
Maison >Périphériques technologiques >IA >Transformer bat encore Diffusion ! Google lance Muse, une nouvelle génération de modèle de génération texte-image : l'efficacité de la génération est décuplée
Transformer bat encore Diffusion ! Google lance Muse, une nouvelle génération de modèle de génération texte-image : l'efficacité de la génération est décuplée

- PHPzavant
- 2023-05-13 08:46:051254parcourir
Récemment, Google a publié un nouveau modèle Muse de génération de texte-image. Il n'utilise pas le modèle de diffusion qui est actuellement populaire, mais utilise le modèle Transformer classique pour obtenir les performances de génération d'images les plus avancées par rapport à la diffusion ou à The. l'efficacité du modèle autorégressif et du modèle Muse a également été grandement améliorée.

Lien papier : https://arxiv.org/pdf/2301.00704.pdf
Lien du projet : https://muse-model.github.io/
Muse est formé sur un espace de jetons discret avec une tâche de modélisation masquée : étant donné les incorporations de texte extraites d'un grand modèle de langage (LLM) pré-entraîné, le processus de formation de Muse consiste à prédire des jetons d'image masqués de manière aléatoire.
Par rapport aux modèles de diffusion spatiale de pixels (tels que Imagen et DALL-E 2), puisque Muse utilise des jetons discrets, il ne nécessite que moins d'itérations d'échantillonnage, donc l'efficacité est considérablement améliorée
Par rapport aux modèles autorégressifs ; (comme Parti), Muse est plus efficace car il utilise le décodage parallèle.

L'utilisation d'un LLM pré-entraîné peut permettre une compréhension fine du langage, ce qui se traduit par la génération d'images haute fidélité et la compréhension de concepts visuels, tels que les objets, les relations spatiales, les postures, la cardinalité, etc.
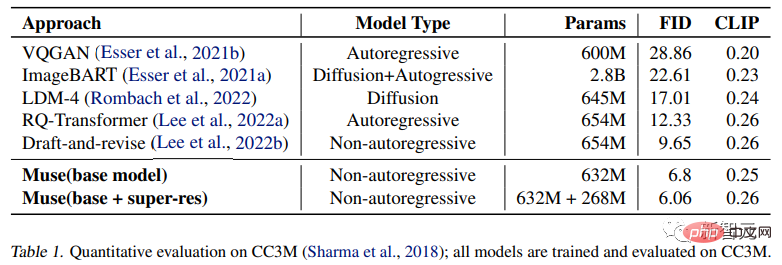
Dans les résultats expérimentaux, le modèle Muse avec seulement 900M de paramètres a atteint de nouvelles performances SOTA sur CC3M avec un score FID de 6,06.
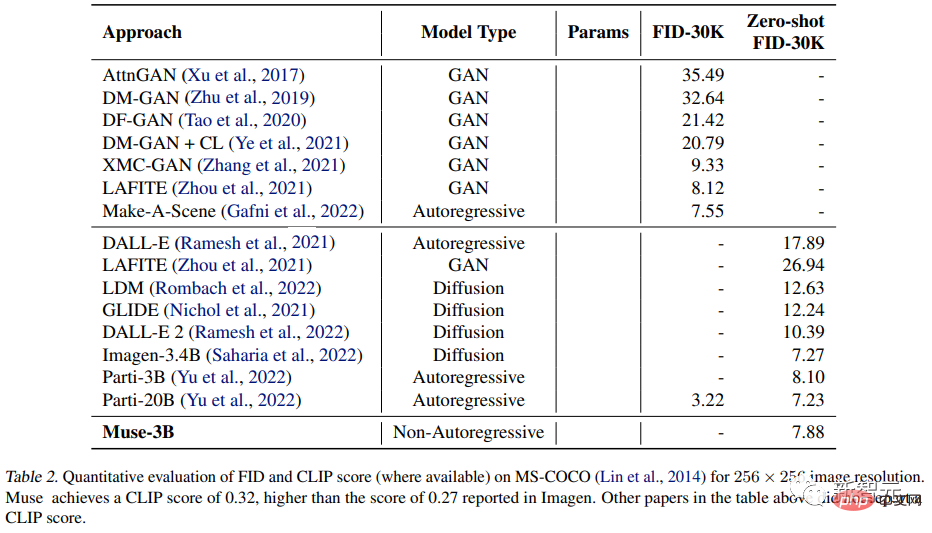
Le modèle paramétrique Muse 3B a obtenu un FID de 7,88 dans l'évaluation COCO zéro-shot, tout en obtenant également un score CLIP de 0,32.

Muse peut également implémenter directement certaines applications d'édition d'images sans affiner ni inverser le modèle : inpainting, outpainting et édition sans masque.
Modèle MuseLe cadre du modèle Muse contient plusieurs composants. Le pipeline de formation comprend l'encodeur de texte pré-entraîné T5-XXL, le modèle de base et le modèle de super-résolution. Encodeur de texte pré-entraîné Résultats de la génération d'images.
Par exemple, l'intégration extraite du modèle de langage T5-XXL contient des informations sur les objets (noms), les actions (verbes), les attributs visuels (adjectifs), les relations spatiales (prépositions) et d'autres attributs (tels que la cardabilité et Composition) informations riches. 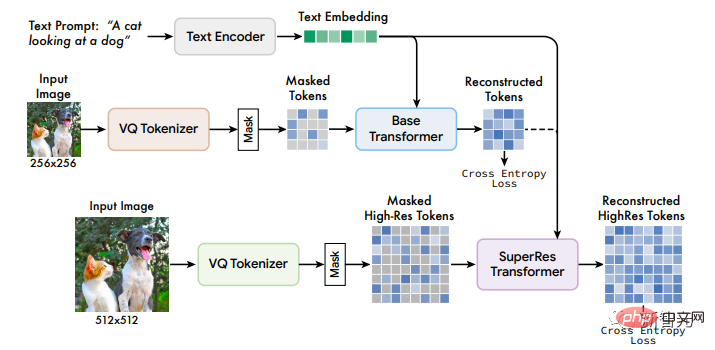
Les chercheurs avancent donc une hypothèse : le modèle Muse apprend à mapper ces riches concepts visuels et sémantiques dans les intégrations LLM aux images générées. Certains travaux récents ont prouvé que la représentation conceptuelle apprise par LLM et la représentation conceptuelle apprise par le modèle formé à la tâche visuelle peuvent être grossièrement « cartographiées linéairement ».
À partir d'un titre de texte d'entrée, le transmettre à l'encodeur T5-XXL avec des paramètres gelés donne lieu à un vecteur d'intégration de langage à 4096 dimensions. Ces vecteurs sont ensuite projetés linéairement sur le modèle Transformer (taux de base et super-résolution). ) dans la dimension de taille cachée.
2. Utilisez VQGAN pour la tokenisation sémantique
Le modèle VQGAN se compose d'un encodeur et d'un décodeur, où la couche de quantification mappe l'image d'entrée en un jeton à partir d'une séquence de livre de codes apprise.
Ensuite, l'encodeur et le décodeur sont entièrement construits avec des couches convolutives pour prendre en charge l'encodage d'images de différentes résolutions.
L'encodeur comprend plusieurs blocs de sous-échantillonnage pour réduire la dimension spatiale de l'entrée, tandis que le décodeur dispose d'un nombre correspondant de blocs de suréchantillonnage pour mapper les latents à la taille de l'image d'origine.
Les chercheurs ont formé deux modèles VQGAN : un avec un taux de sous-échantillonnage f=16, et le modèle a obtenu les étiquettes du modèle de base sur une image de 256×256 pixels, ce qui donne une étiquette avec une taille spatiale de 16×. 16 ; l'autre C'est le taux de sous-échantillonnage f=8, et le jeton du modèle super-résolution est obtenu sur l'image 512×512, et la taille spatiale correspondante est 64×64.
Le jeton discret obtenu après encodage peut capturer la sémantique de haut niveau de l'image, tout en éliminant également le bruit de bas niveau, et sur la base du caractère discret du jeton, la perte d'entropie croisée peut être utilisée à l'extrémité de sortie pour prédisez le jeton masqué à l'étape suivante
3. Modèle de base
Le modèle de base de Muse est un transformateur masqué, où l'entrée est l'intégration T5 mappée et le jeton d'image.
Les chercheurs définissez toutes les intégrations de texte sur non masquées. Après avoir masqué de manière aléatoire une partie des différents jetons d'image, utilisez une marque spéciale [MASK] pour remplacer le jeton d'origine.
Ensuite, le jeton d'image est mappé linéairement à l'entrée du transformateur requise ou à la taille cachée. intégration d'entrée d'image dimensionnelle, et apprenez l'intégration de position 2D en même temps
La même chose que l'architecture originale de Transformer, comprenant plusieurs couches de transformateur, utilisant des blocs d'auto-attention, des blocs d'attention croisée et des blocs MLP pour extraire des fonctionnalités.
Dans la couche de sortie, utilisez un MLP pour convertir chaque image masquée intégrée en un ensemble de logits (correspondant à la taille du livre de codes VQGAN) et utilisez la perte d'entropie croisée pour cibler le jeton de vérité terrain.
Dans la phase de formation, l'objectif de formation du modèle de base est de prédire tous les jetons msked à chaque étape ; mais dans la phase d'inférence, la prédiction du masque est effectuée de manière itérative, ce qui peut grandement améliorer la qualité.
4. Modèle de super-résolution
Les chercheurs ont découvert que la prédiction directe des images à une résolution de 512 × 512 a amené le modèle à se concentrer sur les détails de bas niveau plutôt que sur la sémantique de haut niveau.
Utiliser une cascade de modèles peut améliorer cette situation :
Utiliser d'abord un modèle de base qui génère une carte latente 16×16 (correspondant à une image 256×256 puis un modèle Rate super-résolution, suréchantillonner) ; la carte latente de base à 64×64 (correspondant à une image 512×512). Le modèle super-résolution est formé une fois la formation de base du modèle terminée.
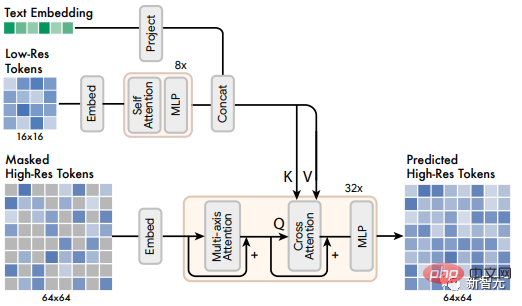
Comme mentionné précédemment, les chercheurs ont formé un total de deux modèles VQGAN, l'un avec une résolution latente de 16 × 16 et une résolution spatiale de 256 × 256, et l'autre avec une résolution latente de 64 × 64 et une résolution spatiale de 512 × 512. .
Étant donné que le modèle de base génère un jeton correspondant à la carte latente 16×16, le module de super-résolution apprend à « traduire » la carte latente basse résolution en une carte latente haute résolution, puis transmet la carte latente haute résolution. résolution VQGAN Decode pour obtenir l'image finale haute résolution ; le modèle de traduction est également entraîné avec le conditionnement du texte et l'attention croisée d'une manière similaire au modèle de base.
5. Mise au point du décodeur
Afin d'améliorer encore la capacité du modèle à générer des détails, les chercheurs ont choisi d'augmenter la capacité du décodeur VQGAN en ajoutant davantage de couches et de canaux résiduels tout en gardant la capacité de l'encodeur inchangée.
Ensuite, affinez le nouveau décodeur tout en gardant inchangés les poids, le livre de codes et les transformateurs (c'est-à-dire le modèle de base et le modèle super-résolution) de l'encodeur VQGAN. Cette approche améliore la qualité visuelle des images générées sans qu'il soit nécessaire de recycler d'autres composants du modèle (car les jetons visuels restent fixes).

Comme on peut le constater, le décodeur a été affiné pour reconstruire des détails plus nombreux et plus clairs.
6. Taux de masquage variable#🎜🎜 #
# 🎜🎜#Les chercheurs utilisent des taux de masque variables basés sur la planification Csoine pour entraîner le modèle : pour chaque exemple d'entraînement, un taux de masque r∈[0, 1] est tiré de la distribution arccos tronquée, sa fonction de densité est la suivante. 🎜#
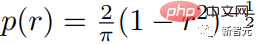 La valeur attendue du taux de masquage est de 0,64, ce qui signifie que des valeurs plus élevées sont préférées. le problème de prédiction est plus difficile.
La valeur attendue du taux de masquage est de 0,64, ce qui signifie que des valeurs plus élevées sont préférées. le problème de prédiction est plus difficile.
Les taux de masquage aléatoires sont non seulement cruciaux pour les schémas d'échantillonnage parallèles, mais permettent également certaines fonctionnalités d'édition dispersées et prêtes à l'emploi. Guide sans classification (CFG) 🎜#
Les chercheurs utilisent le guidage sans classification (CFG) pour améliorer la qualité de la génération d'images et l'alignement texte-image.Pendant la formation, les conditions de texte sont supprimées de 10 % des échantillons sélectionnés au hasard et le mécanisme d'attention est réduit à l'auto-attention du jeton d'image lui-même.
Dans la phase d'inférence, un logit conditionnel lc et un logit inconditionnel lu sont calculés pour chaque jeton masqué, puis utilisés comme guide en supprimant un montant t du échelle logit inconditionnelle pour former le logit lg final :
Intuitivement, CFG troque la diversité contre la fidélité. Mais différent du précédent. méthodes, Muse augmente linéairement l'échelle de guidage t tout au long du processus d'échantillonnage pour réduire la perte de diversité, de sorte que les premiers jetons puissent être échantillonnés plus librement sous un guidage faible ou sans guidage, mais cela augmente également le besoin d'invites conditionnelles ultérieures. .
Les chercheurs ont également profité de ce mécanisme en remplaçant le logit inconditionnel lu par un logit conditionné à l'invite négative, ce qui a facilité la génération d'images avec des invites positives liées fonctionnalité.
8. Décodage parallèle itératif lors de l'inférence
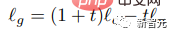
En améliorant le Un élément clé de l'efficacité du temps d'inférence est l'utilisation du décodage parallèle pour prédire plusieurs jetons de sortie dans un seul canal aller, l'hypothèse clé étant la propriété de Markov selon laquelle de nombreux jetons sont conditionnellement indépendants compte tenu des autres jetons.
Le décodage est effectué selon le programme cosinus, et le masque avec la plus grande confiance dans une proportion fixe est sélectionné pour la prédiction, où le jeton est défini pour être démasqué dans les étapes restantes et réduisez de manière appropriée les jetons masqués.
Selon le processus ci-dessus, seules 24 étapes de décodage peuvent être utilisées pour obtenir l'inférence de 256 jetons dans le modèle de base, dans le modèle super-résolution, 8 étapes de décodage. effectuez une inférence sur 4096 jetons, contre 256 ou 4096 étapes pour le modèle autorégressif et des centaines d'étapes pour le modèle de diffusion. Bien que certaines recherches récentes, notamment la distillation progressive et un meilleur solveur ODE, aient considérablement réduit les étapes d'échantillonnage des modèles de diffusion, ces méthodes n'ont pas été largement validées dans la génération de texte en image à grande échelle. Les chercheurs ont formé une série de modèles de base de Transformer basés sur T5-XXL avec différentes quantités de paramètres (de 600M à 3B). La qualité des images générées L'expérience a testé la capacité du modèle Muse à gérer des invites textuelles avec différents attributs, y compris une compréhension de base de la cardinalité. Pour les objets non singuliers, Muse n'a pas généré le même texte. plusieurs fois. Pixels de l'objet, mais ajoute des changements de contexte, rendant l'image entière plus réaliste. Par exemple, la taille et la direction de l'éléphant, la couleur de l'emballage de la bouteille de vin, la rotation de la balle de tennis, etc. Comparaison quantitative Les chercheurs ont mené des comparaisons expérimentales avec d'autres méthodes de recherche sur les ensembles de données CC3M et COCO. Les mesures incluent la distance de démarrage de Frechet (FID), qui mesure la qualité et la diversité des échantillons, et le score image/CLIP pour. alignement du texte. Les résultats expérimentaux prouvent que le modèle 632M Muse obtient des résultats SOTA sur CC3M, améliorant le score FID, tout en obtenant également un score CLIP de pointe. Sur l'ensemble de données MS-COCO, le modèle 3B a obtenu un score FID de 7,88, ce qui est légèrement meilleur que le 8,1 obtenu par le modèle Parti-3B avec des quantités de paramètres similaires. Résultats expérimentaux

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI