
Maison >Java >javaDidacticiel >Analyser des exemples d'opérations de terminal dans l'API Java Stream
Analyser des exemples d'opérations de terminal dans l'API Java Stream

- 王林avant
- 2023-05-08 17:34:17985parcourir
1. Opération de traitement des données du pipeline Java Stream
Dans l'article que j'ai écrit avant ce numéro, je vous ai présenté un jour que le flux de pipeline Java Stream est une API Java utilisée pour simplifier le traitement des éléments de classe de collection. Le processus d'utilisation est divisé en trois étapes. Avant de commencer cet article, je pense que je dois encore présenter ces trois étapes à de nouveaux amis, comme le montre l'image :
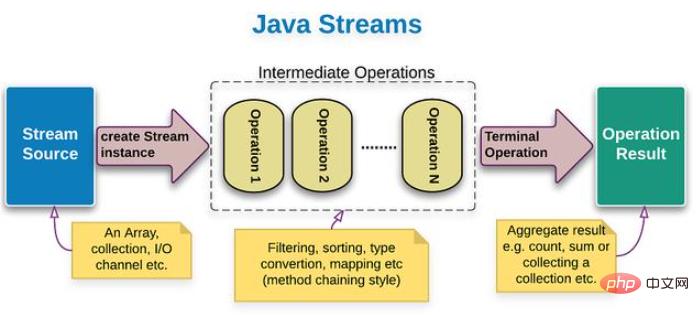
La première étape (en bleu sur l'image) : Convertir des collections, des tableaux ou des lignes fichiers texte La deuxième étape du flux du pipeline Java Stream
(la partie en pointillé de la figure) : opération de traitement des données de streaming du pipeline, traitant chaque élément du pipeline. Les éléments de sortie du canal précédent servent d’éléments d’entrée pour le canal suivant.
La troisième étape (en vert sur l'image) : l'opération de traitement des résultats du flux du pipeline, qui est le contenu principal de cet article.
Avant de commencer à apprendre, il est encore nécessaire de revoir un exemple que nous vous avons dit précédemment :
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);Utilisez d'abord la méthode stream() pour convertir la chaîne List en un flux pipeline Stream
Ensuite, effectuez les opérations de traitement des données du pipeline , utilisez d'abord la fonction de filtrage pour filtrer toutes les chaînes commençant par un L majuscule, puis convertissez les chaînes du pipeline en lettres majuscules en UpperCase, puis appelez la méthode sorted pour trier. L'utilisation de ces API a été présentée dans les articles précédents de cet article. Des expressions Lambda et des références de fonctions sont également utilisées.
Enfin, utilisez la fonction de collecte pour le traitement des résultats afin de convertir le flux du pipeline Java Stream en une liste. Le résultat final de la liste est : [LEMUR, LION][LEMUR, LION]
如果你不使用java Stream管道流的话,想一想你需要多少行代码完成上面的功能呢?回到正题,这篇文章就是要给大家介绍第三阶段:对管道流处理结果都可以做哪些操作呢?下面开始吧!
二、ForEach和ForEachOrdered
如果我们只是希望将Stream管道流的处理结果打印出来,而不是进行类型转换,我们就可以使用forEach()方法或forEachOrdered()方法。
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEach(System.out::println);
Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.parallel()
.forEachOrdered(System.out::println);parallel()函数表示对管道中的元素进行并行处理,而不是串行处理,这样处理速度更快。但是这样就有可能导致管道流中后面的元素先处理,前面的元素后处理,也就是元素的顺序无法保证
forEachOrdered从名字上看就可以理解,虽然在数据处理顺序上可能无法保障,但是forEachOrdered方法可以在元素输出的顺序上保证与元素进入管道流的顺序一致。也就是下面的样子(forEach方法则无法保证这个顺序):
Monkey
Lion
Giraffe
Lemur
Lion
三、元素的收集collect
java Stream 最常见的用法就是:一将集合类转换成管道流,二对管道流数据处理,三将管道流处理结果在转换成集合类。那么collect()方法就为我们提供了这样的功能:将管道流处理结果在转换成集合类。
3.1.收集为Set
通过Collectors.toSet()方法收集Stream的处理结果,将所有元素收集到Set集合中。
Set<String> collectToSet = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .collect(Collectors.toSet()); //最终collectToSet 中的元素是:[Monkey, Lion, Giraffe, Lemur],注意Set会去重。
3.2.收集到List
同样,可以将元素收集到List使用toList()收集器中。
List<String> collectToList = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toList()); // 最终collectToList中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.3.通用的收集方式
上面为大家介绍的元素收集方式,都是专用的。比如使用Collectors.toSet()收集为Set类型集合;使用Collectors.toList()收集为List类型集合。那么,有没有一种比较通用的数据元素收集方式,将数据收集为任意的Collection接口子类型。 所以,这里就像大家介绍一种通用的元素收集方式,你可以将数据元素收集到任意的Collection类型:即向所需Collection类型提供构造函数的方式。
LinkedList<String> collectToCollection = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ).collect(Collectors.toCollection(LinkedList::new)); //最终collectToCollection中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
注意:代码中使用了LinkedList::new,实际是调用LinkedList的构造函数,将元素收集到Linked List。当然你还可以使用诸如LinkedHashSet::new和PriorityQueue::new将数据元素收集为其他的集合类型,这样就比较通用了。
3.4.收集到Array
通过toArray(String[]::new)方法收集Stream的处理结果,将所有元素收集到字符串数组中。
String[] toArray = Stream.of( "Monkey", "Lion", "Giraffe", "Lemur", "Lion" ) .toArray(String[]::new); //最终toArray字符串数组中的元素是: [Monkey, Lion, Giraffe, Lemur, Lion]
3.5.收集到Map
使用Collectors.toMap()方法将数据元素收集到Map里面,但是出现一个问题:那就是管道中的元素是作为key,还是作为value。我们用到了一个Function.identity()方法,该方法很简单就是返回一个“ t -> t ”(输入就是输出的lambda表达式)。另外使用管道流处理函数distinct()
Map<String, Integer> toMap = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.distinct()
.collect(Collectors.toMap(
Function.identity(), //元素输入就是输出,作为key
s -> (int) s.chars().distinct().count()// 输入元素的不同的字母个数,作为value
));
// 最终toMap的结果是: {Monkey=6, Lion=4, Lemur=5, Giraffe=6}🎜parallel() indique que les éléments du pipeline sont traités en parallèle plutôt qu'en série, de sorte que la vitesse de traitement soit plus rapide. Cependant, cela peut entraîner le traitement des éléments ultérieurs du flux du pipeline en premier et le traitement des éléments précédents plus tard, c'est-à-dire que l'ordre des éléments ne peut pas être garanti🎜🎜forEachOrdered peut être compris à partir du nom, bien que les données L'ordre de traitement peut ne pas être garanti, mais la méthode forEachOrdered peut garantir que l'ordre dans lequel les éléments sont sortis est cohérent avec l'ordre dans lequel les éléments entrent dans le flux du pipeline. Voilà à quoi cela ressemble ci-dessous (la méthode forEach ne peut garantir cet ordre) : 🎜🎜Singe🎜Trois elements L'utilisation la plus courante de collect🎜🎜java Stream est la suivante : premièrement, convertir la classe de collection en un flux de pipeline, deuxièmement, traiter les données du flux de pipeline et troisièmement, convertir le résultat du traitement du flux de pipeline en une classe de collection. Ensuite, la méthode collect() nous fournit la fonction de convertir les résultats du traitement du flux du pipeline en une classe de collection. 🎜🎜3.1. Collect as Set🎜🎜Collectez les résultats du traitement de Stream via la méthode Collectors.toSet() et collectez tous les éléments dans la collection Set. 🎜
Lion
Girafe
Lémurien
Lion🎜
Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}🎜3.2. Collecter dans la liste🎜🎜De même, les éléments peuvent être collectés dans List à l'aide du collecteur toList(). 🎜boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}🎜3.3. Méthodes de collecte universelles🎜🎜Les méthodes de collecte d'éléments présentées ci-dessus sont toutes dédiées. Par exemple, utilisez Collectors.toSet() pour collecter une collection de type Set ; utilisez Collectors.toList() pour collecter une collection de type List. Alors, existe-t-il un moyen plus général de collecter des éléments de données pour collecter des données dans n'importe quel sous-type d'interface de collection ? Par conséquent, voici une manière générale de collecter des éléments. Vous pouvez collecter des éléments de données dans n'importe quel type Collection : c'est-à-dire en fournissant un constructeur au type Collection requis. 🎜rrreee🎜Remarque : LinkedList::new est utilisé dans le code, qui appelle en fait le constructeur de LinkedList pour collecter des éléments dans Linked List. Bien sûr, vous pouvez également utiliser des méthodes telles que LinkedHashSet::new et PriorityQueue::new pour collecter des éléments de données dans d'autres types de collections, ce qui est plus polyvalent. 🎜🎜3.4. Collecter dans Array🎜🎜Collectez les résultats du traitement du Stream via la méthode toArray(String[]::new) et collectez tous les éléments dans un tableau de chaînes. 🎜rrreee🎜3.5. Collecter sur la carte🎜🎜Utilisez la méthode Collectors.toMap() pour collecter des éléments de données dans la carte, mais il y a un problème : si les éléments du pipeline sont utilisés comme clés ou comme valeurs. Nous avons utilisé une méthode Function.identity(), qui renvoie simplement un "t -> t" (l'entrée est l'expression lambda de la sortie). De plus, utilisez la fonction de traitement de flux de pipeline distinct() pour garantir l'unicité de la valeur de la clé Map. 🎜rrreee🎜3.6. GroupingBy🎜🎜Collectors.groupingBy est utilisé pour implémenter un regroupement d'éléments. Le code suivant montre comment collecter différents éléments de données dans différentes listes en fonction de leurs premières lettres et les encapsuler sous forme de cartes. 🎜Map<Character, List<String>> groupingByList = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur", "Lion"
)
.collect(Collectors.groupingBy(
s -> s.charAt(0) , //根据元素首字母分组,相同的在一组
// counting() // 加上这一行代码可以实现分组统计
));
// 最终groupingByList内的元素: {G=[Giraffe], L=[Lion, Lemur, Lion], M=[Monkey]}
//如果加上counting() ,结果是: {G=1, L=3, M=1}这是该过程的说明:groupingBy第一个参数作为分组条件,第二个参数是子收集器。
四、其他常用方法
boolean containsTwo = IntStream.of(1, 2, 3).anyMatch(i -> i == 2);
// 判断管道中是否包含2,结果是: true
long nrOfAnimals = Stream.of(
"Monkey", "Lion", "Giraffe", "Lemur"
).count();
// 管道中元素数据总计结果nrOfAnimals: 4
int sum = IntStream.of(1, 2, 3).sum();
// 管道中元素数据累加结果sum: 6
OptionalDouble average = IntStream.of(1, 2, 3).average();
//管道中元素数据平均值average: OptionalDouble[2.0]
int max = IntStream.of(1, 2, 3).max().orElse(0);
//管道中元素数据最大值max: 3
IntSummaryStatistics statistics = IntStream.of(1, 2, 3).summaryStatistics();
// 全面的统计结果statistics: IntSummaryStatistics{count=3, sum=6, min=1, average=2.000000, max=3}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Pourquoi ne puis-je pas charger des images dans mon fichier JAR exporté depuis Eclipse ?
- Comment détecter l'orientation paysage ou portrait sous Android ?
- Pourquoi est-ce que je reçois une erreur « Aucun fournisseur de persistance pour EntityManager » ?
- Odeur de code – Alias de collection
- Collection Java à lister