
Maison >Périphériques technologiques >IA >Compressez 26 jetons en 1 nouvelle méthode pour économiser de l'espace dans la zone de saisie ChatGPT
Compressez 26 jetons en 1 nouvelle méthode pour économiser de l'espace dans la zone de saisie ChatGPT

- PHPzavant
- 2023-05-09 14:10:371542parcourir
Avant de saisir le texte, considérez l'invite d'un modèle de langage Transformer (LM) comme ChatGPT :

Avec des millions d'utilisateurs et de requêtes générées chaque jour, ChatGPT utilise un mécanisme d'auto-attention pour mettre en œuvre des invites. Pour un codage répété, le temps et la complexité de la mémoire augmentent quadratiquement avec la longueur d'entrée. La mise en cache de l'activation du transformateur de l'invite empêche un recalcul partiel, mais cette stratégie entraîne toujours des coûts de mémoire et de stockage importants à mesure que le nombre d'invites mises en cache augmente. À grande échelle, même une petite réduction de la longueur des invites peut entraîner des économies de calcul, de mémoire et de stockage tout en permettant à l'utilisateur d'insérer davantage de contenu dans la fenêtre contextuelle limitée du LM.
Alors. Comment réduire le coût de l'invite ? Une approche typique consiste à affiner ou à distiller le modèle afin qu'il se comporte de manière similaire au modèle d'origine sans invite, éventuellement en utilisant des méthodes adaptatives efficaces en termes de paramètres. Cependant, un inconvénient fondamental de cette approche est que le modèle doit être recyclé à chaque fois pour une nouvelle invite (illustré au milieu de la figure 1 ci-dessous).
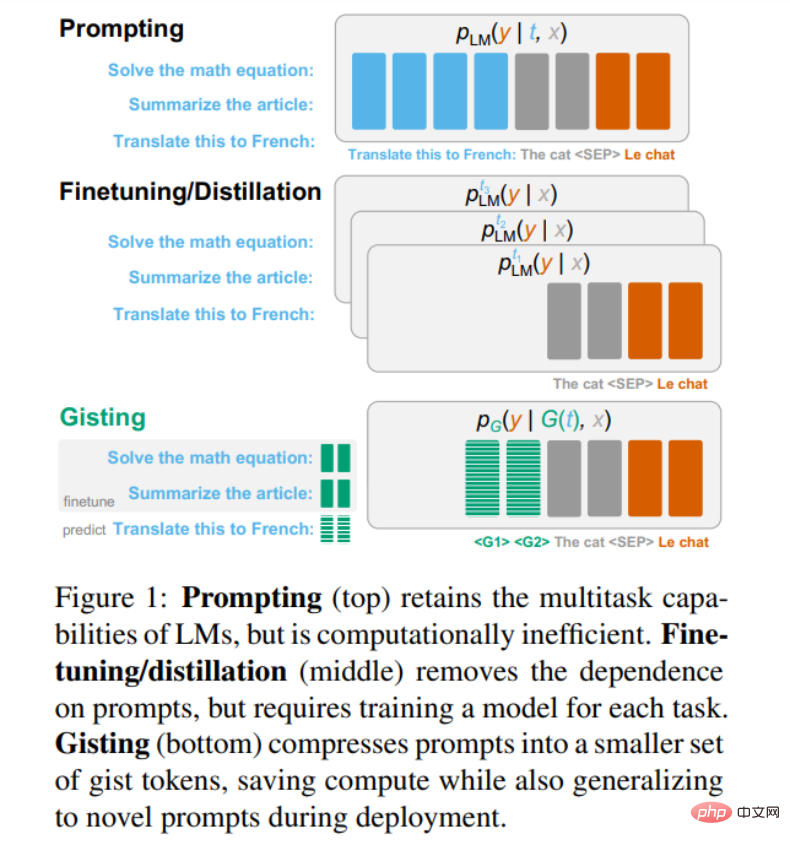
Dans cet article, des chercheurs de l'Université de Stanford ont proposé le modèle Gisting (en bas de la figure 1 ci-dessus), qui compresse les invites arbitraires en un ensemble de jetons virtuels « Gist » plus petits, similaires au préfixe fine. -réglage. Cependant, le réglage fin du préfixe nécessite l'apprentissage du préfixe pour chaque tâche par descente de gradient, tandis que Gisting utilise une méthode de méta-apprentissage pour prédire le préfixe Gist uniquement via des invites sans apprendre le préfixe pour chaque tâche. Cela amortit le coût de l'apprentissage des préfixes par tâche, permettant la généralisation à des instructions inconnues sans formation supplémentaire.
De plus, étant donné que le jeton « Gist » est beaucoup plus court que l'invite complète, Gisting permet à l'invite d'être compressée, mise en cache et réutilisée pour améliorer l'efficacité des calculs. Les chercheurs ont proposé une méthode très simple pour apprendre les instructions essentielles à suivre. Modèle : Simplement affinez la commande, insérez le jeton gish après l'invite, et le masque d'attention modifié empêche le jeton après le jeton essentiel de faire référence au jeton avant le jeton essentiel. Cela permet au modèle d'apprendre simultanément la compression rapide et le suivi des instructions sans frais de formation supplémentaires.
Sur le décodeur uniquement (LLaMA-7B) et l'encodeur-décodeur (FLAN-T5-XXL) LM, gisting atteint une compression instantanée jusqu'à 26x tout en conservant une qualité de sortie similaire à celle du modèle d'origine. Cela se traduit par une réduction de 40 % des FLOP lors de l'inférence, une accélération de la latence de 4,2 % et des coûts de stockage considérablement réduits par rapport aux méthodes traditionnelles de mise en cache rapide. 
Les chercheurs décrivent d'abord le gisting dans le contexte du perfectionnement de l'enseignement. Pour l'instruction suivant l'ensemble de données , t représente la tâche codée dans une invite en langage naturel (par exemple traduire ceci en français), x représente l'entrée (facultative) de la tâche (par exemple Le chat) et y représente la sortie souhaitée ( par exemple Le chat). Le but du réglage fin de l'instruction est d'apprendre la distribution pLM(y | t,x) en concaténant t et x, puis en laissant un modèle de langage généralement pré-entraîné prédire de manière autorégressive y. Pendant l'inférence, une nouvelle tâche t et une entrée x peuvent être utilisées pour demander et décoder le modèle afin d'obtenir des résultats de prédiction.
Cependant, ce modèle de connexion t et x présente des inconvénients : le LM basé sur un transformateur a une fenêtre contextuelle limitée, qui est limitée par l'architecture ou la puissance de calcul. Ce dernier point est particulièrement difficile à résoudre car l’attention personnelle évolue quadratiquement avec la longueur d’entrée. Par conséquent, les invites très longues, en particulier celles qui sont réutilisées à plusieurs reprises, sont inefficaces sur le plan informatique. Quelles options sont disponibles pour réduire le coût de l'invite ?
Une approche simple consiste à affiner LM pour une tâche spécifique t, c'est-à-dire qu'à partir d'un ensemble de données 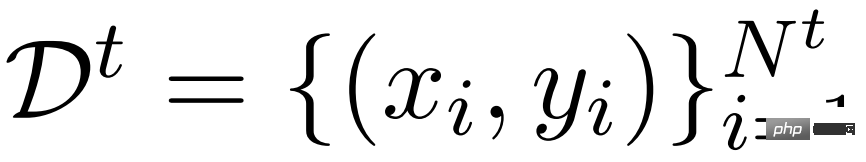
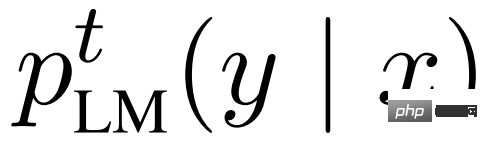
Des méthodes de réglage précis encore meilleures et efficaces en termes de paramètres, telles que le réglage précis du préfixe/invite ou l'adaptateur, peuvent atteindre le même objectif à un coût bien inférieur à celui du réglage fin à grande échelle. Cependant, un problème demeure : au moins une partie des poids du modèle pour chaque tâche doit être stockée et, plus important encore, pour chaque tâche t, l'ensemble de données de la paire entrée/sortie correspondante D^t doit être collecté et le modèle recyclé.
Gisting est une approche différente qui amortit deux coûts : (1) le coût du temps d'inférence pour conditionner p_LM sur t, (2) le coût du temps de formation pour apprendre un nouveau p^t_LM pour chaque t . L'idée est d'apprendre une version compressée de t G (t) lors du réglage fin, de telle sorte que l'inférence à partir de p_G (y | G (t),x) soit plus rapide qu'à partir de p_LM (y|t,x).
En termes de LM, G (t) sera un ensemble de jetons Gist "virtuels" qui sont moins nombreux que les jetons de t mais induiront toujours un comportement similaire dans LM. Les activations de transformateur (par exemple, les matrices de clé et de valeur) sur G (t) peuvent ensuite être mises en cache et réutilisées pour améliorer l'efficacité du calcul. Surtout, les chercheurs espèrent que G pourra se généraliser à des tâches invisibles : étant donné une nouvelle tâche t, l’activation Gist correspondante G(t) peut être prédite et utilisée sans aucune formation supplémentaire.
Apprendre Gisting via des masques
Le cadre général de Gisting a été décrit ci-dessus, et nous explorerons ensuite une manière très simple d'apprendre un tel modèle : utiliser le LM lui-même comme prédicteur Gist G. Cela exploite non seulement les connaissances préexistantes dans le LM, mais permet également d'apprendre l'essentiel en effectuant simplement un réglage précis des instructions standard et en modifiant le masque d'attention du Transformer pour améliorer la compression rapide. Cela signifie que Gisting n'entraîne pas de frais de formation supplémentaires et doit uniquement être peaufiné sur la base d'instructions standard !
Plus précisément, ajoutez un jeton essentiel spécial au vocabulaire du modèle et à la matrice d'intégration, similaire aux jetons de début/fin de phrase courants dans de tels modèles. Ensuite, pour un tuple donné (tâche, entrée) (t, x), concaténez t et x ensemble en utilisant un ensemble de k jetons essentiels consécutifs dans (t, g_1, . . . , g_k, x), par exemple 
La figure 2 ci-dessous montre les modifications requises. Pour les LM à décodeur uniquement tels que GPT-3 ou LLaMA, qui utilisent généralement des masques d'attention causale autorégressifs, il suffit de masquer le coin inférieur gauche du triangle illustré à la figure 2a. Pour un codeur-décodeur LM avec un codeur bidirectionnel et un décodeur autorégressif, deux modifications sont nécessaires (illustré sur la figure 2b).
Tout d'abord, dans les encodeurs qui n'ont généralement pas de masques, bloquez le jeton d'entrée x en référence au jeton d'invite t. Mais il faut également éviter que l'invite t et le jeton essentiel g_i fassent référence au jeton d'entrée x, sinon l'encodeur apprendra différentes représentations essentielles en fonction de l'entrée. Enfin, le décodeur fonctionne normalement sauf pendant les périodes d'attention croisée, où il faut empêcher le décodeur de se référer au jeton d'invite t.
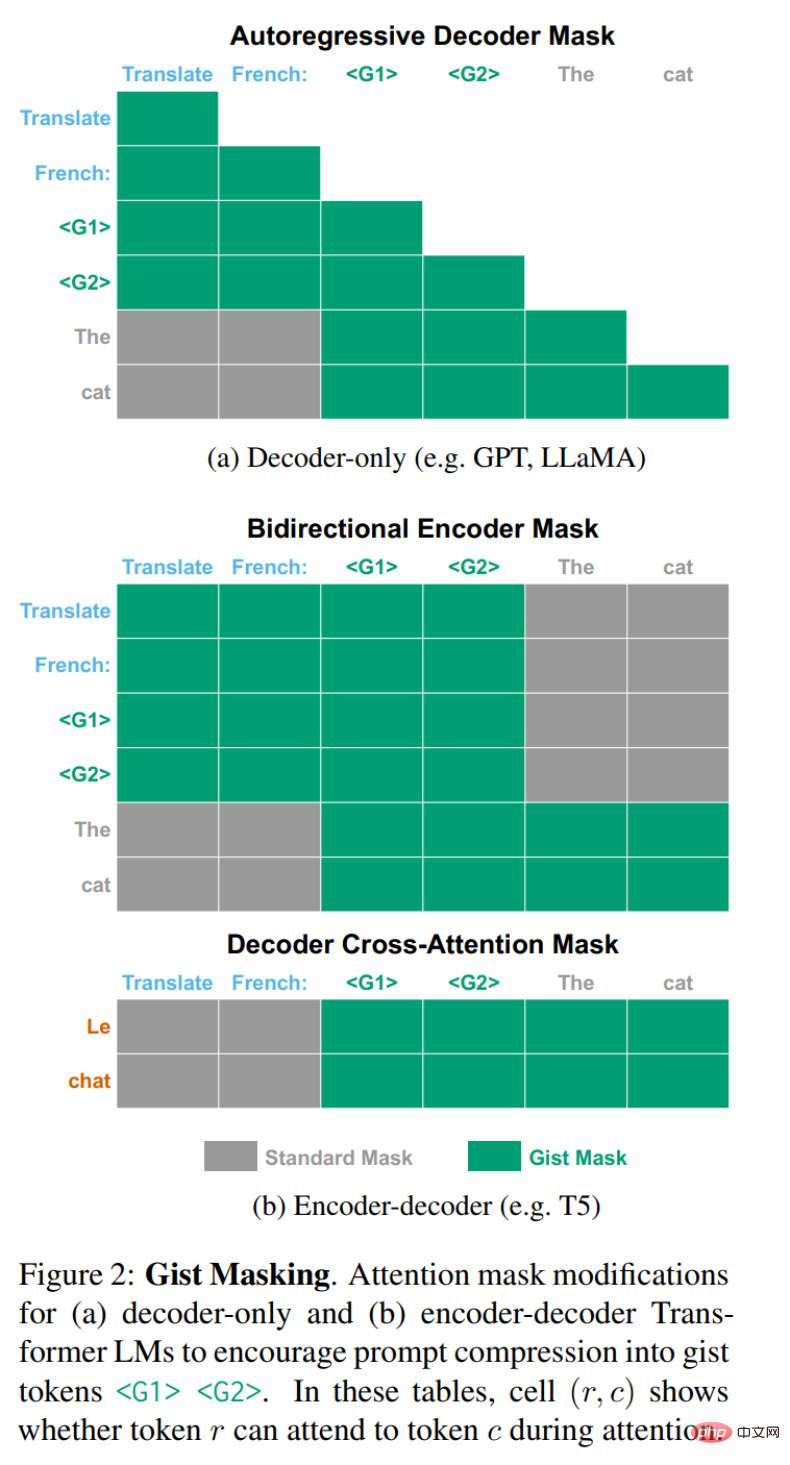
Résultats expérimentaux
Pour différents nombres de jetons essentiels, les résultats d'évaluation ROUGE-L et ChatGPT de LLaMA-7B et FLAN-T5-XXL sont présentés dans la figure 3 ci-dessous.
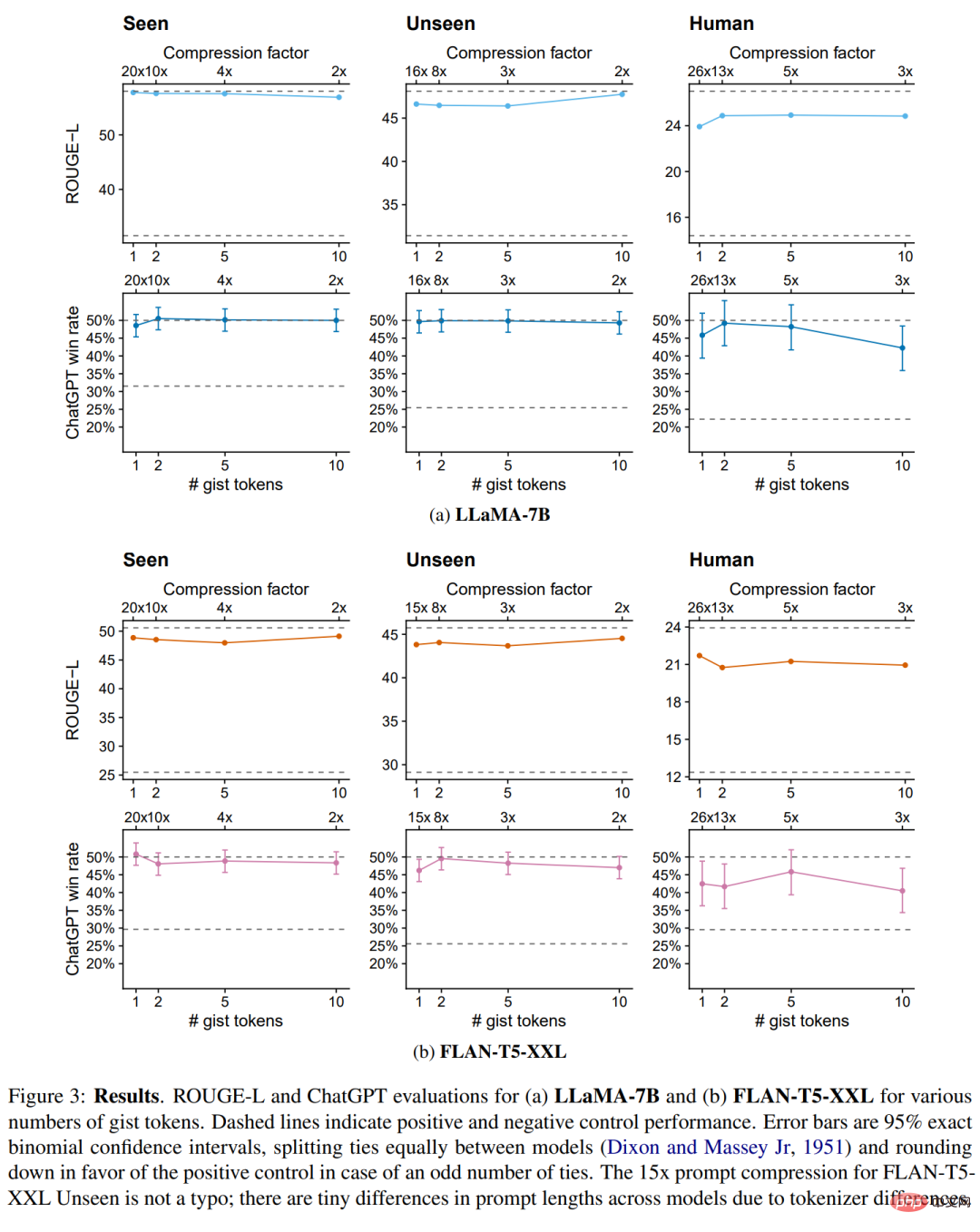
Les modèles sont généralement insensibles au nombre k de jetons essentiels : la compression des invites en un seul jeton n'entraîne pas de dégradation significative des performances. En fait, dans certains cas, trop de jetons essentiels nuisent aux performances (par exemple LLaMA-7B, 10 jetons essentiels), peut-être parce que la capacité accrue suradapte à la distribution de formation. Par conséquent, les chercheurs donnent les valeurs spécifiques du modèle à jeton unique dans le tableau 1 ci-dessous et utilisent un modèle essentiel unique dans les expériences restantes.
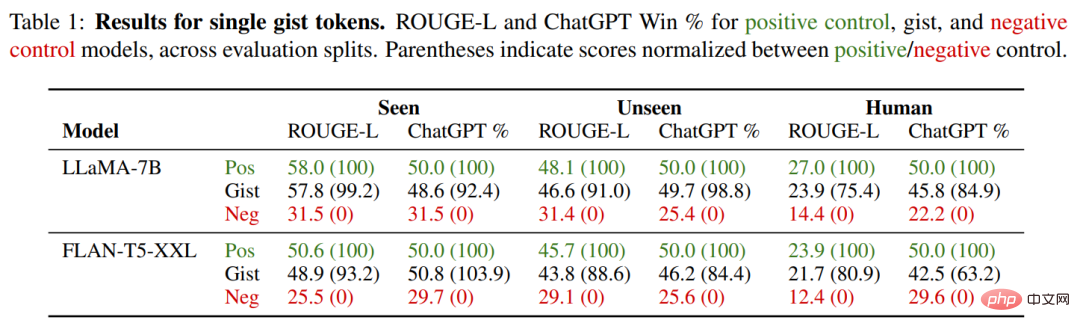
Sur les instructions vues, le modèle essentiel a obtenu presque les mêmes performances ROUGE et ChatGPT que son modèle de contrôle positif correspondant, avec des taux de victoire de 48,6 % et 48,6 % respectivement sur LLaMA-7B FLANT5- XXL 50,8%. Ce qui intéresse le plus les chercheurs ici, c'est leur capacité de généralisation sur des tâches invisibles, qui doit être mesurée à l'aide de deux autres ensembles de données.
Dans les invites invisibles de l'ensemble de données d'entraînement Alpaca+, nous pouvons voir que le modèle essentiel a une forte capacité de généralisation sur les invites invisibles : 49,7 % (LLaMA) et 46,2 % respectivement par rapport au groupe témoin (FLAN-T5) gagnant taux. Sur la division OOD Human la plus difficile, le taux de victoire du modèle essentiel chute légèrement à 45,8 % (LLaMA) et 42,5 % (FLANT5).
Le but de cet article est d'avoir un modèle essentiel qui imite fidèlement les fonctionnalités du modèle d'origine, on pourrait donc se demander quand exactement un modèle essentiel est impossible à distinguer d'un groupe témoin. La figure 4 ci-dessous illustre la fréquence à laquelle cela se produit : pour les tâches vues (mais les entrées invisibles), le modèle essentiel est à égalité avec le groupe témoin presque la moitié du temps. Pour les tâches invisibles, ce nombre tombe à 20-25 %. Pour la tâche OOD Human, ce chiffre retombe à 10 %. Quoi qu’il en soit, la qualité de la sortie du modèle essentiel est très élevée.
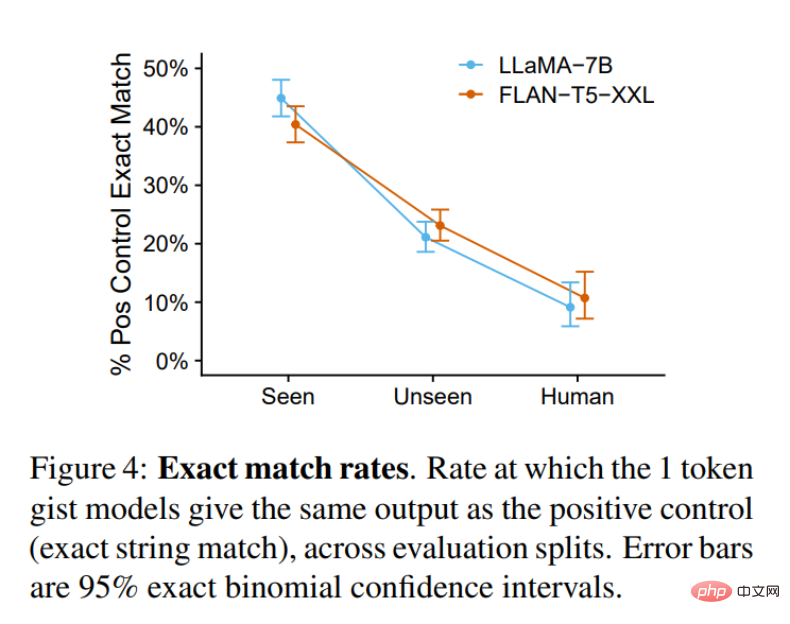
Dans l'ensemble, ces résultats montrent que le modèle Gist peut compresser de manière fiable les invites, même sur certaines invites en dehors de la distribution de formation, en particulier comme LLaMA Un tel LM causal uniquement par décodeur. Les modèles d'encodeur-décodeur tels que FLAN-T5 fonctionnent légèrement moins bien. Une raison possible est que le masque essentiel supprime le flux d'attention bidirectionnel dans l'encodeur, ce qui est plus difficile que de simplement masquer une partie de l'historique dans le décodeur autorégressif. Des travaux supplémentaires sont nécessaires pour étudier cette hypothèse à l’avenir.
Efficacité du calcul, de la mémoire et du stockage
Enfin, revenons à l'une des principales motivations de ce travail : quel type d'amélioration de l'efficacité le gisting peut-il apporter ?
Le tableau 2 ci-dessous montre les résultats d'une seule passe avant du modèle (c'est-à-dire une étape de décodage autorégressif à l'aide d'un seul jeton d'entrée) à l'aide du profileur PyTorch 2.0, en moyenne sur les 252 instructions de la valeur de division de l'évaluation humaine. La mise en cache Gist améliore considérablement l'efficacité par rapport aux modèles non optimisés. Des économies de FLOP de 40 % et des réductions de temps d'horloge de 4 à 7 % ont été réalisées pour les deux modèles.
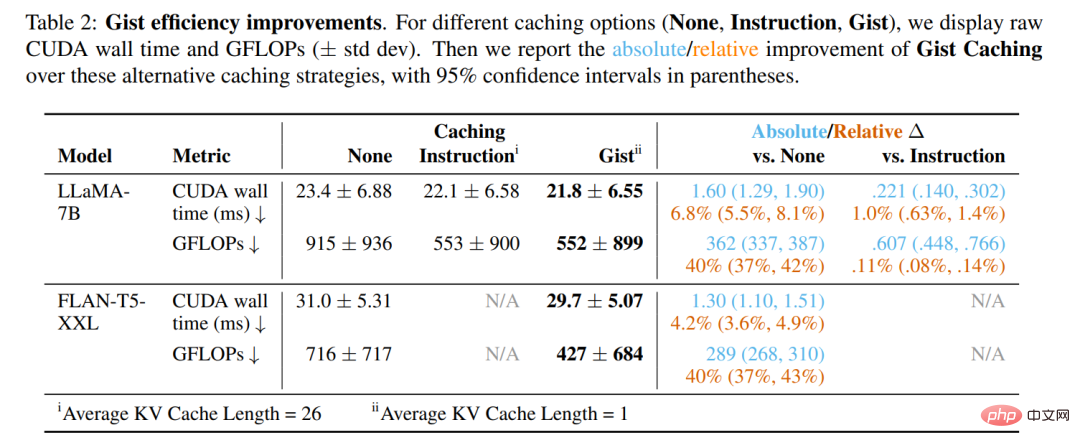
Plus important encore, cependant, par rapport au cache d'instructions, le cache Gist présente un avantage clé en plus de la latence : la compression de 26 jetons en 1 libère la fenêtre de contexte d'entrée. Plus d'espace, qui est limité par intégration de position absolue ou GPU VRAM. Surtout pour LLaMA-7B, chaque jeton du cache KV nécessite 1,05 Mo d'espace de stockage. Bien que le cache KV contribue peu à la mémoire totale requise pour l'inférence LLaMA-7B avec les longueurs d'invite testées, un scénario de plus en plus courant consiste pour les développeurs à mettre en cache de nombreuses invites sur un grand nombre d'utilisateurs, et le coût de stockage peut rapidement augmenter. Avec le même espace de stockage, le cache Gist peut gérer 26 fois plus d'invites que le cache d'instructions complet.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI