
Maison >développement back-end >Tutoriel Python >Comment Python Vaex peut analyser rapidement un volume de données important de 100 Go
Comment Python Vaex peut analyser rapidement un volume de données important de 100 Go

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-13 08:34:051419parcourir
Limitations des pandas dans le traitement du Big Data
De nos jours, la quantité de données fournies par les compétitions de science des données augmente, allant de dizaines de gigaoctets à des centaines de gigaoctets, qui testent les performances des machines et les capacités de traitement des données.
Pandas en Python est un outil de traitement de données couramment utilisé. Il peut gérer des ensembles de données plus volumineux (des dizaines de millions de lignes). Cependant, lorsque le volume de données atteint le niveau de milliards ou de milliards de lignes, Pandas est un peu incapable de gérer. On peut dire que c'est très lent.
Il existe des facteurs de performance tels que la mémoire de l'ordinateur, mais le mécanisme de traitement des données du panda (qui repose sur la mémoire) limite également sa capacité à traiter le Big Data.
Bien sûr, les pandas peuvent lire les données par lots via des morceaux, mais l'inconvénient est que le traitement des données est plus complexe et que chaque étape de l'analyse consomme de la mémoire et du temps.
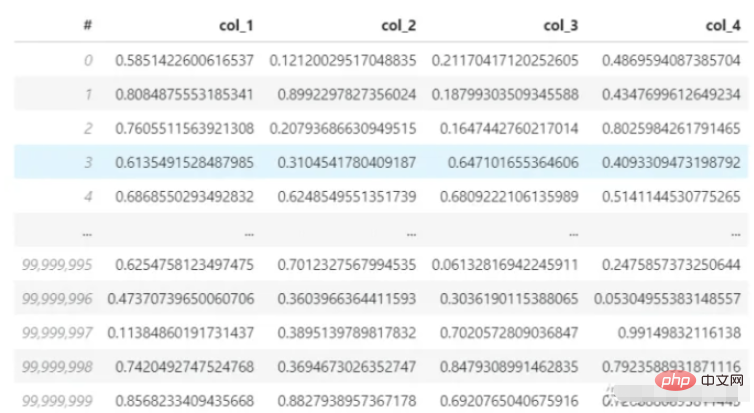
Ensuite, utilisez pandas pour lire un ensemble de données 3,7G (format hdf5). L'ensemble de données comporte 4 colonnes et 100 millions de lignes, et calculez la moyenne de la première ligne. Le processeur de mon ordinateur est un i7-8550U et la mémoire est de 8 Go. Voyons combien de temps prend ce processus de chargement et de calcul.
Ensemble de données :
Utilisez des pandas pour lire et calculer :
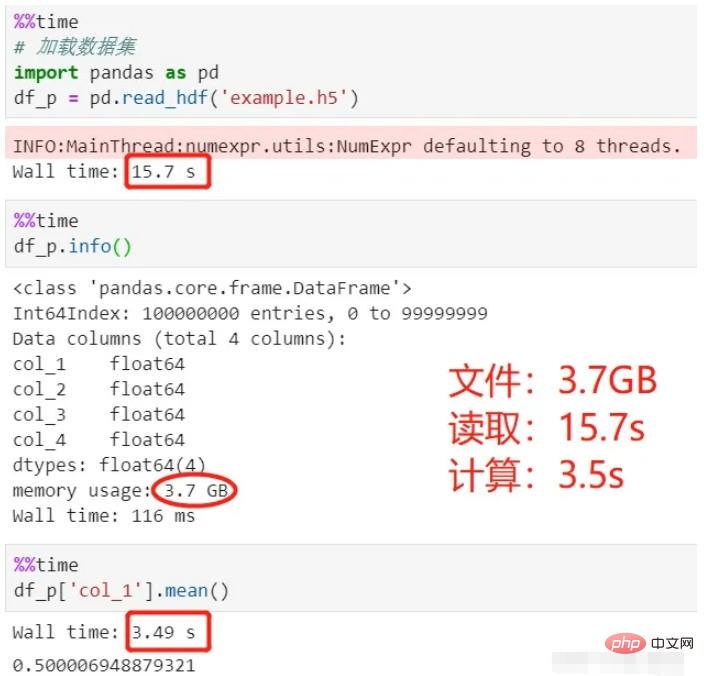
En regardant le processus ci-dessus, il a fallu 15 secondes pour charger les données et 3,5 secondes pour calculer la moyenne, pour un total de 18,5 secondes .
Le fichier hdf5 utilisé ici est un format de stockage de fichiers Par rapport au csv, il est plus adapté au stockage de grandes quantités de données, a un degré de compression élevé et est plus rapide à lire et à écrire.
Passez au vaex protagoniste d'aujourd'hui, lisez les mêmes données et faites le même calcul moyen. Combien de temps cela prendra-t-il ?
Utilisez vaex pour lire et calculer :
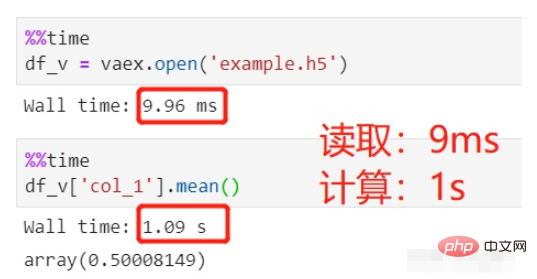
La lecture du fichier a pris 9 ms, ce qui est négligeable, et le calcul moyen a pris 1 s, soit un total de 1 s.
Le même ensemble de données HDFS avec 100 millions de lignes est lu. Pourquoi les pandas prennent-ils plus de dix secondes, alors que vaex en prend près de 0 ?
C'est principalement parce que les pandas lisent les données en mémoire et les utilisent ensuite pour le traitement et le calcul. Vaex mappera uniquement les données en mémoire au lieu de les lire réellement dans la mémoire. C'est la même chose que le chargement paresseux de Spark. Il sera chargé lorsqu'il est utilisé et non lorsqu'il est déclaré.
Donc, quelle que soit la taille des données chargées, 10 Go, 100 Go... cela peut être fait instantanément pour vaex. Le problème est que le chargement paresseux de Vaex ne prend en charge que HDF5, Apache Arrow, Parquet, FITS et d'autres fichiers, mais ne prend pas en charge les fichiers texte tels que CSV, car les fichiers texte ne peuvent pas être mappés en mémoire.
Certains amis peuvent ne pas bien comprendre le mappage mémoire. Voici une explication Pour connaître les détails, vous devez explorer par vous-même :
Le mappage mémoire fait référence à l'emplacement du fichier sur le disque dur et à une zone de celui-ci. la même taille dans l'espace d'adressage logique du processus. Cette correspondance est un concept purement logique et n'existe pas physiquement. La raison en est que l'espace d'adressage logique du processus lui-même n'existe pas. Dans le processus de mappage de la mémoire, il n'y a pas de copie réelle des données. Le fichier n'est pas chargé dans la mémoire, mais est logiquement placé dans la mémoire. Spécifique au code, la structure de données appropriée (struct adresse_espace) est établie et initialisée.
Qu'est-ce que vaex
J'ai comparé la vitesse de traitement du big data entre vaex et pandas, et vaex présente des avantages évidents. Bien que ses capacités soient exceptionnelles et qu'il ne soit pas aussi connu que les pandas, le vaex est encore un nouveau venu qui vient tout juste de sortir de l'industrie.
vaex est également une bibliothèque tierce de traitement de données basée sur python, qui peut être installée à l'aide de pip.
L'introduction de vaex sur le site officiel peut être résumée en trois points :
vaex est un outil de table de données pour le traitement et l'affichage des données, similaire aux pandas
vaex adopte le mappage de mémoire et le calcul paresseux, le fait ; n'occupe pas de mémoire et convient au traitement du Big Data ;
vaex peut effectuer une analyse statistique de deuxième niveau et un affichage visuel sur des dizaines de milliards d'ensembles de données ; données massives, 109 lignes/seconde ;
Lazy : calculs rapides, pas d'utilisation de mémoire
Zéro copie de mémoire : pas de copie de mémoire lors du filtrage/transformation/calcul, streaming en cas de besoin
Visualisation : à l'intérieur ; Contient des composants visuels ;
API : similaire aux pandas, avec de riches fonctions de traitement de données et de calcul ;
Interactif : utilisé avec le notebook Jupyter, visualisation interactive flexible ; conda :
- Lire les données
- vaex prend en charge la lecture de fichiers hdf5, csv, parquet et autres, en utilisant la méthode de lecture. hdf5 peut être lu paresseusement, tandis que csv ne peut être lu qu'en mémoire.
Fonction de lecture de données Vaex :
Traitement des données
Parfois, nous devons effectuer diverses transformations, criblage, calculs, etc. sur les données. Chaque étape du traitement des pandas consomme de la mémoire et prend du temps. À moins que vous n'utilisiez le traitement en chaîne, le processus est très flou.
vaex n'utilise aucune mémoire tout au long du processus. Parce que son traitement génère uniquement une expression, qui est une représentation logique et ne sera pas exécutée. Elle ne sera exécutée que lors de l'étape de génération du résultat final. De plus, les données de l’ensemble du processus sont diffusées en continu et il n’y aura pas d’arriéré de mémoire.
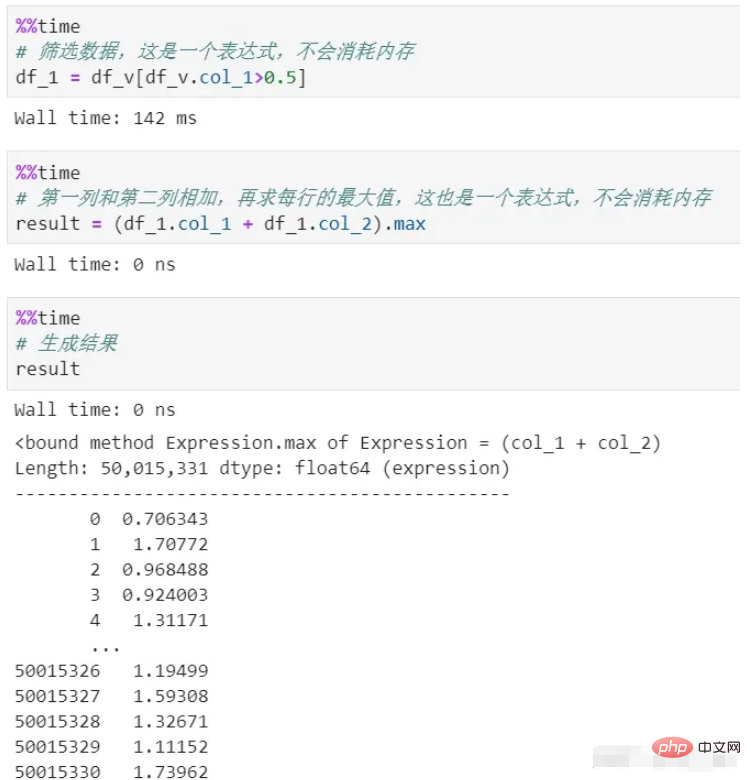
Vous pouvez voir qu'il existe deux processus de filtrage et de calcul, dont aucun ne copie la mémoire. Le calcul différé est utilisé ici, ce qui est un mécanisme paresseux. Si chaque processus est réellement calculé, sans parler de la consommation de mémoire, le coût en temps à lui seul sera énorme.
Fonction de calcul statistique de Vaex :
Affichage visuel
vaex peut également effectuer un affichage visuel rapide, même avec des dizaines de milliards d'ensembles de données, il peut toujours produire des graphiques en quelques secondes.
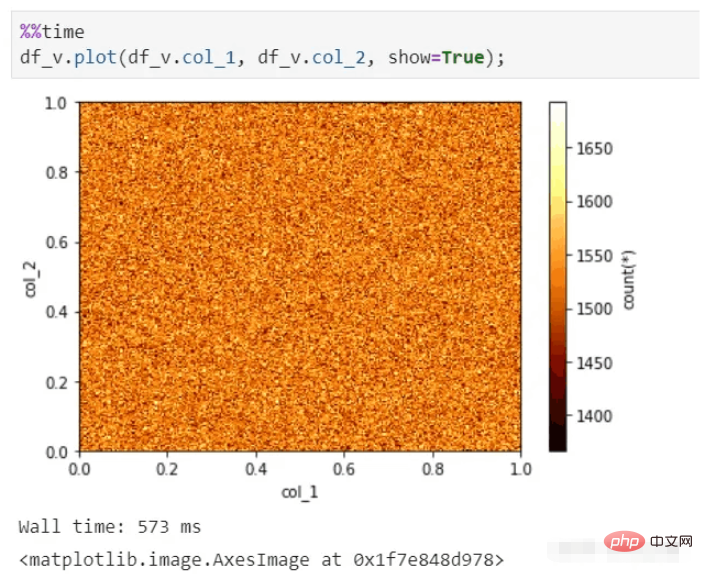
Fonction de visualisation vaex :

Conclusion
vaex est quelque peu similaire à une combinaison d'étincelle et de pandas. Plus la quantité de données est grande, plus ses avantages peuvent être reflétés. Tant que votre disque dur peut contenir autant de données qu’il en a besoin, il peut les analyser rapidement.
vaex continue de se développer rapidement, intégrant de plus en plus de fonctions pandas. Son nombre d'étoiles sur github est de 5k et son potentiel de croissance est énorme.
Pièce jointe : code de génération de l'ensemble de données hdf5 (4 colonnes et 100 millions de lignes de données)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
Veuillez noter que n'utilisez pas de pandas pour générer directement hdf5 ici, car son format sera incompatible avec vaex.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!