
Maison >Java >javaDidacticiel >Analyser des exemples de files d'attente bloquantes en Java
Analyser des exemples de files d'attente bloquantes en Java

- PHPzavant
- 2023-05-09 21:43:061420parcourir
1. Qu'est-ce qu'une file d'attente de blocage
Une file d'attente de blocage est une file d'attente spéciale et une file d'attente commune dans les données structure De même, elle adhère également au principe du premier entré, premier sorti. En même temps, la file d'attente de blocage est une structure de données qui peut garantir la sécurité des threads et présente les deux caractéristiques suivantes : lorsque la file d'attente est pleine, elle continue à fonctionner. insérer des éléments dans la file d'attente entraînera le blocage de la file d'attente jusqu'à ce que d'autres threads prennent des éléments de la file d'attente ; lorsque la file d'attente est vide, continuer à retirer la file d'attente bloquera également la file d'attente jusqu'à ce que d'autres threads insèrent des éléments dans la file d'attente
#🎜 🎜#Supplémentaire : le blocage des threads signifie que le code ne sera pas exécuté à ce moment-là, c'est-à-dire que le système d'exploitation ne planifiera pas ce thread sur le processeur pour l'exécution à ce moment-là 2 Utilisez le code qui. bloque la file d'attenteimport java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.BlockingDeque;
public class Test {
public static void main(String[] args) throws InterruptedException {
//不能直接newBlockingDeque,因为它是一个接口,要向上转型
//LinkedBlockingDeque内部是基于链表方式来实现的
BlockingDeque<String> queue=new LinkedBlockingDeque<>(10);//此处可以指定一个具体的数字,这里的的10代表队列的最大容量
queue.put("hello");
String elem=queue.take();
System.out.println(elem);
elem=queue.take();
System.out.println(elem);
}
}
Remarque : La méthode put a une fonction de blocage, mais pas l'offre, donc la méthode put est généralement utilisée (la raison pour laquelle la méthode offer peut être utilisée est que BlockingDeque hérite de Queue) # 🎜🎜#
BlockingDeque继承了Queue)
打印结果如上所示,当打印了hello后,队列为空,代码执行到elem=queue.take();# 🎜🎜#
elem=queue.take();. À ce moment, le thread entre dans l'état d'attente bloquant et rien ne sera imprimé jusqu'à ce que d'autres threads mettent de nouveaux éléments dans la file d'attente. Le modèle est une méthode de programmation couramment utilisée dans le développement de serveurs et le développement back-end. Il est généralement utilisé pour le découplage, l'écrêtage des pics et le remplissage des vallées. Couplage élevé : la relation entre les deux modules de code est relativement élevée Cohésion élevée : les éléments d'un module de code sont étroitement intégrés les uns aux autres
Par conséquent, nous recherchons généralement un niveau élevé cohésion Réduire le couplage, ce qui accélérera l'efficacité d'exécution, et utiliser le modèle producteur-consommateur pour découpler
(1) Application 1 : Découplage
Dans l'ordinateur, le producteur agit comme un groupe de threads, et le consommateur agit comme un autre groupe de threads, et la plate-forme de négociation peut utiliser le blocage files d'attente 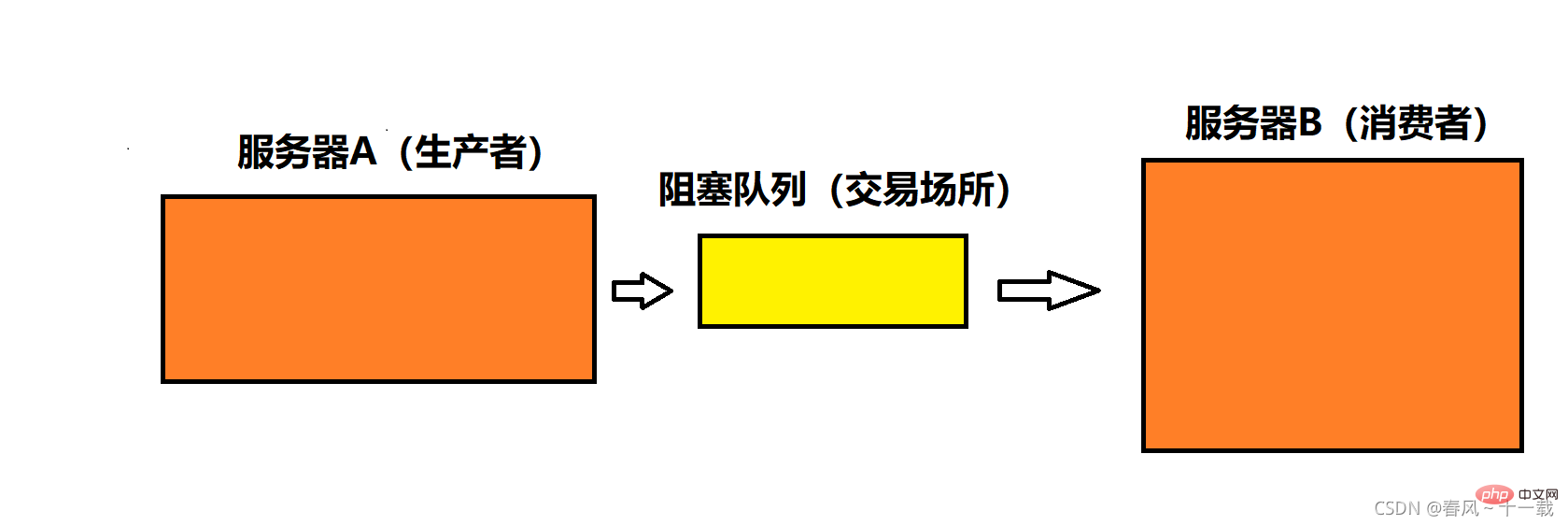
Dans la vraie vie  Barrage dans le rivière C'est une partie très importante. S'il n'y a pas de barrage, imaginez le résultat : lorsque la saison des crues arrive, lorsque l'eau dans le cours supérieur est très grande, une grande quantité d'eau se déverse dans le cours inférieur, provoquant des inondations. et les cultures seront submergées et pendant la saison sèche, les cours inférieurs seront inondés. Le manque d'eau peut déclencher une sécheresse. S'il y a un barrage, le barrage stockera l'excès d'eau dans le barrage pendant la saison des crues, fermera la vanne pour stocker l'eau et permettra à l'eau en amont de s'écouler en aval à un certain débit pour éviter qu'une vague soudaine de fortes pluies n'inonde le en aval, afin que l'aval ne soit pas inondé. Pendant les périodes de sécheresse, le barrage libère l'eau précédemment stockée et permet à l'eau de s'écouler en aval à un certain débit pour éviter que l'aval ne manque d'eau. Cela peut éviter à la fois les inondations pendant la saison des crues et la sécheresse pendant la période sèche.
Barrage dans le rivière C'est une partie très importante. S'il n'y a pas de barrage, imaginez le résultat : lorsque la saison des crues arrive, lorsque l'eau dans le cours supérieur est très grande, une grande quantité d'eau se déverse dans le cours inférieur, provoquant des inondations. et les cultures seront submergées et pendant la saison sèche, les cours inférieurs seront inondés. Le manque d'eau peut déclencher une sécheresse. S'il y a un barrage, le barrage stockera l'excès d'eau dans le barrage pendant la saison des crues, fermera la vanne pour stocker l'eau et permettra à l'eau en amont de s'écouler en aval à un certain débit pour éviter qu'une vague soudaine de fortes pluies n'inonde le en aval, afin que l'aval ne soit pas inondé. Pendant les périodes de sécheresse, le barrage libère l'eau précédemment stockée et permet à l'eau de s'écouler en aval à un certain débit pour éviter que l'aval ne manque d'eau. Cela peut éviter à la fois les inondations pendant la saison des crues et la sécheresse pendant la période sèche.
Vallée : équivalent à la période sèche
Dans l'ordinateur
Cette situation est également très typique en informatique, notamment en développement de serveur, la passerelle Transfère généralement les requêtes d'Internet vers des serveurs d'entreprise, tels que certains serveurs de produits, serveurs d'utilisateurs, serveurs marchands (qui stockent les informations sur les commerçants) et serveurs de diffusion en direct. Cependant, comme le nombre de requêtes provenant d'Internet est incontrôlable, cela équivaut à de l'eau en amont. Si une grande vague de requêtes survient soudainement, même si la passerelle peut la gérer, de nombreux serveurs ultérieurs s'effondreront après avoir reçu de nombreuses requêtes (en traitant une seule). La requête implique une série d'opérations de base de données, car l'efficacité des opérations liées à la base de données est relativement faible. S'il y a trop de requêtes, elle ne peut pas être traitée, elle plantera donc)
#. 🎜🎜#
所以实际情况中网关和业务服务器之间往往用一个队列来缓冲,这个队列就是阻塞队列(交易场所),用这个队列来实现生产者(网关)消费者(业务服务器)模型,把请求缓存到队列中,后面的消费者(业务服务器)按照自己固定的速率去读请求。这样当请求很多时,虽然队列服务器可能会稍微受到一定压力,但能保证业务服务器的安全。
(3)相关代码
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class TestDemo {
public static void main(String[] args) {
// 使用一个 BlockingQueue 作为交易场所
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();
// 此线程作为消费者
Thread customer = new Thread() {
@Override
public void run() {
while (true) {
// 取队首元素
try {
Integer value = queue.take();
System.out.println("消费元素: " + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
customer.start();
// 此线程作为生产者
Thread producer = new Thread() {
@Override
public void run() {
for (int i = 1; i <= 10000; i++) {
System.out.println("生产了元素: " + i);
try {
queue.put(i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
try {
customer.join();
producer.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}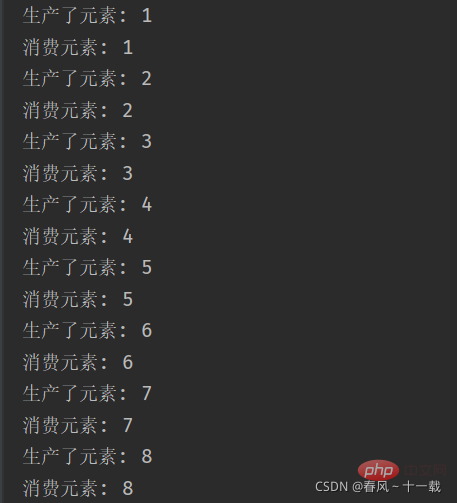
打印如上(此代码是让生产者通过sleep每过1秒生产一个元素,而消费者不使用sleep,所以每当生产一个元素时,消费者都会立马消费一个元素)
4.阻塞队列和生产者消费者模型功能的实现
在学会如何使用BlockingQueue后,那么如何自己去实现一个呢?
主要思路:
1.利用数组
2.head代表队头,tail代表队尾
3.head和tail重合后到底是空的还是满的判断方法:专门定义一个size记录当前队列元素个数,入队列时size加1出队列时size减1,当size为0表示空,为数组最大长度就是满的(也可以浪费一个数组空间用head和tail重合表示空,用tail+1和head重合表示满,但此方法较为麻烦,上一个方法较为直观,因此我们使用上一个方法)
public class Test2 {
static class BlockingQueue {
private int[] items = new int[1000]; // 此处的1000相当于队列的最大容量, 此处暂时不考虑扩容的问题.
private int head = 0;//定义队头
private int tail = 0;//定义队尾
private int size = 0;//数组大小
private Object locker = new Object();
// put 用来入队列
public void put(int item) throws InterruptedException {
synchronized (locker) {
while (size == items.length) {
// 队列已经满了,阻塞队列开始阻塞
locker.wait();
}
items[tail] = item;
tail++;
// 如果到达末尾, 就回到起始位置.
if (tail >= items.length) {
tail = 0;
}
size++;
locker.notify();
}
}
// take 用来出队列
public int take() throws InterruptedException {
int ret = 0;
synchronized (locker) {
while (size == 0) {
// 对于阻塞队列来说, 如果队列为空, 再尝试取元素, 就要阻塞
locker.wait();
}
ret = items[head];
head++;
if (head >= items.length) {
head = 0;
}
size--;
// 此处的notify 用来唤醒 put 中的 wait
locker.notify();
}
return ret;
}
}
public static void main(String[] args) throws InterruptedException {
BlockingQueue queue = new BlockingQueue();
// 消费者线程
Thread consumer = new Thread() {
@Override
public void run() {
while (true) {
try {
int elem = queue.take();
System.out.println("消费元素: " + elem);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
consumer.start();
// 生产者线程
Thread producer = new Thread() {
@Override
public void run() {
for (int i = 1; i < 10000; i++) {
System.out.println("生产元素: " + i);
try {
queue.put(i);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
producer.start();
consumer.join();
producer.join();
}
}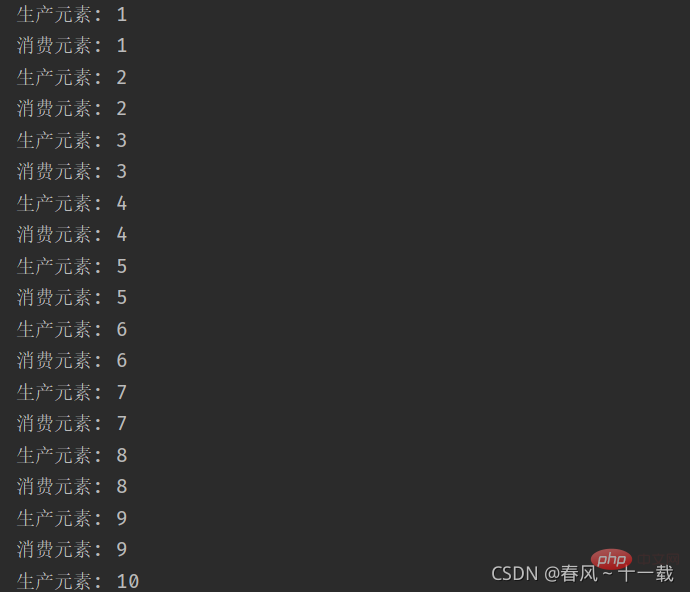
运行结果如上。
注意:
1.wait和notify的正确使用
2.put和take都会产生阻塞情况,但阻塞条件是对立的,wait不会同时触发(put唤醒take阻塞,take唤醒put阻塞)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!