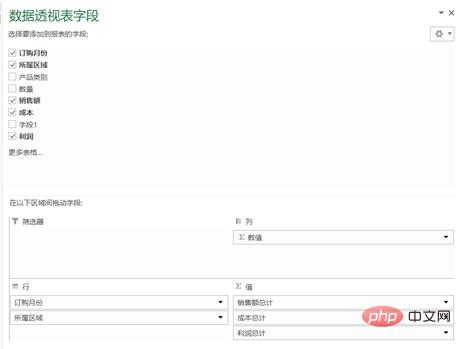
但是我个人还是更喜欢用groupby,因为它运算速度非常快。我在打kaggle比赛的时候,有一张表是贷款人的行为信息,大概有2700万行,用groupby算了几个聚合函数,几秒钟就完成了。
groupby的功能很全面,内置了很多aggregate函数,能够满足大部分的基本需求,如果你需要一些其他的函数,可以搭配使用apply和lambda。
不过pandas的官方文档说了,groupby之后用apply速度非常慢,aggregate内部做过优化,所以很快,apply是没有优化的,所以建议有问题先想想别的方法,实在不行的时候再用apply。
我打比赛的时候,为了生成一个新变量,用了groupby的apply,写了这么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。
绘图
因为Excel画出来的图能够交互,能够在图上进行一些简单操作,所以这里用的python的可视化库是plotly,案例就用我这个学期发展经济学课上的作业吧,当时的图都是用Excel画的,现在用python再画一遍。开始之前,首先加载plotly包。
import plotly.offline as off import plotly.graph_objs as go off.init_notebook_mode()
柱状图
当时用Excel画了很多的柱状图,其中的一幅图是:
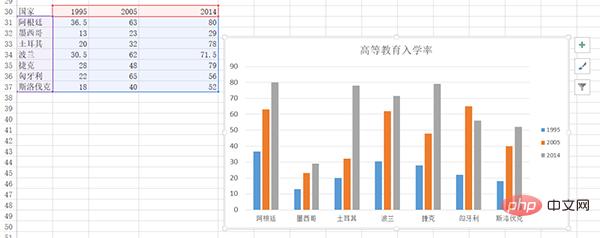
下面用plotly来画一下:
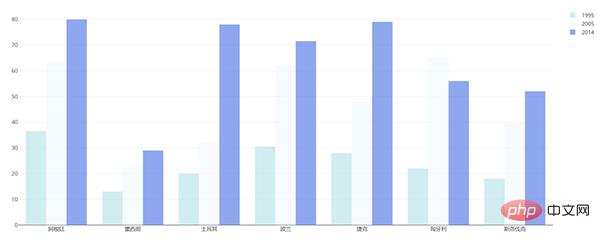
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')
trace1 = go.Bar(
x=df['国家'],
y=df[1995],
name='1995',
opacity=0.6,
marker=dict(
color='powderblue'
)
)
trace2 = go.Bar(
x=df['国家'],
y=df[2005],
name='2005',
opacity=0.6,
marker=dict(
color='aliceblue',
)
)
trace3 = go.Bar(
x=df['国家'],
y=df[2014],
name='2014',
opacity=0.6,
marker=dict(
color='royalblue'
)
)
layout = go.Layout(barmode='group')
data = [trace1, trace2, trace3]
fig = go.Figure(data, layout)
off.plot(fig)雷达图
用Excel画的:
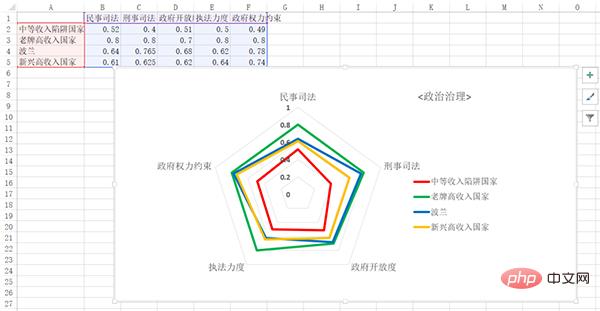
用python画的:
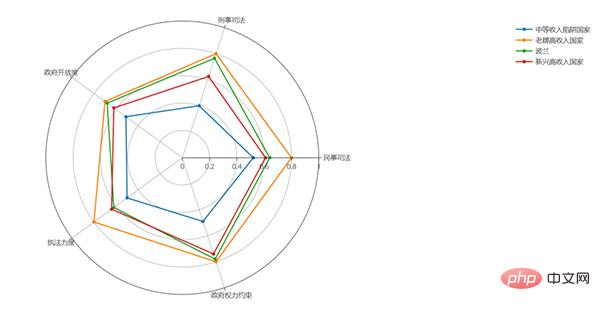
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')
theta = df.columns.tolist()
theta.append(theta[0])
names = df.index
df[''] = df.iloc[:,0]
df = np.array(df)
trace1 = go.Scatterpolar(
r=df[0],
theta=theta,
name=names[0]
)
trace2 = go.Scatterpolar(
r=df[1],
theta=theta,
name=names[1]
)
trace3 = go.Scatterpolar(
r=df[2],
theta=theta,
name=names[2]
)
trace4 = go.Scatterpolar(
r=df[3],
theta=theta,
name=names[3]
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0,1]
)
),
showlegend=True
)
fig = go.Figure(data, layout)
off.plot(fig)画起来比Excel要麻烦得多。
总体而言,如果画简单基本的图形,用Excel是最方便的,如果要画高级一些的或者是需要更多定制化的图形,使用python更合适。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!