
Maison >Périphériques technologiques >IA >Gouvernance des microservices de l'algorithme WeChat NLP
Gouvernance des microservices de l'algorithme WeChat NLP

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-10 11:52:051308parcourir

1. Vue d'ensemble
Musk a acquis Twitter mais n'était pas satisfait de sa technologie. Je pense que la page d'accueil est trop lente car il y a plus de 1 000 RPC. Sans dire si les raisons invoquées par Musk sont correctes, on peut voir qu'un service complet fourni aux utilisateurs sur Internet sera soutenu par un grand nombre d'appels de microservices.
En prenant comme exemple la recommandation de lecture WeChat, elle se divise en deux étapes : le rappel et le tri.
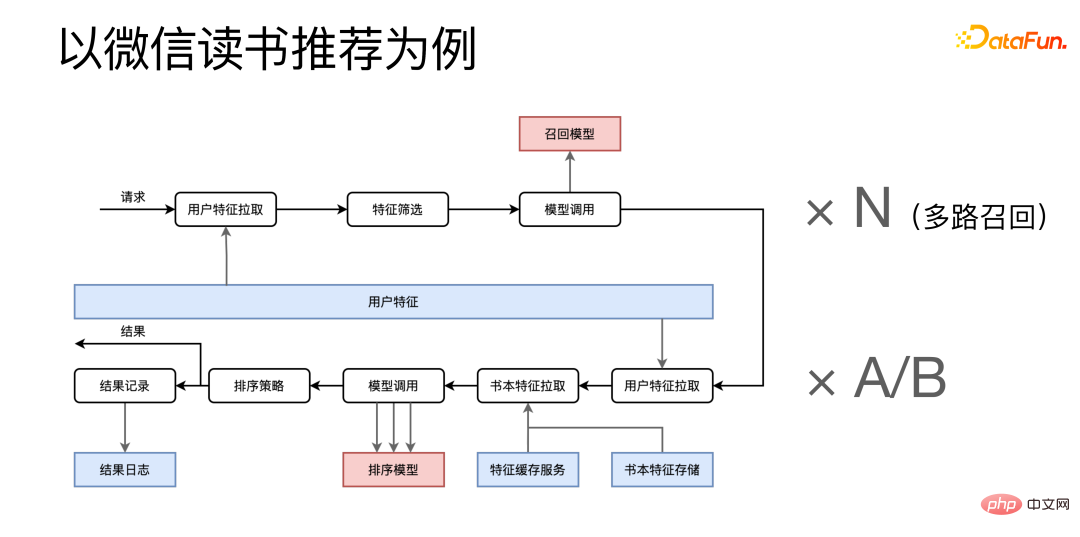
Une fois la demande arrivée, elle extraira d'abord les fonctionnalités du microservice de fonctionnalités utilisateur, combinera les fonctionnalités ensemble pour le filtrage des fonctionnalités, puis appellera et rappellera les microservices associés. Ce processus doit également être multiplié. par An N, parce que nous avons un rappel multicanal, de nombreux processus de rappel similaires seront exécutés en même temps. Voici l'étape de tri, qui extrait les fonctionnalités pertinentes de plusieurs microservices de fonctionnalités et appelle le service de modèle de tri plusieurs fois après les avoir combinées. Après avoir obtenu le résultat final, d'une part, le résultat final est renvoyé à l'appelant et, d'autre part, certains journaux du processus sont envoyés au système de journalisation pour archivage.
Les recommandations de lecture ne représentent qu'une très petite partie de l'ensemble de l'application de lecture WeChat. On peut voir que même un service relativement petit aura un grand nombre d'appels de microservices derrière lui. Si vous y regardez de plus près, vous pouvez vous attendre à ce que l'ensemble du système WeChat Reading contienne un grand nombre d'appels de microservices.
Quels problèmes pose un grand nombre de microservices ?
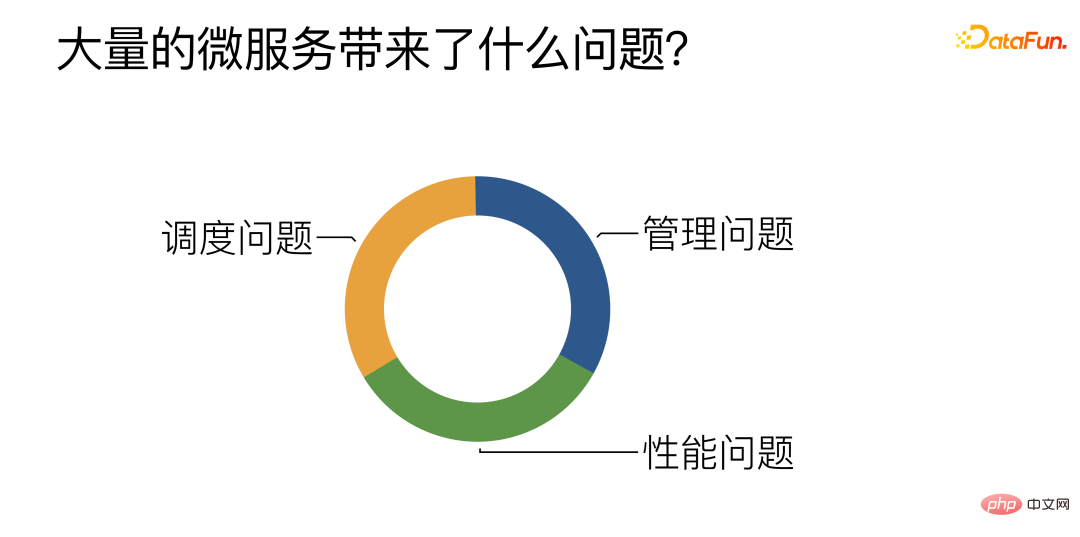
Selon le résumé du travail quotidien, il y a principalement trois défis :
① Management : Principalement autour de la façon de gérer, développer et déployer efficacement un grand nombre de microservices algorithmiques.
② Performance : Essayez d'améliorer les performances des microservices, en particulier des microservices algorithmiques.
③ Planification : Comment parvenir à un équilibrage de charge efficace et raisonnable entre plusieurs microservices d'algorithmes similaires.
2. Problèmes de gestion rencontrés par les microservices
1. Développement et déploiement : le système CI/CD assure le packaging et le déploiement automatiques
Le premier point est que nous fournissons un packaging et un déploiement automatiques. pipeline réduit la pression des étudiants en algorithme pour développer des microservices algorithmiques. Désormais, les étudiants en algorithme n'ont plus qu'à écrire une fonction Python, et le pipeline extraira automatiquement une série de modèles de microservices pré-écrits et remplira rapidement les fonctions développées par les étudiants en algorithme. microservices.
2. Expansion et contraction de la capacité : expansion et contraction automatiques tenant compte du retard des tâches
Le deuxième point concerne l'expansion et la contraction automatiques des microservices. Nous adoptons la solution tenant compte du retard des tâches. Nous détecterons activement le degré d'inactivité d'un certain type de tâches. Lorsque l'arriéré dépasse un certain seuil, l'opération d'expansion sera automatiquement déclenchée. Lorsque l'inactivité atteint un certain seuil, la réduction du nombre de processus de microservices sera déclenchée. également être déclenché.
3. Organisation des microservices : DAG / DSL complet de Turing / tests de résistance automatiques / déploiement automatique
Le troisième point est comment organiser un grand nombre de microservices ensemble pour construire un service complet de couche supérieure. Nos services de couche supérieure sont représentés par DAG. Chaque nœud de DAG représente un appel au microservice, et chaque bord représente le transfert de données entre services. Pour le DAG, un DSL (domain Specific Language) a également été spécialement développé pour mieux décrire et structurer le DAG. Et nous avons développé une série d'outils Web autour du DSL, qui peuvent créer visuellement, tester et déployer des services de couche supérieure directement dans le navigateur.
4. Surveillance des performances : système Trace
Le quatrième point Surveillance des performances est de localiser le problème en cas de problème avec le service de couche supérieure. Nous avons construit notre propre système Trace. Pour chaque requête externe, il existe un ensemble complet de suivi, qui permet de vérifier la consommation de temps de la requête dans chaque microservice, découvrant ainsi le goulot d'étranglement des performances du système.
3. Problèmes de performances rencontrés par les microservices
De manière générale, le temps d'exécution de l'algorithme est consacré au modèle d'apprentissage en profondeur. Une grande partie de l'optimisation des performances des microservices de l'algorithme est d'optimiser les performances des microservices de l'algorithme. optimiser la profondeur. Le modèle d’apprentissage déduit les performances. Vous pouvez choisir un framework d'inférence dédié, ou essayer des compilateurs d'apprentissage profond, l'optimisation du noyau, etc. Pour ces solutions, nous pensons qu'elles ne sont pas complètement nécessaires. Dans de nombreux cas, nous utilisons directement des scripts Python pour aller en ligne, et nous pouvons toujours atteindre des performances comparables à celles du C++.
La raison pour laquelle ce n'est pas complètement nécessaire est que ces solutions peuvent effectivement apporter de meilleures performances, mais de bonnes performances ne sont pas la seule exigence du service. Il existe une règle bien connue des 80/20, décrite en termes de personnes et de ressources, c'est-à-dire que 20 % des personnes généreront 80 % des ressources. En d'autres termes, 20 % des personnes fourniront 80 % des contributions. . Ceci s’applique également aux microservices.
Nous pouvons diviser les microservices en deux catégories. Premièrement, les services matures et stables ne sont pas nombreux et n'occupent peut-être que 20 %, mais ils supportent 80 % du trafic. L'autre catégorie concerne certains services expérimentaux ou encore en cours de développement et d'itération. Ils sont nombreux, représentant 80 %, mais ne représentent que 20 % du trafic. Le point important est qu'il y a souvent des changements et des itérations. Il y aura donc également une forte demande de développement et de lancement rapides.
Les méthodes évoquées précédemment, comme le framework Infer, l'optimisation du Kernel, etc., nécessitent inévitablement des coûts de développement supplémentaires. Les services matures et stables restent très adaptés à ce type de méthode, car il y a relativement peu de changements et ils peuvent être utilisés longtemps après une optimisation. D'un autre côté, ces services supportent une grande quantité de trafic, et une petite amélioration des performances peut avoir un impact énorme, il vaut donc la peine d'investir dans le coût.
Mais ces méthodes ne sont pas si adaptées aux services expérimentaux, car les services expérimentaux seront fréquemment mis à jour et nous ne pouvons pas effectuer de nouvelles optimisations pour chaque nouveau modèle. Pour les services expérimentaux, nous avons développé un interpréteur Python auto-développé - PyInter pour les scénarios de déploiement hybride GPU. Il est possible de se connecter directement à l'aide de scripts Python sans modifier aucun code, et en même temps, les performances peuvent être proches, voire dépasser, de celles du C++.
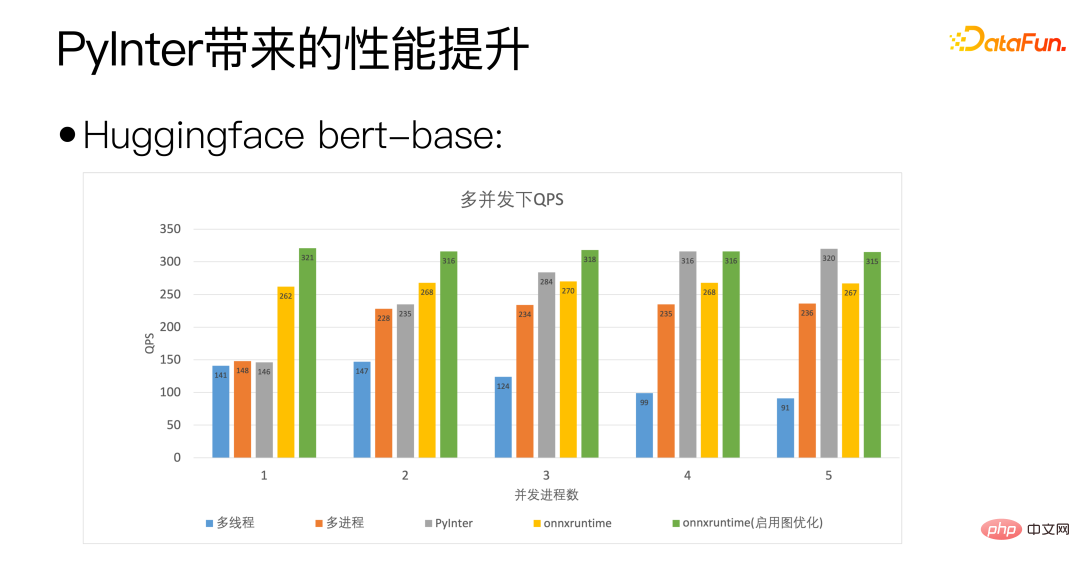
Nous utilisons la base bert de Huggingface comme standard. L'axe horizontal de la figure ci-dessus est le nombre de processus simultanés, indiquant le nombre de copies de modèle que nous déployons. PyInter a un nombre plus élevé de copies de modèles. Dans de nombreux cas, QPS dépasse même onnxruntime.
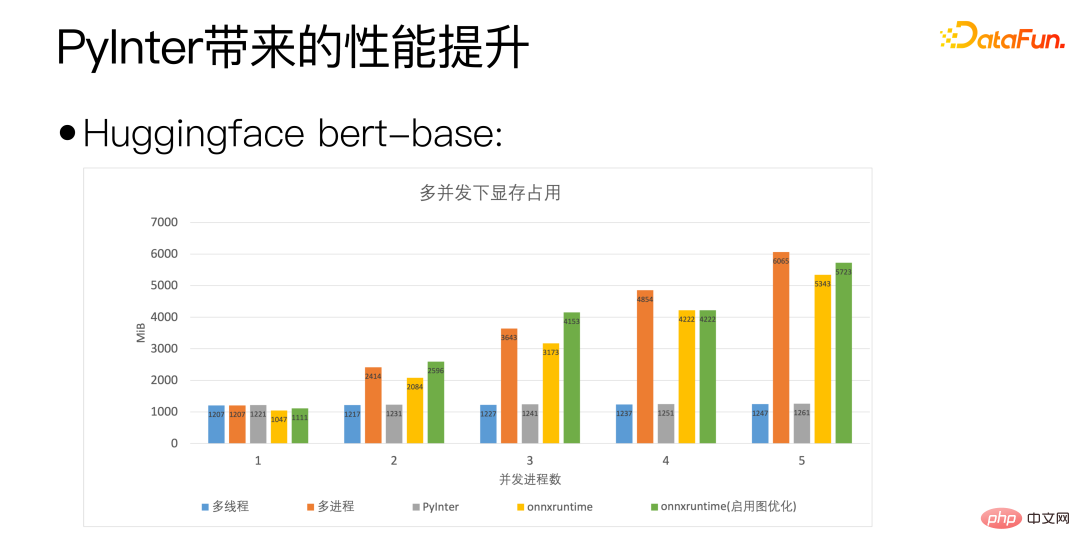
Grâce au chiffre ci-dessus, vous pouvez voir que PyInter réduit l'utilisation de la mémoire de près de 80 % par rapport au multi-processus et à ONNXRuntime lorsque le nombre de copies de modèle est important. Et veuillez noter que, quel que soit le modèle Quel que soit le nombre de copies, l'utilisation de la mémoire de PyInter reste inchangée.
Revenons à la question plus fondamentale d'avant : Python est-il vraiment lent ?
Oui, Python est vraiment lent, mais Python n'est pas lent lors des calculs scientifiques, car le véritable lieu de calcul n'est pas Python, mais une bibliothèque de calcul dédiée telle que MKL ou cuBLAS.
Alors, où est le principal goulot d'étranglement en termes de performances de Python ? Principalement dû au GIL (Global Interpreter Lock) en multi-threading, qui fait qu'un seul thread fonctionne en même temps en multi-threading. Cette forme de multithreading peut être utile pour les tâches gourmandes en E/S, mais elle n'a aucun sens pour le déploiement de modèles, qui nécessite autant de calculs.
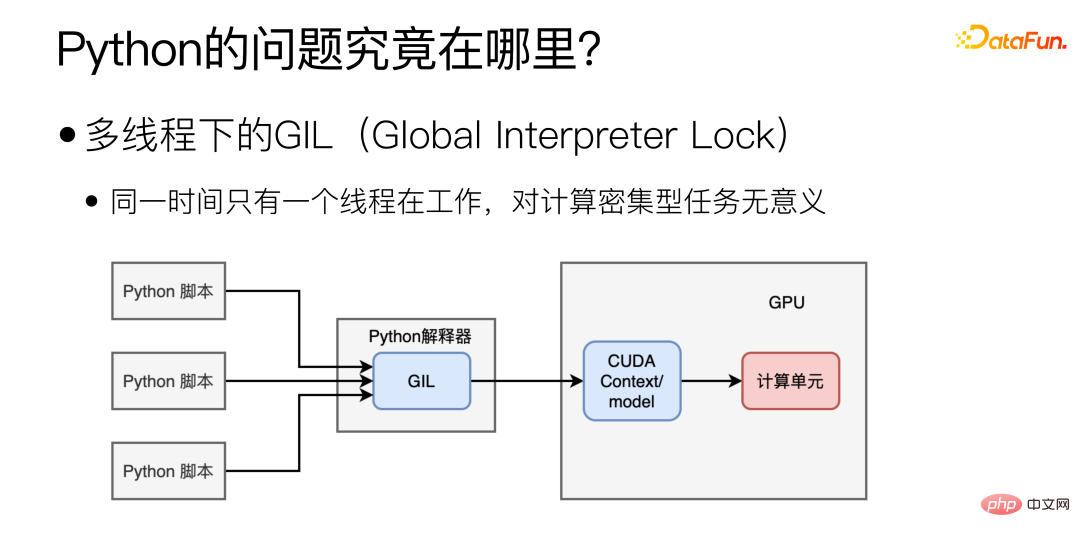
Le passage à plusieurs processus résoudra-t-il le problème ?
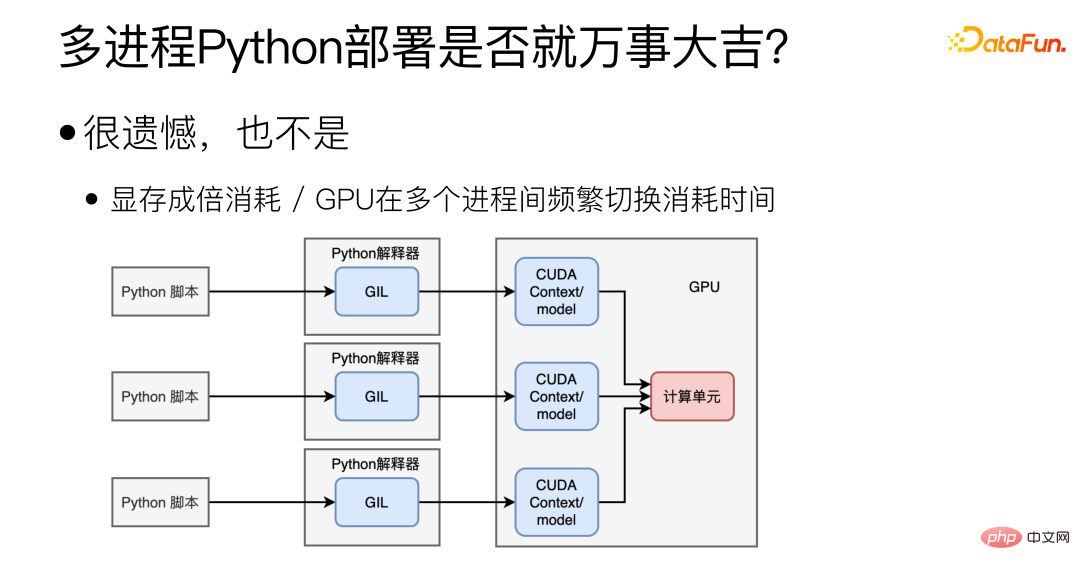
En fait non, le multi-processus peut effectivement résoudre le problème du GIL, mais cela entraînera également d'autres nouveaux problèmes. Tout d'abord, il est difficile de partager le contexte/modèle CUDA entre plusieurs processus, ce qui entraînera un gaspillage important de mémoire vidéo. Dans ce cas, plusieurs modèles ne peuvent pas être déployés sur une seule carte graphique. Le deuxième est le problème du GPU. Le GPU ne peut effectuer que les tâches d'un seul processus en même temps, et le changement fréquent du GPU entre plusieurs processus prend également du temps.
Pour les scénarios Python, le modèle idéal est le suivant :
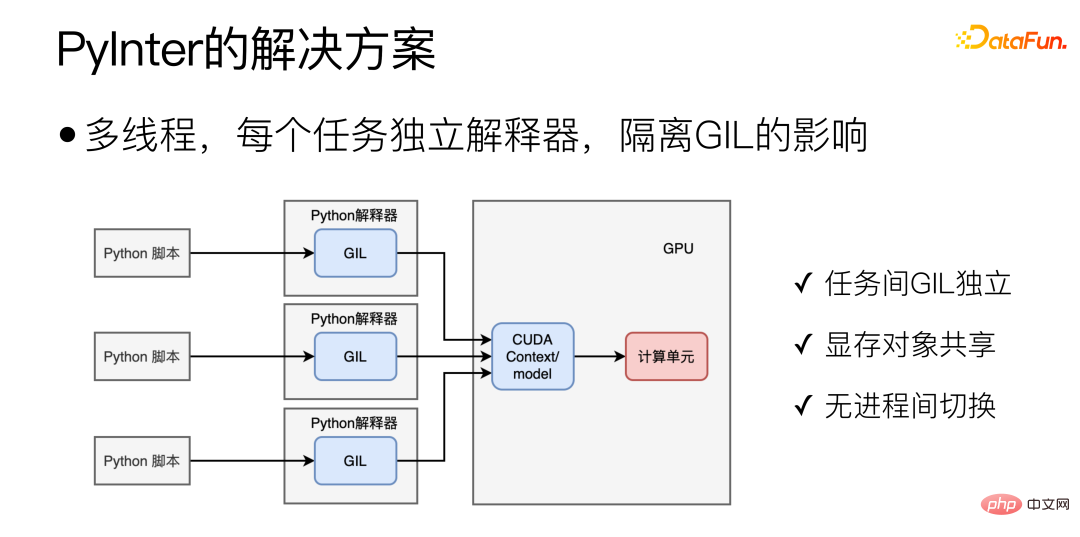
Grâce au déploiement multi-thread et à la suppression de l'influence de GIL, c'est l'objectif principal de PyInter. L'idée de conception est de placer plusieurs copies du modèle dans plusieurs threads pour l'exécution, et en même temps de créer un interpréteur Python isolé distinct pour chaque tâche Python, afin que le GIL de plusieurs tâches n'interfère pas les uns avec les autres. Cela combine les avantages du multi-processus et du multi-thread. D'une part, GIL est indépendant l'un de l'autre. D'autre part, il s'agit essentiellement d'un mode multi-thread à processus unique, de sorte que les objets de mémoire vidéo peuvent être partagés. et il n'y a pas de surcharge de commutation de processus GPU.
La clé de l'implémentation de PyInter est l'isolation des bibliothèques dynamiques au sein du processus. L'isolation de l'interpréteur est essentiellement l'isolation des bibliothèques dynamiques. Ici, nous avons développé un chargeur de bibliothèque dynamique auto-développé, qui est similaire à. dlopen, mais prend en charge "l'isolation" et le "partage". Deux méthodes de chargement de bibliothèque dynamique.
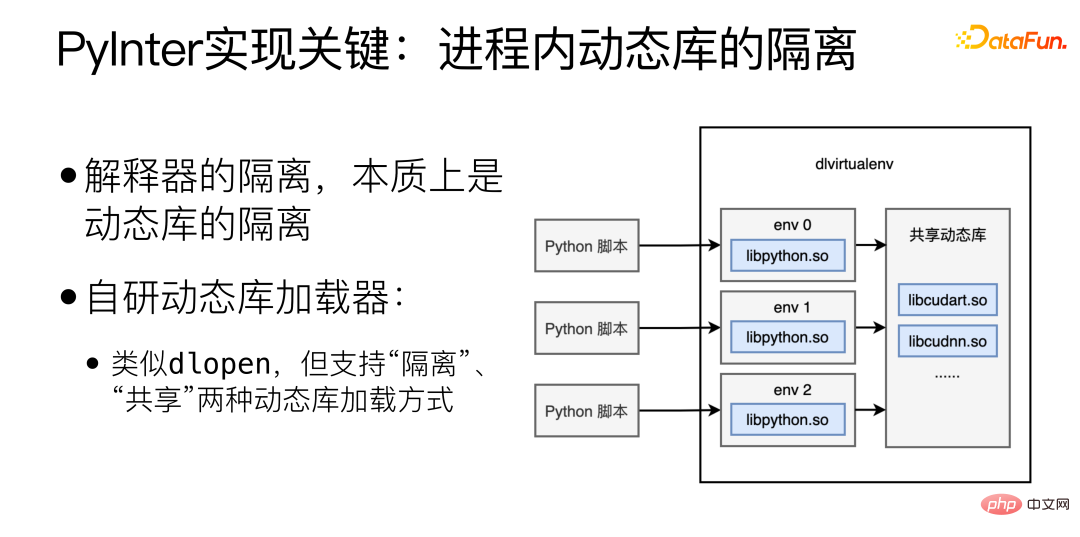
Le chargement de bibliothèques dynamiques en mode "isolé" chargera des bibliothèques dynamiques dans différents espaces virtuels, et différents espaces virtuels ne pourront pas se voir. Si la bibliothèque dynamique est chargée en mode « partagé », la bibliothèque dynamique peut être vue et utilisée n'importe où dans le processus, y compris à l'intérieur de chaque espace virtuel.
Chargez les bibliothèques liées à l'interpréteur Python en mode "isolé", puis chargez les bibliothèques liées à cuda en mode "partagé", réalisant ainsi le partage des ressources de mémoire vidéo tout en isolant l'interpréteur.
4. Problèmes de planification rencontrés par les microservices
Plusieurs microservices jouent la même importance et le même rôle, alors comment parvenir à un équilibrage de charge dynamique entre plusieurs microservices. L’équilibrage dynamique de la charge est important, mais presque impossible à réaliser parfaitement.
Pourquoi l'équilibrage de charge dynamique est-il important ? Les raisons sont les suivantes :
(1) Différence matérielle de la machine (CPU / GPU)
(2) Différence de longueur de demande (traduit 2 mots / traduit 200 mots) ; (3) Sous Random Load Balancing, l'effet longue traîne est évident :
① La différence entre P99/P50 peut atteindre 10 fois ; ② La différence entre P999/P50 peut atteindre 20 fois ; (4) Pour les microservices, la longue traîne est la clé pour déterminer la vitesse globale. Le temps nécessaire pour traiter une demande varie considérablement. Les différences de puissance de calcul, de longueur de demande, etc. affecteront toutes le temps. À mesure que le nombre de microservices augmente, il y aura toujours des microservices qui toucheront la longue traîne, ce qui affectera le temps de réponse de l'ensemble du système. Pourquoi l'équilibrage de charge dynamique est-il si difficile à perfectionner ? Option 1 : Exécutez Benchmark sur toutes les machines. Cette solution n'est pas "dynamique" et ne peut pas faire face à la différence de longueur de requête. Et il n’existe pas de référence parfaite pouvant refléter les performances. Différentes machines réagiront différemment selon les modèles. Option 2 : Obtenez l'état de chaque machine en temps réel et envoyez les tâches à celle dont la charge est la plus légère. Cette solution est relativement intuitive, mais le problème est qu'il n'y a pas de véritable « temps réel » dans un système distribué. Il faudra certainement du temps pour transférer des informations d'une machine à une autre, et pendant ce temps, L'état de la machine peut changer. Par exemple, à un certain moment, une certaine machine Worker est la plus inactive, et plusieurs machines maîtres responsables de la répartition des tâches le détectent toutes, elles attribuent donc toutes des tâches à ce Worker le plus inactif, et ce Worker le plus inactif devient instantanément C'est le célèbre effet de marée dans l'équilibrage de charge. Option 3 : Maintenir une file d'attente de tâches unique au monde. Tous les maîtres responsables de la répartition des tâches envoient des tâches à la file d'attente et tous les travailleurs prennent des tâches dans la file d'attente. Dans cette solution, la file d'attente des tâches elle-même peut devenir un goulot d'étranglement unique, ce qui rend difficile son expansion horizontale. La raison fondamentale pour laquelle l'équilibrage de charge dynamique est difficile à perfectionner est que la transmission des informations prend du temps Lorsqu'un état est observé, cet état doit être "passé". Il existe une vidéo sur Youtube que je recommande à tout le monde, "Load Balancing is Impossible" https://www.youtube.com/watch?v=kpvbOzHUakA. Concernant l'algorithme d'équilibrage de charge dynamique, l'algorithme Power of 2 Choices sélectionne aléatoirement deux travailleurs et attribue des tâches au plus inactif. Cet algorithme constitue la base de l'algorithme d'égalisation dynamique que nous utilisons actuellement. Cependant, il existe deux problèmes majeurs avec l'algorithme Power of 2 Choices : Premièrement, avant que chaque tâche ne soit attribuée, l'état d'inactivité du Worker doit être interrogé, ce qui ajoute un RTT supplémentaire, il est possible que les deux soient aléatoires ; les travailleurs sélectionnés sont très occupés. Pour résoudre ces problèmes, nous avons apporté des améliorations. 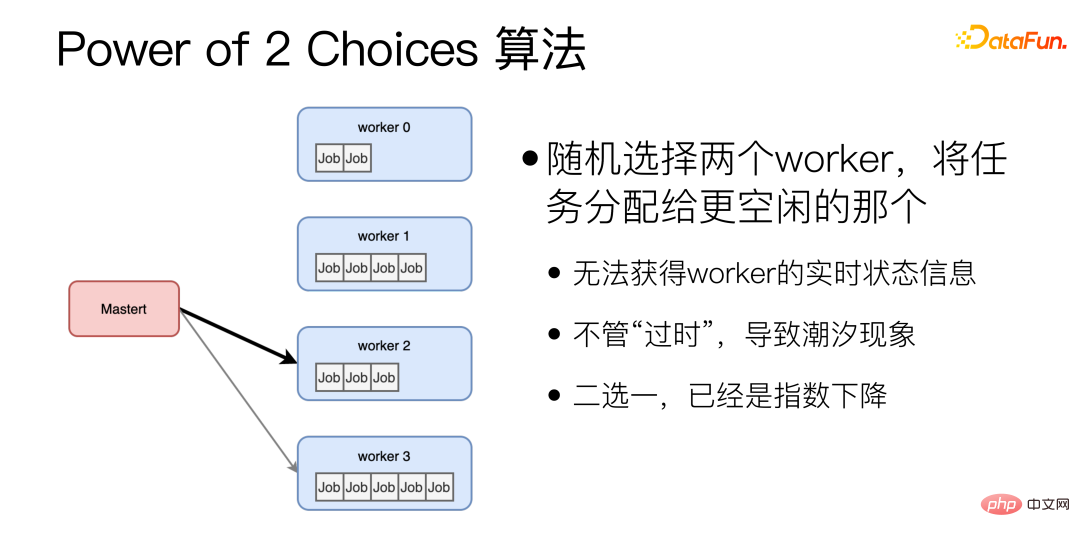
L'algorithme amélioré est Joint-Idle-Queue.
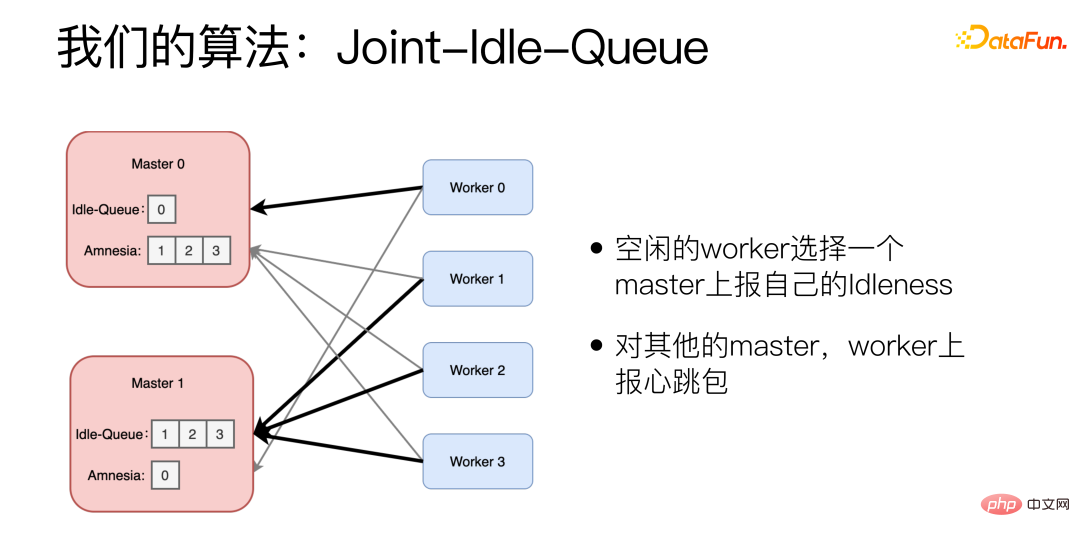
Nous avons ajouté deux parties à la machine Master, Idle-Queue et Amnesia. Idle-Queue est utilisé pour enregistrer quels travailleurs sont actuellement inactifs. Amnesia enregistre les travailleurs qui se sont envoyés des paquets de battements de cœur au cours de la période récente. Si un travailleur ne s'est pas envoyé de paquets de battements de cœur depuis longtemps, Amnesia l'oubliera progressivement. Chaque travailleur signale périodiquement s'il est inactif. Le travailleur inactif sélectionne un maître pour signaler son inactivité et indique le nombre qu'il peut traiter. Le Worker utilise également l'algorithme Power of 2 Choices lors de la sélection du maître. Pour les autres maîtres, le Worker signale les paquets de battements de cœur.
Lorsqu'une nouvelle tâche arrive, le maître sélectionne au hasard deux tâches dans la file d'attente inactive et choisit celle avec la latence historique la plus faible. Si la file d'attente inactive est vide, Amnesia sera affiché. Choisissez-en deux au hasard dans Amnesia et choisissez celui avec la latence historique la plus faible.
En termes d'effet réel, en utilisant cet algorithme, P99/P50 peut être compressé jusqu'à 1,5 fois, ce qui est 10 fois mieux que l'algorithme aléatoire.
5. Résumé
Dans la pratique de la servitisation de modèles, nous avons rencontré trois défis :
Le premier est de savoir comment gérer un grand nombre de microservices, comment optimiser le développement, Notre solution est pour automatiser autant que possible le processus en ligne et de déploiement, extraire les processus répétitifs et les transformer en pipelines et programmes automatisés.
Le deuxième aspect est l'optimisation des performances du modèle. Comment rendre les microservices du modèle d'apprentissage profond plus efficaces. Notre solution consiste à partir des besoins réels du modèle et à effectuer une optimisation personnalisée pour les services relativement stables et à trafic important. Les services expérimentaux utilisent PyInter et utilisent directement des scripts Python pour lancer des services, qui peuvent également atteindre les performances du C++.
Le troisième problème est la planification des tâches. Comment réaliser un équilibrage de charge dynamique ? Notre solution est basée sur la puissance des 2 choix et a développé l'algorithme JIQ, qui atténue considérablement le problème de longue traîne des services chronophages.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI