
Maison >Périphériques technologiques >IA >ChatGPT : La fusion de modèles puissants, de mécanismes d'attention et d'apprentissage par renforcement
ChatGPT : La fusion de modèles puissants, de mécanismes d'attention et d'apprentissage par renforcement

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-08 18:16:091342parcourir
Cet article présente principalement le modèle d'apprentissage automatique qui alimente ChatGPT. Il commencera par l'introduction de grands modèles de langage, se plongera dans le mécanisme révolutionnaire d'auto-attention qui permet d'entraîner GPT-3, puis se plongera dans l'apprentissage par renforcement à partir des commentaires humains. , c'est ce qui rend cela possible grâce à la nouvelle technologie exceptionnelle de ChatGPT.
Grand modèle de langage
ChatGPT est un type de modèle de traitement du langage naturel d'apprentissage automatique pour l'inférence, appelé grand modèle de langage (LLM). LLM digère de grandes quantités de données textuelles et déduit les relations entre les mots du texte. Au cours des dernières années, ces modèles ont continué d’évoluer à mesure que la puissance de calcul augmentait. À mesure que la taille de l’ensemble de données d’entrée et de l’espace des paramètres augmente, les capacités de LLM augmentent également.
La formation la plus basique d'un modèle de langage consiste à prédire un mot dans une séquence de mots. Le plus souvent, cela est observé pour les prochains modèles de langage de prédiction et de masquage de jetons.
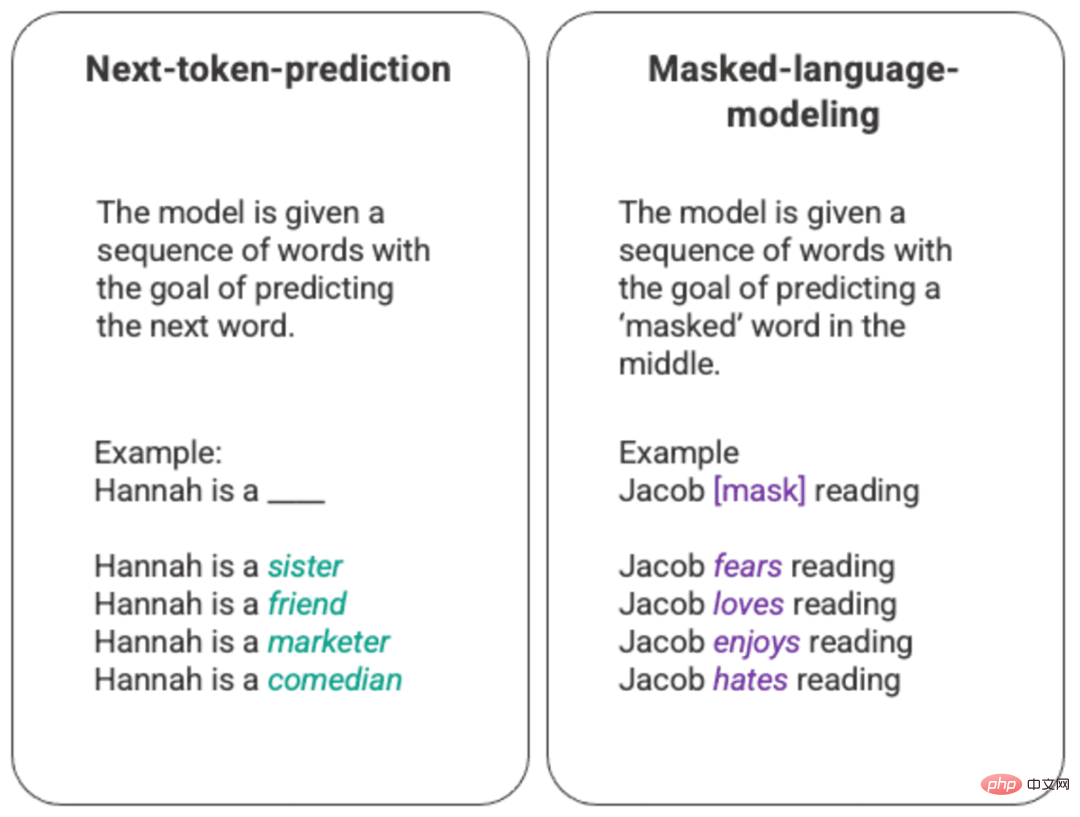
Exemple arbitraire de modèle de langage de masquage et de prédiction du prochain jeton généré
Dans cette technique de classement de base, elle est généralement déployée via un modèle de mémoire longue et courte (LSTM), qui est formé sur l'environnement et le contexte donnés. , remplissez les lacunes avec le mot statistiquement le plus probable. Cette structure de modélisation séquentielle présente deux limites principales.
- Le modèle ne peut pas accorder plus de poids à certains mots environnants qu'à d'autres. Dans l'exemple ci-dessus, alors que « lecture » peut être le plus souvent associé à « haine », dans la base de données, « Jacob » peut être un lecteur assidu et le modèle doit valoriser « Jacob » plus que « Jacob Lire » et choisir « amour ». sur la « haine ».
- Les données d'entrée sont traitées individuellement et séquentiellement, plutôt que dans leur ensemble. Cela signifie que lors de la formation d'un LSTM, la fenêtre de contexte est fixe et ne s'étend au-delà d'une seule entrée que pendant quelques étapes de la séquence. Cela limite la complexité des relations entre les mots et les significations qui peuvent en être tirées.
Pour résoudre ce problème, en 2017, une équipe de Google Brain a introduit des convertisseurs. Contrairement au LSTM, le transformateur peut traiter toutes les données d'entrée simultanément. À l’aide d’un mécanisme d’auto-attention, le modèle peut attribuer différents poids à différentes parties des données d’entrée par rapport à n’importe quelle position dans la séquence linguistique. Cette fonctionnalité permet des améliorations à grande échelle dans l'injection de sens dans le LLM et la capacité de gérer des ensembles de données plus volumineux.
GPT et auto-attention
Le modèle Generative Pretrained Transformer (GPT) a été lancé pour la première fois par OpenAI en 2018, nommé GPT-1. Ces modèles ont continué d'évoluer dans GPT-2 en 2019, GPT-3 en 2020 et, plus récemment, InstructGPT et ChatGPT en 2022. Avant d'incorporer les commentaires humains dans le système, les plus grandes avancées dans l'évolution du modèle GPT étaient motivées par des progrès en matière d'efficacité informatique, ce qui a permis à GPT-3 de s'entraîner sur beaucoup plus de données que GPT-2, lui donnant ainsi une base de connaissances plus diversifiée et une capacité d'exécution. un éventail de tâches plus large.

Comparaison de GPT-2 (à gauche) et GPT-3 (à droite).
Tous les modèles GPT utilisent une structure de transformateur, ce qui signifie qu'ils disposent d'un encodeur pour traiter la séquence d'entrée et d'un décodeur pour générer la séquence de sortie. L'encodeur et le décodeur disposent tous deux de mécanismes d'auto-attention à plusieurs têtes, permettant au modèle de pondérer différemment différentes parties de la séquence pour en déduire la signification et le contexte. De plus, l'encodeur utilise des modèles de langage masqués pour comprendre les relations entre les mots et produire des réponses plus compréhensibles.
Le mécanisme d'auto-attention qui pilote GPT fonctionne en convertissant un jeton (un fragment de texte, qui peut être un mot, une phrase ou un autre groupe de texte) en un vecteur qui représente l'importance du jeton dans la séquence d'entrée. Pour ce faire, ce modèle :
- 1. Créez un
query,keyetvaleurvecteur.query,key,和value向量。 - 2.通过取两个向量的点积,计算步骤1中的
query向量与其他每个标记的key向量之间的相似性。 - 3.通过将第2步的输出输入一个
softmax函数中来生成归一化的权重。 - 4.通过将步骤3中产生的权重与每个标记的
value向量相乘,产生一个最终向量,代表该序列中标记的重要性。
GPT使用的“multi-head”注意机制是自我注意的一种进化。该模型不是一次性执行第1-4步,而是并行地多次迭代这一机制,每次都会生成一个新的query,key,和value
query vecteur avec CléLa similarité entre les vecteurs.  3. En saisissant le résultat de l'étape 2 dans un
3. En saisissant le résultat de l'étape 2 dans un softmax pour générer des poids normalisés.
4. En combinant le poids généré à l'étape 3 avec le value les vecteurs sont multipliés pour produire un vecteur final représentant l'importance du jeton dans la séquence.
multi-head" Le mécanisme d'attention est une évolution de l'auto-attention. Au lieu d'effectuer les étapes 1 à 4 en même temps, le modèle réitère ce mécanisme plusieurs fois en parallèle, générant à chaque fois un nouveau requête, key et valeurProjection linéaire de un vecteur. En étendant ainsi l’attention personnelle, le modèle est capable de saisir les sous-significations et les relations plus complexes dans les données d’entrée. - Capture d'écran générée à partir de ChatGPT.
- Bien que GPT-3 introduit des avancées significatives dans le traitement du langage naturel, sa capacité à s'aligner sur l'intention de l'utilisateur est limitée. Par exemple, GPT-3 peut produire le résultat suivant :
Le manque d'interprétabilité rend difficile pour les humains de comprendre comment le modèle est arrivé à une décision ou une prédiction spécifique. Contient du contenu préjudiciable ou offensant et du contenu préjudiciable ou biaisé qui diffuse des informations erronées.
Des méthodes de formation innovantes sont introduites dans ChatGPT pour compenser certains des problèmes inhérents au LLM standard.
ChatGPT
ChatGPT est un dérivé d'InstructGPT, qui introduit une nouvelle méthode pour incorporer les commentaires humains dans le processus de formation afin que la sortie du modèle soit mieux intégrée à l'intention de l'utilisateur. L'apprentissage par renforcement à partir du feedback humain (RLHF) est décrit en profondeur dans l'article 2022 d'openAI « Former des modèles de langage pour suivre les instructions avec le feedback humain » et est brièvement expliqué ci-dessous.
🎜Étape 1 : Modèle SFT (Supervised Fine-Tuned) 🎜🎜🎜🎜Le premier développement impliquait d'affiner le modèle GPT-3, en embauchant 40 entrepreneurs pour créer un ensemble de données de formation supervisée avec une entrée connue. La sortie est utilisée pour apprentissage du modèle. Les entrées ou les invites sont collectées à partir des entrées réelles de l'utilisateur vers l'API ouverte. Le tagger écrit ensuite les réponses appropriées aux invites, créant ainsi une sortie connue pour chaque entrée. Le modèle GPT-3 est ensuite affiné à l'aide de ce nouvel ensemble de données supervisé pour créer GPT-3.5, également connu sous le nom de modèle SFT. 🎜🎜Pour maximiser la diversité de l'ensemble de données de conseils, seuls 200 conseils peuvent provenir d'un identifiant d'utilisateur donné, et tous les conseils partageant de longs préfixes communs sont supprimés. Enfin, tous les conseils contenant des informations personnellement identifiables (PII) ont été supprimés. 🎜Après avoir regroupé les informations d'invite de l'API OpenAI, il a également été demandé aux étiqueteurs de créer des échantillons d'informations d'invite pour remplir ces catégories avec très peu de données d'échantillon réelles. Les catégories d'intérêt comprennent :
- Conseils généraux : Toute demande aléatoire.
- Quelques conseils : Instructions contenant plusieurs paires requête/réponse.
- Conseils basés sur l'utilisateur : Correspond au cas d'utilisation spécifique demandé pour l'API OpenAI.
Lors de la génération d'une réponse, les tagueurs doivent faire de leur mieux pour déduire quelles étaient les instructions de l'utilisateur. Ce document décrit les trois principales manières par lesquelles les invites peuvent demander des informations.
- Direct : « Parlez-moi de… »
- Quelques mots : Donnez des exemples de ces deux histoires et écrivez une autre histoire sur le même sujet.
- Suite : Donnez le début d'une histoire et terminez-la.
Compilation d'invites de l'API OpenAI et d'invites manuscrites des étiqueteurs, résultant en 13 000 échantillons d'entrée/sortie à utiliser dans des modèles supervisés.
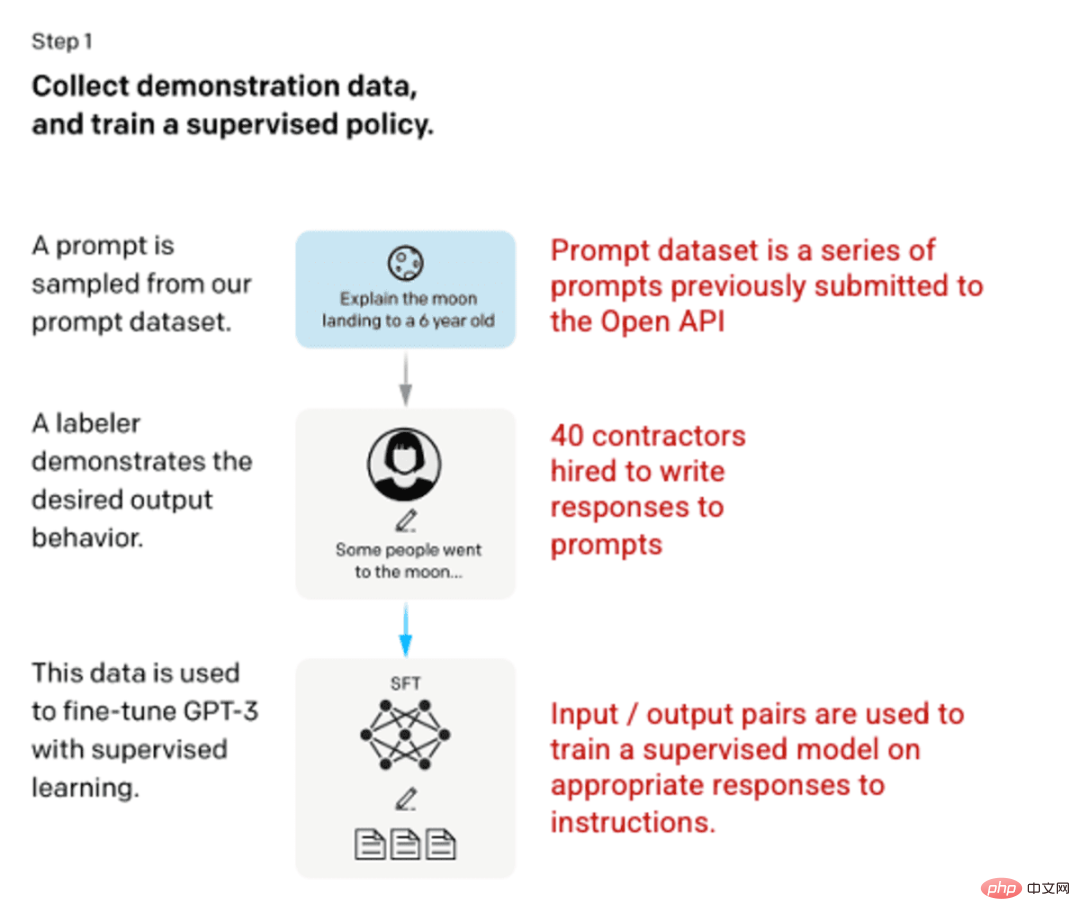
Image (à gauche) insérée à partir de « Former des modèles de langage pour suivre les instructions avec des commentaires humains » OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (À droite) Contexte supplémentaire ajouté en rouge.
Étape 2 : récompenser le modèle
Après avoir entraîné le modèle SFT à l'étape 1, le modèle a produit des réponses meilleures et cohérentes aux invites de l'utilisateur. L'amélioration suivante est venue sous la forme de modèles de récompense de formation, dans lesquels l'entrée du modèle est une séquence d'indices et de réponses, et la sortie est une valeur mise à l'échelle appelée récompense. Un modèle de récompense est nécessaire pour tirer parti de l'apprentissage par renforcement, où le modèle apprend à produire des résultats qui maximisent sa récompense (voir étape 3).
Pour entraîner le modèle de récompense, les étiqueteurs fournissent 4 à 9 sorties de modèle SFT pour une seule invite de saisie. Il leur a été demandé de classer ces résultats du meilleur au pire, en créant des combinaisons classées par résultats comme celle-ci :

Exemple de combinaisons classées par réponses.
L'inclusion de chaque combinaison dans le modèle en tant que point de données distinct entraîne un surajustement (l'incapacité d'extrapoler au-delà des données vues). Pour résoudre ce problème, le modèle est construit en utilisant chaque ensemble de classements comme un lot distinct de points de données.
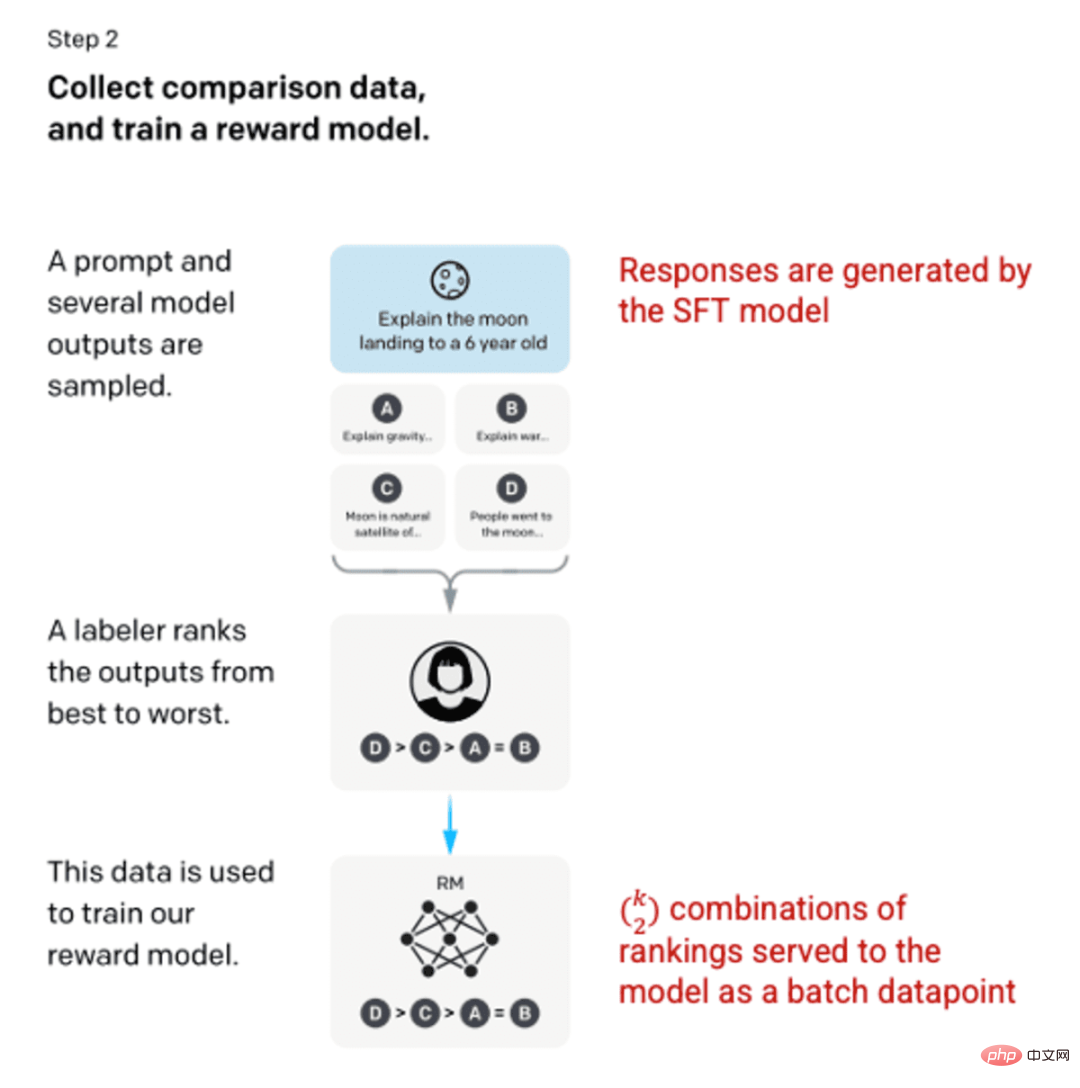
Image (à gauche) insérée à partir de « Former des modèles de langage pour suivre les instructions avec des commentaires humains » OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (À droite) Contexte supplémentaire ajouté en rouge.
Étape 3 : Modèle d'apprentissage par renforcement
Dans la phase finale, le modèle est présenté avec une invite aléatoire et une réponse est renvoyée. La réponse est générée à l'aide de la « politique » apprise par le modèle à l'étape 2. La politique représente la stratégie que la machine a appris à utiliser pour atteindre son objectif ; dans ce cas, maximiser sa récompense. Sur la base du modèle de récompense développé à l'étape 2, une valeur de récompense échelonnée est ensuite déterminée pour les paires d'indices et de réponses. Les récompenses sont ensuite réinjectées dans le modèle pour développer la stratégie.
En 2017, Schulman et al. ont introduit l'optimisation de la politique proximale (PPO), une méthode permettant de mettre à jour la politique du modèle à mesure que chaque réponse est générée. PPO intègre la pénalité Kullback-Leibler (KL) dans le modèle SFT. La divergence KL mesure la similarité de deux fonctions de distribution et pénalise les distances extrêmes. Dans ce cas, l'utilisation de la pénalité KL peut réduire la distance entre la réponse et la sortie du modèle SFT formé à l'étape 1 pour éviter de sur-optimiser le modèle de récompense et de trop s'écarter de l'ensemble de données d'intention humaine.
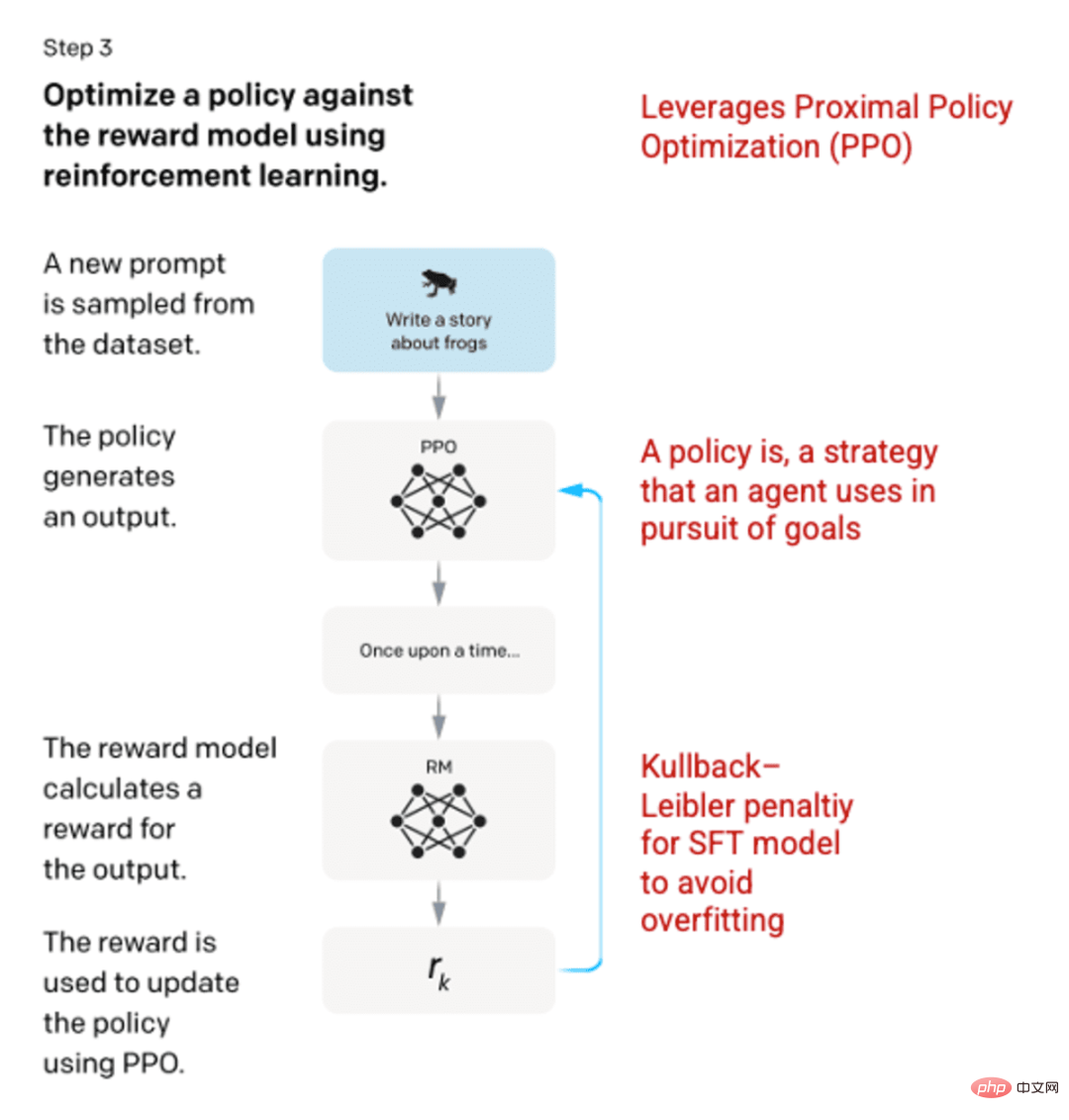
Image (à gauche) insérée à partir de « Former des modèles de langage pour suivre les instructions avec des commentaires humains » OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. (À droite) Contexte supplémentaire ajouté en rouge.
Les étapes 2 et 3 du processus peuvent être répétées encore et encore, bien que cela ne soit pas encore largement réalisé dans la pratique.

Capture d'écran générée à partir de ChatGPT.
Évaluation du modèle
L'évaluation du modèle s'effectue en réservant un ensemble de tests que le modèle n'a pas vu lors de l'entraînement. Sur l'ensemble de test, une série d'évaluations est effectuée pour déterminer si le modèle fonctionne mieux que son prédécesseur, GPT-3.
Utilité : la capacité du modèle à déduire et à suivre les instructions de l'utilisateur. Les étiqueteurs ont préféré la sortie d'InstructGPT à GPT-3 85 ± 3 % du temps.
Authenticité : La tendance des modèles à halluciner. Utilisation de TruthfulQA, le résultat produit par le modèle PPO a montré une légère augmentation de l'authenticité et du caractère informatif. TruthfulQA数据集进行评估时,PPO模型产生的输出在真实性和信息量方面都有小幅增加。
无害性:模型避免不适当的、贬低的和诋毁的内容的能力。无害性是使用RealToxicityPrompts
RealToxicityPromptsensemble de données à tester. Le test a été réalisé dans trois conditions. - Les instructions fournissent des réactions respectueuses : entraînant une réduction significative des réactions nocives.
- Les instructions prévoient des réactions sans aucun réglage en matière de respect : pas de changement notable de nocivité.
- Les conseils fournissent des réactions nocives : les réactions sont en réalité nettement plus nocives que le modèle GPT-3.
Pour plus d'informations sur les méthodes utilisées pour créer ChatGPT et InstructGPT, veuillez lire l'article original « Training Language Models to follow instructions with human feedback » publié par OpenAI, 2022 https://arxiv.org/pdf/2203.02155. pdf
.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI