
Maison >Périphériques technologiques >IA >Dernière recherche, GPT-4 expose des lacunes ! Je ne comprends pas vraiment l'ambiguïté du langage !
Dernière recherche, GPT-4 expose des lacunes ! Je ne comprends pas vraiment l'ambiguïté du langage !

- PHPzavant
- 2023-05-11 21:52:041650parcourir
L'inférence du langage naturel (NLI) est une tâche importante dans le traitement du langage naturel. Son objectif est de déterminer si l'hypothèse peut être déduite des prémisses sur la base des prémisses et des hypothèses données. Cependant, puisque l’ambiguïté est une caractéristique intrinsèque du langage naturel, la gestion de l’ambiguïté constitue également un élément important de la compréhension du langage humain. En raison de la diversité des expressions du langage humain, le traitement des ambiguïtés est devenu l’une des difficultés rencontrées dans la résolution des problèmes de raisonnement en langage naturel. Actuellement, divers algorithmes de traitement du langage naturel sont appliqués dans des scénarios tels que les systèmes de questions et réponses, la reconnaissance vocale, la traduction intelligente et la génération de langage naturel, mais même avec ces technologies, résoudre complètement l'ambiguïté reste une tâche extrêmement difficile.
Pour les tâches NLI, les grands modèles de traitement du langage naturel tels que GPT-4 sont confrontés à des défis. L’un des problèmes est que l’ambiguïté du langage rend difficile pour les modèles de comprendre avec précision le véritable sens des phrases. De plus, en raison de la flexibilité et de la diversité du langage naturel, il peut exister diverses relations entre différents textes, ce qui rend l'ensemble des données de la tâche NLI extrêmement complexe. Cela affecte également l'universalité et la polyvalence du modèle de traitement du langage naturel. posent des défis importants. Par conséquent, face au langage ambigu, il sera crucial que les grands modèles réussissent à l’avenir, et les grands modèles ont été largement utilisés dans des domaines tels que les interfaces conversationnelles et les aides à l’écriture. Faire face à l’ambiguïté aidera à s’adapter à différents contextes, à améliorer la clarté de la communication et la capacité à identifier les discours trompeurs ou trompeurs.
Le titre de cet article traitant de l'ambiguïté dans les grands modèles utilise un jeu de mots, "Nous avons peur...", qui exprime non seulement les préoccupations actuelles concernant la difficulté des modèles de langage à modéliser avec précision l'ambiguïté, mais fait également allusion au langage décrit. dans la structure papier. Cet article montre également que les gens travaillent dur pour développer de nouveaux critères afin de véritablement défier de nouveaux grands modèles puissants afin de comprendre et de générer le langage naturel avec plus de précision et de réaliser de nouvelles percées dans les modèles.
Titre de l'article : Nous avons peur que les modèles de langage ne modélisent pas l'ambiguïté
Lien de l'article : https://arxiv.org/abs/2304.14399
Code et adresse des données : https://github.com/alisawuffles/ambient
L'auteur de cet article prévoit d'étudier si le grand modèle pré-entraîné a la capacité de reconnaître et de distinguer des phrases avec plusieurs interprétations possibles, et d'évaluer comment le modèle distingue différentes lectures et interprétations. Cependant, les données de référence existantes ne contiennent généralement pas d'exemples ambigus, il faut donc construire ses propres expériences pour explorer cette question.
Le schéma d'annotation à trois voies NLI traditionnel fait référence à une méthode d'annotation utilisée pour les tâches d'inférence en langage naturel (NLI), qui nécessite que l'annotateur sélectionne une étiquette parmi trois étiquettes pour représenter la relation entre le texte original et l'hypothèse. Les trois étiquettes sont généralement « implication », « neutre » et « contradiction ».
L'auteur a utilisé le format de la tâche NLI pour mener des expériences, en adoptant une approche fonctionnelle pour caractériser l'ambiguïté à travers l'impact de l'ambiguïté dans les prémisses ou les hypothèses sur les relations d'implication. Les auteurs proposent un benchmark appelé AMBIENT (Ambiguity in Entailment) qui couvre une variété d'ambiguïtés lexicales, syntaxiques et pragmatiques, et couvre plus largement les phrases pouvant véhiculer plusieurs messages différents.
Comme le montre la figure 1, l'ambiguïté peut être un malentendu inconscient (figure 1 en haut) ou elle peut être délibérément utilisée pour induire le public en erreur (figure 1 en bas). Par exemple, si un chat se perd après avoir quitté la maison, alors il est perdu dans le sens où il ne peut pas retrouver le chemin du retour (implication edge) s'il n'est pas rentré chez lui depuis plusieurs jours, alors il est perdu dans le sens où les autres) ; Je ne peux pas le trouver. Dans un sens, il est également perdu (côté neutre).
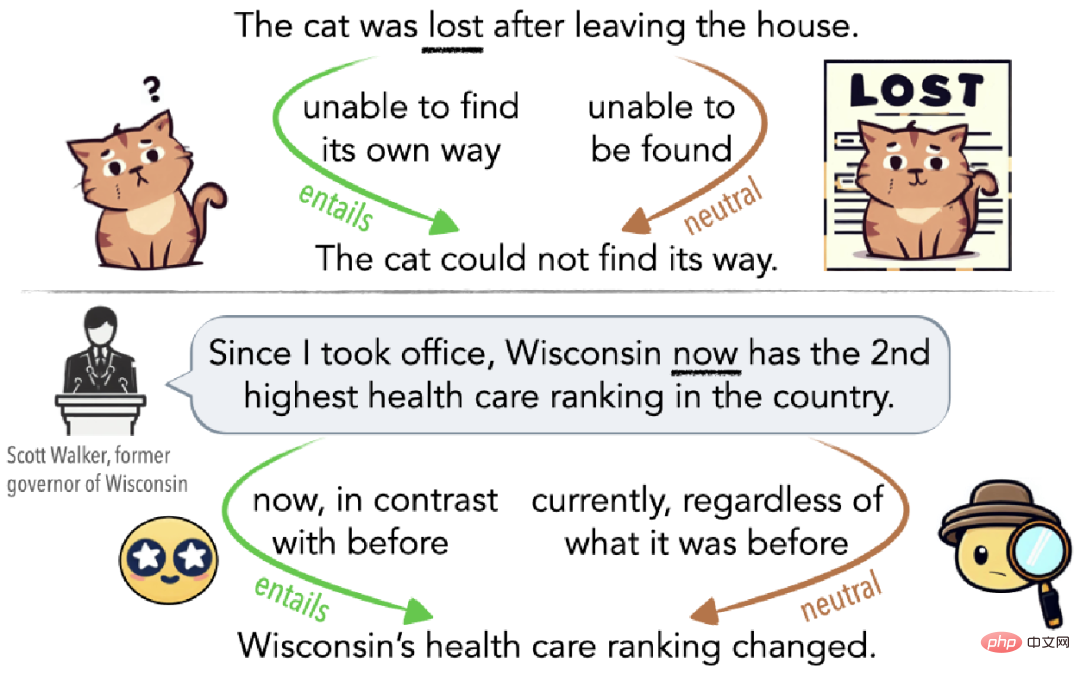
▲ Figure 1 Exemples d'ambiguïté expliquée par Cat Lost
Introduction à l'ensemble de données AMBIENT
Exemples sélectionnés
L'auteur fournit 1645 exemples de phrases couvrant plusieurs types d'ambiguïtés, y compris des échantillons manuscrits et des temps modernes Il existe NLI ensembles de données et manuels de linguistique. Chaque exemple dans AMBIENT contient un ensemble d'étiquettes correspondant à diverses compréhensions possibles, et une réécriture de désambiguïsation pour chaque compréhension, comme le montre le tableau 1.
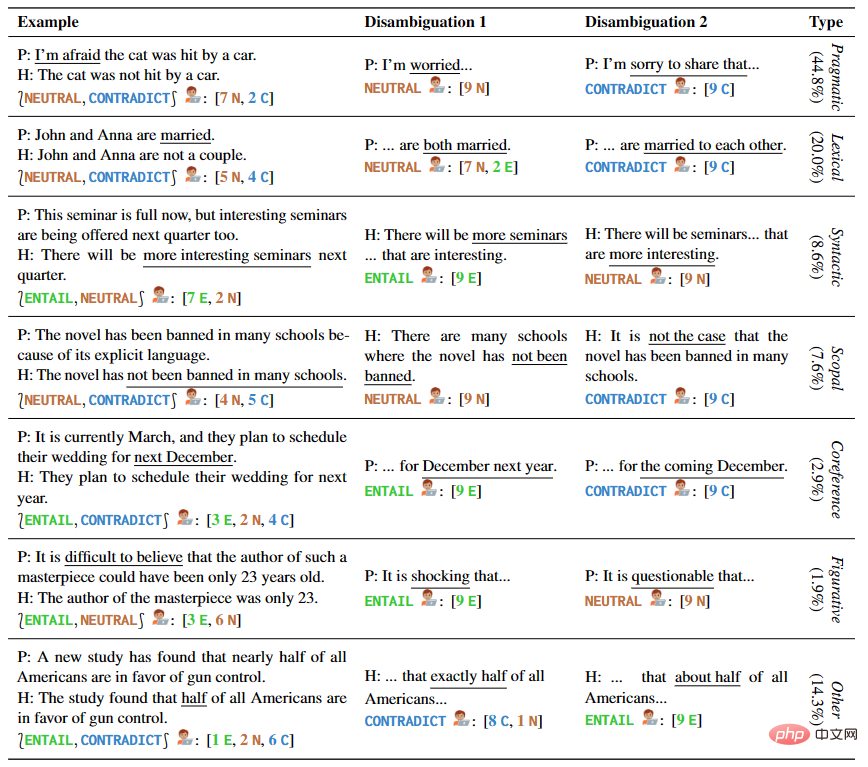
▲Tableau 1 Paires de prémisses et d'hypothèses dans des exemples sélectionnés
Exemples générés
Les chercheurs ont également adopté des méthodes de surgénération et de filtrage pour créer un vaste corpus d'exemples NLI non étiqueté afin de couvrir avec plus de précision et de manière complète différentes situations d'ambiguïté. Inspirés de travaux antérieurs, ils identifient automatiquement des paires de prémisses qui partagent des modèles de raisonnement et améliorent la qualité du corpus en encourageant la création de nouveaux exemples avec les mêmes modèles.
Annotation et vérification
Des annotations et annotations sont requises pour les exemples obtenus lors des étapes précédentes. Ce processus impliquait l'annotation par deux experts, la vérification et le résumé par un expert, et la vérification par certains auteurs. Pendant ce temps, 37 étudiants en linguistique ont sélectionné un ensemble d'étiquettes pour chaque exemple et ont fourni des réécritures de désambiguïsation. Tous ces exemples annotés ont été filtrés et vérifiés, ce qui a abouti à 1 503 exemples finaux.
Le processus spécifique est illustré dans la figure 2 : commencez par utiliser InstructGPT pour créer des exemples non étiquetés, puis deux linguistes les annotent indépendamment. Enfin, grâce à l'intégration par un auteur, les annotations et annotations finales sont obtenues.
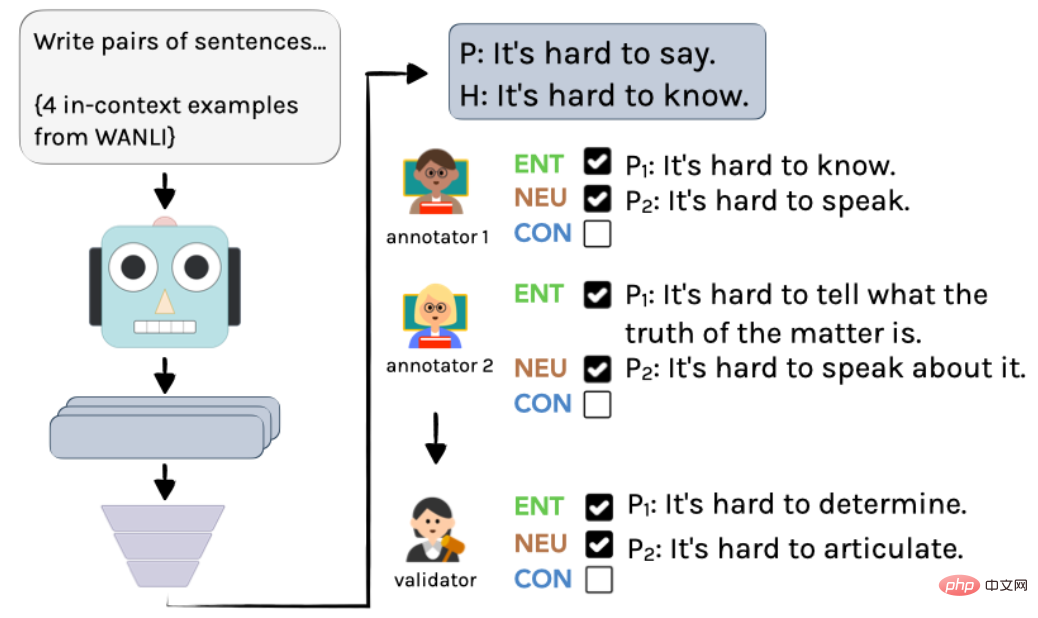
▲ Figure 2 Processus d'annotation pour générer des exemples dans AMBIENT
De plus, la question de la cohérence des résultats d'annotation entre les différents annotateurs et les types d'ambiguïtés existant dans l'ensemble de données AMBIENT sont également abordés ici. L'auteur a sélectionné au hasard 100 échantillons dans cet ensemble de données comme ensemble de développement, et les échantillons restants ont été utilisés comme ensemble de test. La figure 3 montre la distribution des étiquettes d'ensemble, et chaque échantillon a une étiquette de relation d'inférence correspondante. La recherche montre qu'en cas d'ambiguïté, les résultats d'annotation de plusieurs annotateurs sont cohérents et que l'utilisation des résultats conjoints de plusieurs annotateurs peut améliorer la précision des annotations.
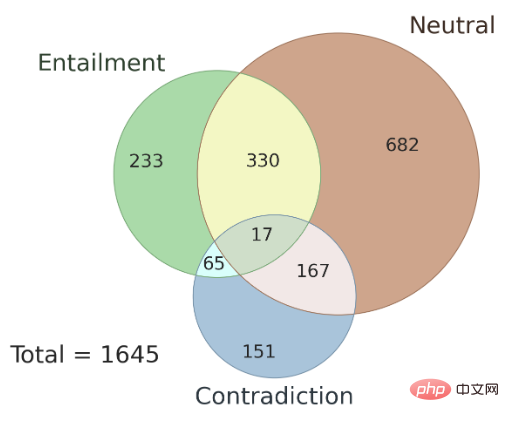
▲ Figure 3 Répartition des labels des ensembles dans AMBIENT
L'ambiguïté explique-t-elle le "désaccord" ?
Cette étude analyse le comportement des annotateurs lors de l'annotation d'entrées ambiguës dans le cadre du schéma d'annotation à trois voies traditionnel du NLI. L'étude a révélé que les annotateurs peuvent être conscients de l'ambiguïté et que l'ambiguïté est la principale cause des différences d'étiquetage, remettant ainsi en question l'hypothèse populaire selon laquelle le « désaccord » est la source d'incertitude dans les exemples simulés.
Dans l'étude, l'ensemble de données AMBIENT a été utilisé et 9 travailleurs de crowdsourcing ont été embauchés pour annoter chaque exemple ambigu.
La tâche est divisée en trois étapes :
- Annoter les exemples ambigus
- Identifier les différentes interprétations possibles
- Annoter les exemples non ambigus
Parmi eux, à l'étape 2, trois explications possibles incluent deux possibles La signification est similaire mais pas exactement la même chose qu'une phrase. Enfin, pour chaque explication possible, elle est remplacée dans l'exemple d'origine pour obtenir trois nouveaux exemples NLI, et l'annotateur est invité à choisir respectivement une étiquette.
Les résultats de cette expérience soutiennent l'hypothèse : dans un système d'étiquetage unique, les exemples flous originaux produiront des résultats très incohérents, c'est-à-dire que dans le processus d'étiquetage des phrases, les gens ont tendance à avoir des jugements différents sur les phrases ambiguës, conduisant à des résultats incohérents. . Cependant, lorsqu’une étape de désambiguïsation a été ajoutée à la tâche, les annotateurs ont généralement été capables d’identifier et de vérifier de multiples possibilités pour les phrases, et les incohérences dans les résultats ont été largement résolues. La levée de l’ambiguïté est donc un moyen efficace de réduire l’impact de la subjectivité de l’annotateur sur les résultats.
Évaluer les performances sur les grands modèles
Q1. Le contenu lié à la désambiguïsation peut-il être généré directement ?
L'objectif de cette partie est de tester la capacité d'apprentissage du modèle de langage à générer directement la désambiguïsation et les étiquettes correspondantes en contexte. À cette fin, les auteurs ont construit un signal naturel et validé les performances du modèle à l'aide d'une évaluation automatique et manuelle, comme le montre le tableau 2.

▲Tableau 2 : quelques modèles pour générer des tâches de désambiguïsation lorsque la prémisse n'est pas claire
Lors des tests, chaque exemple comporte 4 autres exemples de tests comme contexte et utilise la métrique EDIT-F1 et l'évaluation humaine pour calculer les scores et l'exactitude . Les résultats expérimentaux présentés dans le tableau 3 montrent que GPT-4 a obtenu les meilleurs résultats lors du test, atteignant un score EDIT-F1 de 18,0 % et une précision d'évaluation humaine de 32,0 %. De plus, il a été observé que les grands modèles adoptent souvent la stratégie consistant à ajouter un contexte supplémentaire lors de la désambiguïsation pour confirmer ou infirmer directement les hypothèses. Cependant, il est important de noter que l'évaluation humaine peut surestimer la capacité du modèle à signaler avec précision les sources d'ambiguïté.
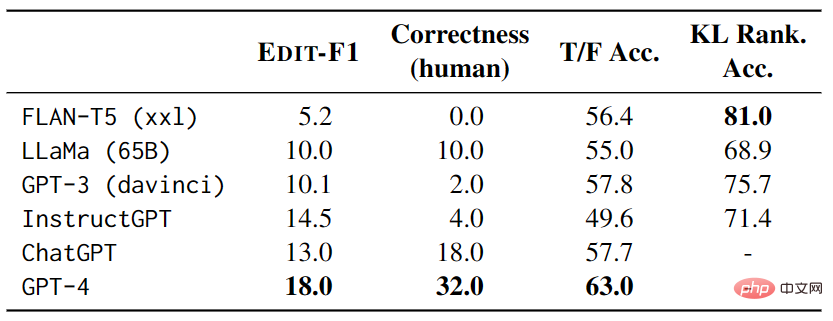
▲Tableau 3 Performances des grands modèles sur AMBIENT
Q2. La validité des explications raisonnables peut-elle être identifiée ?
Cette partie étudie principalement les performances des grands modèles dans l'identification des phrases ambiguës. En créant une série de modèles d'énoncés vrais et faux et en testant le modèle de manière zéro, les chercheurs ont évalué l'efficacité du grand modèle dans le choix des prédictions entre vrai et faux. Les résultats expérimentaux montrent que le meilleur modèle est GPT-4. Cependant, lorsque l'ambiguïté est prise en compte, GPT-4 est moins performant que les suppositions aléatoires pour répondre aux interprétations ambiguës des quatre modèles. De plus, les grands modèles présentent des problèmes de cohérence en termes de questions. Pour différentes paires d’interprétations d’une même phrase ambiguë, le modèle peut présenter des contradictions internes.
Ces résultats suggèrent que nous devons étudier plus en profondeur comment améliorer la compréhension des phrases ambiguës par les grands modèles et mieux évaluer les performances des grands modèles.
Q3. Simuler une génération continue ouverte à travers différentes interprétations
Cette partie étudie principalement la capacité de compréhension de l'ambiguïté basée sur des modèles de langage. Les modèles linguistiques sont testés dans un contexte donné et comparent leurs prédictions de continuation du texte sous différentes interprétations possibles. Afin de mesurer la capacité du modèle à gérer l'ambiguïté, les chercheurs ont utilisé la divergence KL pour mesurer la « surprise » du modèle en comparant les différences de probabilité et d'attente produites par le modèle sous une ambiguïté donnée et un contexte correct donné dans le contexte correspondant. , et introduit des « phrases d'interférence » qui remplacent aléatoirement les noms pour tester davantage la capacité du modèle.
Les résultats expérimentaux montrent que FLAN-T5 a la plus grande précision, mais les résultats de performances des différentes suites de tests (LS implique le remplacement de synonymes, PC implique la correction des fautes d'orthographe et SSD implique la correction des structures grammaticales) et des différents modèles sont incohérents, ce qui indique cette ambiguïté constitue toujours un défi de taille.
Expérience du modèle NLI multi-étiquettes
Comme le montre le tableau 4, il reste encore beaucoup à faire pour affiner le modèle NLI sur les données existantes avec des changements d'étiquettes, en particulier dans les tâches NLI multi-étiquettes.
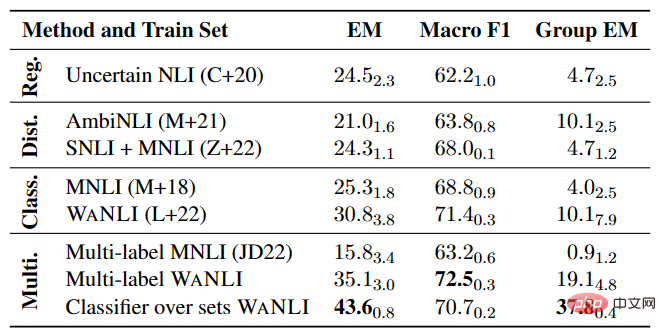
▲Tableau 4 Performances du modèle NLI multi-label sur AMBIENT
Détection du discours politique trompeur
Cette expérience étudie différentes manières de comprendre le discours politique et prouve que des modèles sensibles à différentes manières de comprendre peuvent être utilisés efficacement . Les résultats de la recherche sont présentés dans le tableau 5. Pour les phrases ambiguës, certaines interprétations explicatives peuvent naturellement éliminer l'ambiguïté, car ces interprétations ne peuvent que conserver l'ambiguïté ou exprimer clairement un sens spécifique.
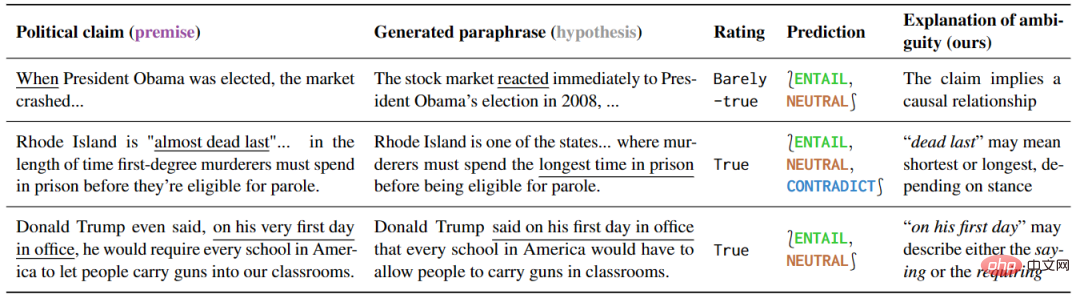
▲Tableau 5 La méthode de détection de cet article marque le discours politique comme ambigu
De plus, l'interprétation de cette prédiction peut révéler la source de l'ambiguïté. En analysant plus en détail les résultats des faux positifs, les auteurs ont également découvert de nombreuses ambiguïtés qui n'étaient pas mentionnées lors des vérifications des faits, illustrant le grand potentiel de ces outils pour prévenir les malentendus.
Résumé
Comme souligné dans cet article, l'ambiguïté du langage naturel sera un défi clé dans l'optimisation des modèles. Nous espérons que dans le futur développement technologique, les modèles de compréhension du langage naturel seront capables d'identifier plus précisément le contexte et les points clés des textes, et feront preuve d'une plus grande sensibilité lorsqu'ils traiteront des textes ambigus. Bien que nous ayons établi une référence pour évaluer les modèles de traitement du langage naturel afin d'identifier l'ambiguïté et que nous soyons capables de mieux comprendre les limites des modèles dans ce domaine, cela reste une tâche très difficile.
Xi Xiaoyao Technology Talk Original
Auteur | Le QI a chuté partout, Python
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI