
Maison >Périphériques technologiques >IA >La méthode de base de ChatGPT peut être utilisée pour la peinture par l'IA, et l'effet monte en flèche de 47 %. Auteur correspondant : est passé à OpenAI.
La méthode de base de ChatGPT peut être utilisée pour la peinture par l'IA, et l'effet monte en flèche de 47 %. Auteur correspondant : est passé à OpenAI.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-10 14:22:071252parcourir
Il existe une méthode de formation de base dans ChatGPT appelée « Apprentissage par renforcement avec feedback humain (RLHF) ».
Cela peut rendre le modèle plus sûr et les résultats plus cohérents avec les intentions humaines.
Maintenant, des chercheurs de Google Research et de l'UC Berkeley ont découvert que l'application de cette méthode à la peinture par l'IA peut "traiter" la situation dans laquelle l'image ne correspond pas exactement à l'entrée, et l'effet est étonnamment bon -
peut atteindre jusqu'à 47. % améliorer.

△ La gauche est la diffusion stable, la droite est l'effet amélioré
En ce moment, les deux modèles populaires dans le domaine AIGC semblent avoir trouvé une sorte de "résonance".
Comment utiliser RLHF pour la peinture IA ?
RLHF, le nom complet est « Reinforcement Learning from Human Feedback », est une technologie d'apprentissage par renforcement développée conjointement par OpenAI et DeepMind en 2017.
Comme son nom l'indique, RLHF utilise l'évaluation humaine des résultats de sortie du modèle (c'est-à-dire les commentaires) pour optimiser directement le modèle. Dans LLM, il peut rendre les « valeurs du modèle » plus cohérentes avec les valeurs humaines.
Dans le modèle de génération d'images AI, il peut aligner complètement l'image générée avec l'invite de texte.
Plus précisément, commencez par collecter des données sur les commentaires humains.
Ici, les chercheurs ont généré un total de plus de 27 000 « paires texte-image » et ont ensuite demandé à des humains de les noter.
Par souci de simplicité, les invites textuelles incluent uniquement les quatre catégories suivantes, liées aux options de quantité, de couleur, d'arrière-plan et de fusion ; les commentaires humains sont uniquement divisés en « bon », « mauvais » et « ne sait pas (ignorer) ; ".

Deuxièmement, apprenez la fonction de récompense.
Cette étape consiste à utiliser l'ensemble de données composé d'évaluations humaines qui viennent d'être obtenues pour entraîner une fonction de récompense, puis à utiliser cette fonction pour prédire la satisfaction humaine à l'égard de la sortie du modèle (partie rouge de la formule).
De cette façon, le modèle sait à quel point ses résultats correspondent au texte.
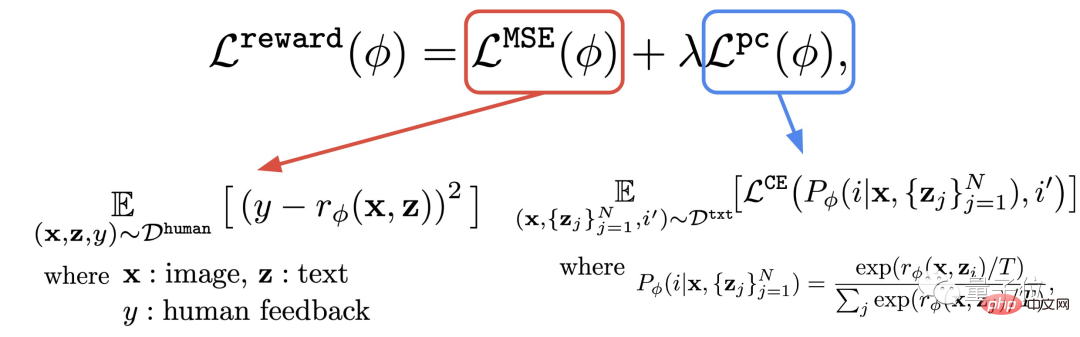
En plus de la fonction récompense, l'auteur propose également une tâche auxiliaire (partie bleue de la formule).
C'est-à-dire qu'une fois la génération de l'image terminée, le modèle donnera un tas de texte, mais un seul d'entre eux est le texte original, et laissera le modèle de récompense "vérifier par lui-même" si l'image correspond au texte.
Cette opération inverse peut produire l'effet "double assurance" (cela peut aider à la compréhension de l'étape 2 dans l'image ci-dessous).
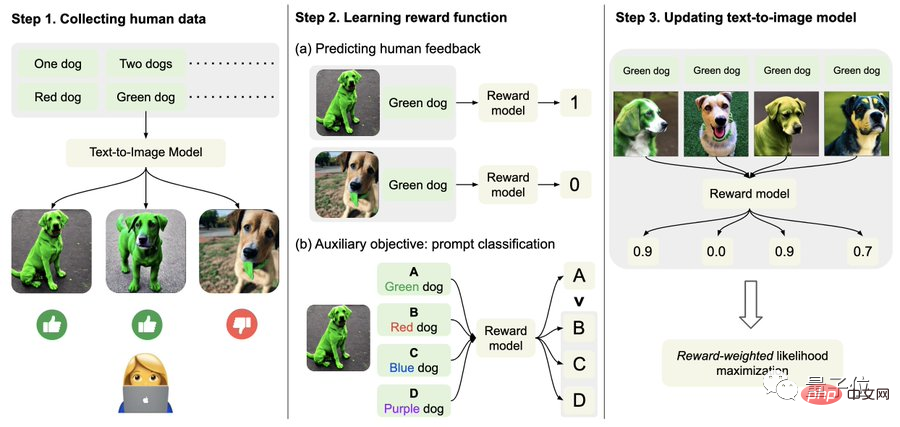
Enfin, il s’agit de peaufiner.
C'est-à-dire que le modèle de génération texte-image est mis à jour via une maximisation de la probabilité pondérée en fonction des récompenses (le premier élément de la formule ci-dessous).
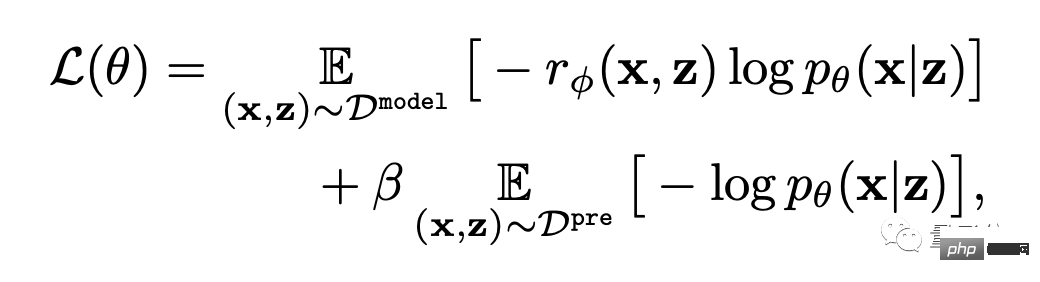
Afin d'éviter le surajustement, l'auteur a minimisé la valeur NLL (le deuxième terme de la formule) sur l'ensemble de données de pré-entraînement. Cette approche est similaire à InstructionGPT (le « prédécesseur direct » de ChatGPT).
L'effet a augmenté de 47%, mais la clarté a chuté de 5%
Comme le montre la série d'effets suivante, par rapport à la diffusion stable originale, le modèle affiné avec RLHF peut :
(1) Obtenez le "" dans le texte plus correctement "Deux" et "vert"

(2) n'ignorera pas l'exigence de "mer" comme arrière-plan
(3) Si vous voulez un tigre rouge, cela peut donner un résultat "plus rouge".
À en juger par les données spécifiques, le taux de satisfaction humaine du modèle affiné est de 50 %, soit une amélioration de 47 % par rapport au modèle original (3 %).
Cependant, le prix est une perte de clarté d'image de 5%.
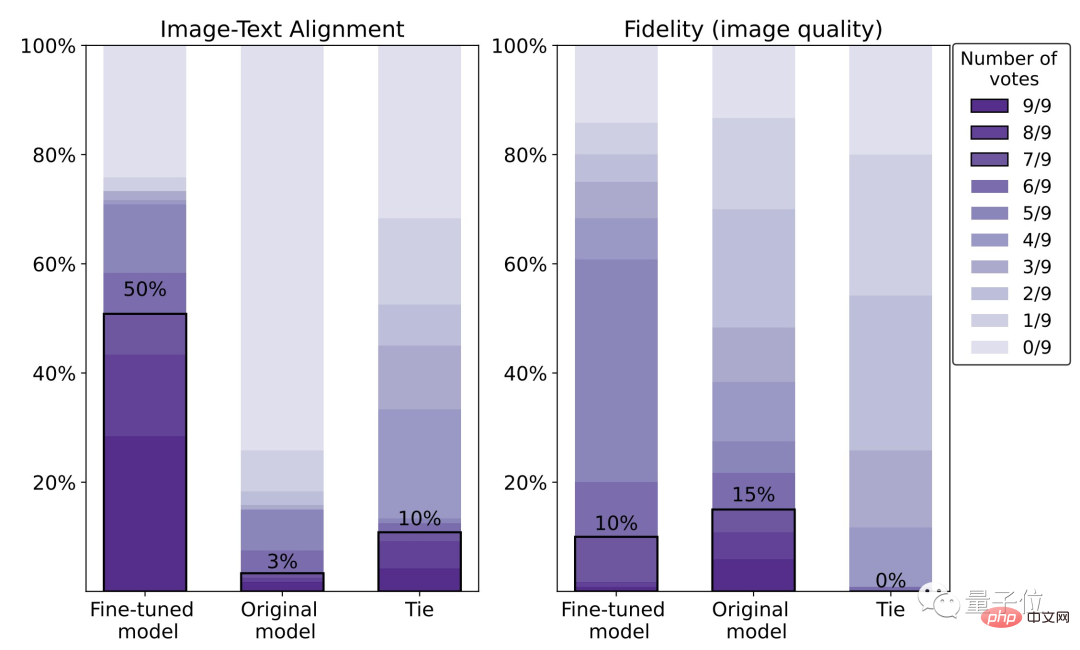
Nous pouvons également voir clairement sur l'image ci-dessous que le loup de droite est évidemment plus flou que celui de gauche :
À cet égard, l'auteur a déclaré qu'en utilisant un ensemble de données d'évaluation humaine plus large et une meilleure méthode d’optimisation (RL) peut améliorer cette situation.
À propos de l'auteur
Il y a 9 auteurs au total pour cet article.

En tant que chercheuse sur Google AI, Kimin Lee, Ph.D. de l'Institut coréen des sciences et technologies, des recherches postdoctorales sont menées. à l'Université de Berkeley.

Trois auteurs chinois :
Liu Hao, doctorant à l'UC Berkeley, Son principal intérêt de recherche concerne les réseaux neuronaux de rétroaction.
Du Yuqing est doctorant à l'UC Berkeley. Son principal domaine de recherche concerne les méthodes d'apprentissage par renforcement non supervisé.
Shixiang Shane Gu (Gu Shixiang), l'auteur correspondant, a étudié auprès de Hinton, l'un des trois géants, pour son diplôme de premier cycle et a obtenu son doctorat à l'Université de Cambridge.

△ Gu Shixiang
Il convient de mentionner qu'au moment d'écrire cet article, il était encore un Googleur, et maintenant il est passé à Google OpenAI et relève directement du responsable de ChatGPT.
Adresse papier :
https://arxiv.org/abs/2302.12192
Lien de référence : [1] https://www.php.cn/link/4d42d2f5010c1c13f23492a35645d6a7
[2]https://openai.com/blog/instruction-following/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI