
Maison >Périphériques technologiques >IA >NTU a proposé un nouveau modèle de RAM, utilisant Meta pour tout diviser afin d'obtenir la relation, et l'effet d'attaque sournoise chantée et dansée est excellent !
NTU a proposé un nouveau modèle de RAM, utilisant Meta pour tout diviser afin d'obtenir la relation, et l'effet d'attaque sournoise chantée et dansée est excellent !

- 王林avant
- 2023-05-10 10:22:091042parcourir
Au début de ce mois, Meta a lancé le modèle « Split Everything », qui a choqué tout le cercle du CV.
Ces derniers jours, un modèle d'apprentissage automatique appelé "Relate-Anything-Model (RAM)" a vu le jour. Il donne au Segment Anything Model (SAM) la capacité d'identifier diverses relations visuelles entre différents concepts visuels.
Il est entendu que le modèle a été développé par des étudiants de l'équipe MMLab de l'Université technologique de Nanyang et du laboratoire VisCom du King's College de Londres et l'Université de Tongji utilisent leur temps libre pour se développer en collaboration.
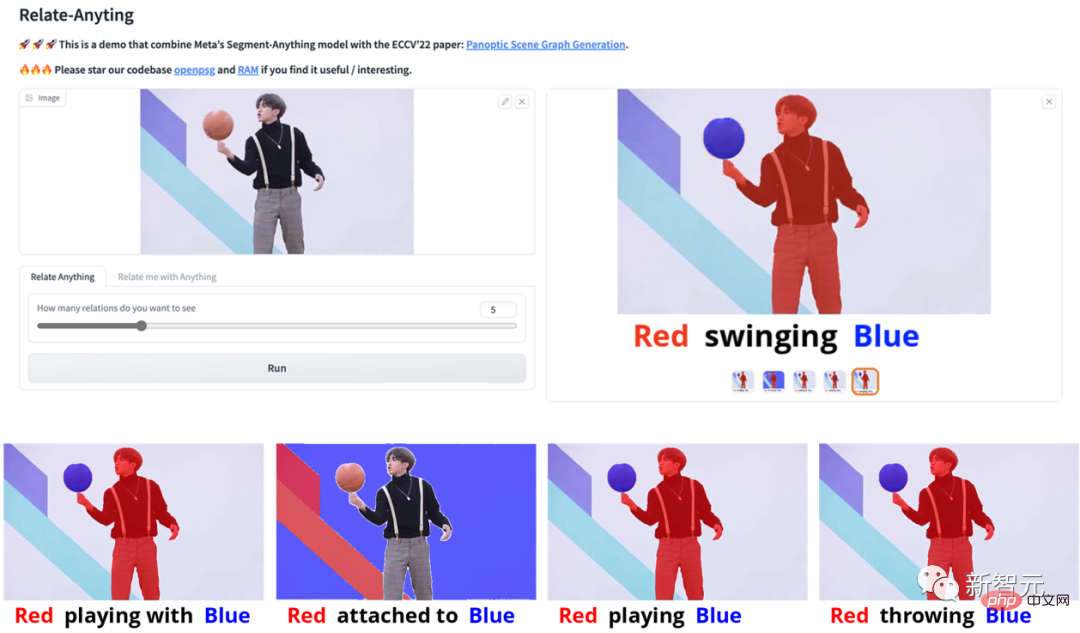
Adresse de démonstration : https:/ / /huggingface.co/spaces/mmlab-ntu/relate-anything-model
Adresse du code : https://github. com /Luodian/RelateAnything
Adresse de l'ensemble de données : https://github.com/Jingkang50/OpenPSG#🎜🎜 #
Démonstration d'effetTout d'abord, jetons un coup d'œil à l'exemple d'application de "Relate-Anything-Model (RAM) " !
Par exemple, les résultats d'analyse d'image suivants de la mise en œuvre du modèle RAM consistant à jouer au football, à danser et à se faire des amis sont très impressionnants. et les excellentes performances et le potentiel du modèle pour diverses applications ont été bien démontrés.
 # 🎜 🎜#
# 🎜 🎜#


Le PSG Challenge est doté d'un prix d'un million de dollars et a reçu une variété de solutions soumises par 100 équipes à travers le monde, dont Use advanced méthodes de segmentation d'images et résoudre des problèmes de longue traîne, etc. En outre, le concours a également reçu des méthodes innovantes, telles que des techniques d'augmentation des données spécifiques aux graphiques de scène.
Après évaluation, basée sur des considérations telles que les indicateurs de performance, la nouveauté et l'importance de la solution, le GRNet de l'équipe Xiaohongshu s'est démarqué . , devient le moyen de gagner.

Avant d'introduire la solution, nous introduisons d'abord deux méthodes de base classiques du PSG, l'une d'elles est une méthode en deux étapes et l’autre est une méthode en une seule étape.
Pour la méthode de base en deux étapes, comme le montre la figure a, dans la première étape, le modèle de segmentation panoramique pré-entraîné Panoptic FPN est utilisé pour extraire les caractéristiques, les prédictions de segmentation et de classification de l'image. Les caractéristiques de chaque objet individuel sont ensuite transmises à un générateur de graphiques de scène classique tel que IMP pour la génération de graphiques de scène adaptés à la tâche PSG dans la deuxième étape. Cette approche en deux étapes permet d'adapter la méthode SGG classique à la tâche PSG avec des modifications minimes. Comme le montre la figure b, la méthode de base en une seule étape PSGTR utilise d'abord CNN pour extraire les caractéristiques de l'image, puis utilise un encodeur-décodeur de transformateur de type DETR pour apprendre directement la représentation du triplet. Le matcher hongrois est utilisé pour comparer les triples prédits avec les triples de vérité terrain. Ensuite, l’objectif d’optimisation est de maximiser le coût de calcul du matcher, et la perte totale est calculée à l’aide de la perte d’entropie croisée DICE/F-1 pour l’étiquetage et la segmentation. 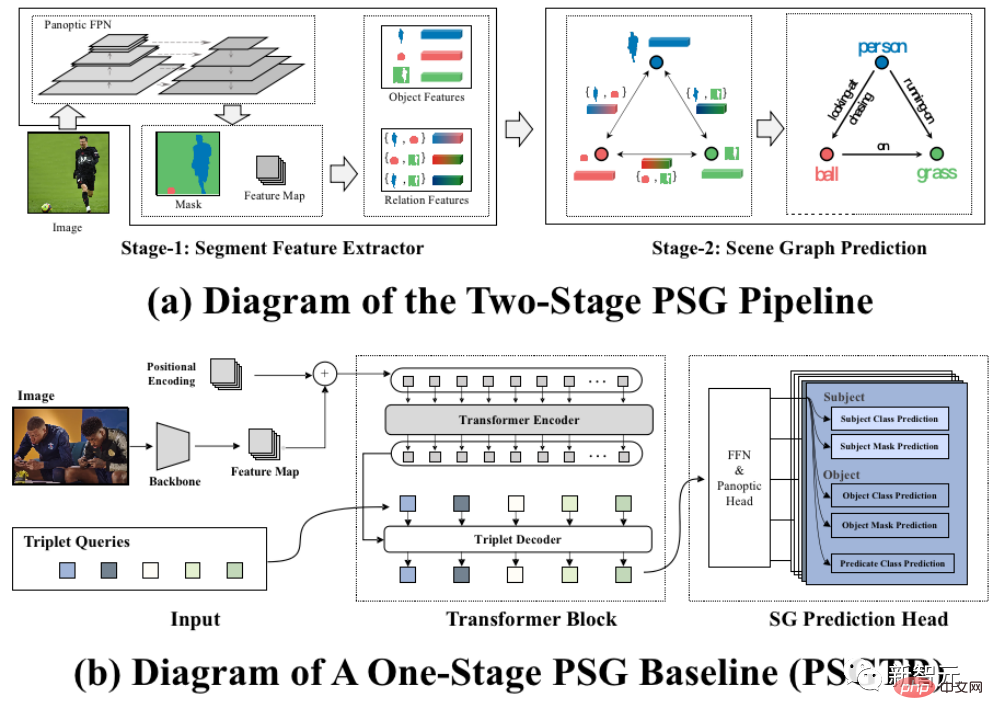
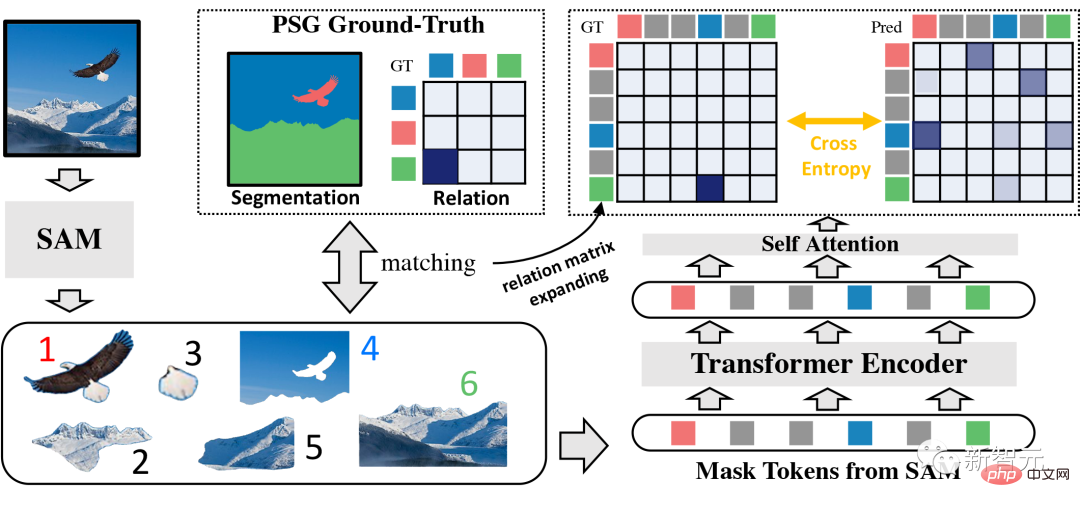
Architecture du modèle RAM
Dans le processus de conception du modèle RAM, l'auteur a fait référence au paradigme structurel en deux étapes de la solution championne du PSG GRNet. Bien que la recherche dans l'article original du PSG montre que le modèle à une étape fonctionne actuellement mieux que le modèle à deux étapes, le modèle à une étape ne peut généralement pas atteindre d'aussi bonnes performances de segmentation que le modèle à deux étapes.
Après avoir observé différentes structures de modèle, il est supposé que les excellentes performances du modèle à une étape dans la prédiction des triples de relations peuvent être dues au signal de supervision direct de la carte des caractéristiques de l'image qui est bénéfique pour capturer les relations.
Partant de ce constat, la conception de RAM, comme GRNet, vise à trouver un compromis entre les deux modes, ce qui est obtenu en se concentrant sur le paradigme en deux étapes et en lui donnant la capacité d'obtenir des contexte similaire au paradigme en une seule étape.
Plus précisément, Segment Anything Model (SAM) est d'abord utilisé comme extracteur de caractéristiques pour identifier et segmenter les objets dans l'image, et la carte de caractéristiques intermédiaire de l'objet spécifique du segmenteur SAM est fusionnée avec sa segmentation correspondante pour obtenir les caractéristiques au niveau de l'objet.
Par la suite, le Transformer est utilisé comme module de contexte global et les caractéristiques obtenues au niveau de l'objet y sont saisies après mappage linéaire. Grâce au mécanisme d'attention croisée de l'encodeur Transformer, les fonctionnalités de l'objet de sortie collectent des informations plus globales provenant d'autres objets.
Enfin, pour chaque fonctionnalité au niveau de l'objet générée par le Transformer, le mécanisme d'auto-attention est utilisé pour enrichir davantage les informations contextuelles et compléter l'interaction entre chaque objet.
Veuillez noter qu'une intégration de catégorie est également ajoutée ici pour indiquer la catégorie de l'objet, et ainsi des prédictions de paires d'objets et de leurs relations sont obtenues.
Classification des relations RAM
Pendant le processus de formation, pour chaque catégorie de relation, une tâche de classification binaire des relations doit être effectuée pour déterminer si une relation existe entre des paires d'objets.
Semblable à GRNet, il existe des considérations particulières pour les tâches de classification binaire relationnelle. Par exemple, les ensembles de données PSG contiennent généralement deux objets avec des relations multiples, telles que « les gens regardent les éléphants » et « les gens nourrissent les éléphants » existent simultanément. Pour résoudre le problème multi-étiquettes, les auteurs convertissent la prédiction de relation d'un problème de classification mono-étiquette en un problème de classification multi-étiquettes.
De plus, étant donné que l'ensemble de données PSG recherche l'exactitude et la pertinence en obligeant les annotateurs à choisir des prédicats spécifiques et précis (tels que « s'arrêter à » au lieu du « à » plus général), il peut ne pas convenir à l'apprentissage des limites. relations (par exemple, "in" existe en fait en même temps que "stop at"). Pour résoudre ce problème, RAM adopte une stratégie d'auto-formation qui utilise des étiquettes auto-distillées pour la classification des relations et utilise une moyenne mobile exponentielle pour mettre à jour dynamiquement les étiquettes.
Autres conceptions de RAM
Lors du calcul de la perte de classification binaire relationnelle, chaque objet prédit doit être associé à son objet de vérité terrain correspondant. L'algorithme de correspondance hongrois est utilisé à cette fin.
Cependant, cet algorithme est sujet à l'instabilité, en particulier dans les premières étapes de formation lorsque la précision du réseau est faible. Cela peut conduire à des résultats de correspondance différents pour la même entrée, conduisant à des directions d'optimisation du réseau incohérentes et rendant la formation plus difficile.
Dans RAM, contrairement à la solution précédente, l'auteur peut effectuer une segmentation complète et détaillée de presque n'importe quelle image à l'aide du puissant modèle SAM. Par conséquent, dans le processus de mise en correspondance de la prédiction et du GT, la RAM est naturellement conçue. Nouvelle méthode de correspondance GT : utilisez l'ensemble de données PSG pour entraîner le modèle.
Pour chaque image d'entraînement, SAM segmente plusieurs objets, mais seuls quelques-uns correspondent au masque de vérité terrain (GT) du PSG. Les auteurs effectuent une correspondance simple en fonction de leurs scores d'intersection-union (IOU), de sorte que (presque) chaque masque GT soit attribué à un masque SAM. Ensuite, l'auteur a régénéré le diagramme de relations basé sur le masque SAM, qui correspondait naturellement aux prédictions du modèle.
Résumé du modèle RAM
Dans le modèle RAM, l'auteur utilise le Segment Anything Model (SAM) pour identifier et segmenter les objets dans l'image, et extraire les caractéristiques de chaque objet segmenté. Le module Transformer est ensuite utilisé pour interagir entre les objets segmentés afin d'obtenir de nouvelles fonctionnalités. Enfin, une fois ces caractéristiques intégrées dans des catégories, les résultats de prédiction sont générés via le mécanisme d’auto-attention.
Pendant le processus de formation, en particulier, l'auteur propose une nouvelle méthode d'appariement GT et, sur la base de cette méthode, calcule la relation d'appariement entre les prédictions et le GT et classe leurs relations mutuelles. Dans le processus d'apprentissage supervisé de la classification des relations, l'auteur le considère comme un problème de classification multi-étiquettes et adopte une stratégie d'auto-apprentissage pour apprendre les relations limites des étiquettes.
Enfin, j'espère que le modèle RAM pourra vous apporter plus d'inspiration et d'innovation. Si vous souhaitez également former un modèle d'apprentissage automatique capable de trouver des relations, vous pouvez suivre le travail de cette équipe et donner votre avis et vos suggestions à tout moment.

Adresse du projet : https://github.com/Jingkang50/OpenPSG
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI