
Maison >Périphériques technologiques >IA >Utilisation d'images pour aligner toutes les modalités, modèle de base d'IA multisensorielle open source Meta pour réaliser une grande unification
Utilisation d'images pour aligner toutes les modalités, modèle de base d'IA multisensorielle open source Meta pour réaliser une grande unification

- 王林avant
- 2023-05-11 19:25:111523parcourir
Dans les sens humains, une image peut mélanger de nombreuses expériences. Par exemple, une image de plage peut nous rappeler le bruit des vagues, la texture du sable, la brise qui souffle sur notre visage, et même Peut inspirer un poème. Cette propriété de « liaison » des images fournit une grande source de supervision pour l’apprentissage des caractéristiques visuelles en les alignant sur toute expérience sensorielle qui leur est associée.
Idéalement, les caractéristiques visuelles devraient être apprises en alignant tous les sens pour un seul espace d'intégration articulaire. Cependant, cela nécessite d’obtenir des données appariées pour tous les types et combinaisons sensorielles à partir du même ensemble d’images, ce qui n’est évidemment pas réalisable.
Récemment, de nombreuses méthodes apprennent les caractéristiques de l'image alignées sur le texte, l'audio, etc. Ces méthodes utilisent une seule paire de modalités ou tout au plus plusieurs modalités visuelles. L'intégration finale est limitée aux paires modales utilisées pour la formation. Par conséquent, l’intégration vidéo-audio ne peut pas être directement utilisée pour les tâches image-texte et vice versa. Un obstacle majeur à l’apprentissage de véritables intégrations conjointes est le manque de grandes quantités de données multimodales où toutes les modalités sont fusionnées.
Aujourd'hui, Meta AI a proposé ImageBind en exploitant plusieurs types de données d'appariement d'images pour apprendre un seul espace de représentation partagé. Cette étude ne nécessite pas un ensemble de données dans lequel toutes les modalités apparaissent simultanément les unes avec les autres. Au lieu de cela, profite des propriétés de liaison de l'image, qui permettront d'atteindre toutes les modalités à condition d'intégrer chaque modalité. est aligné avec l'intégration de l'image. L'alignement rapide de . Meta AI a également annoncé le code correspondant.

- # 🎜 🎜#Adresse papier : https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
- Adresse GitHub : https:/ /github.com/facebookresearch/ImageBind
Spécifique et spécifique En d’autres termes, ImageBind exploite les données de correspondance à l’échelle du réseau (image, texte) et les combine avec des données appariées naturelles (vidéo, audio, image, profondeur) pour apprendre un seul espace d’intégration commun. Cela permet à ImageBind d'aligner implicitement les intégrations de texte avec d'autres modalités (telles que l'audio, la profondeur, etc.), permettant une reconnaissance sans tir sur ces modalités sans appariement sémantique ou textuel explicite.
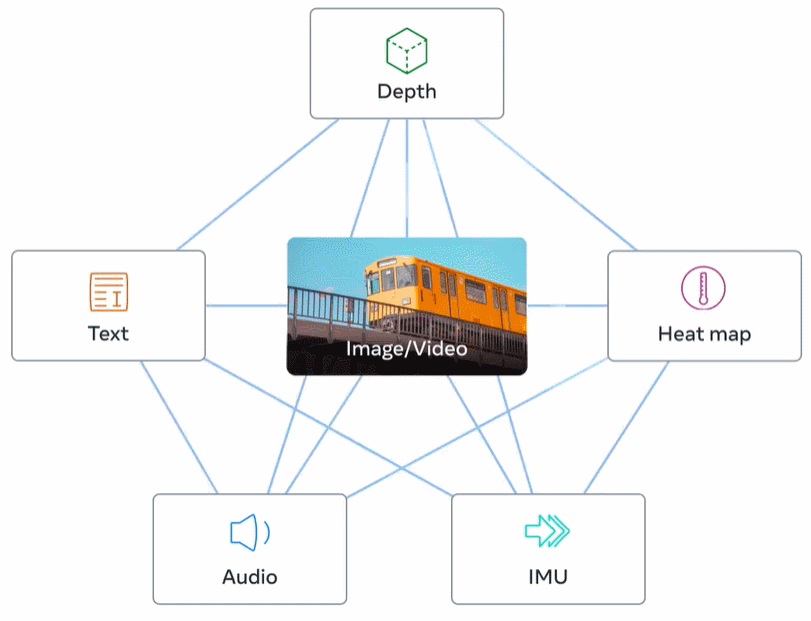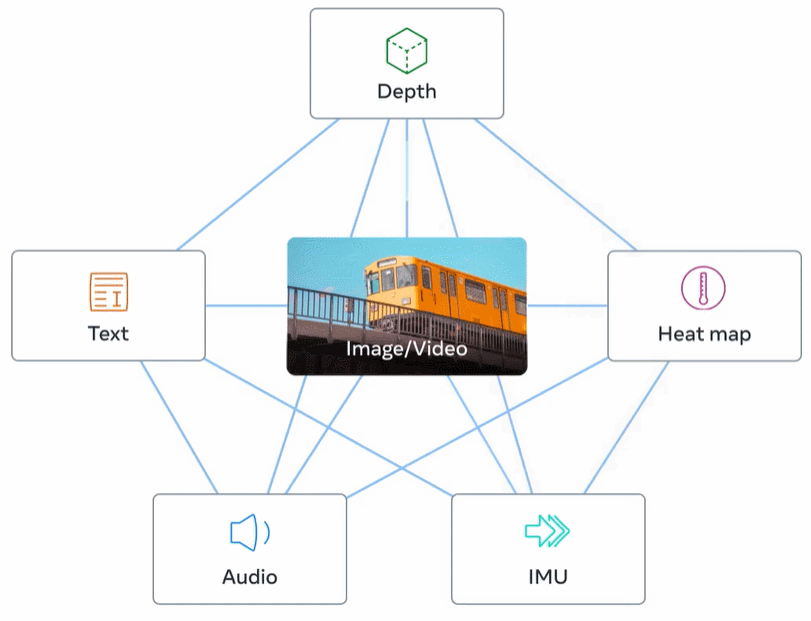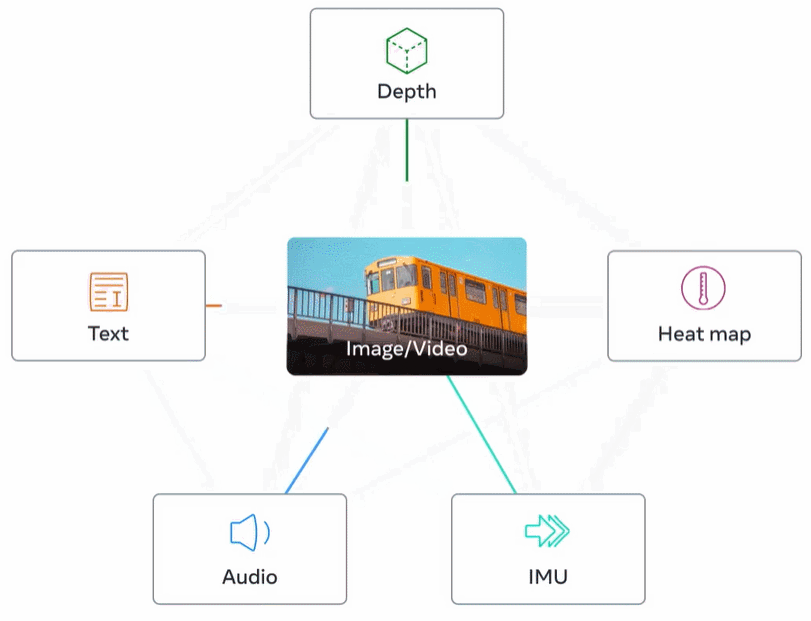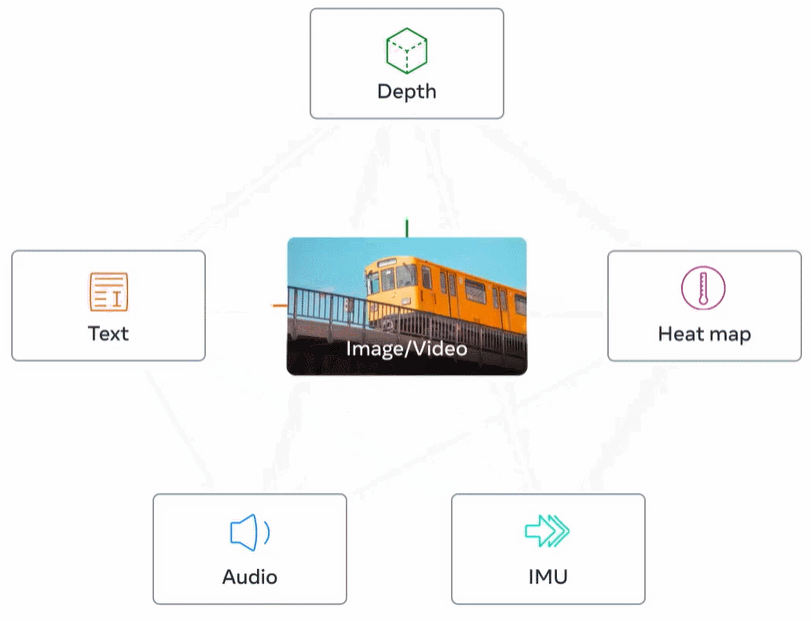
La figure 2 ci-dessous est un aperçu général d'ImageBind.

Dans le même temps, les chercheurs ont déclaré qu'ImageBind pouvait être initialisé à l'aide de modèles de langage visuel à grande échelle (tels que CLIP), exploitant ainsi les riches représentations d'images et de texte de ces modèles. Par conséquent, ImageBind nécessite très peu de formation et peut être appliqué à une variété de modalités et de tâches différentes.
ImageBind fait partie de l'engagement de Meta à créer des systèmes d'IA multimodaux qui apprennent de tous les types de données pertinents. À mesure que le nombre de modalités augmente, ImageBind ouvre les vannes aux chercheurs pour tenter de développer de nouveaux systèmes holistiques, tels que la combinaison de capteurs 3D et IMU pour concevoir ou expérimenter des mondes virtuels immersifs. Il offre également un moyen riche d'explorer votre mémoire en utilisant une combinaison de texte, de vidéo et d'images pour rechercher des images, des vidéos, des fichiers audio ou des informations textuelles.
Lier du contenu et des images, apprendre un seul espace d'intégrationLes humains ont la capacité d'apprendre de nouveaux concepts avec très peu d'échantillons, comme la lecture paires A partir de la description d'un animal, vous pouvez le reconnaître dans la vraie vie ; à partir d'une photo d'un modèle de voiture inconnu, vous pouvez prédire le bruit que son moteur est susceptible de faire. Cela est dû en partie au fait qu’une seule image peut « regrouper » une expérience sensorielle globale. Cependant, dans le domaine de l’intelligence artificielle, même si le nombre de modalités a augmenté, le manque de données multisensorielles limitera l’apprentissage multimodal standard qui nécessite des données appariées.
Idéalement, un espace d'intégration commun avec différents types de données permet au modèle d'apprendre d'autres modalités tout en apprenant les caractéristiques visuelles. Auparavant, il était souvent nécessaire de collecter toutes les combinaisons de données possibles par paire pour que toutes les modalités apprennent un espace d'intégration commun.
ImageBind contourne cette énigme en exploitant les récents modèles de langage visuel à grande échelle. Il étend les capacités zéro-shot des récents modèles de langage visuel à grande échelle à de nouvelles modalités avec leurs associations naturelles d'images, telles que vidéo-audio et Image. -données approfondies pour apprendre un espace d'intégration commun. Pour les quatre autres modalités (audio, profondeur, imagerie thermique et lectures IMU), les chercheurs ont utilisé des données auto-supervisées naturellement appariées.
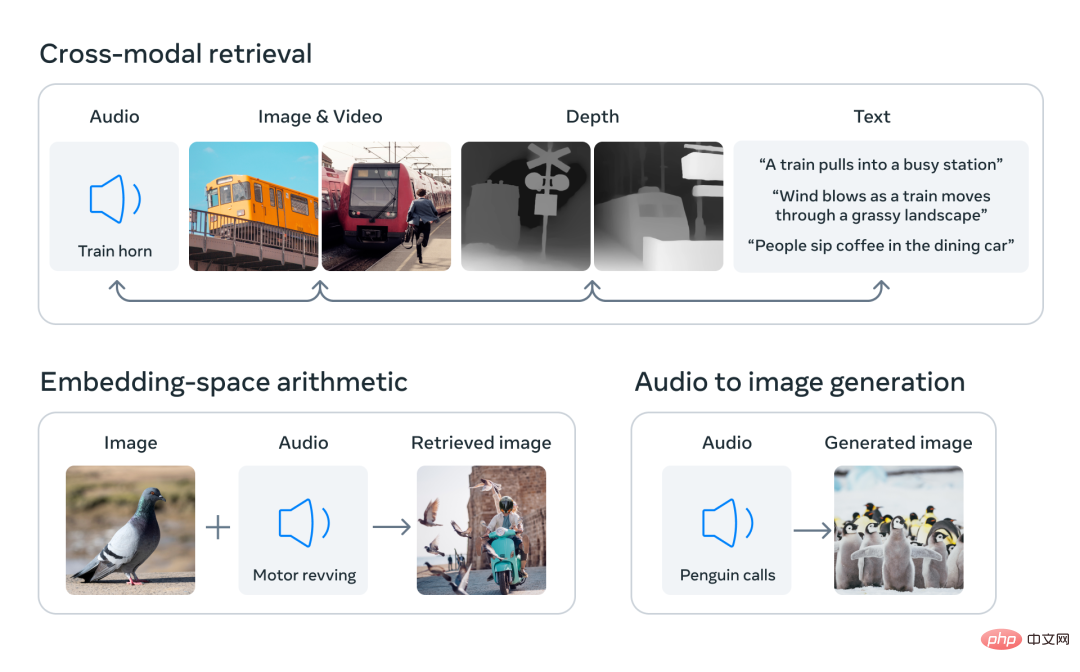
En alignant les intégrations de six modalités dans un espace commun, ImageBind peut récupérer différents types de contenu qui ne sont pas observés simultanément dans toutes les modalités, en ajoutant des intégrations de différentes modalités pour combiner naturellement leur sémantique et utilisez les intégrations audio de Meta AI avec un décodeur DALLE-2 pré-entraîné (conçu pour être utilisé avec l'intégration de texte CLIP) pour réaliser la génération audio-image.
Il existe un grand nombre d'images apparaissant avec du texte sur Internet, c'est pourquoi la formation de modèles image-texte a été largement étudiée. ImageBind tire parti des propriétés de liaison des images qui peuvent être connectées selon diverses modalités, telles que la connexion de texte à des images à l'aide de données réseau ou la connexion d'un mouvement à une vidéo à l'aide de données vidéo capturées dans une caméra portable dotée d'un capteur IMU.
Les représentations visuelles apprises à partir de données de réseau à grande échelle peuvent être utilisées comme cibles pour l'apprentissage de différentes fonctionnalités modales. Cela permet à ImageBind d'aligner l'image avec toutes les modalités présentes en même temps, en alignant naturellement ces modalités les unes avec les autres. Les modalités telles que les cartes thermiques et les cartes de profondeur qui ont une forte corrélation avec les images sont plus faciles à aligner. Les modalités non visuelles telles que l'audio et l'IMU (unité de mesure inertielle) ont des corrélations plus faibles. Par exemple, des sons spécifiques tels que les pleurs d'un bébé peuvent correspondre à divers arrière-plans visuels.
ImageBind montre que les données d'appariement d'images sont suffisantes pour lier ces six modalités ensemble. Le modèle peut expliquer le contenu de manière plus complète, permettant à différentes modalités de « communiquer » entre elles et de trouver des liens entre elles sans les observer simultanément. Par exemple, ImageBind peut lier l'audio et le texte sans les observer ensemble. Cela permet à d'autres modèles de « comprendre » de nouvelles modalités sans nécessiter de formation gourmande en ressources.
Les puissantes performances de mise à l'échelle d'ImageBind permettent à ce modèle de remplacer ou d'améliorer de nombreux modèles d'intelligence artificielle, leur permettant d'utiliser d'autres modalités. Par exemple, alors que Make-A-Scene peut générer une image à l'aide d'une invite de texte, ImageBind peut la mettre à niveau pour générer une image à l'aide d'audio, comme le rire ou le bruit de la pluie.
Performances supérieures d'ImageBind
L'analyse de Meta montre que le comportement de mise à l'échelle d'ImageBind s'améliore avec la puissance de l'encodeur d'image. En d’autres termes, la capacité d’ImageBind à aligner les modalités s’adapte à la puissance et à la taille du modèle visuel. Cela suggère que des modèles visuels plus grands sont bénéfiques pour les tâches non visuelles, telles que la classification audio, et que les avantages de la formation de tels modèles s'étendent au-delà des tâches de vision par ordinateur.
Dans le cadre d'expériences, Meta a utilisé les encodeurs audio et de profondeur d'ImageBind et les a comparés aux travaux antérieurs sur la récupération de plans zéro et les tâches de classification audio et de profondeur.
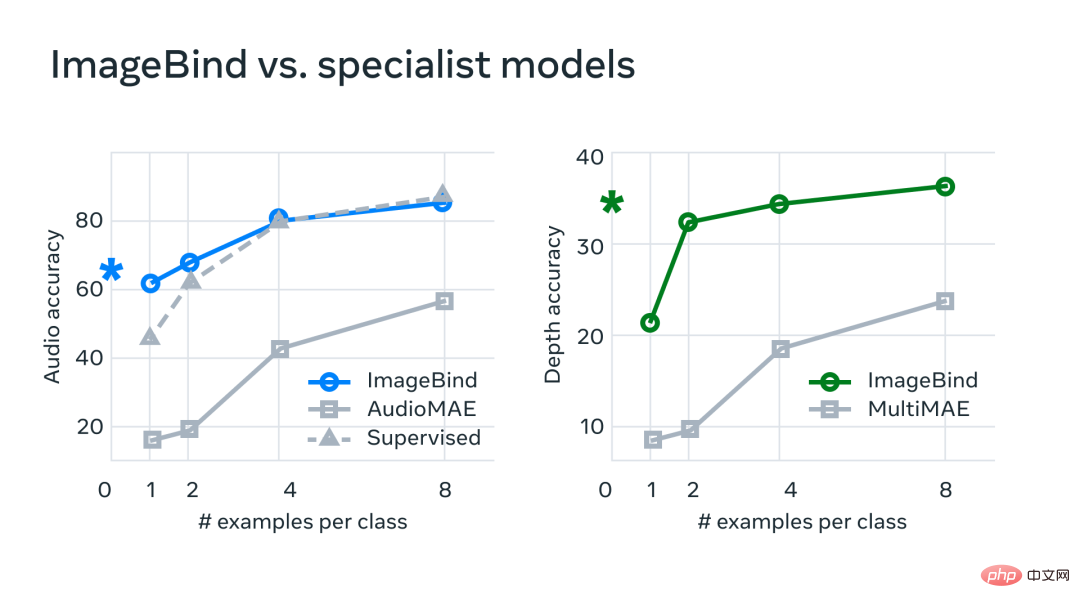
Sur les benchmarks, ImageBind surpasse les modèles experts en audio et en profondeur.
Meta a découvert qu'ImageBind peut être utilisé pour des tâches audio de quelques prises de vue et de classification approfondie et surpasse les méthodes personnalisées précédentes. Par exemple, ImageBind surpasse considérablement le modèle AudioMAE auto-supervisé de Meta formé sur Audioset, ainsi que son modèle AudioMAE supervisé affiné sur la classification audio.
De plus, ImageBind atteint de nouvelles performances SOTA sur la tâche de reconnaissance intermodale sans tir, surpassant même les modèles de pointe formés pour reconnaître les concepts dans cette modalité.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI