
Maison >Périphériques technologiques >IA >La pré-formation ne nécessite aucune attention et la mise à l'échelle jusqu'à 4 096 jetons ne pose aucun problème, ce qui est comparable à BERT.
La pré-formation ne nécessite aucune attention et la mise à l'échelle jusqu'à 4 096 jetons ne pose aucun problème, ce qui est comparable à BERT.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-08 19:37:081208parcourir
Transformer, en tant qu'architecture de modèle de pré-formation PNL, peut apprendre efficacement sur des données non étiquetées à grande échelle. La recherche a prouvé que Transformer est l'architecture de base des tâches PNL depuis BERT.
Des travaux récents ont montré que les modèles spatiaux d'états (SSM) constituent une architecture concurrente favorable pour la modélisation de séquences à longue portée. SSM obtient des résultats de pointe en matière de génération de parole et de benchmarks Long Range Arena, encore meilleurs que l'architecture Transformer. En plus d'améliorer la précision, la couche de routage basée sur SSM ne présentera pas de complexité quadratique à mesure que la longueur de la séquence augmente.
Dans cet article, des chercheurs de l'Université Cornell, DeepMind et d'autres institutions ont proposé le SSM bidirectionnel (BiGS) pour un pré-entraînement sans attention. Il combine principalement le routage SSM avec une architecture de gating basée sur la multiplication (gating multiplicatif). L'étude a révélé que SSM en lui-même fonctionne mal en matière de pré-formation à la PNL, mais qu'une fois intégré dans une architecture multiplicative et fermée, la précision en aval s'améliore.
Les expériences montrent que BiGS est capable d'égaler les performances du modèle BERT lorsqu'il est formé sur les mêmes données dans des paramètres contrôlés. Avec un pré-entraînement supplémentaire sur des instances plus longues, le modèle maintient également un temps linéaire lors de la mise à l'échelle de la séquence d'entrée à 4 096. L'analyse montre que le déclenchement multiplicatif est nécessaire et résout certains problèmes spécifiques des modèles SSM sur les entrées de texte de longueur variable.

Adresse papier : https://arxiv.org/pdf/2212.10544.pdf
Introduction à la méthode
SSM saisira continuellement u (t) et sortira y (t) via ce qui suit équation différentielle ) sont connectées :
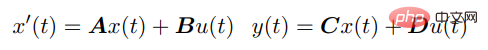
Pour les séquences discrètes, les paramètres SSM sont discrétisés, et le processus peut être approximé comme :
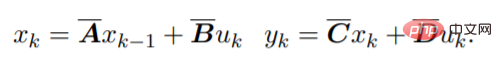
Cette équation peut être interprétée comme un RNN linéaire, où x_k est un état caché. y peut également être calculé à l'aide de convolutions :
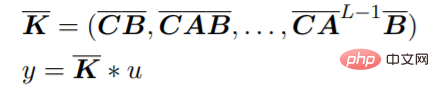
Un moyen efficace d'utiliser SSM dans les réseaux de neurones a été démontré par Gu et al., qui ont développé une méthode pour paramétrer A, appelée HiPPO, qui produit une architecture stable et efficace. est appelé S4. Cela conserve la capacité du SSM à modéliser des séquences à long terme tout en étant plus efficace que la formation RNN. Récemment, des chercheurs ont proposé une version diagonalisée simplifiée de S4 qui permet d'obtenir des résultats similaires avec une approximation plus simple des paramètres d'origine. À un niveau élevé, le routage basé sur SSM offre une alternative à la modélisation de séquences dans des réseaux de neurones sans le coût attentionnel des calculs secondaires.
Architecture de modèle pré-entraînée
Le SSM peut-il remplacer l'attention lors de la pré-formation ? Pour répondre à cette question, cette étude considère deux architectures différentes, l'architecture empilée (STACK) et l'architecture fermée multiplicative (GATED) illustrée à la figure 1.
L'architecture empilée avec auto-attention est équivalente au modèle BERT/transformateur, et l'architecture fermée est une adaptation bidirectionnelle de l'unité fermée, qui a également été récemment utilisée pour le SSM unidirectionnel. 2 blocs de séquence (c'est-à-dire SSM avant et arrière) avec déclenchement multiplicatif sont pris en sandwich dans une couche à action directe. Pour une comparaison équitable, la taille de l’architecture fermée reste comparable à celle de l’architecture empilée.
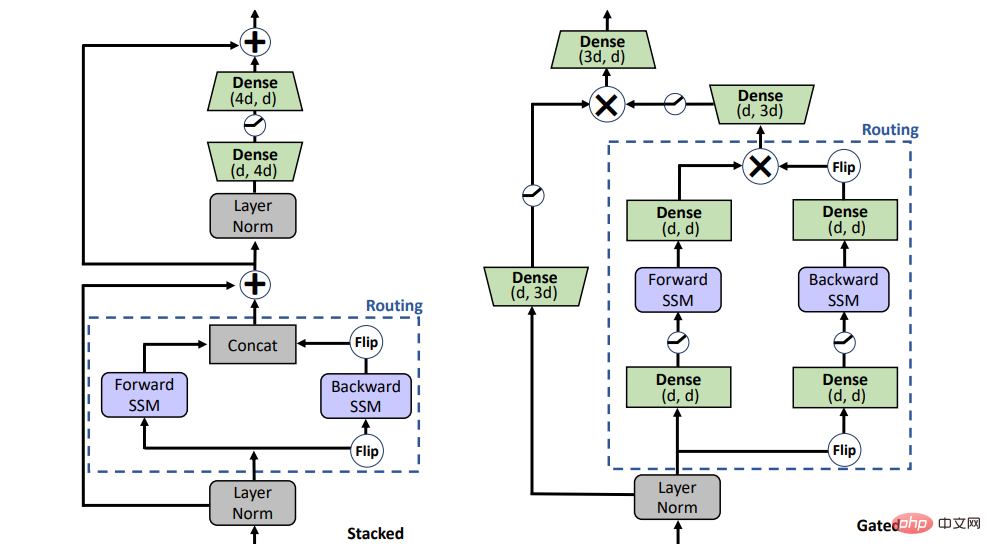
Figure 1 : Variables du modèle. STACK est une architecture de transformateur standard et GATED est basée sur des unités de contrôle de porte. Pour le composant Routage (ligne pointillée), l’étude prend en compte à la fois le SSM bidirectionnel (illustré sur la figure) et l’auto-attention standard. Gated(X) représente la multiplication par élément.
Résultats expérimentaux
Pré-entraînement
Le tableau 1 présente les principaux résultats de différents modèles pré-entraînés sur le benchmark GLUE. BiGS reproduit la précision de BERT sur l'expansion des jetons. Ce résultat montre que SSM peut reproduire la précision du modèle de transformateur pré-entraîné avec un tel budget de calcul. Ces résultats sont nettement meilleurs que ceux d’autres modèles pré-entraînés non basés sur l’attention. Pour atteindre cette précision, un déclenchement multiplicatif est nécessaire. Sans gate, les résultats du SSM empilé sont bien pires. Pour examiner si cet avantage vient principalement de l'utilisation du gating, nous avons formé un modèle basé sur l'attention en utilisant l'architecture GATE. Cependant, les résultats montrent que le modèle est en réalité moins efficace que BERT ;
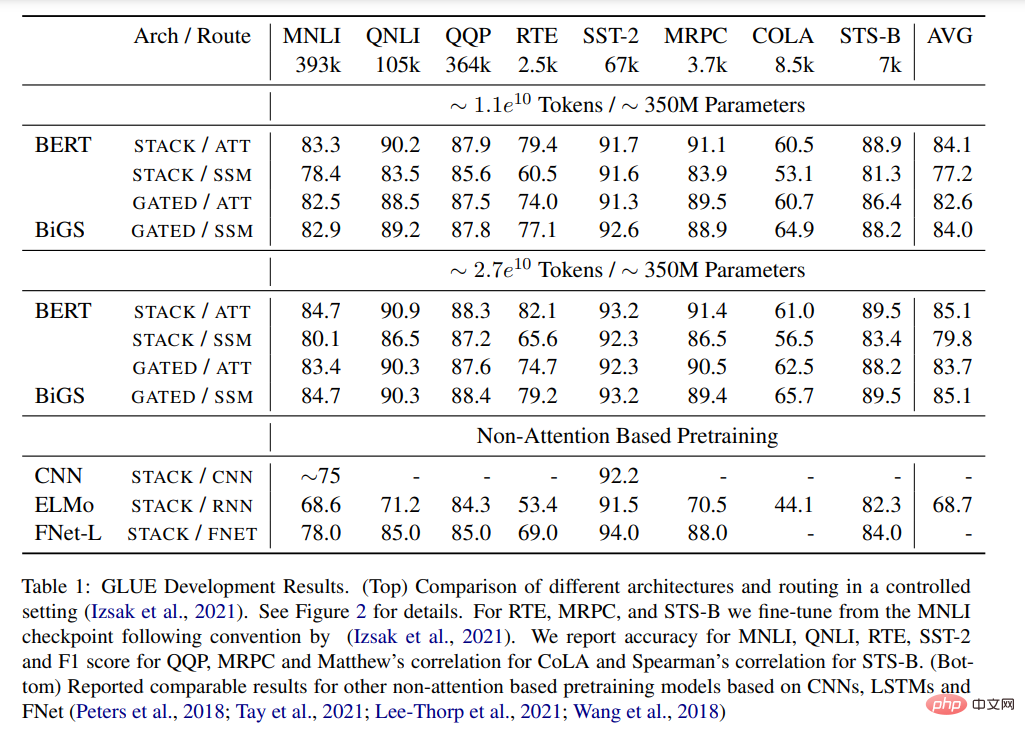
Tableau 1 : Résultats COLLE. (Haut) Comparaison de différentes architectures et routage sous paramètres de contrôle. Voir la figure 2 pour plus de détails. (En bas) a rapporté des résultats comparables pour d'autres modèles pré-entraînés sans attention basés sur CNN, LSTM et FNet.
Tâche longue
Tableau 2 Les résultats montrent que SSM peut être comparé à Longformer EncoderDecoder (LED) et BART, cependant, les résultats montrent qu'il fonctionne également bien dans les tâches à distance, même Encore mieux. SSM dispose de beaucoup moins de données de pré-entraînement que les deux autres méthodes. Même si SSM n’a pas besoin de se rapprocher de ces longueurs, la forme longue reste importante.
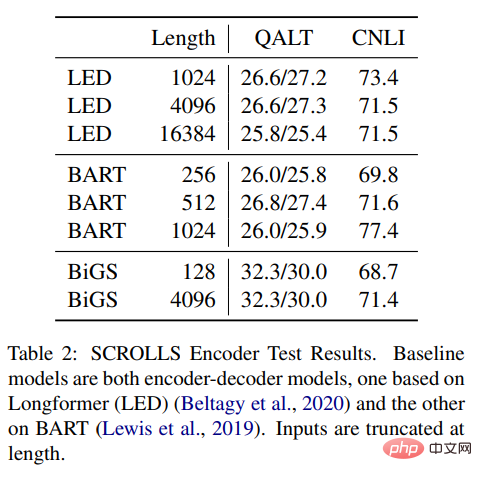
Tableau 2 : Résultats des tests de l'encodeur SCROLLS. Les modèles de base sont tous deux des modèles d'encodeur-décodeur, l'un basé sur Longformer (LED) et l'autre basé sur BART. La longueur saisie est tronquée.
Veuillez consulter le document original pour plus d'informations.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI