

 Périphériques technologiquesIALa vitesse de formation est augmentée de 17 %. Le cadre de recherche sur l'apprentissage par renforcement open source du quatrième paradigme prend en charge la formation mono-agent et multi-agents.
Périphériques technologiquesIALa vitesse de formation est augmentée de 17 %. Le cadre de recherche sur l'apprentissage par renforcement open source du quatrième paradigme prend en charge la formation mono-agent et multi-agents.
OpenRL est un cadre de recherche d'apprentissage par renforcement basé sur PyTorch développé par l'équipe d'apprentissage par renforcement Fourth Paradigm. Il prend en charge la formation de tâches mono-agent, multi-agents, en langage naturel et autres. OpenRL est développé sur la base de PyTorch, dans le but de fournir à la communauté de recherche sur l'apprentissage par renforcement une plate-forme facile à utiliser, flexible, efficace et durablement évolutive. Actuellement, les fonctionnalités prises en charge par OpenRL incluent :
- Une interface commune facile à utiliser et prenant en charge la formation mono-agent et multi-agent
- Prend en charge la formation par apprentissage par renforcement pour les tâches en langage naturel (telles que les tâches de dialogue)
- Prend en charge l'importation de modèles et de données depuis Hugging Face
- Prend en charge LSTM, GRU, Transformer et d'autres modèles
- Prend en charge une variété d'accélérations d'entraînement, telles que : l'entraînement automatique de précision mixte, les données de réseau de politique de demi-précision collection, etc.
- Modèles d'entraînement définis par l'utilisateur, modèles de récompense, données et environnements d'entraînement pris en charge
- Prise en charge de l'environnement du gymnase
- Prise en charge de l'espace d'observation du dictionnaire
- Prise en charge de wandb, tensorboardX et d'autres visualisations d'entraînement grand public outils
- Prend en charge la sérialisation de l'environnement et la formation parallèle, tout en garantissant des effets de formation cohérents dans les deux modes
- Documentation en chinois et en anglais
- Fournir des tests unitaires et des tests de couverture de code
- Se conformer au style Black Code et vérification de type
Actuellement, OpenRL est open source sur GitHub :

Adresse du projet : https://github.com/OpenRL-Lab/openrl
Première expérience avec OpenRL
OpenRL peut actuellement être installé via pip :
<code>pip install openrl</code>
peut également être installé via conda :
<code>conda install -c openrl openrl</code>
OpenRL fournit une interface simple et facile à utiliser pour les utilisateurs débutants de l'apprentissage par renforcement. un exemple d'utilisation de l'algorithme PPO pour former l'environnement CartPole :
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>
Utiliser OpenRL pour former des agents Seules quatre étapes simples sont nécessaires : Créer un environnement=> Initialiser le modèle=>
Exécutez le code ci-dessus sur un ordinateur portable ordinaire, et cela ne prend que quelques secondes pour terminer la formation de l'agent :
De plus, pour le multi-agent, le langage naturel et autres tâches Pour la formation, OpenRL fournit également la même interface simple et facile à utiliser. Par exemple, pour l'environnement MPE dans les tâches multi-agents, OpenRL n'a besoin d'appeler que quelques lignes de code pour terminer la formation :
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>
La figure suivante montre les performances de l'agent avant et après la formation via OpenRL :
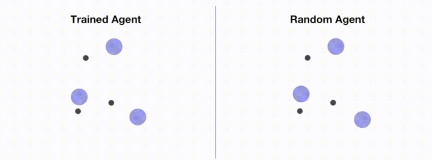
De plus, OpenRL prend également en charge la modification des paramètres d'entraînement à partir de la ligne de commande et des fichiers de configuration. Par exemple, les utilisateurs peuvent modifier rapidement le taux d'apprentissage pendant l'entraînement en exécutant python train_ppo.py --lr 5e-4.
Lorsqu'il existe de nombreux paramètres de configuration, OpenRL permet également aux utilisateurs d'écrire leurs propres fichiers de configuration pour modifier les paramètres de formation. Par exemple, les utilisateurs peuvent créer le fichier de configuration suivant (mpe_ppo.yaml) et y modifier les paramètres :
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
Enfin, les utilisateurs n'ont qu'à spécifier le fichier de configuration lors de l'exécution du programme :
<code>python train_ppo.py --config mpe_ppo.yaml</code>
训练与测试可视化
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:

OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化:
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code>
此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
<code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
智能体的保存和加载
OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作:
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>
执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>
上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>
然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>
自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>
OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>
最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>
自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
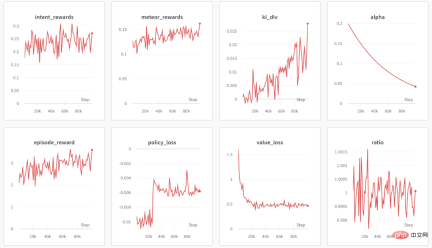
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>
最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
对比评测
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
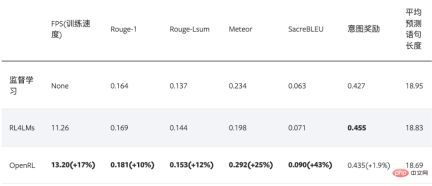
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>
执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
- OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
- OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
- Stable-baselines3 : https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail : https://github.com/ikostrikov/pytorch-a2c- ppo-acktr-gail
- MAPPO : https://github.com/marlbenchmark/on-policy
- Gymnasium : https://github.com/Farama-Foundation/Gymnasium
- DI-engine :https://github.com/opendilab/DI-engine/
- Tianshou : https://github.com/thu-ml/tianshou
- RL4LMs : https://github.com/allenai/ RL4LMs
Travaux futurs
Actuellement, OpenRL est encore en phase de développement et de construction continus. À l'avenir, OpenRL ouvrira davantage de fonctionnalités :
- Formation en auto-jeu pour les agents de support
- Ajouter. apprentissage par renforcement hors ligne, apprentissage par modèle, algorithme d'apprentissage par renforcement inverse
- Ajouter davantage d'environnements et d'algorithmes d'apprentissage par renforcement
- Intégrer des cadres d'accélération tels que Deepspeed
- Prise en charge de la formation distribuée multi-machines
Équipe OpenRL Lab
Framework OpenRL Il a été développé par l'équipe OpenRL Lab, qui est l'équipe de recherche sur l'apprentissage par renforcement de 4Paradigm. Fourth Paradigm s'engage depuis longtemps dans la recherche, le développement et l'application industrielle de l'apprentissage par renforcement. Afin de promouvoir l'intégration de l'industrie, du monde universitaire et de la recherche dans l'apprentissage par renforcement, 4Paradigm a créé l'équipe de recherche OpenRL Lab, dans le but de développer une technologie avancée open source et d'explorer les frontières de l'intelligence artificielle. Moins d'un an après sa création, l'équipe OpenRL Lab a publié trois articles dans AAMAS, participé au concours Google Football Game 11 vs 11 et remporté la troisième place. L'agent TiZero proposé par l'équipe est le premier à compléter la formation d'agent de jeu complet de Google Football à partir de zéro grâce à l'apprentissage du curriculum, à l'apprentissage par renforcement distribué, au self-gaming et à d'autres technologies :

À partir de 2022 Le 28 octobre, Tizero s'est classé premier sur la plateforme d'évaluation Jidi :

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 La nouvelle compilation annuelle des meilleures techniques d'ingénierie rapideApr 10, 2025 am 11:22 AM
La nouvelle compilation annuelle des meilleures techniques d'ingénierie rapideApr 10, 2025 am 11:22 AMPour ceux d'entre vous qui pourraient être nouveaux dans ma chronique, j'explore largement les dernières avancées de l'IA dans tous les domaines, y compris des sujets tels que l'IA incarnée, le raisonnement de l'IA, les percées de haute technologie dans l'IA, l'ingénierie rapide, la formation de l'IA, la mise en place de l'IA, l'IA re
 Plan d'action du continent de l'IA en Europe: gigafactories, laboratoires de données et IA verteApr 10, 2025 am 11:21 AM
Plan d'action du continent de l'IA en Europe: gigafactories, laboratoires de données et IA verteApr 10, 2025 am 11:21 AMLe plan d'action ambitieux de l'IA de l'IA d'Europe vise à établir l'UE en tant que leader mondial de l'intelligence artificielle. Un élément clé est la création d'un réseau de gigafactories d'IA, chacun abritant environ 100 000 puces AI avancées - quatre fois le capaci
 L'histoire d'agent simple de Microsoft est-elle suffisante pour créer plus de fans?Apr 10, 2025 am 11:20 AM
L'histoire d'agent simple de Microsoft est-elle suffisante pour créer plus de fans?Apr 10, 2025 am 11:20 AML'approche unifiée de Microsoft des applications d'agent d'IA: une victoire claire pour les entreprises L'annonce récente de Microsoft concernant les nouvelles capacités d'agent d'IA impressionné par sa présentation claire et unifiée. Contrairement à de nombreuses annonces technologiques enlisées dans TE
 Vendre une stratégie d'IA aux employés: le manifeste du PDG de ShopifyApr 10, 2025 am 11:19 AM
Vendre une stratégie d'IA aux employés: le manifeste du PDG de ShopifyApr 10, 2025 am 11:19 AMLa récente note du PDG de Shopify Tobi Lütke déclare hardiment la maîtrise de l'IA une attente fondamentale pour chaque employé, marquant un changement culturel important au sein de l'entreprise. Ce n'est pas une tendance éphémère; C'est un nouveau paradigme opérationnel intégré à P
 IBM lance le mainframe Z17 avec une intégration complète de l'IAApr 10, 2025 am 11:18 AM
IBM lance le mainframe Z17 avec une intégration complète de l'IAApr 10, 2025 am 11:18 AMMAINTRADE Z17 d'IBM: intégration de l'IA pour les opérations commerciales améliorées Le mois dernier, au siège de New York d'IBM, j'ai reçu un aperçu des capacités du Z17. S'appuyant sur le succès du Z16 (lancé en 2022 et démontrant une augmentation des revenus soutenus
 5 Chatgpt invite à s'arrêter en fonction des autres et à vous faire confiance pleinementApr 10, 2025 am 11:17 AM
5 Chatgpt invite à s'arrêter en fonction des autres et à vous faire confiance pleinementApr 10, 2025 am 11:17 AMDéverrouiller une confiance inébranlable et éliminer le besoin de validation externe! Ces cinq invites Chatgpt vous guideront vers une autonomie complète et un changement transformateur de la perception de soi. Copiez, collez simplement et personnalisez le crochet dans
 L'IA est dangereusement similaire à votre espritApr 10, 2025 am 11:16 AM
L'IA est dangereusement similaire à votre espritApr 10, 2025 am 11:16 AMUne récente [étude] d'Anthropic, une société de sécurité et de recherche sur l'intelligence artificielle, commence à révéler la vérité sur ces processus complexes, montrant une complexité qui est avec inquiétude à notre propre domaine cognitif. L'intelligence naturelle et l'intelligence artificielle peuvent être plus similaires que nous ne le pensons. Espection à l'intérieur: étude d'interprétabilité anthropique Les nouvelles découvertes de la recherche menée par anthropique représentent des progrès importants dans le domaine de l'interprétabilité mécaniste, qui vise à rétro-ingénieur l'informatique interne de l'IA - pas simplement d'observer ce que fait l'IA, mais comprend comment il le fait au niveau des neurones artificiels. Imaginez essayer de comprendre le cerveau en dessinant ce que les neurones tirent lorsque quelqu'un voit un objet spécifique ou pense à une idée spécifique. UN
 Dragonwing met en valeur l'élan Edge de QualcommApr 10, 2025 am 11:14 AM
Dragonwing met en valeur l'élan Edge de QualcommApr 10, 2025 am 11:14 AMDragonwing de Qualcomm: un bond stratégique dans l'entreprise et l'infrastructure Qualcomm étend agressivement sa portée au-delà du mobile, ciblant les marchés d'entreprise et d'infrastructure dans le monde avec sa nouvelle marque Dragonwing. Ce n'est pas simplement un rebran


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

mPDF
mPDF est une bibliothèque PHP qui peut générer des fichiers PDF à partir de HTML encodé en UTF-8. L'auteur original, Ian Back, a écrit mPDF pour générer des fichiers PDF « à la volée » depuis son site Web et gérer différentes langues. Il est plus lent et produit des fichiers plus volumineux lors de l'utilisation de polices Unicode que les scripts originaux comme HTML2FPDF, mais prend en charge les styles CSS, etc. et présente de nombreuses améliorations. Prend en charge presque toutes les langues, y compris RTL (arabe et hébreu) et CJK (chinois, japonais et coréen). Prend en charge les éléments imbriqués au niveau du bloc (tels que P, DIV),

SublimeText3 Linux nouvelle version
Dernière version de SublimeText3 Linux

MantisBT
Mantis est un outil Web de suivi des défauts facile à déployer, conçu pour faciliter le suivi des défauts des produits. Cela nécessite PHP, MySQL et un serveur Web. Découvrez nos services de démonstration et d'hébergement.

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Navigateur d'examen sécurisé
Safe Exam Browser est un environnement de navigation sécurisé permettant de passer des examens en ligne en toute sécurité. Ce logiciel transforme n'importe quel ordinateur en poste de travail sécurisé. Il contrôle l'accès à n'importe quel utilitaire et empêche les étudiants d'utiliser des ressources non autorisées.

