
Maison >développement back-end >Tutoriel Python >Trois façons d'analyser les paramètres en Python
Trois façons d'analyser les paramètres en Python

- 王林avant
- 2023-05-12 11:13:131424parcourir

C'est parti !
Nous utilisons le processus de réglage des paramètres dans l'apprentissage automatique pour nous entraîner. Vous avez le choix entre trois façons. La première option est d'utiliser argparse, qui est un module Python populaire dédié à l'analyse en ligne de commande ; l'autre est de lire un fichier JSON où l'on peut mettre tous les hyperparamètres ; la troisième est également moins connue. La solution est d'utiliser des fichiers YAML ! Curieux, commençons !
Prérequis
Dans le code ci-dessous, j'utiliserai Visual Studio Code, qui est un environnement de développement Python intégré très efficace. La beauté de cet outil est qu'il prend en charge tous les langages de programmation en installant des extensions, intègre le terminal et permet de travailler simultanément avec un grand nombre de scripts Python et de notebooks Jupyter.
- https://www.kaggle.com/datasets/lakshmi25npathi/bike-sharing-dataset
Utilisation d'argparse
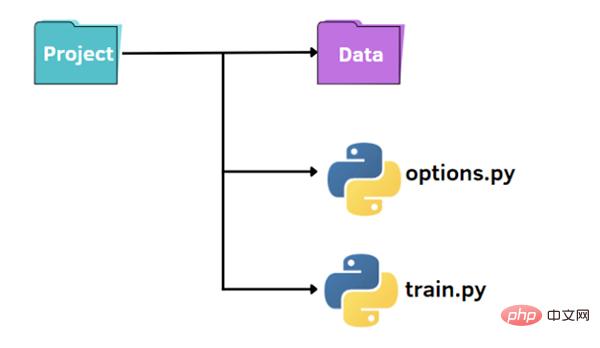
Comme le montre l'image ci-dessus, nous avons une structure standard pour organiser notre petit projet :
- Un dossier nommé data qui contient notre ensemble de données
- Fichier train.py
- Fichier Options.py pour spécifier les hyperparamètres
Tout d'abord, nous pouvons créer un fichier train.py dans Nous avons la procédure de base pour importer les données, entraîner le modèle sur les données d'entraînement et l'évaluer sur l'ensemble de test :
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from options import train_options
df = pd.read_csv('datahour.csv')
print(df.head())
opt = train_options()
X=df.drop(['instant','dteday','atemp','casual','registered','cnt'],axis=1).values
y =df['cnt'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
if opt.normalize == True:
scaler = StandardScaler()
X = scaler.fit_transform(X)
rf = RandomForestRegressor(n_estimators=opt.n_estimators,max_features=opt.max_features,max_depth=opt.max_depth)
model = rf.fit(X_train,y_train)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_pred, y_test))
mae = mean_absolute_error(y_pred, y_test)
print("rmse: ",rmse)
print("mae: ",mae)Dans le code, nous importons également la fonction train_options contenue dans le fichier options.py. Ce dernier fichier est un fichier Python à partir duquel on peut modifier les hyperparamètres considérés dans train.py :
import argparse
def train_options():
parser = argparse.ArgumentParser()
parser.add_argument("--normalize", default=True, type=bool, help='maximum depth')
parser.add_argument("--n_estimators", default=100, type=int, help='number of estimators')
parser.add_argument("--max_features", default=6, type=int, help='maximum of features',)
parser.add_argument("--max_depth", default=5, type=int,help='maximum depth')
opt = parser.parse_args()
return optDans cet exemple, nous utilisons la bibliothèque argparse, très populaire lors de l'analyse des arguments de ligne de commande. Tout d’abord, nous initialisons l’analyseur, puis nous pouvons ajouter les paramètres auxquels nous souhaitons accéder.
Voici un exemple d'exécution du code :
python train.py

Pour modifier les valeurs par défaut des hyperparamètres, il existe deux manières. La première option consiste à définir différentes valeurs par défaut dans le fichier options.py. Une autre option consiste à transmettre la valeur de l'hyperparamètre depuis la ligne de commande :
python train.py --n_estimators 200
Nous devons spécifier le nom de l'hyperparamètre que nous voulons modifier et la valeur correspondante.
python train.py --n_estimators 200 --max_depth 7
En utilisant des fichiers JSON
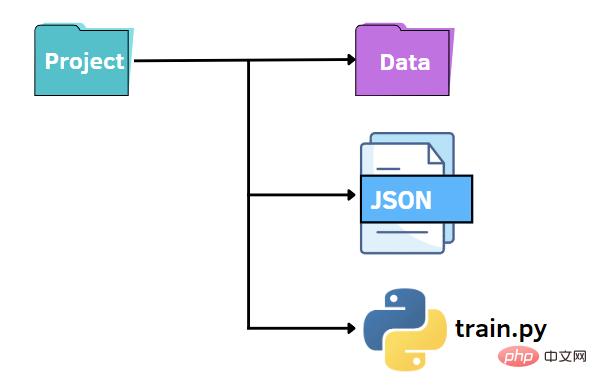
Comme avant, nous pouvons conserver une structure de fichiers similaire. Dans ce cas, nous remplaçons le fichier options.py par un fichier JSON. Autrement dit, nous souhaitons préciser les valeurs des hyperparamètres dans un fichier JSON et les transmettre au fichier train.py. Les fichiers JSON peuvent constituer une alternative rapide et intuitive à la bibliothèque argparse, exploitant les paires clé-valeur pour stocker les données. Ensuite, nous créons un fichier options.json qui contient les données que nous devons transmettre ultérieurement à un autre code.
{
"normalize":true,
"n_estimators":100,
"max_features":6,
"max_depth":5
}Comme vous pouvez le voir ci-dessus, il ressemble beaucoup à un dictionnaire Python. Mais contrairement à un dictionnaire, il contient des données au format texte/chaîne. De plus, il existe certains types de données courants avec une syntaxe légèrement différente. Par exemple, les valeurs booléennes sont faux/vrai, alors que Python reconnaît Faux/Vrai. D'autres valeurs possibles dans JSON sont les tableaux, qui sont représentés sous forme de listes Python à l'aide de crochets.
La beauté de travailler avec des données JSON en Python est qu'elles peuvent être converties en dictionnaire Python via la méthode de chargement :
f = open("options.json", "rb")
parameters = json.load(f)Pour accéder à un élément spécifique, il suffit de citer son nom de clé entre crochets :
if parameters["normalize"] == True: scaler = StandardScaler() X = scaler.fit_transform(X) rf=RandomForestRegressor(n_estimators=parameters["n_estimators"],max_features=parameters["max_features"],max_depth=parameters["max_depth"],random_state=42) model = rf.fit(X_train,y_train) y_pred = model.predict(X_test)
Utiliser des fichiers YAML
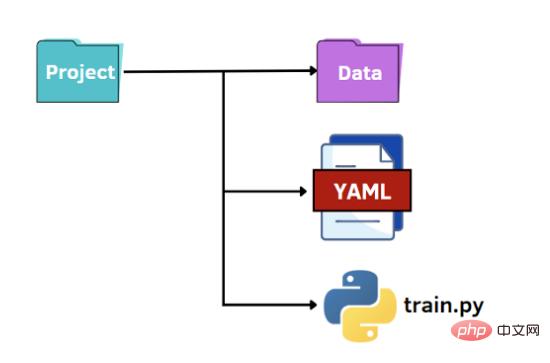
La dernière option est de profiter du potentiel de YAML. Comme pour les fichiers JSON, on lit le fichier YAML en code Python comme un dictionnaire pour accéder aux valeurs des hyperparamètres. YAML est un langage de représentation de données lisible par l'homme dans lequel les hiérarchies sont représentées à l'aide de caractères à double espace au lieu de parenthèses comme dans les fichiers JSON. Ci-dessous, nous montrons ce que contiendra le fichier options.yaml :
normalize: True n_estimators: 100 max_features: 6 max_depth: 5
Dans train.py, nous ouvrons le fichier options.yaml, qui sera toujours converti en dictionnaire Python à l'aide de la méthode de chargement, cette fois importé de la bibliothèque yaml :
import yaml
f = open('options.yaml','rb')
parameters = yaml.load(f, Loader=yaml.FullLoader)Comme précédemment, on peut accéder à la valeur de l'hyperparamètre en utilisant la syntaxe requise pour un dictionnaire.
Réflexions finales
Les profils se compilent très rapidement, alors que argparse nécessite d'écrire une ligne de code pour chaque argument que nous voulons ajouter.
Nous devons donc choisir la manière la plus appropriée en fonction de nos différentes situations
Par exemple, si nous devons ajouter des commentaires aux paramètres, JSON ne convient pas car il n'autorise pas les commentaires, tandis que YAML et argparse peuvent être très adaptés.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!