
Maison >développement back-end >Tutoriel Python >Comment écrire un simple JSONParser en utilisant Python
Comment écrire un simple JSONParser en utilisant Python

- WBOYavant
- 2023-05-12 14:58:061194parcourir
JSON Tokenizer
Analyse lexicale JSON, je me réfère principalement à la méthode dans la capture d'écran ci-dessus et j'ai moi-même écrit un exemple simple. Il est relativement simple à écrire, et il faut dire qu'il ne peut prendre en charge qu'un simple sous-ensemble de JSON.
Pour les types de TOKEN ici, reportez-vous à https://json.org, mais son format de syntaxe JSON comporte des espaces. Je n'ai pas l'habitude de gérer cela, donc je n'ai pas fait référence à sa syntaxe. Après l'analyse lexicale, les espaces, les nouvelles lignes et les tabulations sont filtrés, je les supprime simplement sans les traiter.
json_tokenizer.py
Utilisez des expressions régulières pour effectuer une analyse lexicale de JSON.
import json
import re
from typing import Dict, List, Union
# TOKEN 的种类
LEFT_BRACE = "LEFT_BRACE" # {
RIGHT_BRACE = "RIGHT_BRACE" # }
LEFT_BRACKET = "LEFT_BRACKET" # ]
RIGHT_BRACKET = "RIGHT_BRACKET" # [
COLON = "COLON" # :
COMMA = "COMMA" # ,
NUMBER = "NUMBER" # ".*?"
STRING = "STRING" # [1-9]\d*
BOOL = "BOOL" # true/false
NULL = "NULL" # null
NEWLINE = "NEWLINE" # \n
SKIP = "SKIP" # ' ', '\t'
MISMATCH = "MISMATCH" # mismatch
# 处理 token 的正则
token_specification = [
('LEFT_BRACE', r'[{]'),
('RIGHT_BRACE', r'[}]'),
('LEFT_BRACKET', r'[\[]'),
('RIGHT_BRACKET', r'[\]]'),
('COLON', r'[:]'),
('COMMA', r'[,]'),
('NUMBER', r'-?[1-9]+[0-9]*'),
('STRING', r'".*?"'),
('BOOL', r'(true)|(false)'),
('NULL', r'null'),
('NEWLINE', r'\n'),
('SKIP', r'[ \t]'),
('MISMATCH', r'.')
]
tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)
print("Debug: ", tok_regex)
def process(kind: str, value: str) -> Dict[str, Union[str, bool, int, None]]:
"""
处理输入的 kind 和 value,并生成 Dict 对象,简单表示 token 对象
"""
if kind == STRING:
# 去掉外层的双引号,暂时没有比较好的方式
return {"kind": kind, "value": value[1:-1]}
if kind == NUMBER:
return {"kind": kind, "value": int(value)}
if kind == BOOL:
if value == "true":
return {"kind": kind, "value": True}
else:
return {"kind": kind, "value": False}
if kind == NULL:
return {"kind": kind, "value": None}
return {"kind": kind, "value": value}
def tokenizer(json_str: str) -> List[Dict[str, Union[str, bool, int, None]]]:
"""
tokenizer
"""
tokens = []
for m in re.finditer(tok_regex, json_str):
# 获取 token 的类型
kind = m.lastgroup
# 获取 token 的值
value = m.group()
if kind == MISMATCH:
raise Exception("json format is error")
if kind == NEWLINE:
continue
if kind == SKIP:
continue
token = process(kind=kind, value=value)
tokens.append(token)
return tokens
if __name__ == "__main__":
json_doc = open("./demo.json", "r", encoding="utf-8").read()
tokens = tokenizer(json_doc)
if tokens:
json.dump(tokens, open("./json_tokens.json", "w",
encoding="utf-8"), ensure_ascii=False)J'ai mis toutes les données d'entrée et de sortie dans le document. Je publierai mes données d'entrée et une partie des données de sortie ci-dessous.
demo.json
{
"name": "小黑子",
"age": 3,
"gender": false,
"other_info": {
"friends": [
"嘎子",
"潘叔",
"狗"
],
"declaration": "练习时长两年半",
"hobbies": [
"唱",
"跳",
"rap",
"篮球????"
]
}
}json_token.json Une partie des données j'ai formaté les données, elles sont donc relativement longues. En voici seulement une partie.
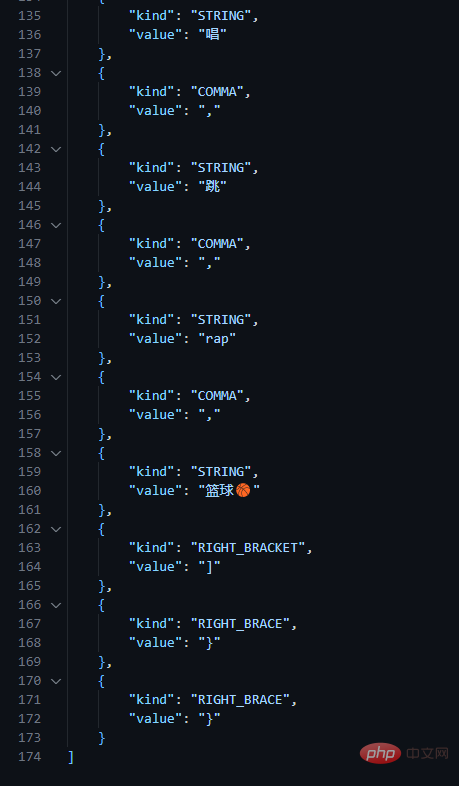
JSON Parser
json_parser.py
Analysez la séquence de jetons générée à l'étape précédente et générez l'objet Dict correspondant à JSON. L'implémentation de l'analyseur fait référence au fichier de syntaxe json d'antlr4, qui supprime les espaces et est plus simple à traiter.
import json
from typing import Dict, Union
# TOKEN 的种类
LEFT_BRACE = "LEFT_BRACE" # {
RIGHT_BRACE = "RIGHT_BRACE" # }
LEFT_BRACKET = "LEFT_BRACKET" # ]
RIGHT_BRACKET = "RIGHT_BRACKET" # [
COLON = "COLON" # :
COMMA = "COMMA" # ,
NUMBER = "NUMBER" # ".*?"
STRING = "STRING" # [1-9]\d*
BOOL = "BOOL" # true/false
NULL = "NULL" # null
class Token(object):
"""为了简单,就不创建这个了"""
class JSON_Parser(object):
"""
JSON_Parser the class aims parse input token sequence into a python object or array.
"""
def __init__(self, tokens) -> None:
self.index = 0
self.tokens = tokens
def get_token(self) -> Dict[str, Union[str, int, bool, None]]:
"""
get current's token
"""
if self.index < len(self.tokens):
return self.tokens[self.index]
else:
raise Exception("index out of range.")
def move_token(self) -> Dict[str, Union[str, int, bool, None]]:
"""
move to next token and return it
"""
if self.index + 1 < len(self.tokens):
self.index = self.index + 1
return self.tokens[self.index]
else:
raise Exception("index out of range.")
def parse(self):
"""
parse whole json
"""
token = self.get_token()
if token.get("kind") == LEFT_BRACE:
return self.parse_obj()
elif token.get("kind") == LEFT_BRACKET:
return self.parse_arr()
else:
raise Exception("error json, neither object or array.")
def parse_obj(self):
"""
parse object
"""
obj = {}
token = self.move_token()
kind = token.get("kind")
# '{' '}'
if kind == RIGHT_BRACE:
return obj
# '{' pair (',' pair)* '}'
name, val = self.parse_pair()
obj[name] = val
while self.index < len(self.tokens):
token = self.move_token()
kind = token.get("kind")
if kind == COMMA:
self.move_token()
name, val = self.parse_pair()
obj[name] = val
elif kind == RIGHT_BRACE:
return obj
else:
raise Exception("parse object encounter error")
def parse_arr(self):
"""
parse array
"""
arr = []
token = self.move_token()
kind = token.get("kind")
# '[' ']'
if kind == RIGHT_BRACE:
return arr
# '[' value (',' value)* ']'
val = self.parse_value()
arr.append(val)
while self.index < len(self.tokens):
token = self.move_token()
kind = token.get("kind")
if kind == COMMA:
self.move_token()
val = self.parse_value()
arr.append(val)
elif kind == RIGHT_BRACKET:
return arr
else:
raise Exception("parse array encounter error")
def parse_value(self):
"""
parse value
"""
token = self.get_token()
kind = token.get("kind")
if kind == LEFT_BRACE:
return self.parse_obj()
elif kind == LEFT_BRACKET:
return self.parse_arr()
elif kind == STRING or kind == NUMBER or kind == BOOL:
return token.get("value")
elif kind == NULL:
return
else:
raise Exception("encounter unexcepted token")
def parse_pair(self):
"""
parse pair
"""
token = self.get_token()
kind = token.get("kind")
name = token.get("value")
# STRING ':' value
if kind == STRING:
token = self.move_token()
kind = token.get("kind")
if kind == COLON:
token = self.move_token()
return name, self.parse_value()
raise Exception("parse pair encounter error")
if __name__ == "__main__":
# json token 文件路径
TOKEN_PATH = "./json_tokens.json"
# 读取 token 序列
input_tokens = [token for token in json.load(
open(TOKEN_PATH, "r", encoding="utf-8"))]
if not input_tokens:
raise Exception("input token sequence is empty")
# 调试的时候,用来查表的,很方便定位到 index 走到哪一个 token 了
for i, tok in enumerate(input_tokens):
print(f"debug {i:2d} --> {tok}")
print("\n===========================================\n")
parser = JSON_Parser(tokens=input_tokens)
json_obj = parser.parse()
# 再将 object 转成 json 并格式化后输出
print(json.dumps(json_obj, ensure_ascii=False, indent=4))Résultat de sortie :
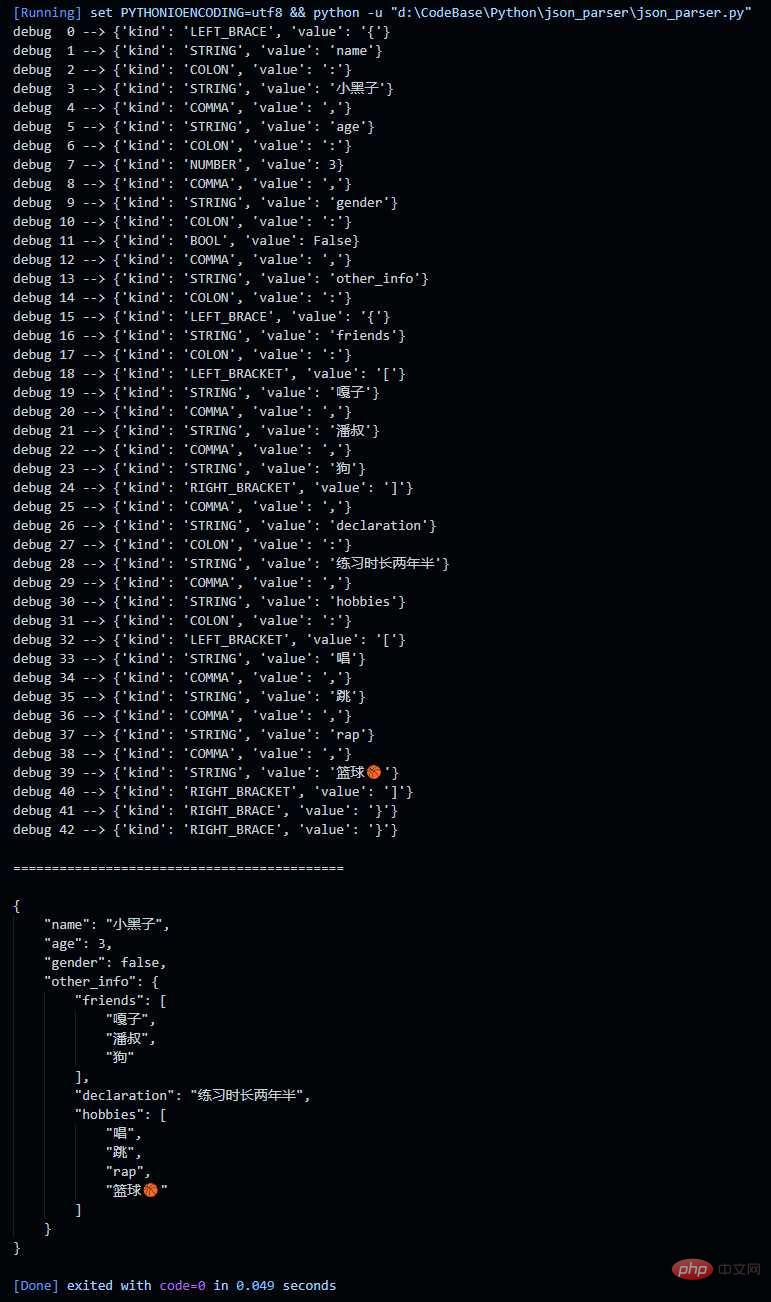
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!