
Maison >Java >javaDidacticiel >Comment le multithreading Java assemble-t-il des unités de calcul asynchrones via CompletableFuture ?
Comment le multithreading Java assemble-t-il des unités de calcul asynchrones via CompletableFuture ?

- 王林avant
- 2023-05-11 19:04:041321parcourir
CompletableFuture Introduction
CompletableFuture est une nouvelle fonctionnalité introduite dans la version 1.8. Certains scénarios de calcul asynchrone plus complexes, en particulier ceux qui nécessitent la connexion de plusieurs unités informatiques asynchrones en série, peuvent être implémentés à l'aide de CompletableFuture.
Dans le monde réel, les problèmes complexes que nous devons résoudre doivent être divisés en plusieurs étapes. Tout comme notre code, dans une méthode logique complexe, plusieurs méthodes seront appelées pour l'implémenter étape par étape.
Imaginez le scénario suivant. Vous devez planter des arbres le jour de l'arbre, qui est divisé en les étapes suivantes :
creuser un trou pendant 10 minutes
obtenir un jeune arbre pendant 5 minutes
planter un arbre. jeune arbre pendant 20 minutes
arroser 5 minutes
Parmi eux, 1 et 2 peuvent être effectués en parallèle. Ce n'est que lorsque 1 et 2 sont terminés que l'étape 3 peut être effectuée, puis l'étape 4 peut être effectuée.
Nous avons les méthodes de mise en œuvre suivantes :
Une seule personne plante des arbres
S'il n'y a qu'une seule personne qui plante des arbres maintenant et que 100 arbres doivent être plantés, alors cela ne peut être fait que dans l'ordre suivant :
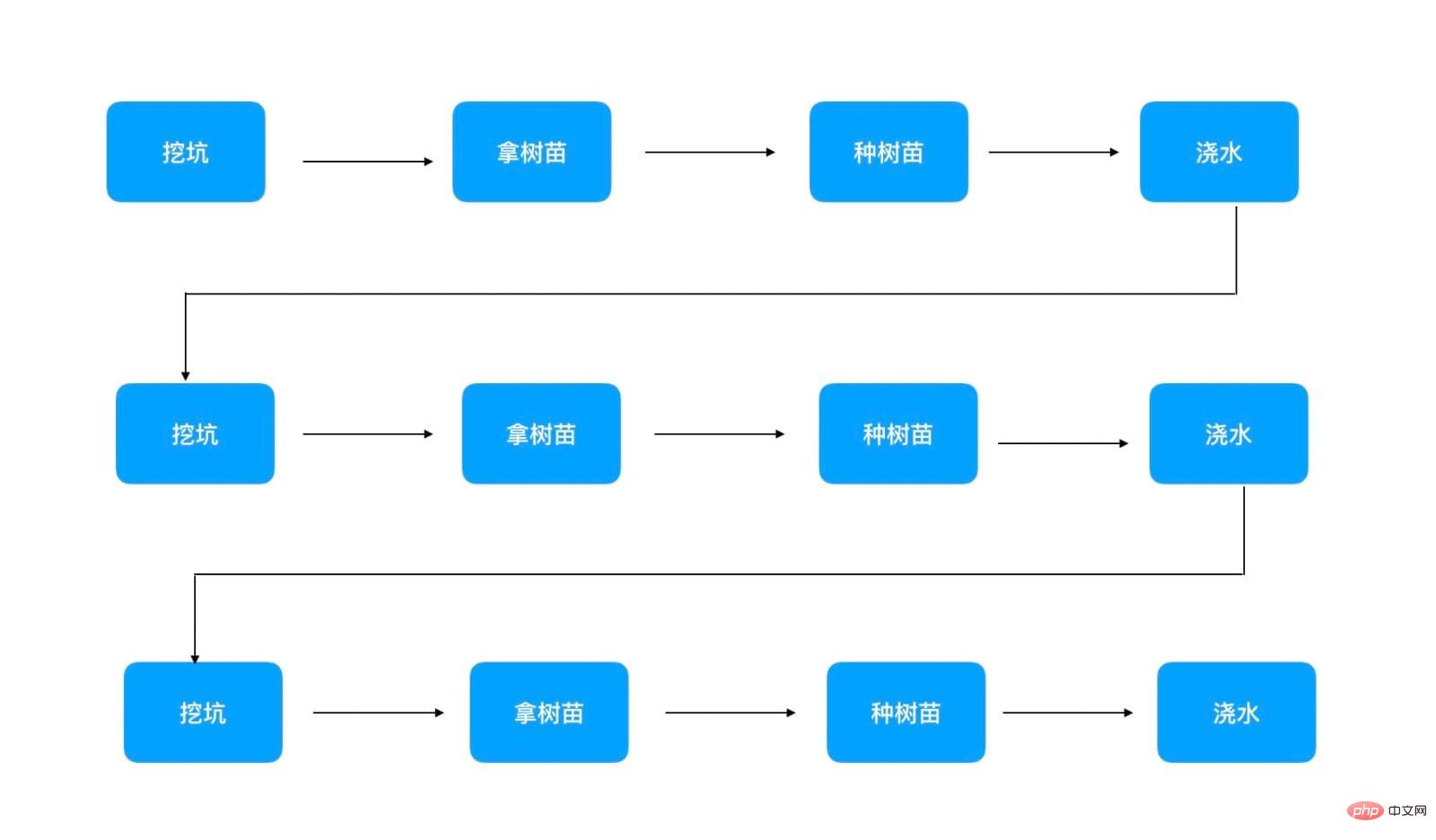
Seules les espèces sont répertoriées sur la photo Trois Arbres signalés. Vous pouvez voir qu'en exécution en série, vous ne pouvez planter qu'un arbre après l'autre, il faut donc 40 * 100 = 4000 分钟 pour planter 100 arbres. Cette méthode correspond au programme, qui est une exécution synchrone monothread.
Trois personnes plantent des arbres en même temps, chaque personne est responsable de planter un arbre
Comment raccourcir le temps de plantation d'un arbre ? Vous devez penser que ce n’est pas facile à gérer. Après avoir étudié la concurrence pendant si longtemps, ce n’est certainement pas un problème pour moi. Vous ne voulez pas planter 100 arbres ? Ensuite, je trouverai 100 personnes à planter ensemble, et chaque personne plantera un arbre. Il ne faut alors que 40 minutes pour planter 100 arbres.
Oui, si votre programme a une méthode appelée plantTree, qui contient les quatre parties ci-dessus, alors vous n'avez besoin que de 100 threads. Attention cependant, la création et la destruction de 100 threads consomment beaucoup de ressources système. Et créer et détruire des threads prend du temps. De plus, le nombre de cœurs du CPU ne peut pas réellement supporter 100 threads simultanément. Et si on voulait planter 10 000 arbres ? Vous ne pouvez pas avoir 10 000 fils de discussion, n'est-ce pas ?
C'est donc juste une situation idéale. Nous l'exécutons généralement via le pool de threads et ne démarrerons pas réellement 100 threads.
Plusieurs personnes plantent des arbres en même temps
Lors de la plantation de chaque arbre, les étapes indépendantes peuvent être effectuées par différentes personnes en parallèle
Cette méthode peut encore raccourcir le temps de plantation des arbres, car la première étape consiste à creuser un trou et la deuxième étape consiste à creuser un trou à deux personnes en parallèle, donc chaque arbre ne prend que 35 minutes. Comme indiqué ci-dessous :
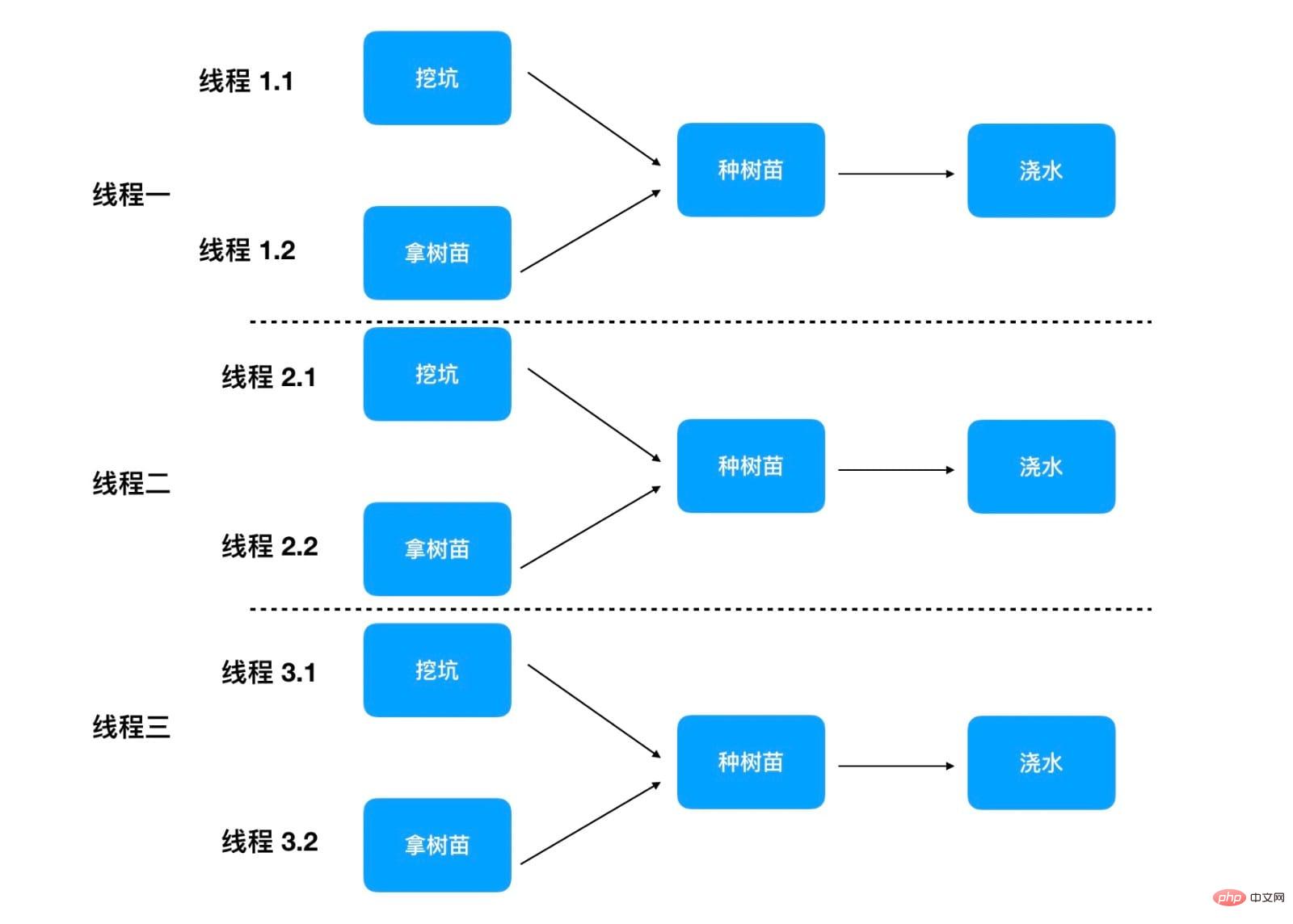
Si le programme dispose encore de 100 threads principaux exécutant simultanément la méthode plantTree, alors il ne faut que 35 minutes pour planter 100 arbres. Ici, vous devez faire attention à chaque thread, car il existe deux threads pour effectuer les étapes 1 et 2 simultanément. En fonctionnement réel, 100 x 3 = 300 fils participeront à la plantation d'arbres. Mais le fil de discussion responsable des étapes 1 et 2 ne participera que brièvement, puis deviendra inactif.
Cette méthode et la deuxième méthode ont également le problème de créer un grand nombre de fils de discussion. C'est donc juste une situation idéale.
Supposons qu'il n'y ait que 4 personnes qui plantent des arbres, chaque personne n'est responsable que de ses propres pas
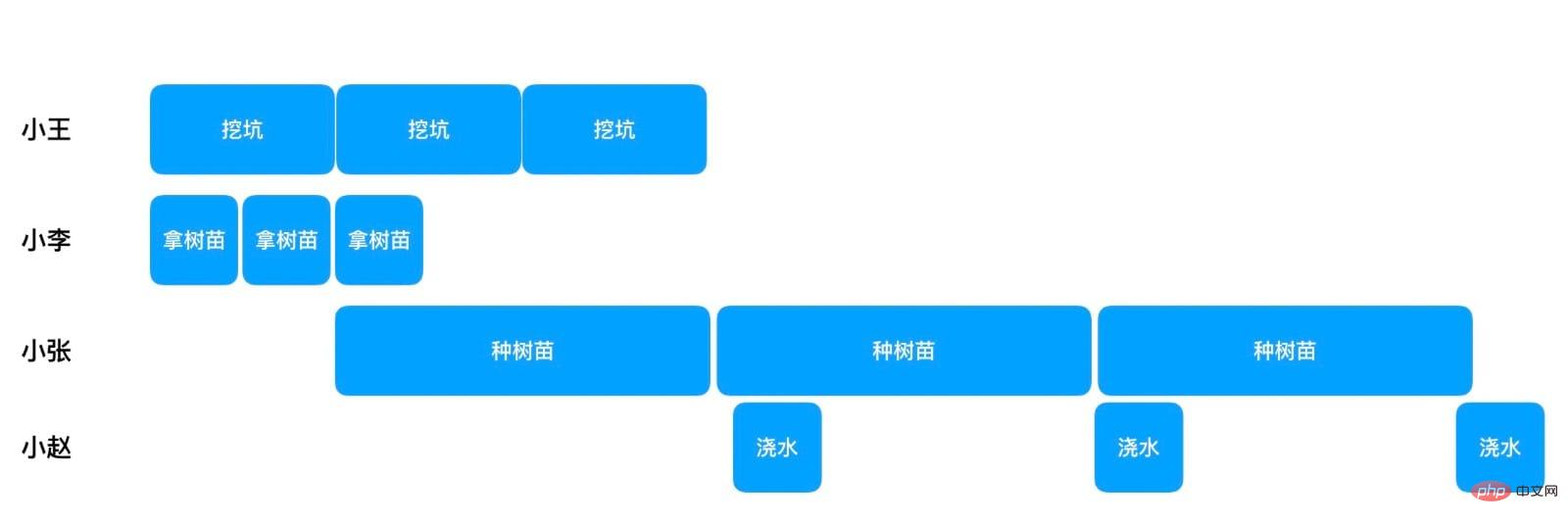
Vous pouvez voir qu'après que Xiao Wang ait creusé le premier trou, Xiao Li a déjà récupéré deux jeunes arbres, mais à ce moment-là, Xiao Zhang peut commencer à planter le premier jeune arbre. À partir de ce moment-là, Xiao Zhang peut planter des jeunes arbres un par un, et lorsqu'il plante un jeune arbre, Xiao Zhao peut l'arroser en parallèle. Suite à ce processus, il faudra 10+20x100+5=2015 minutes pour planter 100 jeunes arbres. C'est bien mieux que les 4 000 minutes d'un seul thread, mais c'est bien inférieur à la vitesse de 100 threads plantant simultanément des arbres. Mais n’oubliez pas que 100 threads simultanément ne sont qu’une situation idéale et que cette méthode n’utilise que 4 threads.
Nous apporterons quelques ajustements à la division du travail. Non seulement chacun fait son propre travail, mais une fois son propre travail terminé, il voit s’il existe un autre travail qui peut être fait. Par exemple, après que Xiao Wang ait creusé un trou et découvert qu'il pouvait planter des jeunes arbres, il plantait des jeunes arbres. Une fois que Xiao Li a fini de prendre les jeunes arbres, il peut également creuser des trous ou planter des jeunes arbres. De cette façon, l’efficacité globale sera plus élevée. Si nous nous basons sur cette idée, nous divisons en fait les tâches en 4 catégories, avec 100 tâches dans chaque catégorie, pour un total de 400 tâches. Lorsque les 400 tâches sont terminées, cela signifie que la tâche entière est terminée. Ensuite, les participants à la tâche n'ont besoin que de connaître les dépendances de la tâche, puis de recevoir en permanence des tâches exécutables à exécuter. Cette efficacité sera la plus élevée.
Comme mentionné précédemment, il nous est impossible d'exécuter des tâches via 100 threads simultanément, donc dans des circonstances normales, nous utiliserons un pool de threads, qui coïncide avec l'idée de conception ci-dessus. Après avoir utilisé le pool de threads, la quatrième méthode décompose les étapes en détails plus fins, augmentant ainsi la possibilité de concurrence. La vitesse sera donc plus rapide que la deuxième méthode. Alors par rapport au troisième type, lequel est le plus rapide ? Si le nombre de threads peut être infini, le temps minimum que ces deux méthodes peuvent atteindre est le même, 35 minutes. Cependant, lorsque les threads sont limités, la quatrième méthode utilisera les threads plus efficacement, car chaque étape peut être exécutée en parallèle (les personnes impliquées dans la plantation d'arbres peuvent aider les autres après avoir terminé leur travail), la planification des threads est plus flexible, donc les threads dans le pool de threads est difficile à inactiver et à continuer de fonctionner. Oui, personne ne peut être paresseux. La troisième méthode ne peut être utilisée qu'en même temps que la méthode plantTree, pour creuser des trous et obtenir des plants, elle n'est donc pas aussi flexible que la quatrième méthode
J'en ai tellement dit ci-dessus, principalement pour expliquer les raisons de l'émergence de CompletableFuture. Il est utilisé pour décomposer des tâches complexes en étapes d'exécution asynchrones connectées, améliorant ainsi l'efficacité globale. Revenons au sujet de la section : personne ne peut être paresseux. Oui, c'est ce que CompleteableFuture vise à réaliser. En faisant abstraction de l'unité de calcul, les threads peuvent participer à chaque étape de manière efficace et simultanée. Le code synchrone peut être complètement transformé en code asynchrone via CompletableFuture. Voyons comment utiliser CompletableFuture.
CompletableFuture utilise
CompletableFuture pour implémenter l'interface Future et implémenter l'interface CompletionStage. Nous connaissons déjà l'interface Future, et l'interface CompletionStage définit les spécifications entre les étapes de calcul asynchrones pour garantir qu'elles peuvent être connectées étape par étape. CompletionStage définit 38 méthodes publiques de connexion entre les étapes de calcul asynchrones. Ensuite, nous sélectionnerons quelques méthodes couramment utilisées et relativement fréquemment utilisées pour voir comment les utiliser.
Résultat du calcul connu
Si vous connaissez déjà le résultat du calcul de CompletableFuture, vous pouvez utiliser la méthode statiquecompleteFuture. Transmettez le résultat du calcul et déclarez l’objet CompletableFuture. Lorsque la méthode get est appelée, le résultat du calcul entrant sera renvoyé immédiatement sans être bloqué, comme le montre le code suivant :
public static void main(String[] args) throws Exception{
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("Hello World");
System.out.println("result is " + completableFuture.get());
}
// result is Hello WorldPensez-vous que cette utilisation n'a aucun sens ? Maintenant que vous connaissez le résultat du calcul, vous pouvez simplement l'utiliser directement. Pourquoi avez-vous besoin de le packager avec CompletableFuture ? En effet, les unités de calcul asynchrones doivent être connectées via CompletableFuture, donc parfois même si nous connaissons déjà les résultats du calcul, nous devons les regrouper dans CompletableFuture pour les intégrer dans le processus de calcul asynchrone.
Encapsuler la logique de calcul asynchrone avec la valeur de retour
C'est notre méthode la plus couramment utilisée. Encapsulez la logique qui nécessite un calcul asynchrone dans une unité de calcul et transmettez-la à CompletableFuture pour qu'elle l'exécute. Comme dans le code suivant :
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成Ici nous utilisons la méthode supplyAsync de CompletableFuture et lui passons une implémentation de l'interface fournisseur sous la forme d'une expression lambda.
On peut voir que le résultat du calcul obtenu par completableFuture.get() est la valeur de retour après l'exécution de la fonction que vous transmettez. Ensuite, si vous avez une logique qui nécessite un calcul asynchrone, vous pouvez la placer dans le corps de la fonction transmis par supplyAsync. Comment cette fonction est-elle exécutée de manière asynchrone ? Si vous suivez le code, vous pouvez voir que supplyAsync exécute réellement cette fonction via l'exécuteur, qui est le pool de threads. completableFuture utilise ForkJoinPool par défaut. Bien sûr, vous pouvez également spécifier d'autres Excutors pour supplyAsync et le transmettre à la méthode supplyAsync via le deuxième paramètre.
supplyAsync a de nombreux scénarios d'utilisation. Pour un exemple simple, le programme principal doit appeler les interfaces de plusieurs microservices pour demander des données. Il peut ensuite démarrer plusieurs CompletableFutures et appeler supplyAsync. De cette façon, différentes requêtes d'interface peuvent s'exécuter de manière asynchrone et simultanée, et finalement lorsque toutes les interfaces reviennent, la logique suivante sera exécutée.
Encapsuler la logique de calcul asynchrone sans valeur de retour
La fonction reçue par supplyAsync a une valeur de retour. Dans certains cas, il s’agit simplement d’un processus de calcul et nous n’avons pas besoin de renvoyer de valeur. C'est comme la méthode run de Runnable, qui ne renvoie pas de valeur. Dans ce cas nous pouvons utiliser la méthode runAsync, comme indiqué dans le code suivant :
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> System.out.println("挖坑完成"));
completableFuture.get();
}
// 挖坑完成runAsync reçoit la fonction de l'interface exécutable. Il n’y a donc aucune valeur de retour. La logique dans Chestnut imprime simplement "Creuser terminé".
Traitez davantage les résultats renvoyés de manière asynchrone et renvoyez de nouveaux résultats de calcul
Lorsque nous terminons le calcul asynchrone via supplyAsync et renvoyons CompletableFuture, nous pouvons continuer à traiter les résultats renvoyés, comme le code suivant :
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenApply(s -> s + ", 并且归还铁锹")
.thenApply(s -> s + ", 全部完成。");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹, 全部完成。Appelez supplyAsync Enfin, nous chaîne appelle la méthode thenApply deux fois. s est le résultat du calcul renvoyé par supplyAsync à l'étape précédente. Nous avons retraité le résultat du calcul deux fois. Nous pouvons traiter en continu les résultats du calcul via thenApply. Si vous souhaitez exécuter la logique de thenApply de manière asynchrone, vous pouvez utiliser thenApplyAsync. La méthode d'utilisation est la même, mais elle s'exécutera de manière asynchrone via le pool de threads.
进一步处理异步返回的结果,无返回
这种场景你可以使用thenApply。这个方法可以让你处理上一步的返回结果,但无返回值。参照如下代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"));
completableFuture.get();
}这里可以看到 thenAccept 接收的函数没有返回值,只有业务逻辑。处理后返回 CompletableFuture 类型对象。
既不需要返回值,也不需要上一步计算结果,只想在执行结束后再执行一段代码
此时你可以使用 thenRun 方法,他接收 Runnable 的函数,没有输入也没有输出,仅仅是在异步计算结束后回调一段逻辑,比如记录 log 等。参照下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"))
.thenRun(() -> System.out.println("挖坑工作已经全部完成"));
completableFuture.get();
}
// 挖坑完成, 并且归还铁锹
// 挖坑工作已经全部完成可以看到在 thenAccept 之后继续调用了 thenRun,仅仅是打印了日志而已
组合 Future 处理逻辑
我们可以把两个 CompletableFuture 组合起来使用,如下面的代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + ", 并且归还铁锹"));
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹thenApply 和 thenCompose 的关系就像 stream中的 map 和 flatmap。从上面的例子来看,thenApply 和thenCompose 都可以实现同样的功能。但是如果你使用一个第三方的库,有一个API返回的是CompletableFuture 类型,那么你就只能使用 thenCompose方法。
组合Futurue结果
如果你有两个异步操作互相没有依赖,但是第三步操作依赖前两部计算的结果,那么你可以使用 thenCombine 方法来实现,如下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCombine(CompletableFuture.supplyAsync(() -> ", 拿树苗完成"), (x, y) -> x + y + "植树完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 拿树苗完成植树完成挖坑和拿树苗可以同时进行,但是第三步植树则祖尧前两步完成后才能进行。
可以看到符合我们的预期。使用场景之前也提到过。我们调用多个微服务的接口时,可以使用这种方式进行组合。处理接口调用间的依赖关系。 当你需要两个 Future 的结果,但是不需要再加工后向下游传递计算结果时,可以使用 thenAcceptBoth,用法一样,只不过接收的函数没有返回值。
并行处理多个 Future
假如我们对微服务接口的调用不止两个,并且还有一些其它可以异步执行的逻辑。主流程需要等待这些所有的异步操作都返回时,才能继续往下执行。此时我们可以使用 CompletableFuture.allOf 方法。它接收 n 个 CompletableFuture,返回一个 CompletableFuture。对其调用 get 方法后,只有所有的 CompletableFuture 全完成时才会继续后面的逻辑。我们看下面示例代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("挖坑完成");
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取树苗完成");
});
CompletableFuture<Void> future3 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取肥料完成");
});
CompletableFuture.allOf(future1, future2, future3).get();
System.out.println("植树准备工作完成!");
}
// 挖坑完成
// 取肥料完成
// 取树苗完成
// 植树准备工作完成!异常处理
在异步计算链中的异常处理可以采用 handle 方法,它接收两个参数,第一个参数是计算及过,第二个参数是异步计算链中抛出的异常。使用方法如下:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
if (1 == 1) {
throw new RuntimeException("Computation error");
}
return "挖坑完成";
}).handle((result, throwable) -> {
if (result == null) {
return "挖坑异常";
}
return result;
});
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑异常代码中会抛出一个 RuntimeException,抛出这个异常时 result 为 null,而 throwable 不为null。根据这些信息你可以在 handle 中进行处理,如果抛出的异常种类很多,你可以判断 throwable 的类型,来选择不同的处理逻辑。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!