
Maison >Périphériques technologiques >IA >DetGPT, qui peut lire des images, discuter et effectuer un raisonnement et un positionnement intermodaux, est là pour mettre en œuvre des scénarios complexes.
DetGPT, qui peut lire des images, discuter et effectuer un raisonnement et un positionnement intermodaux, est là pour mettre en œuvre des scénarios complexes.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-11 23:28:051298parcourir
Les êtres humains ont toujours rêvé que les robots puissent les aider à gérer les questions de vie et de travail. « S'il vous plaît, aidez-moi à baisser la température du climatiseur » et même « S'il vous plaît, aidez-moi à écrire un site Web de centre commercial » ont tous été réalisés ces dernières années avec les assistants à domicile et Copilot publiés par OpenAI.
L'émergence de GPT-4 nous montre en outre le potentiel des grands modèles multimodaux dans la compréhension visuelle. En termes de modèles open source de petite et moyenne taille, LLAVA et minigpt-4 fonctionnent bien. Ils peuvent regarder des images et discuter, et peuvent également deviner des recettes dans des images de nourriture pour les humains. Cependant, ces modèles sont encore confrontés à des défis importants lors de leur mise en œuvre réelle : ils n'ont pas de capacités de positionnement précises, ne peuvent pas donner l'emplacement spécifique d'un objet dans l'image et ne peuvent pas comprendre les instructions humaines complexes pour détecter des objets spécifiques. exécuter des tâches humaines spécifiques. Dans des scénarios réels, les gens rencontrent des problèmes complexes : s'ils peuvent demander à l'assistant intelligent d'obtenir la bonne réponse en prenant une photo, une telle fonction « photo et demander » est tout simplement cool.
Pour réaliser la fonction « photo et demander », le robot doit avoir de multiples capacités :
1. Capacité de compréhension du langage : capable d'écouter et de comprendre les intentions humaines
2. Capable de comprendre les objets dans l'image que vous voyez
3. Capacité de raisonnement de bon sens : Capable de convertir des intentions humaines complexes en cibles précises qui peuvent être localisées
4. Capacité de positionnement d'objets : Capable de localiser et de détecter à partir de. la photo Actuellement, seuls quelques grands modèles (comme le PaLM-E de Google) disposent de ces quatre capacités correspondant aux objets
. Cependant, des chercheurs de l'Université des sciences et technologies de Hong Kong et de l'Université de Hong Kong ont proposé un modèle entièrement open source DetGPT (nom complet DetectionGPT), qui n'a besoin que d'affiner trois millions de paramètres, permettant au modèle de posséder facilement un raisonnement complexe et local. capacités de positionnement d'objets, et peut être généralisé à la plupart des scènes à grande échelle. Cela signifie que le modèle peut comprendre les instructions abstraites humaines en raisonnant à partir de ses propres connaissances et identifier facilement les objets d'intérêt humain dans les images ! Ils ont transformé le modèle en une démo « photo et demande », et vous êtes invités à en faire l'expérience en ligne : https://detgpt.github.io/
DetGPT permet aux utilisateurs de tout faire fonctionner en langage naturel, sans avoir besoin pour les commandes ou interfaces encombrantes. Dans le même temps, DetGPT dispose également de capacités de raisonnement intelligent et de détection de cibles, qui peuvent comprendre avec précision les besoins et les intentions de l'utilisateur. Par exemple, lorsqu'un humain envoie une commande verbale « Je veux boire une boisson fraîche », le robot recherche d'abord une boisson fraîche dans la scène, mais ne la trouve pas. Alors j'ai commencé à penser : « Il n'y a pas de boisson fraîche dans la scène, où dois-je la trouver ? Grâce au puissant modèle de raisonnement du bon sens, j'ai pensé au réfrigérateur, j'ai donc scanné la scène et trouvé le réfrigérateur, et j'ai réussi à verrouiller l'emplacement de la boisson !
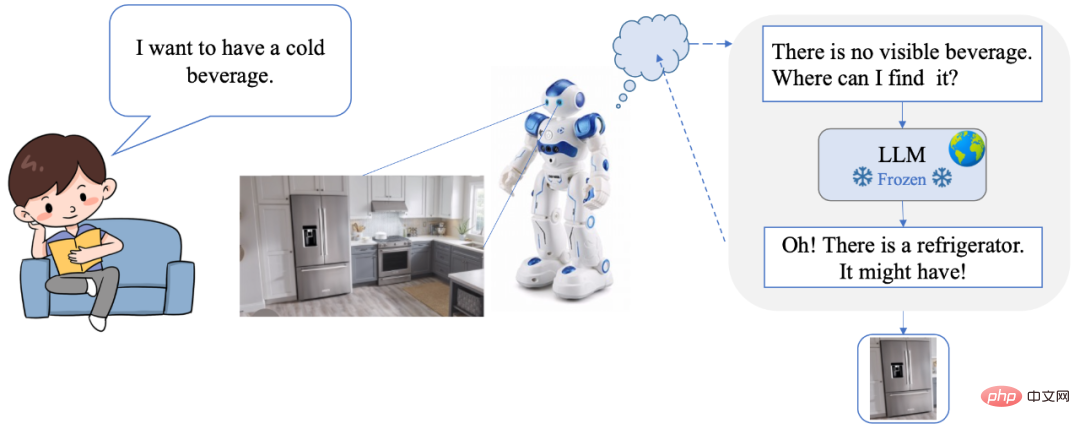
- Code source ouvert https://www.php.cn/link/10eb6500bd1e4a3704818012a1593cc3
- Essai de démonstration en ligne : https://detgpt.github. io/
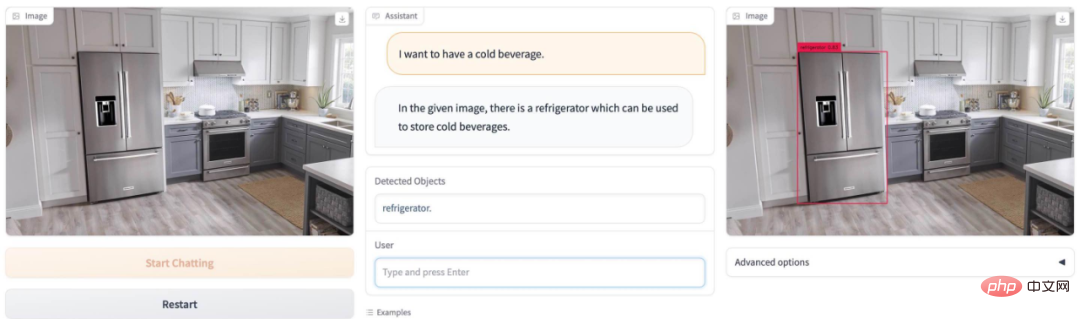
J'ai soif en été, où est la boisson glacée sur la photo ? DetGPT Facile à comprendre Trouver le réfrigérateur :
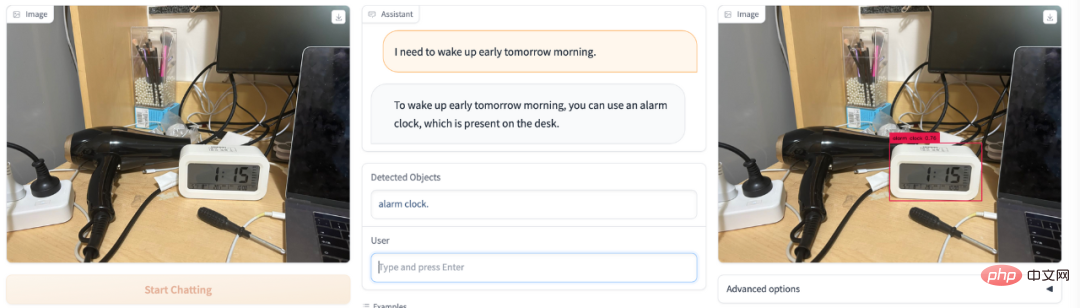
Tu veux te lever tôt demain ? Réveil électronique DetGPT easy pick :
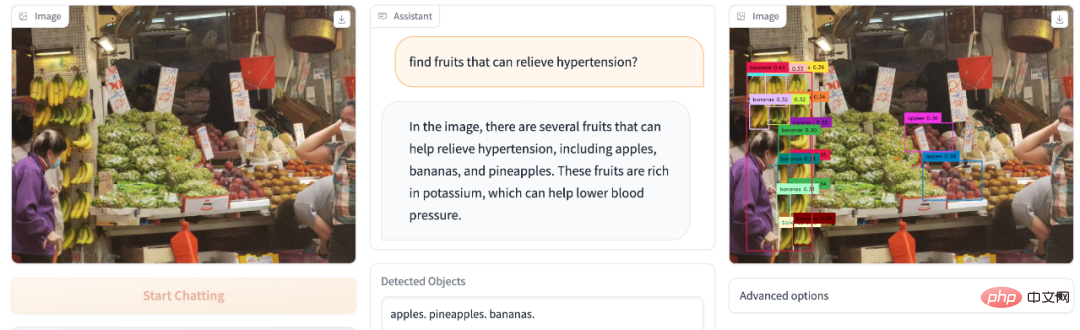
hypertension artérielle et fatigue facilement ? Vous allez au marché aux fruits et vous ne savez pas quel fruit acheter peut soulager l’hypertension artérielle ? DetGPT fait office de professeur de nutrition :
Vous n'arrivez pas à terminer le jeu Zelda ? DetGPT vous aide à passer le niveau Daughter Kingdom déguisé :
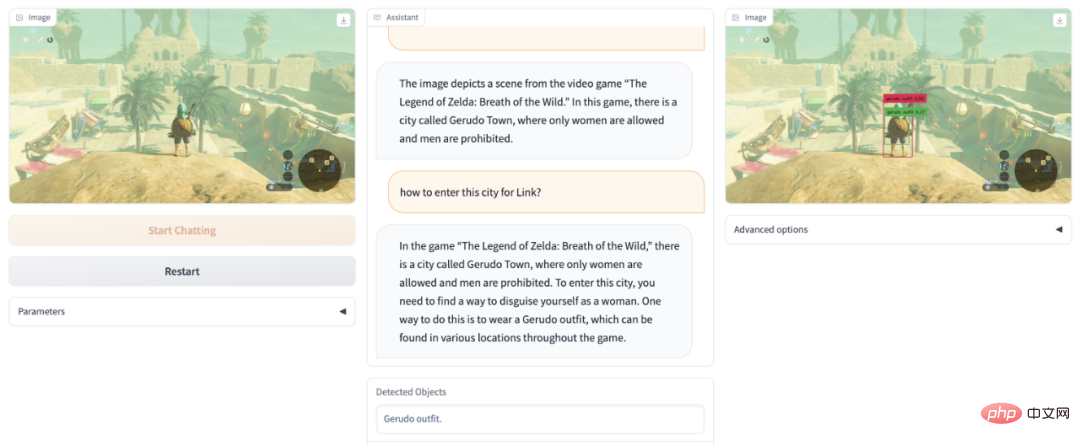
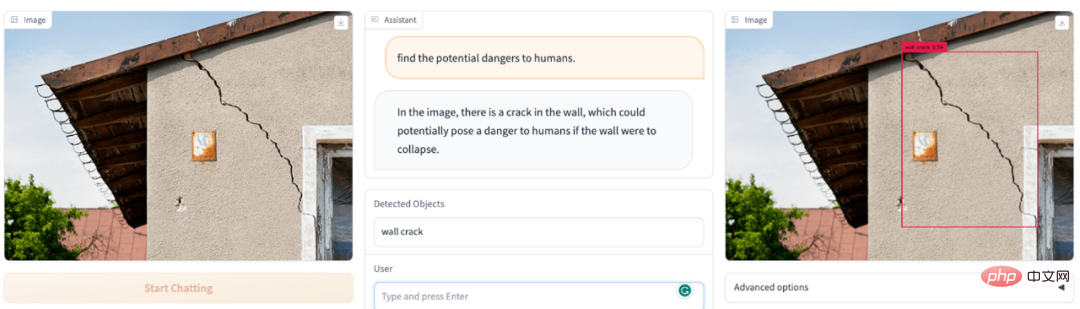
Quelles choses dangereuses se trouvent dans le champ de vision de l'image ? DetGPT devient votre agent de sécurité :
Quels éléments sur la photo sont dangereux pour les enfants ? DetGPT est toujours OK :
Quelles sont les fonctionnalités de DetGPT ?
- La capacité à comprendre des objets spécifiques dans les images a été grandement améliorée. Par rapport aux précédents modèles de dialogue image-texte multimodaux, nous pouvons récupérer et localiser des objets cibles à partir d'images en comprenant les instructions de l'utilisateur, plutôt qu'en décrivant simplement l'image dans son ensemble.
- Peut comprendre des instructions humaines complexes et abaisser le seuil de l'utilisateur pour poser des questions. Par exemple, le modèle peut comprendre le problème « Trouver les aliments sur l'image qui peuvent soulager l'hypertension artérielle ». La détection de cible traditionnelle nécessite des réponses connues des humains, et la catégorie de détection « banane » est prédéfinie à l'avance.
- DetGPT peut raisonner sur la base des connaissances LLM existantes pour localiser avec précision les objets correspondants dans l'image qui peuvent résoudre des tâches complexes. Pour des tâches complexes comme « les aliments pour soulager l’hypertension artérielle ». DetGPT peut raisonner étape par étape pour cette tâche complexe : Soulager l'hypertension artérielle -> Le potassium peut soulager l'hypertension artérielle -> Les bananes sont riches en potassium -> Les bananes peuvent soulager l'hypertension artérielle ->
- a fourni des réponses qui dépassent la portée du bon sens humain. Pour certains problèmes rares, comme le fait que les humains ne savent pas quels fruits sont riches en potassium, le modèle peut y répondre sur la base des connaissances existantes.
Une nouvelle direction digne d'attention : utiliser un raisonnement de bon sens pour obtenir une détection de cible ouverte plus précise

Les tâches de détection traditionnelles nécessitent de prérégler les catégories d'objets possibles pour la détection. Mais décrire de manière précise et complète les objets à détecter est peu convivial, voire irréaliste pour l'homme. Plus précisément, (1) Limités par une mémoire/des connaissances limitées, les gens ne peuvent pas toujours exprimer avec précision les objets cibles qu'ils souhaitent détecter. Par exemple, les médecins recommandent aux personnes souffrant d'hypertension de manger plus de fruits pour compléter le potassium, mais sans savoir quels fruits sont riches en potassium, ils ne peuvent pas donner de noms de fruits spécifiques pour que le modèle puisse détecter ; Les humains n'ont qu'à prendre une photo, et le modèle lui-même pensera, raisonnera et détectera les fruits riches en potassium. Ce problème est beaucoup plus simple. (2) Les catégories d’objets que les humains peuvent illustrer ne sont pas exhaustives. Par exemple, si nous surveillons les comportements incompatibles avec l'ordre public dans les lieux publics, les humains peuvent simplement énumérer quelques scénarios tels que tenir des couteaux et fumer ; "ordre public" au modèle de détection. Si le modèle pense par lui-même et fait des déductions basées sur ses propres connaissances, il peut capturer davantage de mauvais comportements et les généraliser à des catégories plus connexes qui doivent être détectées. Après tout, les connaissances que les humains ordinaires comprennent sont limitées, et les types d'objets qui peuvent être cités sont également limités. Mais s'il existe un cerveau comme ChatGPT pour l'assistance et le raisonnement, les instructions que les humains doivent donner seront beaucoup plus simples et. les réponses obtenues peuvent également être beaucoup plus précises et complètes.
Sur la base de l'abstraction et des limites des instructions humaines, des chercheurs de l'Université des sciences et technologies de Hong Kong et de l'Université de Hong Kong ont proposé une nouvelle direction de « détection de cible inférentielle ». Pour faire simple, les humains confient des tâches abstraites, et le modèle peut comprendre et raisonner par lui-même quels objets dans l'image peuvent accomplir cette tâche, et les détecter. Pour donner un exemple simple, lorsqu'un humain décrit « Je veux une boisson fraîche, où puis-je la trouver », le modèle voit une photo d'une cuisine, et il peut détecter le « réfrigérateur ». Ce sujet nécessite la combinaison parfaite des capacités de compréhension d'images des modèles multimodaux et des riches connaissances stockées dans de grands modèles de langage, et de les utiliser dans des scénarios de tâches de détection à granularité fine : utiliser le cerveau des modèles de langage pour comprendre les instructions abstraites humaines et avec précision. localiser des images Objets d'intérêt humain sans catégories d'objets prédéfinies.
Introduction à la méthode
La "détection inférentielle de cible" est un problème difficile, car le détecteur doit non seulement comprendre et raisonner sur les instructions grossières/abstraites de l'utilisateur, mais doit également analyser les informations visuelles actuellement vues pour localiser la cible. .hors de l'objet cible. Dans cette direction, des chercheurs de HKUST et HKU ont mené quelques explorations préliminaires. Plus précisément, ils utilisent un encodeur visuel pré-entraîné (BLIP-2) pour obtenir des caractéristiques visuelles de l'image et aligner les caractéristiques visuelles sur l'espace de texte via une fonction d'alignement. Utilisez un modèle de langage à grande échelle (Robin/Vicuna) pour comprendre les questions des utilisateurs et combiner les informations visuelles vues pour raisonner sur les objets qui intéressent réellement l'utilisateur. Les noms d'objets sont ensuite transmis à un détecteur pré-entraîné (Grouding-DINO) pour la prédiction d'emplacements spécifiques. De cette manière, le modèle peut analyser l'image selon toutes les instructions de l'utilisateur et prédire avec précision l'emplacement de l'objet qui intéresse l'utilisateur.
Il convient de noter que la difficulté ici réside principalement dans le fait que le modèle doit être capable d'obtenir un résultat spécifique à une tâche pour différentes tâches spécifiques sans endommager autant que possible les capacités d'origine du modèle. Afin de guider le modèle de langage pour qu'il suive un modèle spécifique, effectue un raisonnement et génère une sortie conforme au format de détection cible dans le cadre de la compréhension des images et des instructions utilisateur, l'équipe de recherche a utilisé ChatGPT pour générer des données d'instructions intermodales afin d'affiner. régler le modèle. Plus précisément, sur la base de 5 000 images coco, ils ont utilisé ChatGPT pour créer 30 000 ensembles de données de réglage fin image-texte multimodaux. Afin d'améliorer l'efficacité de la formation, ils ont corrigé d'autres paramètres du modèle et appris uniquement la cartographie linéaire intermodale. Les résultats expérimentaux prouvent que même si seule la couche linéaire est affinée, le modèle de langage peut comprendre les caractéristiques fines de l'image et suivre des modèles spécifiques pour effectuer des tâches de détection d'image basées sur l'inférence, affichant d'excellentes performances.
Ce sujet de recherche a un grand potentiel. Grâce à cette technologie, le domaine des robots domestiques va encore briller : les personnes à la maison peuvent utiliser des instructions vocales abstraites ou grossières pour permettre aux robots de comprendre, d'identifier et de localiser les éléments nécessaires et de fournir les services associés. Dans le domaine des robots industriels, cette technologie aura une vitalité sans fin : les robots industriels pourront collaborer plus naturellement avec les travailleurs humains, comprendre avec précision leurs instructions et leurs besoins, et prendre des décisions et effectuer des opérations intelligentes. Sur la chaîne de production, les travailleurs humains peuvent utiliser des instructions vocales grossières ou la saisie de texte pour permettre au robot de comprendre, d'identifier et de localiser automatiquement les éléments à traiter, améliorant ainsi l'efficacité et la qualité de la production.
Sur la base du modèle de détection de cible doté de ses propres capacités de raisonnement, nous pouvons développer des robots plus intelligents, naturels et efficaces pour fournir aux humains des services plus pratiques, efficaces et humains. C'est un domaine avec de larges perspectives. Il mérite également davantage d’attention et d’exploration de la part des chercheurs.
Il convient de mentionner que DetGPT prend en charge plusieurs modèles de langage et a été vérifié sur la base de deux modèles de langage : Robin-13B et Vicuna-13B. Le modèle linguistique de la série Robin est un modèle de dialogue formé par l'équipe LMFlow de l'Université des sciences et technologies de Hong Kong (https://github.com/OptimalScale/LMFlow). Il a obtenu des résultats équivalents à ceux de Vicuna sur plusieurs critères d'évaluation des compétences linguistiques. (téléchargement du modèle : https:// github.com/OptimalScale/LMFlow#model-zoo). Heart of the Machine a précédemment signalé que l'équipe LMFlow pouvait entraîner ChatGPT exclusif en seulement 5 heures sur la carte graphique grand public 3090. Aujourd'hui, cette équipe et le laboratoire HKU NLP nous ont apporté une autre surprise multimodale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI