
Maison >Périphériques technologiques >IA >Un document interne de Google divulgué montre que Google et OpenAI manquent de mécanismes de protection efficaces, de sorte que le seuil pour les grands modèles est continuellement abaissé par la communauté open source.
Un document interne de Google divulgué montre que Google et OpenAI manquent de mécanismes de protection efficaces, de sorte que le seuil pour les grands modèles est continuellement abaissé par la communauté open source.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-08 23:19:201585parcourir
"Nous n'avons pas de fossé, et OpenAI non plus." Dans un document récemment divulgué, un chercheur de Google a exprimé ce point de vue.
Ce chercheur estime que même si, à première vue, il semble qu'OpenAI et Google se poursuivent sur de grands modèles d'IA, le véritable gagnant ne viendra peut-être pas de ces deux-là, car une force tierce se lève tranquillement.
Cette puissance est appelée « Open Source ». En se concentrant sur les modèles open source tels que LLaMA de Meta, l'ensemble de la communauté construit rapidement des modèles dotés de fonctionnalités similaires à celles d'OpenAI et des grands modèles de Google. De plus, les modèles open source sont itératifs plus rapides, plus personnalisables et plus privés... "Quand c'est gratuit. Les gens ne paieront pas pour un modèle restreint alors que les alternatives sans restriction sont de qualité égale », écrivent les auteurs.
Ce document a été initialement partagé par une personne anonyme sur un serveur Discord public SemiAnalysis, un média industriel autorisé à réimprimer, a déclaré avoir vérifié l'authenticité de ce document.
Cet article a été largement relayé sur les plateformes sociales telles que Twitter. Parmi eux, Alex Dimakis, professeur à l'Université du Texas à Austin, a exprimé le point de vue suivant :
- L'IA open source est en train de gagner Je suis d'accord que c'est une bonne chose pour le monde et pour la construction d'un écosystème compétitif. C'est aussi une bonne chose. Bien que nous n'en soyons pas encore là dans le monde LLM, OpenClip vient de battre openAI Clip, et Stable Diffusion était meilleur que le modèle fermé.
- Vous n'avez pas besoin d'un modèle énorme, des données de haute qualité sont plus efficaces et plus importantes, et le modèle alpaga derrière l'API affaiblit encore davantage le fossé.
- Vous pouvez commencer avec un bon modèle de base et un algorithme PEFT (Parameter Efficient Fine-Tuning) tel que Lora qui fonctionne très bien en une journée. L'innovation algorithmique a enfin commencé !
- Les universités et les communautés open source devraient organiser davantage d'efforts pour gérer les ensembles de données, former des modèles de base et créer des communautés de réglage fin comme Stable Diffusion.
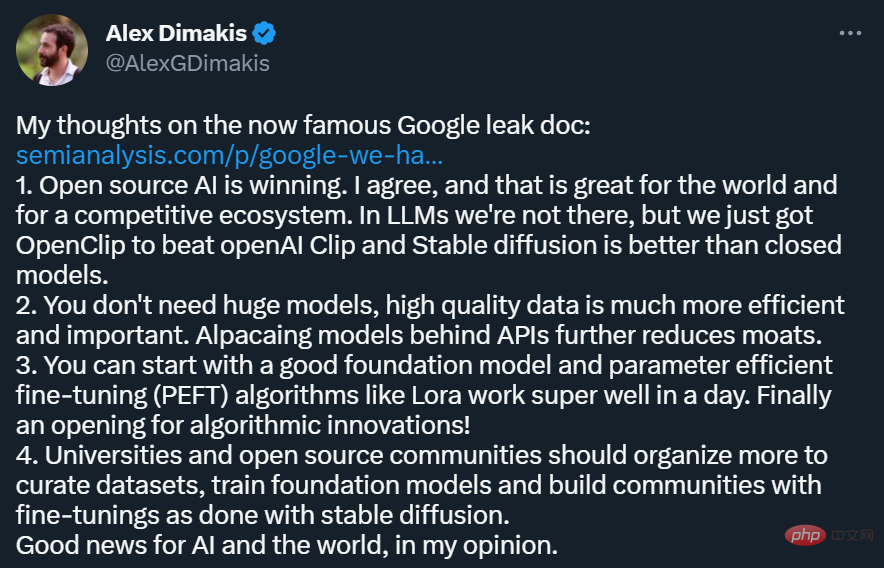
Bien sûr, tous les chercheurs ne sont pas d'accord avec les opinions exprimées dans l'article. Certaines personnes sont sceptiques quant à savoir si les modèles open source peuvent réellement avoir la puissance et la polyvalence de grands modèles comparables à OpenAI.
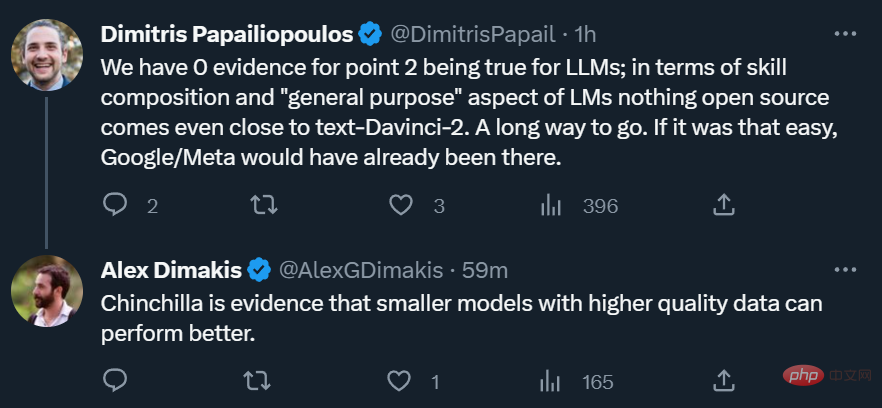
Cependant, pour le monde universitaire, la montée en puissance de l'open source est toujours une bonne chose, ce qui signifie que même s'il n'y a pas 1000 GPU, les chercheurs ont encore quelque chose à faire.
Ce qui suit est le texte original du document :
Ni Google ni OpenAI n'ont de fossés
Nous n'avons pas de fossé, et OpenAI non plus.
Nous avons prêté attention à la dynamique et au développement d'OpenAI. Qui franchira le prochain cap ? Quelle est la prochaine étape ?
Mais la vérité inconfortable est que nous ne sommes pas équipés pour gagner cette course aux armements, et OpenAI non plus. Pendant que nous nous chamaillions, une troisième faction en récolte les fruits.
Cette faction est la "faction open source". Franchement, ils nous dépassent. Ce que nous considérions comme les « problèmes importants à résoudre » sont désormais résolus et sont désormais entre les mains des citoyens.
Laissez-moi vous donner quelques exemples :
- Grand modèle de langage pouvant fonctionner sur les téléphones mobiles : on peut exécuter le modèle de base sur le Pixel 6 à 5 jetons/seconde.
- IA personnelle évolutive : vous pouvez passer une soirée à peaufiner une IA personnalisée sur votre ordinateur portable.
- Édition responsable : Ce problème n’est pas tant « résolu » qu’« ignoré ». Certains sites Web sont des modèles entièrement artistiques sans aucune restriction, et le texte ne fait pas exception.
- Multi-modal : L'actuelle QA scientifique multimodale SOTA est formée en moins d'une heure.
Bien que nos modèles conservent encore un léger avantage en termes de qualité, l'écart se réduit à un rythme alarmant. Le modèle open source est plus rapide, plus personnalisable, plus privé et plus puissant dans les mêmes conditions. Ils font quelque chose avec des paramètres de 100 et 13 milliards de dollars que nous avons du mal à faire avec des paramètres de 10 millions et 54 milliards de dollars. Et ils peuvent le faire en quelques semaines, pas en mois. Cela a de profondes implications pour nous :
- Nous n’avons pas de sauce secrète. Notre meilleur espoir est d'apprendre et de collaborer avec d'autres personnes extérieures à Google. Nous devrions donner la priorité à la réalisation de l’intégration 3P.
- Les gens ne paieront pas pour un modèle restreint alors que l’alternative gratuite et sans restriction est de qualité comparable. Nous devons réfléchir à où se situe notre valeur ajoutée.
- Le modèle énorme nous a ralenti. À long terme, les meilleurs modèles sont ceux qui peuvent être répétés rapidement. Maintenant que nous savons ce que peuvent faire les modèles avec 20 milliards de paramètres, nous devons les construire dès le départ.
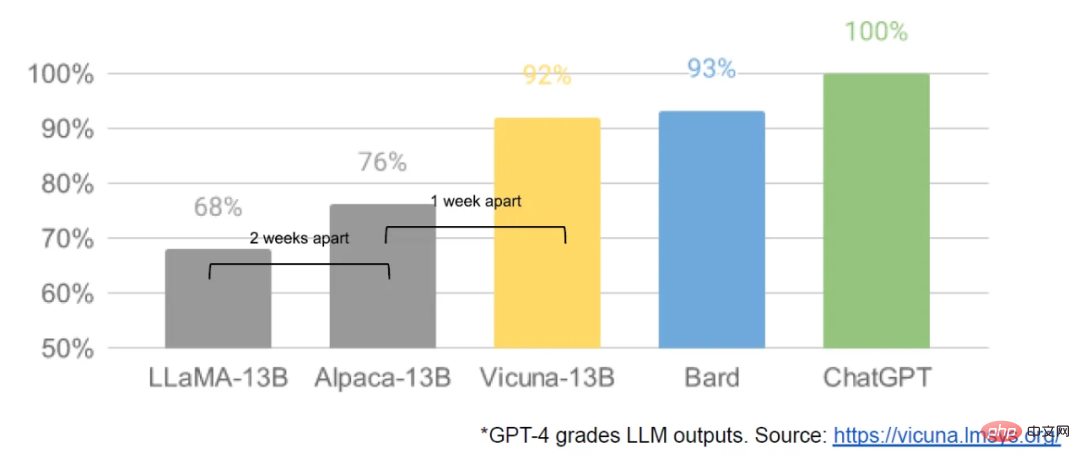
Modifications open source initiées par LLaMA
Début mars, avec la fuite du modèle LLaMA de Meta au public, la communauté open source a obtenu son premier modèle de base vraiment utile. Ce modèle n'a pas d'instructions ni de réglages de dialogue, et pas de RLHF. Néanmoins, la communauté open source a immédiatement compris l'importance de LLaMA.
Ce qui a suivi a été un flux constant d'innovations, avec des développements majeurs survenus à quelques jours d'intervalle (comme l'exécution du modèle LLaMA sur Raspberry Pi 4B, le réglage fin des instructions LLaMA sur un ordinateur portable, l'exécution de LLaMA sur un MacBook, etc.) . À peine un mois plus tard, des variantes telles que le réglage fin des instructions, la quantification, l'amélioration de la qualité, la multimodalité, le RLHF, etc. sont toutes apparues, dont beaucoup s'appuient les unes sur les autres.
Mieux encore, ils ont résolu le problème de mise à l'échelle, ce qui signifie que n'importe qui peut librement modifier et optimiser ce modèle. De nombreuses idées nouvelles viennent de gens ordinaires. Le seuil de formation et d’expérimentation est passé des grands instituts de recherche à une seule personne, une soirée et un ordinateur portable puissant.
Moment de diffusion stable du LLM
À bien des égards, cela ne devrait surprendre personne. La renaissance actuelle du LLM open source fait suite à une renaissance de la génération d’images, beaucoup appelant cela le moment de diffusion stable pour le LLM.
Dans les deux cas, la participation du public à faible coût est obtenue grâce à un mécanisme de réglage fin d'adaptation de bas rang (LoRA) beaucoup moins coûteux, combiné à une avancée majeure en termes d'échelle. La disponibilité aisée de modèles de haute qualité a aidé les individus et les institutions du monde entier à incuber un pipeline d’idées et leur a permis de les exploiter et de devancer rapidement les grandes entreprises.
Ces contributions sont cruciales dans le domaine de la génération d'images et placent Stable Diffusion sur une voie différente de celle de Dall-E. Le fait de disposer d'un modèle ouvert a permis l'intégration de produits, de marchés, d'interfaces utilisateur et d'innovations qui n'étaient pas présentes chez Dall-E.
L’effet est évident : l’impact culturel de Stable Diffusion domine rapidement par rapport aux solutions OpenAI. Reste à savoir si LLM connaîtra des tendances similaires, mais les grands éléments structurels sont les mêmes.
Qu'est-ce que Google a manqué ?
Les projets open source utilisent des méthodes ou des technologies innovantes qui résolvent directement des problèmes avec lesquels nous sommes encore aux prises. Prêter attention aux efforts open source peut nous aider à éviter de commettre les mêmes erreurs. Parmi elles, LoRA est une technologie extrêmement puissante et nous devrions y prêter plus d’attention.
LoRA présente les mises à jour du modèle comme une factorisation de bas rang, ce qui peut réduire la taille de la matrice de mise à jour des milliers de fois. De cette manière, le réglage fin du modèle ne nécessite que peu de temps et d’argent. Il est important de réduire le temps nécessaire au réglage personnalisé des modèles de langage à quelques heures sur du matériel grand public, en particulier pour ceux qui souhaitent intégrer des connaissances nouvelles et diverses en temps quasi réel. Même si la technologie a un impact important sur certains des projets que nous souhaitons réaliser, elle est sous-utilisée au sein de Google.
Le pouvoir magique de LoRA
Une des raisons pour lesquelles LoRA est si efficace : comme d'autres formes de réglage, il se cumule. Nous pouvons appliquer des améliorations telles que le réglage fin des commandes pour faciliter des tâches telles que le dialogue et le raisonnement. Bien que les ajustements individuels soient de faible rang, alors que leur somme ne l'est pas, LoRA permet aux mises à jour de rang complet du modèle de s'accumuler au fil du temps.
Cela signifie qu'à mesure que des ensembles de données et des tests plus récents et de meilleure qualité deviennent disponibles, le modèle peut être maintenu à jour à moindre coût sans avoir à payer le coût total de fonctionnement.
En revanche, entraîner un grand modèle à partir de zéro non seulement jette la pré-formation, mais jette également toutes les itérations et améliorations précédentes. Dans le monde open source, ces améliorations deviennent rapidement monnaie courante, rendant une reconversion complète extrêmement coûteuse.
Nous devrions sérieusement nous demander si chaque nouvelle application ou idée nécessite réellement un modèle complètement nouveau. Si nous disposons d'améliorations architecturales significatives qui empêchent la réutilisation directe des poids des modèles, nous devrions alors nous engager dans une approche plus agressive de la distillation qui préserve autant que possible les fonctionnalités de la génération précédente.
Grand modèle vs petit modèle, qui est le plus compétitif ?
Le coût des mises à jour LoRA est très faible (environ 100$) pour les tailles de modèles les plus populaires. Cela signifie que presque toute personne ayant une idée peut la générer et la diffuser. À des vitesses normales, où l'entraînement prend moins d'une journée, l'effet cumulatif du réglage fin surmonte rapidement le désavantage initial de taille. En fait, ces modèles s’améliorent beaucoup plus rapidement que nos plus grandes variantes ne peuvent le faire en termes de temps d’ingénierie. Et les meilleurs modèles sont déjà largement impossibles à distinguer de ChatGPT. Donc, nous concentrer sur le maintien de certains des plus grands modèles nous désavantage. Beaucoup de ces projets permettent d'économiser du temps en s'entraînant sur de petits ensembles de données hautement organisés. Cela indique une flexibilité dans les règles de mise à l'échelle des données. Cet ensemble de données existe à partir des idées de Data Doesn't Do What You Think et devient rapidement le moyen standard de s'entraîner sans Google. Ces ensembles de données sont créés à l'aide de méthodes synthétiques (telles que le filtrage des meilleures réflexions des modèles existants) et extraits d'autres projets, qui ne sont pas couramment utilisés chez Google. Heureusement, ces ensembles de données de haute qualité sont open source et sont donc disponibles gratuitement. Cette évolution récente a un impact très direct sur la stratégie des entreprises. Qui paierait pour un produit Google avec des restrictions d'utilisation alors qu'il existe une alternative gratuite et de haute qualité sans restrictions d'utilisation ? Par ailleurs, il ne faut pas espérer rattraper son retard. L'Internet moderne fonctionne en open source, car l'open source présente des avantages significatifs que nous ne pouvons pas reproduire.
"Nous avons besoin d'eux" plus que "ils ont besoin de nous"
Garder nos secrets technologiques est toujours une proposition fragile. Les chercheurs de Google se rendent régulièrement dans d’autres entreprises pour étudier. On peut donc supposer qu’ils savent tout ce que nous savons. Et ils continueront à le faire aussi longtemps que ce pipeline sera ouvert.
Mais à mesure que la recherche de pointe dans le domaine des LLM devient abordable, maintenir un avantage concurrentiel technologique devient de plus en plus difficile. Les institutions de recherche du monde entier apprennent les unes des autres pour explorer les possibilités de solutions selon une approche globale qui dépasse largement nos propres capacités. Nous pouvons travailler dur pour conserver nos propres secrets, mais l’innovation externe dilue leur valeur, alors essayez d’apprendre les uns des autres.Les particuliers ne sont pas liés par des licences comme les entreprises
La plupart des innovations sont construites sur les poids des modèles divulgués par Meta. Cela changera inévitablement à mesure que les modèles véritablement ouverts s’amélioreront, mais le fait est qu’il n’est pas nécessaire d’attendre. Les protections juridiques fournies par « l'usage personnel » et l'impossibilité de poursuites individuelles signifient que les individus peuvent utiliser ces technologies pendant qu'elles sont chaudes.Paradoxalement, il n'y a qu'un seul gagnant dans tout cela, et c'est Meta, après tout, le modèle divulgué est le leur. La plupart des innovations open source reposant sur leur architecture, rien n’empêche de les intégrer directement dans leurs propres produits. Comme vous pouvez le constater, la valeur d’avoir un écosystème ne peut être surestimée. Google lui-même utilise déjà ce paradigme dans des produits open source comme Chrome et Android. En créant une plate-forme d'incubation de travaux innovants, Google a consolidé sa position de leader d'opinion et de pionnier, acquérant la capacité de façonner des idées plus grandes qu'elle. Plus nous contrôlons étroitement nos modèles, plus il est intéressant de créer des alternatives ouvertes. Google et OpenAI ont tendance à avoir un modèle de version défensive qui leur permet de contrôler strictement la manière dont les modèles sont utilisés. Cependant, ce contrôle est irréaliste. Quiconque souhaite utiliser les LLM à des fins non approuvées peut choisir parmi des modèles disponibles gratuitement. Par conséquent, Google devrait se positionner comme un leader dans la communauté open source et prendre les devants en collaborant à un dialogue plus large plutôt que de l'ignorer. Cela peut impliquer de prendre des mesures inconfortables, comme publier les poids des modèles pour les petites variantes d'ULM. Cela signifie aussi nécessairement renoncer à un certain contrôle sur son propre modèle, mais ce compromis est inévitable. Nous ne pouvons pas espérer à la fois stimuler l’innovation et la contrôler. Compte tenu de la politique fermée actuelle d’OpenAI, toutes ces discussions sur l’open source semblent injustes. S’ils ne sont pas disposés à partager la technologie, pourquoi devrions-nous la partager ? Mais le fait est que nous avons tout partagé avec eux en débauchant continuellement les chercheurs seniors d’OpenAI. Tant que nous n’aurons pas endigué la marée, le secret restera une question controversée. Enfin, OpenAI n'a pas d'importance. Ils commettent les mêmes erreurs que nous avec leur position open source, et leur capacité à conserver leur avantage sera forcément remise en question. À moins qu’OpenAI ne change de position, les alternatives open source peuvent et finiront par les éclipser. Au moins à cet égard, nous pouvons franchir cette étape. Possédez l'écosystème : faites en sorte que le travail Open Source fonctionne pour vous
Où est l’avenir d’OpenAI ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI