
Maison >Périphériques technologiques >IA >Le modèle d'apprentissage multimodal non invasif développé par l'Institute of Automation réalise le décodage des signaux cérébraux et l'analyse sémantique
Le modèle d'apprentissage multimodal non invasif développé par l'Institute of Automation réalise le décodage des signaux cérébraux et l'analyse sémantique

- PHPzavant
- 2023-05-08 10:40:091419parcourir

- Adresse papier : https://ieeexplore.ieee.org/document/10089190
- Adresse code : https://github.com/ChangdeDu/BraVL
- Adresse des données : https://figshare.com/articles/dataset/BraVL/17024591
Trop long à lire
Cette étudeest la première à combiner les connaissances sur le cerveau, la vision et le langage, à travers de multiples La méthode d'apprentissage modal permet un décodage sans échantillon de nouvelles catégories visuelles à partir des enregistrements d'activité cérébrale humaine. Cet article fournit également trois ensembles de données de correspondance trimodale "cerveau-image-texte".
Les résultats expérimentaux indiquent des conclusions et des idées cognitives intéressantes : 1) le décodage de nouvelles catégories visuelles à partir de l'activité cérébrale humaine est réalisable avec une grande précision ; 2) le décodage en utilisant une combinaison de caractéristiques visuelles et linguistiques. Le modèle fonctionne mieux qu'un modèle utilisant uniquement l'un d'eux ; 3) La perception visuelle peut être accompagnée d'influences linguistiques pour représenter la sémantique des stimuli visuels. Ces découvertes mettent non seulement en lumière la compréhension du système visuel humain, mais fournissent également de nouvelles idées pour la future technologie d’interface cerveau-ordinateur. Le code et les ensembles de données de cette étude sont open source.
Contexte de recherche
Le décodage des représentations neuronales visuelles humaines est un défi d'importance scientifique importante qui peut révéler les mécanismes de traitement visuel et promouvoir le développement de la science du cerveau et de l'intelligence artificielle. Cependant, Les méthodes de décodage neuronal actuelles sont difficiles à généraliser à de nouvelles catégories au-delà des données d'entraînement Il y a deux raisons principales : la première est que les méthodes existantes n'utilisent pas pleinement les connaissances sémantiques multimodales derrière les données neuronales ; données d'entraînement d'appariement (stimulus-réponse cérébrale) disponibles.
La recherche montre que la perception humaine et la reconnaissance des stimuli visuels sont affectées par les caractéristiques visuelles et les expériences antérieures des gens. Par exemple, lorsque nous voyons un objet familier, notre cerveau récupère naturellement les connaissances liées à cet objet. Comme le montre la figure 1 ci-dessous, les recherches en neurosciences cognitives sur la théorie du double codage [9] estiment que des concepts spécifiques sont codés dans le cerveau à la fois visuellement et linguistiquement, où le langage, en tant qu'expérience préalable efficace, contribue à façonner les représentations générées par la vision.
Par conséquent, l'auteur estime que pour mieux décoder les signaux cérébraux enregistrés, il convient d'utiliser non seulement les caractéristiques sémantiques visuelles réellement présentées, mais également une combinaison de caractéristiques sémantiques linguistiques plus riches liées à l'objet visuel cible.
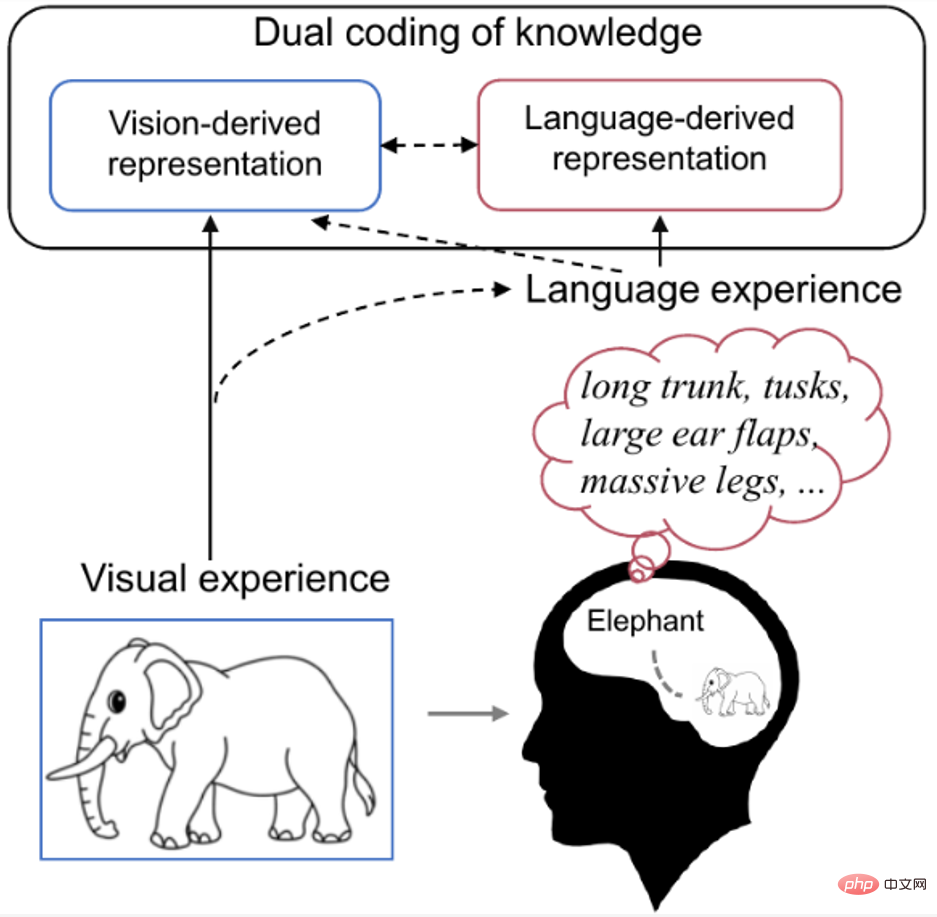
Figure 1. Double encodage des connaissances dans le cerveau humain. Lorsque nous voyons des photos d’éléphants, nous récupérons naturellement dans notre esprit des connaissances liées aux éléphants (telles que de longues trompes, de longues dents, de grandes oreilles, etc.). À ce stade, le concept d’éléphant est codé visuellement et verbalement dans le cerveau, le langage servant d’expérience préalable valide qui contribue à façonner la représentation produite par la vision.
Comme le montre la figure 2 ci-dessous, comme il est très coûteux de collecter les activités cérébrales humaines de diverses catégories visuelles, les chercheurs n'ont généralement que des activités cérébrales très limitées de catégories visuelles. Cependant, les données d’images et de textes sont abondantes et peuvent fournir des informations supplémentaires utiles. La méthode décrite dans cet article peut utiliser pleinement tous les types de données (trimodales, bimodales et unimodales) pour améliorer la capacité de généralisation du décodage neuronal.
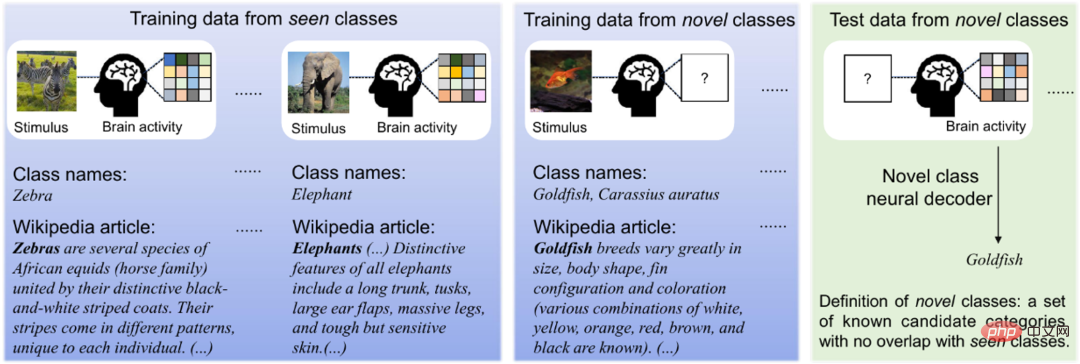
Figure 2. Stimuli d'image, activités cérébrales induites et données textuelles correspondantes. Nous ne pouvons collecter des données sur l’activité cérébrale que pour quelques catégories, mais des données d’images et/ou de texte peuvent facilement être collectées pour presque toutes les catégories. Par conséquent, pour les catégories connues, nous supposons que l'activité cérébrale, les images visuelles et les descriptions textuelles correspondantes sont toutes disponibles pour l'entraînement, tandis que pour les nouvelles catégories, seules les images visuelles et les descriptions textuelles sont disponibles pour l'entraînement. Les données de test sont des données d'activité cérébrale provenant de nouvelles catégories.
Apprentissage multimodal « Cerveau-Image-Texte »
Comme le montre la figure 3A ci-dessous, la clé de cette méthode est d'aligner la distribution apprise par chaque modalité dans un espace latent partagé Contient des informations multimodales de base. liés aux nouvelles catégories.
Plus précisément, l'auteur propose un cadre d'apprentissage bayésien variationnel d'auto-encodage multimodal, qui utilise le mélange de produits d'experts, MoPoE), un encodage latent est déduit pour permettre la génération conjointe de tous trois modalités. Afin d'apprendre des représentations conjointes plus pertinentes et d'améliorer l'efficacité des données lorsque les données sur l'activité cérébrale sont limitées, les auteurs introduisent en outre des termes de régularisation des informations mutuelles intra-modales et intermodales. De plus, les modèles BraVL peuvent être entraînés dans divers scénarios d'apprentissage semi-supervisé pour incorporer des fonctionnalités visuelles et textuelles supplémentaires de catégories d'images à grande échelle.
Dans la figure 3B, les auteurs entraînent un classificateur SVM à partir de représentations latentes de caractéristiques visuelles et textuelles de nouvelles catégories. A noter que dans cette étape les encodeurs E_v et E_t sont figés et seul le classificateur SVM (module gris) sera optimisé.
Dans l'application, comme le montre la figure 3C, la entrée de cette méthode n'est qu'une nouvelle catégorie de signaux cérébraux et ne nécessite pas d'autres données, elle peut donc être facilement appliquée à la plupart des scénarios de décodage neuronal. Le classificateur SVM est capable de généraliser de (B) à (C) car les représentations sous-jacentes de ces trois modalités sont déjà alignées dans A.

Figure 3 Le cadre d'apprentissage conjoint trimodal « cerveau-image-texte » proposé dans cet article, appelé BraVL.
De plus, les signaux cérébraux changeront d'un essai à l'autre, même pour le même stimulus visuel. Pour améliorer la stabilité du décodage neuronal, les auteurs ont utilisé une méthode de sélection de stabilité pour traiter les données IRMf. Les scores de stabilité de tous les voxels sont présentés dans la figure 4 ci-dessous. L'auteur a sélectionné les 15 % de voxels présentant la meilleure stabilité pour participer au processus de décodage neuronal. Cette opération peut réduire efficacement la dimensionnalité des données IRMf et supprimer les interférences provoquées par des voxels bruyants sans affecter sérieusement la capacité discriminante des caractéristiques cérébrales.

Figure 4. Carte du score de stabilité de l'activité voxel du cortex visuel du cerveau.
Les ensembles de données d'encodage et de décodage neuronaux existants ne contiennent souvent que des stimuli d'image et des réponses cérébrales. Afin d'obtenir la description linguistique correspondant au concept visuel, l'auteur a adopté une méthode d'extraction semi-automatique des articles Wikipédia. Plus précisément, les auteurs créent d'abord une correspondance automatique des classes ImageNet avec leurs pages Wikipédia correspondantes. La correspondance est basée sur la similitude entre les mots synset de la classe ImageNet et le titre Wikipédia, ainsi que leurs catégories parentes. Comme le montre la figure 5 ci-dessous, malheureusement, ce type de correspondance peut parfois produire des faux positifs car des classes portant des noms similaires peuvent représenter des concepts très différents. Lors de la construction de l'ensemble de données trimodal, pour garantir une correspondance de haute qualité entre les caractéristiques visuelles et les caractéristiques linguistiques, les auteurs ont supprimé manuellement les articles sans correspondance.
Figure 5. Acquisition semi-automatique de description de concept visuel
Résultats expérimentaux
L'auteur a mené de vastes expériences de décodage neuronal sans tir sur plusieurs ensembles de données de correspondance trimodale "cerveau-image-texte". Les résultats expérimentaux sont présentés dans le tableau ci-dessous. Comme on peut le constater, les modèles utilisant une combinaison de fonctionnalités visuelles et textuelles (V&T) fonctionnent bien mieux que les modèles utilisant l'une ou l'autre seule. Notamment, BraVL basé sur les fonctionnalités V&T améliore considérablement la précision moyenne du top 5 sur les deux ensembles de données. Ces résultats suggèrent que, même si les stimuli présentés aux sujets contiennent uniquement des informations visuelles, il est concevable que les sujets invoquent inconsciemment des représentations linguistiques appropriées, affectant ainsi le traitement visuel.
Pour chaque catégorie de concepts visuels, les auteurs montrent également le gain de précision du décodage neuronal après l'ajout de fonctionnalités de texte, comme le montre la figure 6 ci-dessous. On peut constater que pour la plupart des classes de test, l'ajout de fonctionnalités de texte a un impact positif, la précision moyenne du décodage Top-1 augmentant d'environ 6 %. Figure 6. Gain de précision du décodage neuronal après l'ajout de fonctionnalités de texte Contribution à l'encodage (prédiction de l'activité du voxel cérébral correspondant basée sur des caractéristiques visuelles ou textuelles)
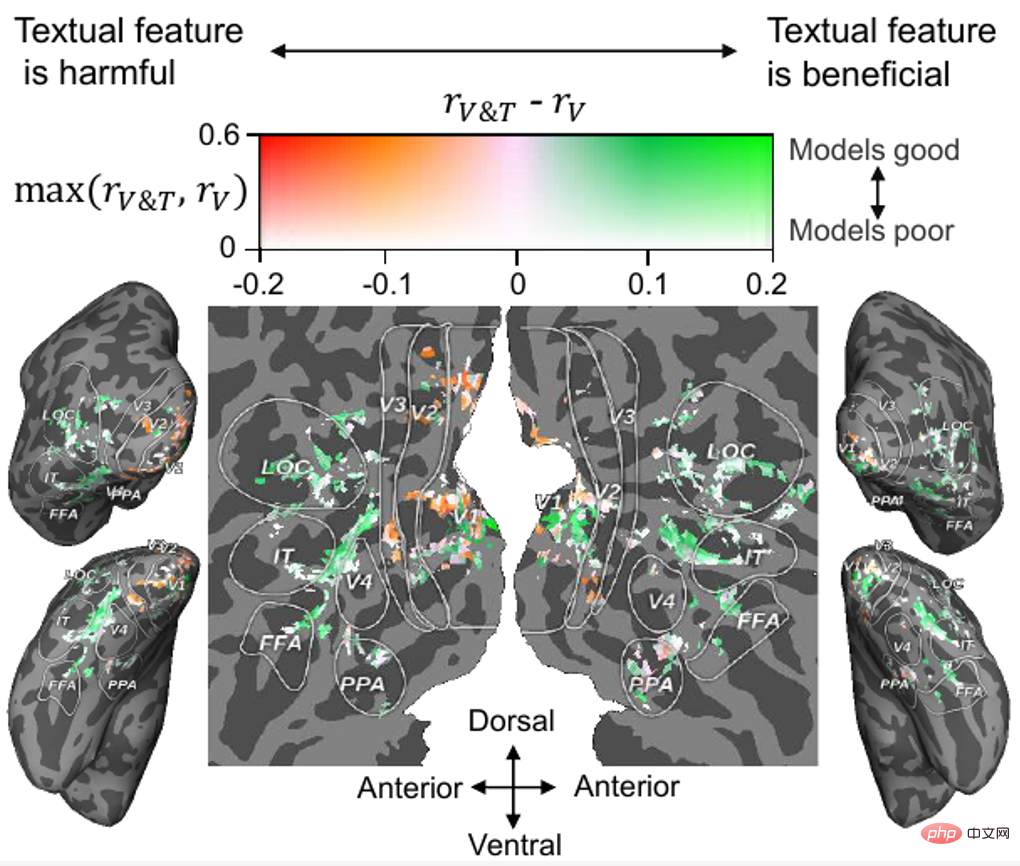
, les résultats sont présentés dans la figure 7. On peut constater que pour la plupart des cortex visuels de haut niveau (HVC, tels que FFA, LOC et IT), la fusion de caractéristiques textuelles sur la base de caractéristiques visuelles peut améliorer la précision de la prédiction de l'activité cérébrale, tandis que pour la plupart des cortex visuels de bas niveau. (LVC, tels que V1, V2 et V3), la fusion des fonctionnalités de texte n'est ni bénéfique ni même nuisible.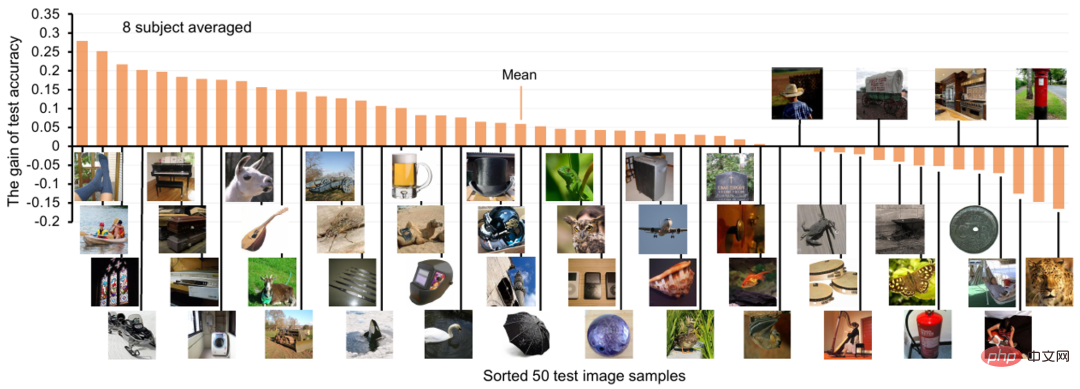
Figure 7. Projection de la contribution des fonctionnalités de texte au cortex visuel
Pour plus de résultats expérimentaux, veuillez consulter le texte original.Dans l'ensemble, cet article tire des conclusions et des idées cognitives intéressantes : 1) le décodage de nouvelles catégories visuelles à partir de l'activité cérébrale humaine est réalisable avec une grande précision ; 2) en utilisant une combinaison de caractéristiques visuelles et linguistiques. Le modèle de décodage de a un décodage neuronal plus élevé ; performances ; 5) Les données supplémentaires monomodales et bimodales peuvent améliorer considérablement la précision du décodage.
 Discussion et perspectives
Discussion et perspectives
Du Changde, premier auteur de l'article et assistant de recherche spécial à l'Institut d'automatisation de l'Académie chinoise des sciences, a déclaré : « Ce travail confirme que les caractéristiques extraites de l'activité cérébrale, des images visuelles et des descriptions textuelles sont efficaces pour décoder les signaux neuronaux. Cependant, les caractéristiques visuelles extraites peuvent ne pas refléter avec précision toutes les étapes du traitement visuel humain, et un meilleur ensemble de fonctionnalités serait utile pour ces tâches. Par exemple, des modèles de langage pré-entraînés plus grands (tels que GPT). -3) peut être utilisé pour extraire des caractéristiques de texte avec de meilleures capacités de généralisation sans tir. De plus, bien que les articles Wikipédia contiennent des informations visuelles riches, ces informations sont facilement masquées par un grand nombre de phrases non visuelles grâce à l'extraction ou à l'utilisation de phrases visuelles. ChatGPT et GPT-4 La collecte de descriptions visuelles plus précises et plus riches par d'autres modèles peut résoudre ce problème. Enfin, bien que cette étude ait utilisé relativement plus de données trimodales par rapport aux études similaires, un ensemble de données plus vaste et plus diversifié serait plus bénéfique. . Nous laissons ces aspects pour des recherches futures.” Le chercheur He Huiguang de l'Institut d'automatisation de l'Académie chinoise des sciences, auteur correspondant de l'article, a souligné : « La méthode proposée dans cet article a trois applications potentielles : 1) En tant qu'outil de décodage neurosémantique, cette méthode sera utilisée dans de nouveaux dispositifs neuroprothétiques qui lisent les informations sémantiques du cerveau humain. Jouent un rôle important dans le développement. Bien que cette application ne soit pas encore mature, la méthode présentée dans cet article en fournit une base technique. 2) En déduisant l'activité cérébrale à travers les modalités. la méthode décrite dans cet article peut également être utilisée comme outil de codage neuronal pour étudier la vision et la façon dont les caractéristiques du langage sont exprimées sur le cortex cérébral humain, révélant quelles régions du cerveau ont des propriétés multimodales (c'est-à-dire sont sensibles aux caractéristiques visuelles et linguistiques). La décodabilité neuronale de la représentation interne du modèle d'IA peut être considérée comme un niveau de type cerveau du modèle. Par conséquent, la méthode décrite dans cet article peut également être utilisée comme outil d'évaluation des propriétés de type cerveau pour tester quel modèle. (visuelle ou linguistique) est plus proche de l'activité cérébrale humaine, motivant ainsi les chercheurs à concevoir davantage de modèles informatiques ressemblant à ceux du cerveau. C'est également un moyen efficace d'explorer les principes qui sous-tendent les fonctions complexes du cerveau humain et de promouvoir le développement d'une intelligence semblable à celle du cerveau. L'équipe de recherche en informatique neuronale et interaction cerveau-ordinateur de l'Institut d'automatisation travaille dans ce domaine depuis de nombreuses années et a réalisé une série de travaux de recherche, qui ont été publiés dans TPAMI 2023, TMI2023, TNNLS 2022/2019, TMM 2021, Infos Fusion 2021, AAAI 2020, etc. Les travaux préliminaires ont fait la une du MIT Technology Review et ont remporté le prix ICME 2019 Best Paper Runner-up Award. Cette recherche a été soutenue par le projet majeur Innovation scientifique et technologique 2030 - « Intelligence artificielle de nouvelle génération », le projet de la Fondation nationale, le projet de l'Institut d'automatisation 2035 et le fonds de prix académique de la China Artificial Intelligence Society-Huawei MindSpore et Projets de base intelligente. À propos de l'auteur
Auteur correspondant : He Huiguang, chercheur à l'Institut d'automatisation, Académie chinoise des sciences, directeur de doctorat, post-professeur à l'Université de l'Académie chinoise des sciences, professeur distingué à l'Université des sciences et technologies de Shanghai, membre exceptionnel de l'Association de promotion de la jeunesse de l'Académie chinoise des sciences et lauréat de la médaille commémorative du 70e anniversaire de la fondation de la République populaire de Chine . Il a successivement entrepris 7 projets du Fonds naturel national (y compris des projets de fonds clés et de coopération internationale), 2 863 projets et des projets de plans clés de recherche nationaux. Il a remporté deux prix nationaux de progrès scientifique et technologique de deuxième classe (classés respectivement deuxième et troisième), deux prix de progrès scientifique et technologique de Pékin, le prix de progrès scientifique et technologique de première classe du ministère de l'Éducation, le premier prix de thèse de doctorat exceptionnel. de l'Académie chinoise des sciences, de l'étoile montante des sciences et technologies de Pékin et de l'Académie chinoise des sciences « Lu Jiaxi Young Talent Award », professeur titulaire de la chaire « Minjiang Scholar » de la province du Fujian. Ses domaines de recherche incluent l’intelligence artificielle, l’interface cerveau-ordinateur, l’analyse d’images médicales, etc. Au cours des cinq dernières années, il a publié plus de 80 articles dans des revues et conférences telles que IEEE TPAMI/TNNLS et ICML. Il est membre du comité de rédaction de l'IEEEE TCDS, du Journal of Automation et d'autres revues, membre distingué du CCF et membre distingué du CSIG.
 Page d'accueil personnelle : https://changdedu.github.io/
Page d'accueil personnelle : https://changdedu.github.io/ 
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI