
Maison >développement back-end >Tutoriel Python >Programme solitaire d'écriture de poésie Python
Programme solitaire d'écriture de poésie Python

- 王林avant
- 2023-05-08 09:04:181890parcourir
Corpus de poésie
Tout d'abord, nous utilisons le robot d'exploration Python pour explorer des poèmes et créer un corpus. Les pages explorées sont les suivantes :
Poèmes explorés
Étant donné que cet article vise principalement à essayer de montrer l'idée du projet, donc seulement 300 poèmes Tang, 300 poèmes anciens et 3 paroles de chansons à partir de cette page ont été explorés 100. Paroles de chansons sélectionnées, un total de plus de 1 100 poèmes. Afin d'accélérer le robot, celui-ci est implémenté simultanément et enregistré dans le fichier poème.txt. Le programme Python complet est le suivant :
import re
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 爬取的诗歌网址
urls = ['https://so.gushiwen.org/gushi/tangshi.aspx',
'https://so.gushiwen.org/gushi/sanbai.aspx',
'https://so.gushiwen.org/gushi/songsan.aspx',
'https://so.gushiwen.org/gushi/songci.aspx'
]
poem_links = []
# 诗歌的网址
for url in urls:
# 请求头部
headers = {: 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
content = soup.find_all('div', class_="sons")[0]
links = content.find_all('a')
for link in links:
poem_links.append('https://so.gushiwen.org'+link['href'])
poem_list = []
# 爬取诗歌页面
def get_poem(url):
#url = 'https://so.gushiwen.org/shiwenv_45c396367f59.aspx'
# 请求头部
headers = {: 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'}
req = requests.get(url, headers=headers)
soup = BeautifulSoup(req.text, "lxml")
poem = soup.find('div', class_='contson').text.strip()
poem = poem.replace(' ', '')
poem = re.sub(re.compile(r"([sS]*?)"), '', poem)
poem = re.sub(re.compile(r"([sS]*?)"), '', poem)
poem = re.sub(re.compile(r"。([sS]*?)"), '', poem)
poem = poem.replace('!', '!').replace('?', '?')
poem_list.append(poem)
# 利用并发爬取
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers,即线程的个数
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(get_poem, url) for url in poem_links]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
# 将爬取的诗句写入txt文件
poems = list(set(poem_list))
poems = sorted(poems, key=lambda x:len(x))
for poem in poems:
poem = poem.replace('《','').replace('》','')
.replace(':', '').replace('“', '')
print(poem)
with open('F://poem.txt', 'a') as f:
f.write(poem)
f.write('
')
Ce programme explore plus de 1 100 poèmes et enregistre les poèmes dans le fichier poème.txt pour former notre corpus de poésie. Bien entendu, ces poèmes ne peuvent pas être utilisés directement et les données doivent être nettoyées. Par exemple, certains poèmes ont une ponctuation irrégulière, certains ne sont pas des poèmes, mais ne sont que des préfaces de poèmes, etc. Ce processus nécessite une opération manuelle, bien qu'il soit nécessaire. C'est un peu gênant, mais pour le phrasé ultérieur des poèmes, l'effet en vaut également la peine.
Phrases poétiques
Avec le corpus poétique, nous devons segmenter les poèmes. La norme de segmentation est la suivante : selon la fin. ? ! Pour la segmentation, cela peut être réalisé à l'aide d'expressions régulières. Après cela, écrivez les poèmes avec de bonnes phrases dans un dictionnaire : la clé (clé) est le pinyin du premier mot de la phrase, la valeur (valeur) est le poème correspondant au pinyin, et enregistrez le dictionnaire sous forme de fichier pickle. . Le code Python complet est le suivant :
import re
import pickle
from xpinyin import Pinyin
from collections import defaultdict
def main():
with open('F://poem.txt', 'r') as f:
poems = f.readlines()
sents = []
for poem in poems:
parts = re.findall(r'[sS]*?[。?!]', poem.strip())
for part in parts:
if len(part) >= 5:
sents.append(part)
poem_dict = defaultdict(list)
for sent in sents:
print(part)
head = Pinyin().get_pinyin(sent, tone_marks='marks', splitter=' ').split()[0]
poem_dict[head].append(sent)
with open('./poemDict.pk', 'wb') as f:
pickle.dump(poem_dict, f)
main()
On peut jeter un œil au contenu du fichier pickle (poemDict.pk) :

Contenu du fichier pickle (partie)
Bien sûr, un pinyin peut correspondent à plusieurs poèmes.
Poetry Solitaire
Lisez le fichier pickle, écrivez un programme et exécutez le programme en tant que fichier exe. Afin d'éviter les erreurs lors de la compilation du fichier exe, nous devons réécrire le fichier init.py du module xpinyin, copier tout le code du fichier dans mypinyin.py, et réécrire le code suivant
data_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'Mandarin.dat')
dans le code Pour
data_path = os.path.join(os.getcwd(), 'Mandarin.dat')
, cela complète notre fichier mypinyin.py. Ensuite, nous devons écrire le code du solitaire de poésie (Poem_Jielong.py). Le code complet est le suivant :
import pickle
from mypinyin import Pinyin
import random
import ctypes
STD_INPUT_HANDLE = -10
STD_OUTPUT_HANDLE = -11
STD_ERROR_HANDLE = -12
FOREGROUND_DARKWHITE = 0x07 # 暗白色
FOREGROUND_BLUE = 0x09 # 蓝色
FOREGROUND_GREEN = 0x0a # 绿色
FOREGROUND_SKYBLUE = 0x0b # 天蓝色
FOREGROUND_RED = 0x0c # 红色
FOREGROUND_PINK = 0x0d # 粉红色
FOREGROUND_YELLOW = 0x0e # 黄色
FOREGROUND_WHITE = 0x0f # 白色
std_out_handle = ctypes.windll.kernel32.GetStdHandle(STD_OUTPUT_HANDLE)
# 设置CMD文字颜色
def set_cmd_text_color(color, handle=std_out_handle):
Bool = ctypes.windll.kernel32.SetConsoleTextAttribute(handle, color)
return Bool
# 重置文字颜色为暗白色
def resetColor():
set_cmd_text_color(FOREGROUND_DARKWHITE)
# 在CMD中以指定颜色输出文字
def cprint(mess, color):
color_dict = {
: FOREGROUND_BLUE,
: FOREGROUND_GREEN,
: FOREGROUND_SKYBLUE,
: FOREGROUND_RED,
: FOREGROUND_PINK,
: FOREGROUND_YELLOW,
: FOREGROUND_WHITE
}
set_cmd_text_color(color_dict[color])
print(mess)
resetColor()
color_list = ['蓝色','绿色','天蓝色','红色','粉红色','黄色','白色']
# 获取字典
with open('./poemDict.pk', 'rb') as f:
poem_dict = pickle.load(f)
#for key, value in poem_dict.items():
#print(key, value)
MODE = str(input('Choose MODE(1 for 人工接龙, 2 for 机器接龙): '))
while True:
try:
if MODE == '1':
enter = str(input('
请输入一句诗或一个字开始:'))
while enter != 'exit':
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]
if tail not in poem_dict.keys():
cprint('无法接这句诗。
', '红色')
MODE = 0
break
else:
cprint('
机器回复:%s'%random.sample(poem_dict[tail], 1)[0], random.sample(color_list, 1)[0])
enter = str(input('你的回复:'))[:-1]
MODE = 0
if MODE == '2':
enter = input('
请输入一句诗或一个字开始:')
for i in range(10):
test = Pinyin().get_pinyin(enter, tone_marks='marks', splitter=' ')
tail = test.split()[-1]
if tail not in poem_dict.keys():
cprint('------>无法接下去了啦...', '红色')
MODE = 0
break
else:
answer = random.sample(poem_dict[tail], 1)[0]
cprint('(%d)--> %s' % (i+1, answer), random.sample(color_list, 1)[0])
enter = answer[:-1]
print('
(*****最多展示前10回接龙。*****)')
MODE = 0
except Exception as err:
print(err)
finally:
if MODE not in ['1','2']:
MODE = str(input('
Choose MODE(1 for 人工接龙, 2 for 机器接龙): '))
Maintenant, la structure de l'ensemble du projet est la suivante (le fichier Mandarin.dat est copié du dossier correspondant à le module xpinyin) :
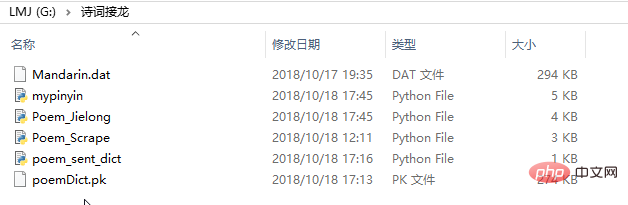
Fichier projet
Basculez vers ce dossier et entrez la commande suivante pour générer le fichier exe :
pyinstaller -F Poem_jielong.py
Le fichier exe généré est Poem_jielong.exe, situé dans le dossier dist de ce dossier. Pour que l'exe s'exécute correctement, les fichiers poetDict.pk et Mandarin.dat doivent être copiés dans le dossier dist.
Test d'exécution
Exécutez le fichier Poem_jielong.exe, la page est la suivante :
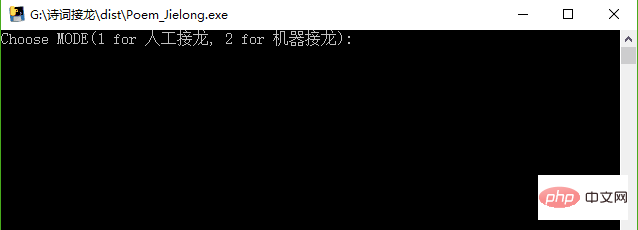
Page de démarrage du fichier exe
Il existe deux modes pour le solitaire de poésie dans ce projet, l'un est le solitaire manuel, c'est-à-dire que vous entrez d'abord un poème ou un mot, puis l'ordinateur répond par une phrase, et vous répondez par une phrase, qui est responsable des règles du solitaire de poésie ; l'autre mode est le solitaire automatique, c'est-à-dire que vous entrez d'abord un poème ou un mot ; un mot, et la machine produira automatiquement les versets de solitaire suivants (jusqu'à 10). Testez d'abord le mode Solitaire manuel :
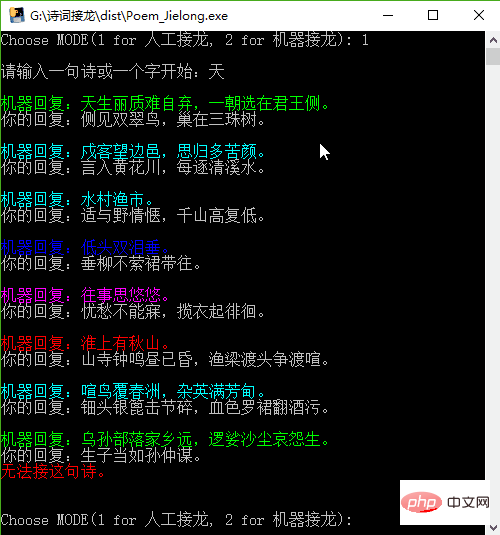
Solitaire manuel
Testez ensuite le mode Solitaire machine :
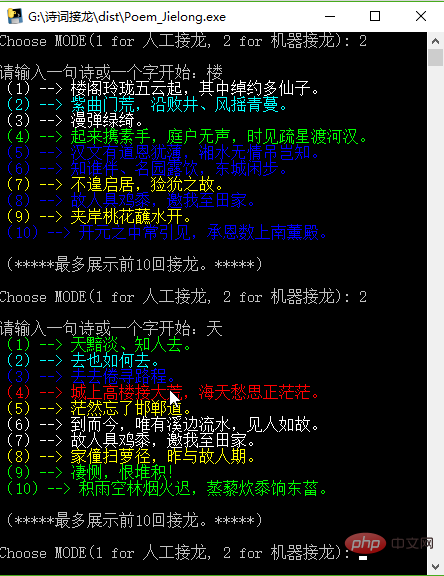
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!