
Maison >développement back-end >Tutoriel Python >Dix scripts Python avancés intéressants, recommandés pour la collection !
Dix scripts Python avancés intéressants, recommandés pour la collection !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-10 14:52:061892parcourir

Bonjour à tous, je suis une recrue.
Dans notre travail quotidien, nous serons toujours confrontés à divers problèmes.
Beaucoup de ces problèmes peuvent être résolus à l'aide d'un simple code Python. Par exemple, il n'y a pas si longtemps, un patron de Fudan a utilisé 130 lignes de code Python pour compléter les statistiques sur les acides nucléiques, ce qui a considérablement amélioré l'efficacité et fait gagner beaucoup de temps.
Aujourd'hui, le frère recrue vous apprendra 10 programmes de script Python. Bien que simple, cela reste très utile. Ceux qui sont intéressés peuvent le mettre en œuvre eux-mêmes et trouver des techniques qui les aideront.
1. Jpg en Png
Conversion du format d'image Dans le passé, la première chose à laquelle frère J aurait pu penser était le logiciel [Format Factory].
De nos jours, l'écriture d'un script Python peut compléter la conversion de différents formats d'image. Ici, nous prenons comme exemple la conversion de jpg en png.
Il existe deux solutions, toutes deux partagées par tout le monde.
# 图片格式转换, Jpg转Png
# 方法①
from PIL import Image
img = Image.open('test.jpg')
img.save('test1.png')
# 方法②
from cv2 import imread, imwrite
image = imread("test.jpg", 1)
imwrite("test2.png", image)2. Cryptage et décryptage PDF
Si vous avez 100 fichiers PDF ou plus qui doivent être cryptés, les crypter manuellement n'est certainement pas réalisable et prend extrêmement de temps.
Utilisez le module pikepdf de Python pour crypter des fichiers et écrivez une boucle pour crypter des documents par lots.
# PDF加密
import pikepdf
pdf = pikepdf.open("test.pdf")
pdf.save('encrypt.pdf', encryption=pikepdf.Encryption(owner="your_password", user="your_password", R=4))
pdf.close()S'il y a un cryptage, il y aura un décryptage. Le code est le suivant.
# PDF解密
import pikepdf
pdf = pikepdf.open("encrypt.pdf",password='your_password')
pdf.save("decrypt.pdf")
pdf.close()3. Obtenir des informations sur la configuration de l'ordinateur
De nombreux amis peuvent utiliser Master Lu pour vérifier la configuration de leur ordinateur, ce qui nécessite le téléchargement d'un logiciel.
Utilisez le module WMI de Python pour visualiser facilement les informations de votre ordinateur.
# 获取计算机信息
import wmi
def System_spec():
Pc = wmi.WMI()
os_info = Pc.Win32_OperatingSystem()[0]
processor = Pc.Win32_Processor()[0]
Gpu = Pc.Win32_VideoController()[0]
os_name = os_info.Name.encode('utf-8').split(b'|')[0]
ram = float(os_info.TotalVisibleMemorySize) / 1048576
print(f'操作系统: {os_name}')
print(f'CPU: {processor.Name}')
print(f'内存: {ram} GB')
print(f'显卡: {Gpu.Name}')
print("n计算机信息如上 ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑")
System_spec() En prenant comme exemple le propre ordinateur de frère J, vous pouvez voir la configuration en exécutant le code.
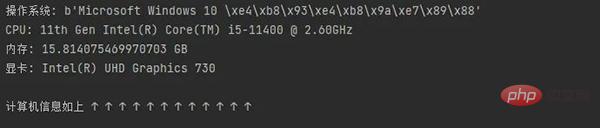
4. Décompresser les fichiers
Utilisez le module zipfile pour décompresser les fichiers De la même manière, les fichiers peuvent également être compressés.
# 解压文件
from zipfile import ZipFile
unzip = ZipFile("file.zip", "r")
unzip.extractall("output Folder")5. La fusion de feuilles de calcul Excel
vous aide à fusionner des feuilles de calcul Excel en un seul tableau. Le contenu du tableau est comme indiqué ci-dessous.
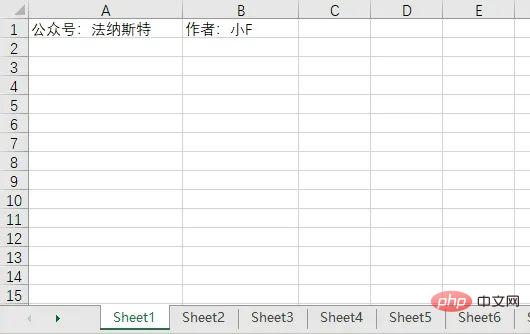
6 tables, le contenu du reste des tables est le même que celui de la première table.
Définissez le nombre de tables sur 5 et le contenu des 5 premières tables sera fusionné.
import pandas as pd # 文件名 filename = "test.xlsx" # 表格数量 T_sheets = 5 df = [] for i in range(1, T_sheets+1): sheet_data = pd.read_excel(filename, sheet_name=i, header=None) df.append(sheet_data) # 合并表格 output = "merged.xlsx" df = pd.concat(df) df.to_excel(output)
Les résultats sont les suivants.
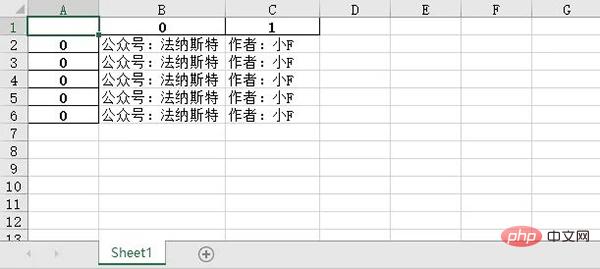
6. Convertir une image en croquis
est quelque peu similaire à la conversion de format d'image précédente, qui consiste à traiter l'image.
Dans le passé, vous avez peut-être utilisé Meitu Xiuxiu, mais maintenant, ce sont peut-être les filtres de Douyin.
En fait, en utilisant OpenCV de Python, vous pouvez rapidement obtenir de nombreux effets souhaités.
# 图像转换
import cv2
# 读取图片
img = cv2.imread("img.jpg")
# 灰度
grey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
invert = cv2.bitwise_not(grey)
# 高斯滤波
blur_img = cv2.GaussianBlur(invert, (7, 7), 0)
inverse_blur = cv2.bitwise_not(blur_img)
sketch_img = cv2.divide(grey, inverse_blur, scale=256.0)
# 保存
cv2.imwrite('sketch.jpg', sketch_img)
cv2.waitKey(0)
cv2.destroyAllWindows()L'image originale est la suivante.

Le croquis est le suivant, c'est plutôt sympa.
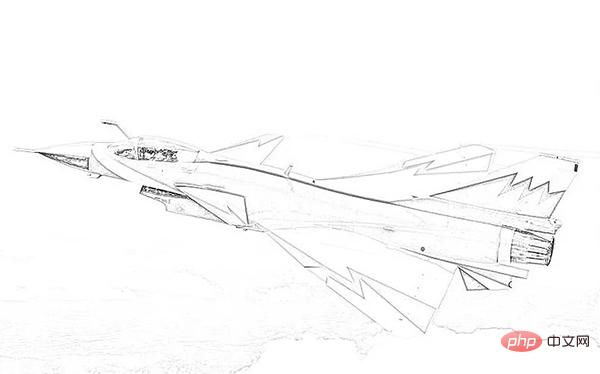
7. Obtenez la température du processeur
Avec ce script Python, vous n'aurez besoin d'aucun logiciel pour connaître la température du processeur.
# 获取CPU温度
from time import sleep
from pyspectator.processor import Cpu
cpu = Cpu(monitoring_latency=1)
with cpu:
while True:
print(f'Temp: {cpu.temperature} °C')
sleep(2)8. Extraire des tableaux PDF
Parfois, nous devons extraire les données d'un tableau à partir d'un PDF.
Vous pensez peut-être d'abord à la finition manuelle, mais lorsque la charge de travail est particulièrement lourde, le travail manuel peut être plus laborieux.
Ensuite, vous pourriez penser à des logiciels et des outils Web pour extraire des tableaux PDF.
Ce script simple ci-dessous vous aidera à faire de même en une seconde seulement.
# 方法①
import camelot
tables = camelot.read_pdf("tables.pdf")
print(tables)
tables.export("extracted.csv", f="csv", compress=True)
# 方法②, 需要安装Java8
import tabula
tabula.read_pdf("tables.pdf", pages="all")
tabula.convert_into("table.pdf", "output.csv", output_format="csv", pages="all")Le contenu du document PDF est le suivant, incluant un tableau.
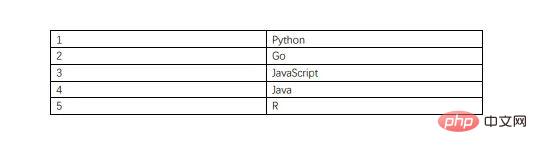
Le contenu du fichier CSV extrait est le suivant.
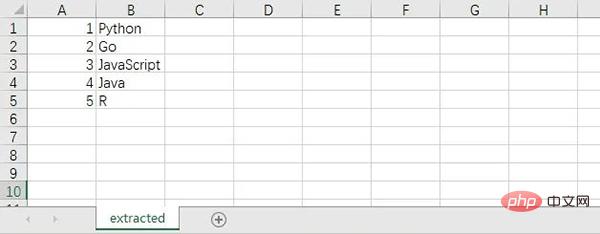
9. Capture d'écran
Ce script prendra simplement une capture d'écran sans utiliser de logiciel de capture d'écran.
Dans le code ci-dessous, je vous montre deux méthodes pour prendre des captures d'écran en Python.
# 方法①
from mss import mss
with mss() as screenshot:
screenshot.shot(output='scr.png')
# 方法②
import PIL.ImageGrab
scr = PIL.ImageGrab.grab()
scr.save("scr.png")10. Vérificateur orthographique
Ce script Python peut effectuer une vérification orthographique. Bien sûr, il ne fonctionne qu'en anglais. Après tout, le chinois est vaste et profond.
# 拼写检查
# 方法①
import textblob
text = "mussage"
print("original text: " + str(text))
checked = textblob.TextBlob(text)
print("corrected text: " + str(checked.correct()))
# 方法②
import autocorrect
spell = autocorrect.Speller(lang='en')
# 以英语为例
print(spell('cmputr'))
print(spell('watr'))
print(spell('survice'))Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!