
Maison >Périphériques technologiques >IA >Il a fallu deux ans à Google pour construire 23 robots utilisant l'apprentissage par renforcement pour aider à trier les déchets
Il a fallu deux ans à Google pour construire 23 robots utilisant l'apprentissage par renforcement pour aider à trier les déchets

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-09 15:01:091102parcourir
L'apprentissage par renforcement (RL) permet aux robots d'interagir par essais et erreurs, d'apprendre des comportements complexes et de s'améliorer au fil du temps. Certains travaux antérieurs de Google ont exploré comment RL peut permettre aux robots de maîtriser des compétences complexes telles que la préhension, l'apprentissage multitâche et même le jeu de tennis de table. Bien que l’apprentissage par renforcement chez les robots ait fait de grands progrès, nous ne voyons toujours pas de robots dotés d’apprentissage par renforcement dans les environnements quotidiens. Le monde réel étant complexe, diversifié et en constante évolution au fil du temps, cela pose d’énormes défis aux systèmes robotiques. Cependant, l’apprentissage par renforcement devrait être un excellent outil pour relever ces défis : en s’entraînant, en s’améliorant et en apprenant sur le tas, les robots devraient être capables de s’adapter à un monde en constante évolution.
Dans l'article de Google « Deep RL at Scale : Sorting Waste in Office Buildings with a Fleet of Mobile Manipulators », les chercheurs explorent comment résoudre ce problème grâce aux dernières expériences à grande échelle qu'ils ont déployées sur deux ans. Un groupe de 23 robots compatibles RL sont utilisés pour le tri et le recyclage des déchets dans les immeubles de bureaux de Google. Le système robotique utilisé combine un apprentissage par renforcement approfondi évolutif à partir de données du monde réel avec une entrée guidée et auxiliaire sensible aux objets issue de la formation par simulation pour améliorer la généralisation tout en conservant les avantages de la formation de bout en bout à vérifier.

Adresse papier : https://rl-at-scale.github.io/assets/rl_at_scale.pdf
Réglage du problème
Si les gens ne classent pas correctement les déchets, dans les lots de matières recyclables peuvent être contaminés et le compost peut être mal éliminé dans les décharges. Dans l'expérience de Google, des robots parcouraient les immeubles de bureaux à la recherche de « poubelles » (bacs de recyclage, bacs à compost et autres poubelles). La tâche du robot est d'arriver à chaque déchetterie pour trier les déchets, transporter les objets entre les différents bacs afin de placer tous les objets recyclables (canettes, bouteilles) dans les bacs recyclables et tous les objets compostables (conteneurs en carton, gobelets en papier) dans le bac à compost et tout le reste dans les autres bacs.
En fait, cette tâche n'est pas aussi facile qu'il y paraît. La seule sous-tâche consistant à ramasser les différents objets que les gens jettent à la poubelle constitue déjà un énorme défi. Le robot doit également identifier le bac approprié pour chaque objet et les trier le plus rapidement et le plus efficacement possible. Dans le monde réel, les robots sont confrontés à une variété de situations uniques, comme les exemples réels d'immeubles de bureaux suivants :
Apprendre de différentes expériences
L'apprentissage continu sur le tas est utile, mais avant d'en arriver là, auparavant, un Un ensemble de compétences de base était nécessaire pour guider un robot. À cette fin, Google utilise quatre sources d'expérience : (1) des stratégies simples de conception manuelle, qui ont un faible taux de réussite mais contribuent à fournir une expérience initiale ; (2) un cadre de formation par simulation qui utilise le transfert de la simulation vers le réel pour fournir une certaine expérience ; expérience préliminaire. Stratégies de tri des déchets ; (3) « salles de classe robotisées », où les robots utilisent des stations d'ordures représentatives pour s'entraîner en continu ; (4) environnements de déploiement réels, où les robots s'entraînent dans des immeubles de bureaux avec de vrais déchets ;
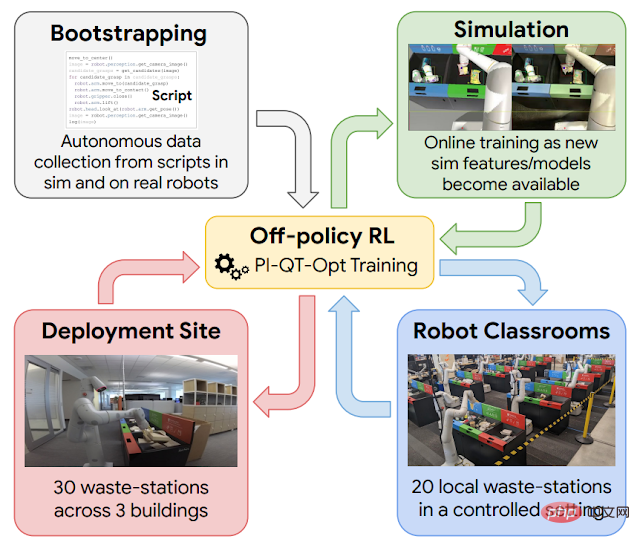
Schéma schématique de l'apprentissage par renforcement dans cette application à grande échelle. Utilisez les données générées par le script pour guider le lancement de la politique (en haut à gauche). Un modèle simulation-réel est ensuite entraîné, générant des données supplémentaires dans l'environnement de simulation (en haut à droite). Lors de chaque cycle de déploiement, ajoutez les données collectées dans les « classes robotisées » (en bas à droite). Déploiement et collecte de données dans un immeuble de bureaux (en bas à gauche).
Le cadre d'apprentissage par renforcement utilisé ici est basé sur QT-Opt, qui est également utilisé pour capturer différents déchets dans l'environnement de laboratoire et une série d'autres compétences. Commencez par une stratégie de script simple pour vous guider dans un environnement de simulation, appliquez l'apprentissage par renforcement et utilisez des méthodes de transfert basées sur CycleGAN pour rendre les images de simulation plus réalistes à l'aide de RetinaGAN.
C’est là que nous commençons à entrer dans les « classes robotisées ». Même si les immeubles de bureaux réels offrent l'expérience la plus réaliste, le débit de collecte de données est limité : certains jours, il y aura beaucoup de déchets à trier, d'autres moins. Les robots ont accumulé l’essentiel de leur expérience dans les « classes de robots ». Dans les "classes de robots" présentées ci-dessous, 20 robots s'entraînent à la tâche de tri des déchets :

Pendant que ces robots sont formés dans les "classes de robots", d'autres robots trient 30 déchets dans 3 immeubles de bureaux. Apprendre en position debout.
Performances de classification
Au final, les chercheurs ont collecté 540 000 données expérimentales provenant de « classes de robots » et 325 000 données expérimentales dans l'environnement de déploiement réel. À mesure que les données continuent d’augmenter, les performances de l’ensemble du système s’améliorent. Les chercheurs ont évalué le système final dans des « classes de robots » pour permettre des comparaisons contrôlées, en établissant des scénarios basés sur ce que les robots verraient lors de déploiements réels. Le système final a atteint une précision moyenne d’environ 84 %, avec des performances qui s’améliorent régulièrement au fur et à mesure de l’ajout de données. Dans le monde réel, les chercheurs ont documenté les statistiques des déploiements réels de 2021 à 2022 et ont découvert que le système pouvait réduire les contaminants présents dans les poubelles de 40 à 50 % en poids. Dans leur article, les chercheurs de Google fournissent des informations plus approfondies sur la conception de la technologie, une étude de l'atténuation de diverses décisions de conception et des statistiques plus détaillées issues de leurs expériences.
Conclusion et perspectives de travail futur
Les résultats expérimentaux montrent que le système basé sur l'apprentissage par renforcement peut permettre aux robots d'effectuer des tâches réelles dans des environnements de bureau réels. La combinaison de données hors ligne et en ligne permet aux robots de s’adapter à des situations très variées du monde réel. Dans le même temps, l'apprentissage dans un environnement de « salle de classe » plus contrôlé, y compris dans des environnements de simulation et des environnements réels, peut fournir un mécanisme de démarrage puissant qui permet au « volant » de l'apprentissage par renforcement de commencer à tourner, permettant ainsi l'adaptabilité.
Bien que des résultats importants aient été obtenus, il reste encore beaucoup de travail à faire : la stratégie finale d'apprentissage par renforcement n'est pas toujours couronnée de succès et des modèles plus puissants sont nécessaires pour améliorer ses performances et l'adapter à un plus large éventail de tâches. . En outre, d'autres sources d'expérience, notamment provenant d'autres tâches, d'autres robots et même de vidéos Internet, peuvent compléter l'expérience de démarrage acquise grâce à la simulation et à la « salle de classe ». Ce sont des questions qui devront être résolues à l’avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI