
Maison >développement back-end >Tutoriel Python >Comment Python traite-t-il les fichiers Excel ?
Comment Python traite-t-il les fichiers Excel ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-08 17:58:152006parcourir
『Description du problème』
Le fichier Excel à traiter cette fois comporte deux feuilles et la valeur de l'autre feuille doit être calculée en fonction des données d'une feuille. Le problème est que la feuille à calculer contient non seulement des valeurs numériques, mais aussi des formules. Jetons un coup d'oeil :
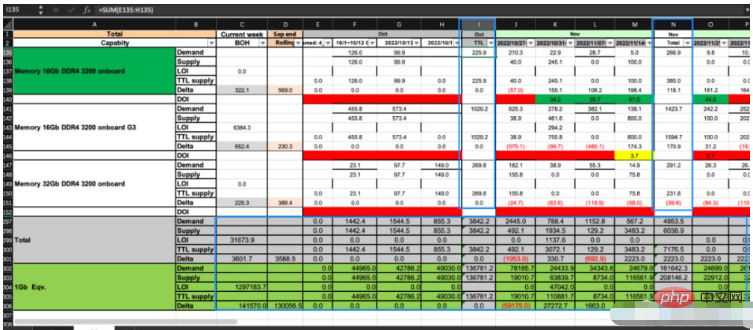
Comme le montre l'image ci-dessus, cet Excel comporte deux feuilles : CP et DS Nous devons suivre certaines règles commerciales et calculer les données des cellules correspondant à DS en fonction des données de CP. . Les cases bleues de l'image contiennent des formules, tandis que d'autres zones contiennent des valeurs numériques.
Jetons un coup d'œil, si nous suivons la logique de traitement mentionnée précédemment, lisons Excel dans le dataframe par lots à la fois, puis le réécrivons par lots à la fois, quels sont les problèmes ? Cette partie du code est la suivante :
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()Le problème avec le code ci-dessus est que lorsque la méthode pd.read_excel() lit les données d'Excel dans le dataframe, pour les cellules avec des formules, les résultats des calculs de formule seront lus directement (sinon, le résultat est renvoyé sous la forme Nan), et lorsque nous écrivons dans Excel, nous réécrivons directement la trame de données par lots à la fois, de sorte que les cellules avec les formules précédentes soient réécrites avec la valeur calculée ou Nan, et la formule est perdu.
D'accord, un problème est survenu, comment devons-nous le résoudre ? Deux idées me viennent à l'esprit ici :
Lors de la réécriture du dataframe dans Excel, ne le réécrivez pas par lots à la fois, mais réécrivez uniquement les données calculées par itération de lignes et de colonnes, en laissant les cellules avec les formules inchangées ;
- Lors de la lecture d'Excel, existe-t-il un moyen de lire la formule des cellules contenant des formules au lieu de lire les résultats des calculs de formule
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")Le code ci-dessus résout en effet le problème, c'est-à-dire les formules pour les cellules avec. Les formules ont été conservées. Cependant, selon les conseils sur le traitement Python d'Excel mentionnés au début de notre article, ce code présente de sérieux problèmes de performances, car il exploite fréquemment les cellules Excel via l'API, ce qui entraîne une écriture très lente. 40 minutes, ce qui était tout simplement inacceptable, le plan a donc dû être abandonné. 「Option 2」Cette idée est de conserver la valeur de la formule lors de la lecture de cellules avec des valeurs de formule dans Excel. Cela ne peut être trouvé qu'à partir de l'API de chaque bibliothèque Python Excel pour voir s'il existe une méthode correspondante. J'ai regardé attentivement la méthode read_excel() de Pandas et il n'y a pas de support de paramètre correspondant. J'ai trouvé une API qui peut prendre en charge Openpyxl, comme suit : import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)La clé est le paramètre data_only ici. S'il est vrai, les données seront renvoyées. S'il est faux, la valeur de la formule peut être conservée . J'ai trouvé la solution correspondante. C'était une bonne affaire. Salut, mais quand j'ai vu la structure des données dans la trame de données lue via openpyxl, j'ai été choqué. Parce que l'en-tête de mon tableau Excel est un en-tête à deux niveaux relativement complexe, et qu'il existe des situations où les cellules sont fusionnées et divisées dans l'en-tête, une fois qu'un tel en-tête est lu dans le dataframe par openpyxl, il ne suit pas le multi-niveau. en-tête des pandas. L'index est traité, mais il est simplement transformé en un index numérique 0123...Mais mon calcul de la trame de données reposera sur une indexation multi-niveaux, donc cette méthode de traitement d'openpyxl rend mes calculs ultérieurs incapables. processus. openpyxl ne fonctionne pas, qu'en est-il de xlwings ? Après avoir parcouru la documentation de l'API xlwings, je l'ai trouvée, comme indiqué ci-dessous :
#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulasMais j'ai mal pensé ds_worksheet.used_range.formula m'a fait mal comprendre que la formule ne renverrait que les cellules avec des formules. dans Excel, mais en fait il renvoie toutes les cellules, seules les formules sont conservées pour les cellules avec des formules. Ainsi, lorsque je réécrirai la formule, elle écrasera les autres valeurs que j'ai calculées via le dataframe et écrites dans Excel. Si tel est le cas, alors je ne peux traiter les cellules avec les formules que séparément au lieu de les traiter toutes en même temps, donc le code doit être écrit comme ceci :
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()Après test, le code ci-dessus répond parfaitement à mes besoins, et les performances sont également bonnes. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!