
Maison >Périphériques technologiques >IA >HuggingGPT : un outil magique pour les tâches d'IA
HuggingGPT : un outil magique pour les tâches d'IA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-08 18:40:191491parcourir
Introduction
L'intelligence générale artificielle (AGI) peut être considérée comme un système d'intelligence artificielle capable de comprendre, de traiter et de répondre à des tâches intellectuelles comme les humains. Il s’agit d’une tâche difficile qui nécessite une compréhension approfondie du fonctionnement du cerveau humain afin de pouvoir le reproduire. Cependant, l’émergence de ChatGPT a suscité un énorme intérêt de la part de la communauté des chercheurs pour le développement de tels systèmes. Microsoft a publié un tel système clé basé sur l'IA appelé HuggingGPT (Microsoft Jarvis).
Avant de plonger dans les nouveautés de HuggingGPT et les détails pertinents sur son fonctionnement, comprenons d'abord les problèmes de ChatGPT et pourquoi il a du mal à résoudre des tâches d'IA complexes. Les grands modèles de langage comme ChatGPT sont efficaces pour interpréter les données textuelles et gérer les tâches générales. Cependant, ils ont souvent du mal à accomplir certaines tâches et peuvent réagir de manière absurde. Vous avez peut-être rencontré de fausses réponses de ChatGPT en résolvant des problèmes mathématiques complexes. D'autre part, nous disposons de modèles d'IA de niveau expert tels que Stable Diffusion et DALL-E, qui ont une compréhension plus approfondie de leurs domaines respectifs mais ont du mal à gérer un plus large éventail de tâches. À moins d'établir une connexion entre le LLM et les modèles d'IA professionnels, nous ne pouvons pas exploiter pleinement le potentiel du LLM pour résoudre des tâches d'IA difficiles. C'est ce que fait HuggingGPT, il combine les avantages des deux pour créer un système d'IA plus efficace, précis et polyvalent.
Qu'est-ce que HuggingGPT ?
Selon un article récent publié par Microsoft, HuggingGPT exploite la puissance de LLM en tant que contrôleur, en le connectant à divers modèles d'IA de la communauté d'apprentissage automatique (HuggingFace), lui permettant d'utiliser des outils externes pour améliorer l'efficacité du travail. HuggingFace est un site Web qui fournit une multitude d'outils et de ressources aux développeurs et aux chercheurs. Il propose également une grande variété de modèles professionnels et de haute précision. HuggingGPT applique ces modèles à des tâches d'IA complexes dans différents domaines et modes, obtenant des résultats impressionnants. Il possède des capacités multimodales similaires à OPenAI GPT-4 en ce qui concerne le texte et les images. Cependant, il vous connecte également à Internet et vous pouvez fournir un lien Web externe pour poser des questions à ce sujet.
Supposons que vous souhaitiez que le modèle fasse une lecture audio d'un texte écrit sur une image. HuggingGPT effectuera cette tâche en série en utilisant le modèle le mieux adapté. Tout d’abord, il exportera le texte de l’image et utilisera le résultat pour la génération audio. Les détails de la réponse peuvent être consultés dans l’image ci-dessous. Tout simplement incroyable !

Analyse qualitative de la coopération multimodale des modes vidéo et audio
Comment fonctionne HuggingGPT ?
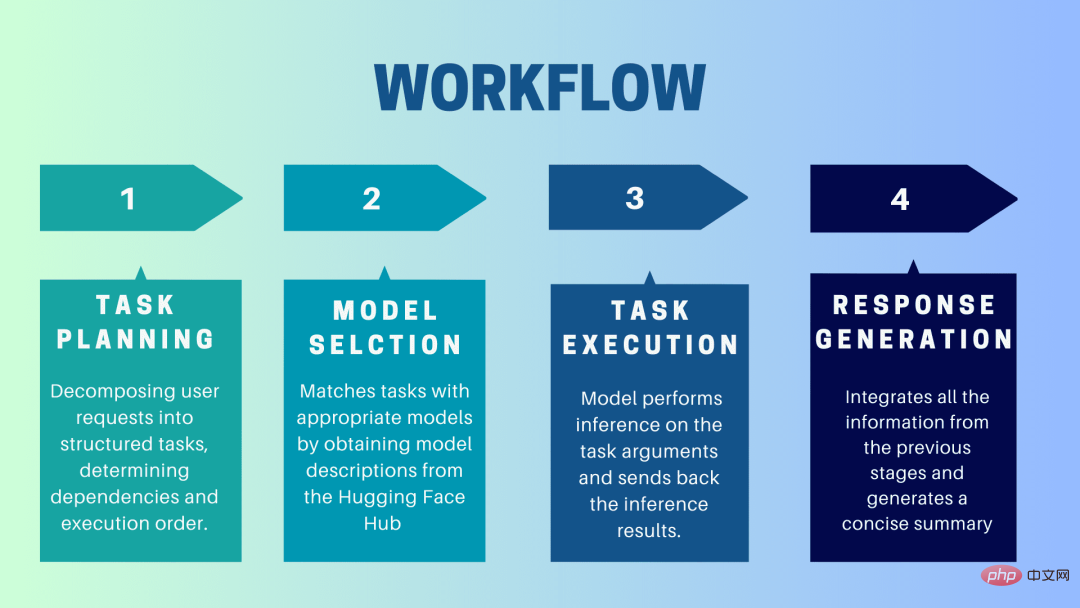
HuggingGPT est un système de collaboration qui utilise LLM comme interface pour envoyer les demandes des utilisateurs à des modèles experts. Le processus complet, de l'invite de l'utilisateur à la modélisation jusqu'à la réception de la réponse, peut être décomposé en les étapes discrètes suivantes :
1. Planification des tâches
Dans cette étape, HuggingGPT utilise ChatGPT pour comprendre l'invite de l'utilisateur, puis décompose la requête en petites requêtes gérables. Tâches opérationnelles. Il identifie également les dépendances de ces tâches et définit l'ordre dans lequel elles sont exécutées. HuggingGPT dispose de quatre emplacements pour l'analyse des tâches, à savoir le type de tâche, l'ID de tâche, les dépendances de tâches et les paramètres de tâche. Les discussions entre HuggingGPT et l'utilisateur sont enregistrées et affichées sur l'écran affichant l'historique des ressources.
2. Sélection du modèle
En fonction de l'environnement utilisateur et des modèles disponibles, HuggingGPT utilise un mécanisme contextuel d'allocation de modèle de tâche pour sélectionner le modèle le plus approprié pour une tâche spécifique. Selon ce mécanisme, la sélection de modèles est considérée comme une question à choix multiples, qui filtre initialement les modèles en fonction du type de tâche. Ensuite, les modèles ont été classés en fonction du nombre de téléchargements, car cela est considéré comme une mesure fiable de la qualité du modèle. Les modèles Top-K sont sélectionnés sur la base de ce classement. K ici est juste une constante qui reflète le nombre de modèles, par exemple, s'il est réglé à 3, alors il sélectionnera les 3 modèles avec le plus de téléchargements.
3. Exécution de la tâche
Ici, la tâche est affectée à un modèle spécifique, qui effectue une inférence sur celle-ci et renvoie les résultats. Pour rendre ce processus plus efficace, HuggingGPT peut exécuter différents modèles simultanément, à condition qu'ils ne nécessitent pas les mêmes ressources. Par exemple, si vous êtes invité à générer des images de chats et de chiens, différents modèles peuvent être exécutés en parallèle pour effectuer cette tâche. Cependant, il arrive parfois qu'un modèle nécessite la même ressource, c'est pourquoi HuggingGPT conserve un attribut
4. Générer une réponse
La dernière étape consiste à générer une réponse à l'utilisateur. Premièrement, il intègre toutes les informations et résultats de raisonnement des étapes précédentes. Les informations sont présentées dans un format structuré. Par exemple, si l'invite consiste à détecter le nombre de lions dans une image, elle dessinera des cadres de délimitation appropriés avec des probabilités de détection. LLM (ChatGPT) prend ensuite ce format et le restitue dans un langage convivial.
SET HuggingGPT
HuggingGPT est construit sur l'architecture GPT-3.5 de pointe de Hugging Face, qui est un modèle de réseau neuronal profond capable de générer du texte en langage naturel. Voici les étapes à suivre pour le configurer sur votre ordinateur local :
Configuration système requise
La configuration par défaut nécessite Ubuntu 16.04 LTS, au moins 24 Go de VRAM, au moins 12 Go (minimum), 16 Go (standard) ou 80 Go (complet) de RAM et au moins 284 Go d'espace disque. De plus, 42 Go d'espace sont requis pour damo-vilab/text-to-video-ms-1.7b, 126 Go pour ControlNet, 66 Go pour stable-diffusion-v1-5 et 50 Go pour les autres ressources. Pour une configuration « allégée », seul Ubuntu 16.04 LTS est requis.
Étapes pour commencer
Tout d'abord, remplacez la clé OpenAI et le jeton Hugging Face dans le fichier server/configs/config.default.yaml par vos clés. Ou bien, vous pouvez les mettre respectivement dans les variables d'environnement OPENAI_API_KEY et HUGGINGFACE_ACCESS_TOKEN
Exécutez la commande suivante :
Pour le serveur :
- Configurez un environnement Python et installez les dépendances requises.
<code># 设置环境cd serverconda create -n jarvis pythnotallow=3.8conda activate jarvisconda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidiapip install -r requirements.txt</code>
- Téléchargez le modèle requis.
<code># 下载模型。确保`git-lfs`已经安装。cd modelsbash download.sh # required when `inference_mode` is `local` or `hybrid`.</code>
- Running Server
<code># 运行服务器cd ..python models_server.py --config configs/config.default.yaml # required when `inference_mode` is `local` or `hybrid`python awesome_chat.py --config configs/config.default.yaml --mode server # for text-davinci-003</code>
Vous pouvez désormais accéder aux services de Jarvis en envoyant des requêtes HTTP au point de terminaison de l'API Web. Envoyez une demande au point de terminaison :
- /hugginggpt, en utilisant la méthode POST pour accéder au service complet.
- /tasks endpoint, utilisez la méthode POST pour accéder aux résultats intermédiaires de l'étape 1.
- /results endpoint, utilisez la méthode POST pour accéder aux résultats intermédiaires des étapes 1 à 3.
Ces requêtes doivent être au format JSON et doivent inclure une liste d'informations saisies au nom de l'utilisateur.
Pour le Web :
- Après avoir lancé l'application Awesome_chat.py en mode serveur, installez node js et npm sur votre ordinateur.
- Accédez au répertoire Web et installez les dépendances suivantes :
<code>cd webnpm installnpm run dev</code>
- Définissez http://{LAN_IP_of_the_server}:{port}/ sur HUGGINGGPT_BASE_URL pour web/src/config/index.ts au cas où vous exécutez le client Web sur une autre machine.
- Si vous souhaitez utiliser la fonction de génération vidéo, veuillez compiler ffmpeg manuellement en utilisant H.264.
<code># 可选:安装 ffmpeg# 这个命令需要在没有错误的情况下执行。LD_LIBRARY_PATH=/usr/local/lib /usr/local/bin/ffmpeg -i input.mp4 -vcodec libx264 output.mp4</code>
- Double-cliquez sur l'icône des paramètres pour revenir à ChatGPT.
Pour CLI :
La configuration de Jarvis à l'aide de la CLI est très simple. Exécutez simplement la commande mentionnée ci-dessous :
<code>cd serverpython awesome_chat.py --config configs/config.default.yaml --mode cli</code>
Pour Gradio :
La démo de Gradio est également hébergée sur Hugging Face Space. Vous pouvez expérimenter après avoir entré OPENAI_API_KEY et HUGGINGFACE_ACCESS_TOKEN.
Pour l'exécuter localement :
- Installez les dépendances requises, clonez le référentiel du projet depuis Hugging Face Space et accédez au répertoire du projet #🎜🎜 ## 🎜🎜# Démarrez le serveur de modèles puis lancez la démo Gradio en utilisant la commande suivante :
<code>python models_server.py --config configs/config.gradio.yamlpython run_gradio_demo.py --config configs/config.gradio.yaml</code>
- En option, vous pouvez également exécuter la démo en tant qu'image Docker en exécutant la commande suivante :
<code>docker run -it -p 7860:7860 --platform=linux/amd64 registry.hf.space/microsoft-hugginggpt:latest python app.py</code>
REMARQUE : Si Si Si vous avez des questions, veuillez vous référer au dépôt officiel Github (https://github.com/microsoft/JARVIS).
Final Thoughts
HuggingGPT présente également certaines limites qui doivent être soulignées ici. Par exemple, l'efficacité du système constitue un goulot d'étranglement majeur et HuggingGPT nécessite de multiples interactions avec LLM à toutes les étapes mentionnées précédemment. Ces interactions peuvent entraîner une expérience utilisateur dégradée et une latence accrue. De même, la longueur maximale du contexte est limitée par le nombre de jetons autorisés. Un autre problème est la fiabilité du système, car LLM peut mal interpréter les invites et produire une mauvaise séquence de tâches, ce qui affecte l'ensemble du processus. Néanmoins, il présente un grand potentiel pour résoudre des tâches d’IA complexes et constitue une bonne avancée pour l’AGI. Attendons avec impatience la direction que prendront ces recherches pour l’avenir de l’IA !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI