
Maison >développement back-end >Tutoriel Python >Analyse d'exemples d'opérations courantes de ndarray en Python Numpy
Analyse d'exemples d'opérations courantes de ndarray en Python Numpy

- PHPzavant
- 2023-05-10 16:25:141332parcourir
Avant-propos
NumPy (Numerical Python) est une extension de calcul numérique open source pour Python. Cet outil peut être utilisé pour stocker et traiter de grandes matrices. Il est beaucoup plus efficace que la propre structure de liste imbriquée de Python (qui peut également être utilisée pour représenter des matrices) et prend en charge un grand nombre d'opérations sur les tableaux dimensionnels et les matrices. fournit également un grand nombre de bibliothèques de fonctions mathématiques pour les opérations sur les tableaux.
Numpy utilise principalement ndarray pour traiter les tableaux à N dimensions. La plupart des propriétés et méthodes de Numpy servent ndarray, il est donc très nécessaire de maîtriser les opérations courantes de ndarray dans Numpy !
0 Bases de Numpy
L'objet principal de NumPy sont les tableaux multidimensionnels isomorphes. Il s'agit d'une liste d'éléments (généralement des nombres), tous du même type, indexés par un tuple d'entiers non négatifs. Axe appelé dans les dimensions NumPy.
Dans l'exemple ci-dessous, le tableau comporte 2 axes. La longueur du premier axe est 2 et la longueur du deuxième axe est 3.
[[ 1., 0., 0.], [ 0., 1., 2.]]
1 Propriétés de ndarray
1.1 Propriétés communes de sortie de ndarray
ndarray.ndim : Le nombre d'axes (dimensions) du tableau. Dans le monde Python, le nombre de dimensions est appelé rang.
ndarray.shape : Les dimensions du tableau. Il s'agit d'un tuple d'entiers représentant la taille du tableau dans chaque dimension. Pour une matrice avec n lignes et m colonnes, la forme sera (n,m). Par conséquent, la longueur du tuple de forme est le rang ou le nombre de dimensions ndim.
ndarray.size : Le nombre total d'éléments du tableau. Ceci est égal au produit des éléments de forme.
ndarray.dtype : Un objet décrivant le type d'éléments dans le tableau. Un type peut être créé ou spécifié à l'aide de types Python standard. De plus, NumPy fournit ses propres types. Par exemple numpy.int32, numpy.int16 et numpy.float64.
ndarray.itemsize : La taille en octets de chaque élément du tableau. Par exemple, un tableau avec des éléments de type float64 a une taille d'élément de 8 (=64/8), tandis qu'un tableau de type complexe32 a une taille d'élément de 4 (=32/8). Il est égal à ndarray.dtype.itemsize.
>>> import numpy as np
>>> a = np.arange(15).reshape(3, 5)
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name
'int64'
>>> a.itemsize
8
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8])
>>> b
array([6, 7, 8])
>>> type(b)
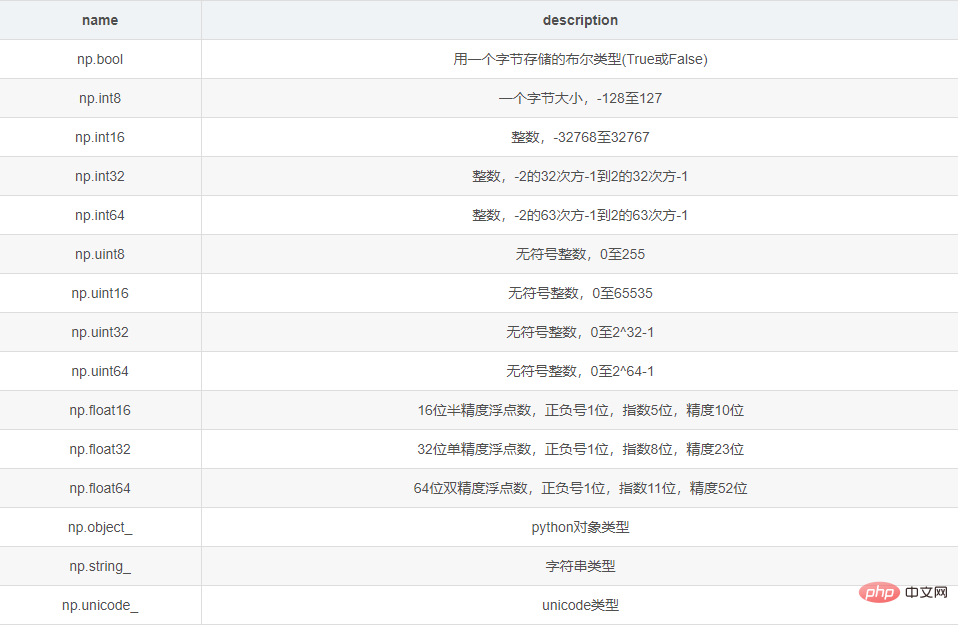
<type 'numpy.ndarray'>2 Type de données de ndarray
Dans le même ndarray, le même type de données est stocké. Les types de données courants de ndarray incluent :
3 Modifier la forme et le type de données de ndarray
. 3.1 Afficher et modifier la forme de ndarray
## ndarray reshape操作 array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.shape) array_a_1 = array_a.reshape((3, 2)) print(array_a_1, array_a_1.shape) # note: reshape不能改变ndarray中元素的个数,例如reshape之前为(2,3),reshape之后为(3,2)/(1,6)... ## ndarray转置 array_a_2 = array_a.T print(array_a_2, array_a_2.shape) ## ndarray ravel操作:将ndarray展平 a.ravel() # returns the array, flattened array([ 1, 2, 3, 4, 5, 6 ]) 输出: [[1 2 3] [4 5 6]] (2, 3) [[1 2] [3 4] [5 6]] (3, 2) [[1 4] [2 5] [3 6]] (3, 2)
3.2 Afficher et modifier le type de données de ndarray
astype(dtype[, order, casting, subok, copy]) : modifier le type de données dans ndarray. Transmettez le type de données qui doit être modifié et les autres paramètres de mots-clés peuvent être ignorés.
array_a = np.array([[1, 2, 3], [4, 5, 6]]) print(array_a, array_a.dtype) array_a_1 = array_a.astype(np.int64) print(array_a_1, array_a_1.dtype) 输出: [[1 2 3] [4 5 6]] int32 [[1 2 3] [4 5 6]] int64
4 Création de tableaux ndarray
NumPy crée principalement des tableaux ndarray via la fonction np.array(). np.array()函数来创建ndarray数组。
>>> import numpy as np >>> a = np.array([2,3,4]) >>> a array([2, 3, 4]) >>> a.dtype dtype('int64') >>> b = np.array([1.2, 3.5, 5.1]) >>> b.dtype dtype('float64')
也可以在创建时显式指定数组的类型:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])也可以通过使用np.random.random函数来创建随机的ndarray数组。
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组。这就减少了数组增长的必要,因为数组增长的操作花费很大。
函数zeros创建一个由0组成的数组,函数 ones创建一个完整的数组,函数empty 创建一个数组,其初始内容是随机的,取决于内存的状态。默认情况下,创建的数组的dtype是 float64 类型的。
>>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # dtype can also be specified
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # uninitialized, output may vary
array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260],
[ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]])为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表。
>>> np.arange( 10, 30, 5 ) array([10, 15, 20, 25]) >>> np.arange( 0, 2, 0.3 ) # it accepts float arguments array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
5 ndarray数组的常见运算
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行:
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # elementwise product
array([[2, 0],
[0, 4]])
>>> A @ B # matrix product
array([[5, 4],
[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],
[3, 4]])某些操作(例如+=和 *=)会更直接更改被操作的矩阵数组而不会创建新矩阵数组。
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b is not automatically converted to integer type
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'当使用不同类型的数组进行操作时,结果数组的类型对应于更一般或更精确的数组(称为向上转换的行为)。
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum()
2.5718191614547998
>>> a.min()
0.1862602113776709
>>> a.max()
0.6852195003967595
Vous pouvez également spécifier explicitement le type du tableau lors de la création :
>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 计算每一列的和
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 计算每一行的和
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # cumulative sum along each row
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
解释:以第一行为例,0=0,1=1+0,3=2+1+0,6=3+2+1+0Vous pouvez également créer un tableau ndarray aléatoire en utilisant la fonction np.random.random. >>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # 等价于 a[0:6:2] = -1000; 从0到6的位置, 每隔一个设置为-1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, fan 216, 343, 512, 729])
>>> a[ : :-1] # 将a反转
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
Généralement, les éléments d'un tableau sont initialement inconnus, mais sa taille est connue. Par conséquent, NumPy fournit plusieurs fonctions pour créer des tableaux avec le contenu initial de l'espace réservé. Cela réduit le besoin de croissance du réseau, qui est une opération coûteuse. La fonction zéros crée un tableau composé de 0, la fonction ones crée un tableau complet, et la fonction vide crée un tableau dont le contenu initial est aléatoire, en fonction de l'état de la mémoire.
>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])Pour créer des tableaux de nombres, NumPy fournit une fonction similaire à range, qui renvoie un tableau au lieu d'une liste.
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])🎜5 Opérations courantes sur les tableaux ndarray🎜🎜Contrairement à de nombreux langages matriciels, les opérateurs de produits * opèrent par éléments dans les tableaux NumPy. Les produits matriciels peuvent être réalisés à l'aide de l'opérateur @ (en python> = 3.5) ou de la fonction ou méthode dot : 🎜>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])🎜 Certaines opérations (telles que += et <code>*=) modifieront plus directement le tableau matriciel sur lequel vous opérez sans créer un nouveau tableau matriciel. 🎜################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]🎜 Lorsque vous travaillez avec des tableaux de types différents, le type du tableau résultant correspond au tableau plus général ou précis (un comportement appelé upcasting). 🎜rrreee🎜De nombreuses opérations unaires, telles que le calcul de la somme de tous les éléments d'un tableau, sont implémentées en tant que méthodes de la classe ndarray. 🎜rrreee🎜🎜Par défaut, ces opérations fonctionnent sur un tableau comme s'il s'agissait d'une liste de nombres, quelle que soit sa forme. Cependant, en spécifiant le paramètre axis, vous pouvez appliquer des opérations le long de l'axe spécifié du tableau : 🎜🎜rrreee🎜6 Indexation, découpage et itération des tableaux ndarray 🎜🎜🎜Unidimensionnelles 🎜Les tableaux peuvent être indexés, découpés et itérés like Les listes sont comme les autres types de séquence Python. Les tableaux 🎜rrreee🎜🎜Multidimensionnels🎜 peuvent avoir un index par axe. Ces indices sont donnés sous forme de tuple séparé par des virgules : 🎜>>> b
array([[ 0, 1, 2, 3],
[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33],
[40, 41, 42, 43]])
>>> b[2,3]
23
>>> b[0:5, 1] # each row in the second column of b
array([ 1, 11, 21, 31, 41])
>>> b[ : ,1] # equivalent to the previous example
array([ 1, 11, 21, 31, 41])
>>> b[1:3, : ] # each column in the second and third row of b
array([[10, 11, 12, 13],
[20, 21, 22, 23]])
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])7 ndarray数组的堆叠、拆分
几个数组可以沿不同的轴堆叠在一起,例如:np.vstack()函数和np.hstack()函数
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])column_stack()函数将1D数组作为列堆叠到2D数组中。
>>> from numpy import newaxis
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # returns a 2D array
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # the result is different
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # this allows to have a 2D columns vector
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # the result is the same
array([[ 4., 3.],
[ 2., 8.]])使用hsplit(),可以沿数组的水平轴拆分数组,方法是指定要返回的形状相等的数组的数量,或者指定应该在其之后进行分割的列:
同理,使用vsplit(),可以沿数组的垂直轴拆分数组,方法同上。
################### np.hsplit ###################
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # Split a into 3
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # Split a after the third and the fourth column
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> x = np.arange(8.0).reshape(2, 2, 2)
>>> x
array([[[0., 1.],
[2., 3.]],
[[4., 5.],
[6., 7.]]])
################### np.vsplit ###################
>>> np.vsplit(x, 2)
[array([[[0., 1.],
[2., 3.]]]), array([[[4., 5.],
[6., 7.]]])]Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!