
Maison >Périphériques technologiques >IA >Contrôler un bras robotique à double articulation à l'aide de l'algorithme d'apprentissage par renforcement DDPG d'Actor-Critic
Contrôler un bras robotique à double articulation à l'aide de l'algorithme d'apprentissage par renforcement DDPG d'Actor-Critic

- 王林avant
- 2023-05-12 21:55:17956parcourir
Dans cet article, nous présenterons la formation d'un agent intelligent pour contrôler un bras robotique à double articulation dans l'environnement Reacher, un programme de simulation basé sur Unity développé à l'aide de la boîte à outils Unity ML-Agents. Notre objectif est d'atteindre la position cible avec une grande précision, nous pouvons donc utiliser ici l'algorithme de pointe DDPG (Deep Deterministic Policy Gradient) conçu pour les espaces d'état et d'action continus.

Applications du monde réel
Les bras robotiques sont utilisés dans la fabrication, les installations de production, l'exploration spatiale et les opérations de recherche et de sauvetage. . Il est très important de contrôler le bras du robot avec une grande précision et flexibilité. En employant des techniques d'apprentissage par renforcement, ces systèmes robotiques peuvent être en mesure d'apprendre et d'ajuster leur comportement en temps réel, améliorant ainsi les performances et la flexibilité. Les progrès en matière d’apprentissage par renforcement contribuent non seulement à notre compréhension de l’intelligence artificielle, mais ont également le potentiel de révolutionner les industries et d’avoir un impact significatif sur la société.
Reacher est un simulateur de bras robotique qui est souvent utilisé pour le développement et les tests d'algorithmes de contrôle. Il fournit un environnement virtuel qui simule les caractéristiques physiques et les lois de mouvement du bras robotique, permettant aux développeurs de mener des recherches et des expériences sur des algorithmes de contrôle sans avoir besoin de matériel réel.
L'environnement de Reacher se compose principalement des parties suivantes :
- Bras robotique : Reacher simule un bras robotique à double articulation, comprenant une base fixe et deux articulations mobiles. Les développeurs peuvent modifier l'attitude et la position du bras robotique en contrôlant ses deux articulations.
- Point cible : dans la plage de mouvement du bras robotique, Reacher fournit un point cible et la position du point cible est générée aléatoirement. La tâche du développeur est de contrôler le bras robotique afin que l'extrémité du bras robotique puisse toucher le point cible.
- Moteur physique : Reacher utilise un moteur physique pour simuler les caractéristiques physiques et les schémas de mouvement du bras robotique. Les développeurs peuvent simuler différents environnements physiques en ajustant les paramètres du moteur physique.
- Interface visuelle : Reacher fournit une interface visuelle qui peut afficher les positions du bras robotique et les points cibles, ainsi que la posture et la trajectoire de mouvement du bras robotique. Les développeurs peuvent déboguer et optimiser les algorithmes de contrôle via une interface visuelle.
Le simulateur Reacher est un outil très pratique qui peut aider les développeurs à tester et à optimiser rapidement les algorithmes de contrôle sans avoir besoin de matériel réel.
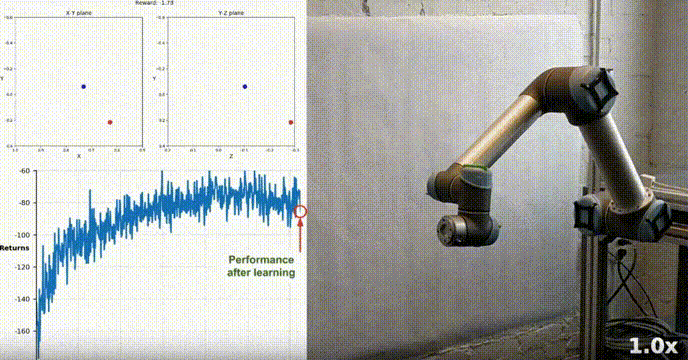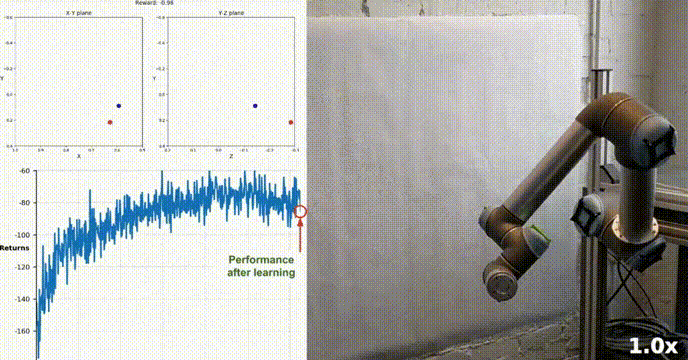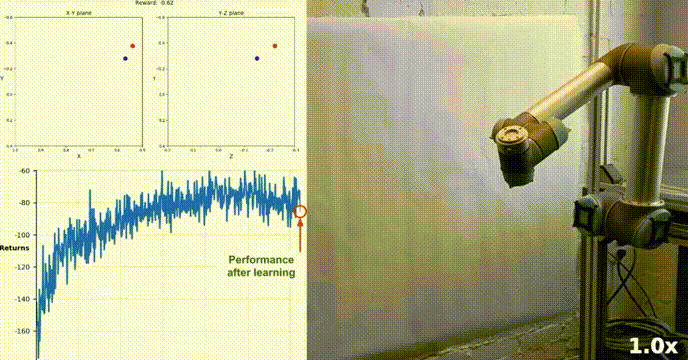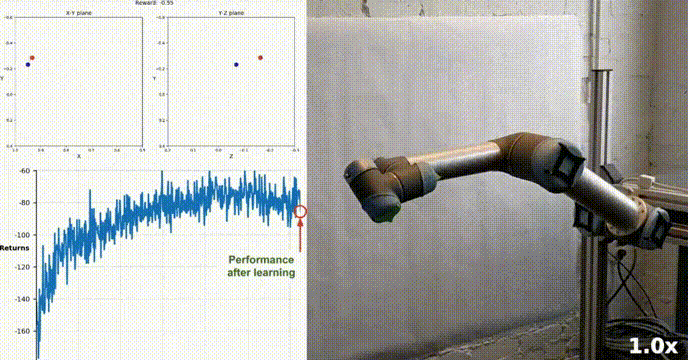
Simulation Environment
Reacher est construit à l'aide de la boîte à outils Unity ML-Agents, notre agent peut contrôler un robot à double articulation bras. Le but est de guider le bras vers la position cible et de maintenir sa position dans la zone cible le plus longtemps possible. L'environnement comprend 20 agents synchronisés, chacun fonctionnant indépendamment, ce qui permet de collecter efficacement l'expérience pendant la formation.

État et espace d'action
Comprendre l'état et l'espace d'action est une amélioration efficace pour conception L'apprentissage des algorithmes est crucial. Dans l'environnement Reacher, l'espace d'état se compose de 33 variables continues qui fournissent des informations sur le bras robotique, telles que sa position, sa rotation, sa vitesse et sa vitesse angulaire. L'espace d'action est également continu, avec quatre variables correspondant aux couples exercés sur les deux articulations du bras robotique. Chaque variable d'action est un nombre réel compris entre -1 et 1.
Types de tâches et critères de réussite
Reacher Les tâches sont considérées comme épisodiques, chaque fragment contenant un nombre fixe de pas de temps. L'objectif de l'agent est de maximiser sa récompense totale au cours de ces étapes. L'effecteur du bras reçoit un bonus de +0,1 pour chaque pas nécessaire pour maintenir la position cible. Le succès est considéré lorsqu'un agent atteint un score moyen de 30 points ou plus sur 100 opérations consécutives.
Comprendre l'environnement, nous explorerons ci-dessous l'algorithme DDPG, sa mise en œuvre et la manière dont il résout efficacement les problèmes de contrôle continu dans cet environnement.
Sélection d'algorithmes pour le contrôle continu : DDPG
Lorsqu'il s'agit de tâches de contrôle continu comme le problème Reacher, le choix de l'algorithme est essentiel pour obtenir des performances optimales. Dans ce projet, nous avons choisi l'algorithme DDPG car il s'agit d'une méthode acteur-critique spécifiquement conçue pour gérer des espaces d'état et d'action continus.
L'algorithme DDPG combine les avantages des approches basées sur les politiques et basées sur les valeurs en combinant deux réseaux de neurones : le réseau d'acteurs détermine le meilleur comportement compte tenu de l'état actuel, et le réseau critique (Critic network) estime la fonction valeur état-comportement (fonction Q). Les deux types de réseaux ont des réseaux cibles qui stabilisent le processus d'apprentissage en fournissant une cible fixe pendant le processus de mise à jour.
En utilisant le réseau Critic pour estimer la fonction q et le réseau Actor pour déterminer le comportement optimal, l'algorithme DDPG combine efficacement les avantages de la méthode du gradient politique et du DQN. Cette approche hybride permet aux agents d'apprendre efficacement dans un environnement de contrôle continu.
<code>import random from collections import deque import torch import torch.nn as nn import numpy as np from actor_critic import Actor, Critic class ReplayBuffer: def __init__(self, buffer_size, batch_size): self.memory = deque(maxlen=buffer_size) self.batch_size = batch_size def add(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def sample(self): batch = random.sample(self.memory, self.batch_size) states, actions, rewards, next_states, dones = zip(*batch) return states, actions, rewards, next_states, dones def __len__(self): return len(self.memory) class DDPG: def __init__(self, state_dim, action_dim, hidden_dim, buffer_size, batch_size, actor_lr, critic_lr, tau, gamma): self.actor = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.actor_target = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.critic = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.critic_target = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.memory = ReplayBuffer(buffer_size, batch_size) self.batch_size = batch_size self.tau = tau self.gamma = gamma self._update_target_networks(tau=1)# initialize target networks def act(self, state, noise=0.0): state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) action = self.actor(state).detach().numpy()[0] return np.clip(action + noise, -1, 1) def store_transition(self, state, action, reward, next_state, done): self.memory.add(state, action, reward, next_state, done) def learn(self): if len(self.memory) </code>
Le code ci-dessus utilise également Replay Buffer, qui peut améliorer l'efficacité et la stabilité de l'apprentissage. Replay Buffer est essentiellement une structure de données de mémoire qui stocke un nombre fixe d'expériences ou de transitions passées, comprenant des informations sur le statut, l'action, la récompense, le statut suivant et l'achèvement. Le principal avantage de son utilisation est de permettre à l’agent de rompre les corrélations entre expériences consécutives, réduisant ainsi l’impact des corrélations temporelles néfastes.
En tirant des mini-lots aléatoires d'expérience à partir du tampon, l'agent peut apprendre d'un ensemble différent de transformations, ce qui contribue à stabiliser et à généraliser le processus d'apprentissage. Les tampons de relecture permettent également aux agents de réutiliser plusieurs fois leurs expériences passées, augmentant ainsi l'efficacité des données et favorisant un apprentissage plus efficace à partir d'interactions limitées avec l'environnement.
L'algorithme DDPG est un bon choix en raison de sa capacité à gérer efficacement des espaces d'action continus, ce qui est un aspect clé dans cet environnement. La conception de l'algorithme permet une utilisation efficace de l'expérience parallèle recueillie par plusieurs agents, ce qui entraîne un apprentissage plus rapide et une meilleure convergence. Tout comme le Reacher présenté ci-dessus, il peut exécuter 20 agents en même temps, nous pouvons donc utiliser ces 20 agents pour partager des expériences, apprendre collectivement et augmenter la vitesse d'apprentissage.
L'algorithme est terminé. Nous présenterons ensuite le processus de sélection et de formation des hyperparamètres.
L'algorithme DDPG fonctionne dans l'environnement Reacher
Pour mieux comprendre l'efficacité de l'algorithme dans l'environnement, nous devons examiner de plus près les composants et les étapes clés impliqués dans le processus d'apprentissage.
Architecture réseau
L'algorithme DDPG utilise deux réseaux de neurones, Acteur et Critique. Les deux réseaux contiennent deux couches cachées, chacune contenant 400 nœuds. La couche cachée utilise la fonction d'activation ReLU (Rectified Linear Unit), tandis que la couche de sortie du réseau Actor utilise la fonction d'activation tanh pour générer des actions allant de -1 à 1. La couche de sortie du réseau critique n’a pas de fonction d’activation car elle estime directement la fonction q.
Voici le code du réseau :
<code>import numpy as np import torch import torch.nn as nn import torch.optim as optim class Actor(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim, learning_rate=1e-4): super(Actor, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, output_dim) self.tanh = nn.Tanh() self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) x = self.tanh(self.fc3(x)) return x class Critic(nn.Module): def __init__(self, state_dim, action_dim, hidden_dim, learning_rate=1e-4): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim + action_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1) self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state, action): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(torch.cat([x, action], dim=1))) x = self.fc3(x) return x</code>
Sélection des hyperparamètres
Les hyperparamètres sélectionnés sont cruciaux pour un apprentissage efficace. Dans ce projet, la taille de notre tampon de relecture est de 200 000 et la taille du lot est de 256. Le taux d'apprentissage de l'acteur est de 5e-4, le taux d'apprentissage du critique est de 1e-3, le paramètre de mise à jour logicielle (tau) est de 5e-3 et le gamma est de 0,995. Enfin, le bruit d'action a été ajouté, avec une échelle de bruit initiale de 0,5 et un taux d'atténuation du bruit de 0,998.
Processus de formation
Le processus de formation implique une interaction continue entre les deux réseaux, et avec 20 agents parallèles partageant le même réseau, le modèle apprend collectivement de l'expérience collectée par tous les agents. Cette configuration accélère le processus d’apprentissage et augmente l’efficacité.
<code>from collections import deque import numpy as np import torch from ddpg import DDPG def train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.1, noise_decay=0.99): scores_window = deque(maxlen=100) scores = [] for episode in range(1, episodes + 1): env_info = env.reset(train_mode=True)[brain_name] states = env_info.vector_observations agent_scores = np.zeros(num_agents) for step in range(max_steps): actions = agent.act(states, noise_scale) env_info = env.step(actions)[brain_name] next_states = env_info.vector_observations rewards = env_info.rewards dones = env_info.local_done for i in range(num_agents): agent.store_transition(states[i], actions[i], rewards[i], next_states[i], dones[i]) agent.learn() states = next_states agent_scores += rewards noise_scale *= noise_decay if np.any(dones): break avg_score = np.mean(agent_scores) scores_window.append(avg_score) scores.append(avg_score) if episode % 10 == 0: print(f"Episode: {episode}, Score: {avg_score:.2f}, Avg Score: {np.mean(scores_window):.2f}") # Saving trained Networks torch.save(agent.actor.state_dict(), "actor_final.pth") torch.save(agent.critic.state_dict(), "critic_final.pth") return scores if __name__ == "__main__": env = UnityEnvironment(file_name='Reacher_20.app') brain_name = env.brain_names[0] brain = env.brains[brain_name] state_dim = 33 action_dim = brain.vector_action_space_size num_agents = 20 # Hyperparameter suggestions hidden_dim = 400 batch_size = 256 actor_lr = 5e-4 critic_lr = 1e-3 tau = 5e-3 gamma = 0.995 noise_scale = 0.5 noise_decay = 0.998 agent = DDPG(state_dim, action_dim, hidden_dim=hidden_dim, buffer_size=200000, batch_size=batch_size,actor_lr=actor_lr, critic_lr=critic_lr, tau=tau, gamma=gamma) episodes = 200 max_steps = 1000 scores = train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.2, noise_decay=0.995)</code>
Les étapes clés du processus de formation sont les suivantes :
Initialiser le réseau : l'agent initialise les réseaux d'acteurs et de critiques partagés ainsi que leurs réseaux cibles respectifs avec des poids aléatoires. Le réseau cible fournit des cibles d'apprentissage stables lors des mises à jour.
- Interagir avec l'environnement : chaque agent utilise un réseau d'acteurs partagé pour interagir avec l'environnement en sélectionnant des actions en fonction de son état actuel. Pour encourager l'exploration, un terme de bruit est également ajouté aux actions dans les premières étapes de la formation. Après avoir effectué une action, chaque agent observe la récompense qui en résulte et l'état suivant.
- Stockage de l'expérience : chaque agent stocke l'expérience observée (état, action, récompense, next_state) dans un tampon de relecture partagé. Ce tampon contient une quantité fixe d'expérience récente afin que chaque agent puisse apprendre des différentes transitions collectées par tous les agents.
- Apprendre de l'expérience : tirez périodiquement un lot d'expériences du tampon de relecture partagé. Utilisez l’expérience d’échantillonnage pour mettre à jour le réseau critique partagé en minimisant l’erreur quadratique moyenne entre la valeur Q prévue et la valeur Q cible.
- Mettre à jour le réseau d'acteurs : le réseau d'acteurs partagé est mis à jour à l'aide du gradient de politique, qui est calculé en prenant le gradient de sortie du réseau de critiques partagé par rapport à l'action sélectionnée. Le réseau d'acteurs partagés apprend à choisir des actions qui maximisent la valeur Q attendue.
- Mettre à jour le réseau cible : les réseaux cibles partagés des acteurs et des critiques sont mis à jour en douceur en utilisant un mélange de pondérations de réseau actuelles et cibles. Cela garantit un processus d’apprentissage stable.
Affichage des résultats
Notre agent a appris avec succès à contrôler un bras robotique à double articulation dans l'environnement Racher en utilisant l'algorithme DDPG. Tout au long du processus de formation, nous surveillons les performances de l'agent en fonction du score moyen des 20 agents. À mesure que l’agent explore l’environnement et acquiert de l’expérience, sa capacité à prédire un comportement optimal pour maximiser la récompense s’améliore considérablement.
On peut voir que l'agent a montré une maîtrise significative de la tâche, le score moyen dépassant le seuil requis pour résoudre l'environnement (30+). Bien que les performances de l'agent aient varié tout au long du processus de formation, la tendance est globale. vers le haut, indiquant que le processus d’apprentissage est réussi.
Le graphique ci-dessous montre le score moyen de 20 agents :
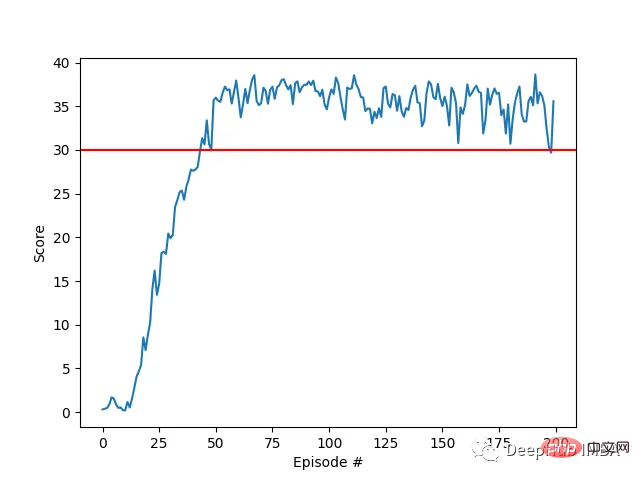
Vous pouvez voir que l'algorithme DDPG que nous avons implémenté a résolu efficacement le problème de l'environnement Racher. Les agents sont capables d'ajuster leur comportement et d'atteindre les performances attendues dans les tâches.
Prochaines étapes
Les hyperparamètres de ce projet ont été sélectionnés sur la base d'une combinaison de recommandations de la littérature et de tests empiriques. Une optimisation plus poussée grâce au réglage des hyperparamètres du système peut conduire à de meilleures performances.
Formation parallèle multi-agents : Dans ce projet, nous utilisons 20 agents pour collecter de l'expérience en même temps. L'impact de l'utilisation d'un plus grand nombre d'agents sur le processus d'apprentissage global peut entraîner une convergence plus rapide ou une amélioration des performances.
Normalisation par lots : pour améliorer davantage le processus d'apprentissage, la mise en œuvre de la normalisation par lots dans les architectures de réseaux neuronaux mérite d'être explorée. En normalisant les caractéristiques d'entrée de chaque couche pendant la formation, la normalisation par lots peut aider à réduire les changements de covariables internes, à accélérer l'apprentissage et potentiellement à améliorer la généralisation. L'ajout d'une normalisation par lots aux réseaux Actor et Critic peut conduire à une formation plus stable et plus efficace, mais cela nécessite des tests supplémentaires.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI