
Maison >Périphériques technologiques >IA >L'abandon amélioré peut être utilisé pour atténuer les problèmes de sous-ajustement.
L'abandon amélioré peut être utilisé pour atténuer les problèmes de sous-ajustement.

- 王林avant
- 2023-05-07 23:43:061359parcourir
En 2012, Hinton et al. ont proposé l'abandon dans leur article « Améliorer les réseaux de neurones en empêchant la co-adaptation des détecteurs de caractéristiques ». La même année, l’émergence d’AlexNet ouvre une nouvelle ère d’apprentissage profond. AlexNet utilise l'abandon pour réduire considérablement le surapprentissage et a joué un rôle clé dans sa victoire au concours ILSVRC 2012. Il suffit de dire que sans abandon, les progrès que nous constatons actuellement dans le domaine de l’apprentissage profond auraient pu être retardés de plusieurs années.
Depuis le lancement de dropout, il a été largement utilisé comme régularisateur pour réduire le surapprentissage dans les réseaux de neurones. L'abandon désactive chaque neurone avec une probabilité p, empêchant différentes fonctionnalités de s'adapter les unes aux autres. Après avoir appliqué l'abandon, la perte de formation augmente généralement tandis que l'erreur de test diminue, comblant ainsi l'écart de généralisation du modèle. Le développement de l’apprentissage profond continue d’introduire de nouvelles technologies et architectures, mais le décrochage existe toujours. Il continue de jouer un rôle dans les dernières réalisations de l’IA, telles que la prédiction des protéines AlphaFold, la génération d’images DALL-E 2, etc., démontrant sa polyvalence et son efficacité.
Malgré la popularité continue du décrochage scolaire, son intensité (exprimée en taux d'abandon p) a diminué au fil des années. L’effort d’abandon initial a utilisé un taux d’abandon par défaut de 0,5. Cependant, ces dernières années, des taux d'abandon plus faibles sont souvent utilisés, tels que 0,1. Des exemples connexes peuvent être vus dans la formation BERT et ViT. Le principal moteur de cette tendance est l’explosion des données d’entraînement disponibles, rendant le surapprentissage de plus en plus difficile. En combinaison avec d’autres facteurs, nous pourrions rapidement nous retrouver avec davantage de problèmes de sous-apprentissage que de surapprentissage.
Récemment, dans un article intitulé « Le décrochage réduit le sous-ajustement », des chercheurs de Meta AI, de l'Université de Californie à Berkeley et d'autres institutions ont démontré comment utiliser le décrochage pour résoudre le problème du sous-ajustement.
Adresse papier : https://arxiv.org/abs/2303.01500
Ils ont d'abord étudié la dynamique de formation du décrochage à travers des observations intéressantes sur la norme de gradient, puis en ont tiré une découverte empirique clé : Étape initiale de la formation, l'abandon réduit la variance de gradient du mini-lot et permet au modèle de se mettre à jour dans une direction plus cohérente. Ces directions sont également plus cohérentes avec les directions de gradient sur l'ensemble de l'ensemble de données, comme le montre la figure 1 ci-dessous.
Ainsi, le modèle peut optimiser plus efficacement la perte d'entraînement sur l'ensemble de l'entraînement sans être affecté par des mini-lots individuels. En d’autres termes, l’abandon neutralise la descente de gradient stochastique (SGD) et empêche la régularisation excessive causée par le caractère aléatoire des mini-lots échantillonnés au début de la formation.
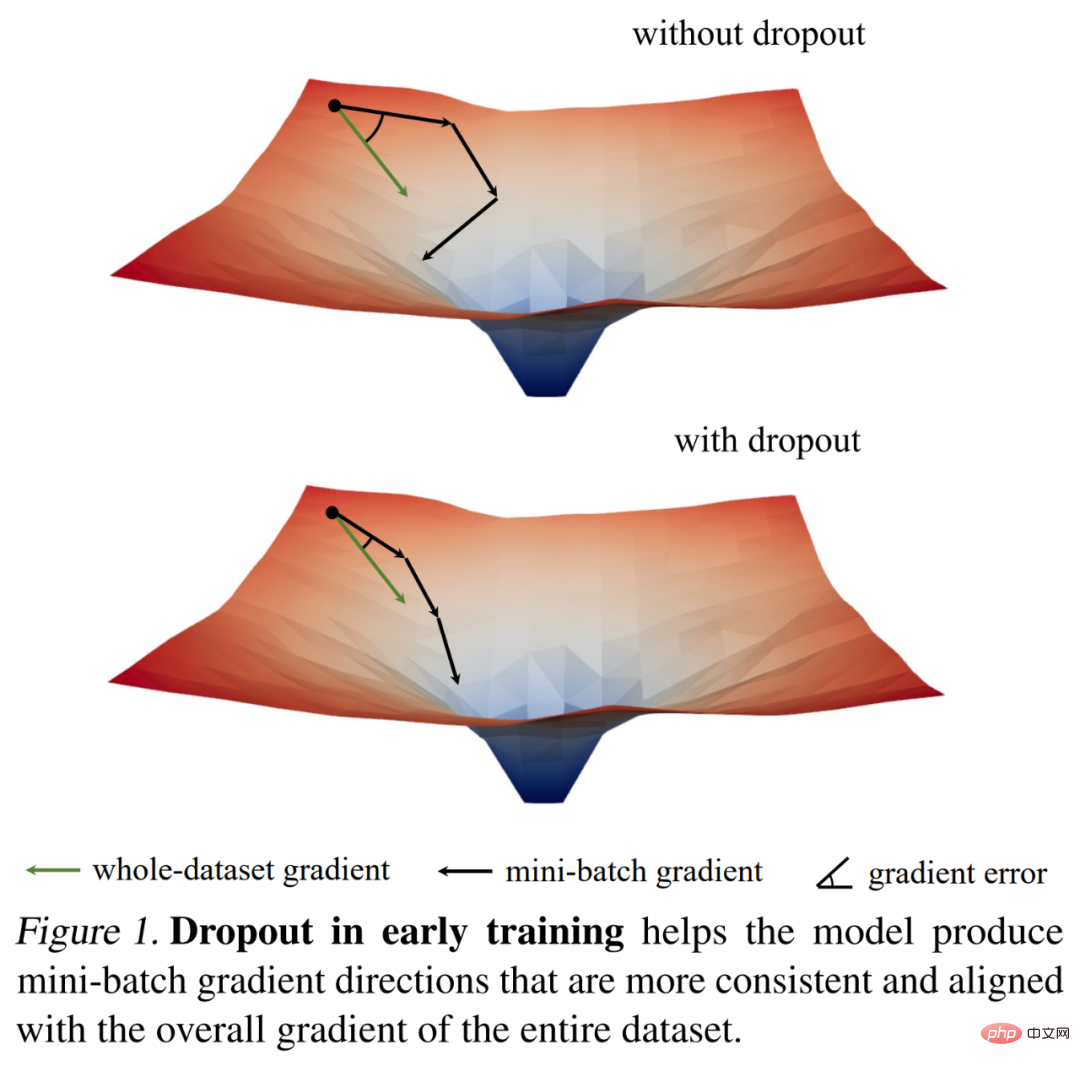
Sur la base de ces résultats, les chercheurs ont proposé un abandon précoce (c'est-à-dire que l'abandon n'est utilisé que dans les premiers stades de la formation) pour aider les modèles sous-adaptés à mieux s'adapter. L'abandon précoce réduit la perte d'entraînement finale par rapport à l'absence d'abandon et à l'abandon standard. En revanche, pour les modèles qui utilisent déjà l’abandon standard, les chercheurs recommandent de supprimer l’abandon dès les premières périodes d’entraînement afin de réduire le surapprentissage. Ils ont qualifié cette méthode d’abandon tardif et ont montré qu’elle pouvait améliorer la précision de généralisation des grands modèles. La figure 2 ci-dessous compare l'abandon standard, l'abandon précoce et l'abandon tardif.

Les chercheurs ont utilisé différents modèles pour évaluer l'abandon précoce et l'abandon tardif dans la classification d'images et les tâches en aval, et les résultats ont montré que les deux produisaient systématiquement de meilleurs résultats que l'abandon standard et l'absence d'abandon. Ils espèrent que leurs découvertes pourront fournir de nouvelles informations sur l’abandon et le surapprentissage et inspirer le développement ultérieur de régularisateurs de réseaux neuronaux.
Analyse et validation
Avant de proposer l'abandon précoce et l'abandon tardif, cette étude a exploré si l'abandon scolaire pouvait être utilisé comme un outil pour réduire le sous-apprentissage. Cette étude a effectué une analyse détaillée de la dynamique de formation des abandons à l'aide des outils et des mesures proposés, et a comparé les processus de formation de deux ViT-T/16 sur ImageNet (Deng et al., 2009) : un sans abandon comme référence ; L'autre One a un taux d'abandon de 0,1 tout au long de la formation.
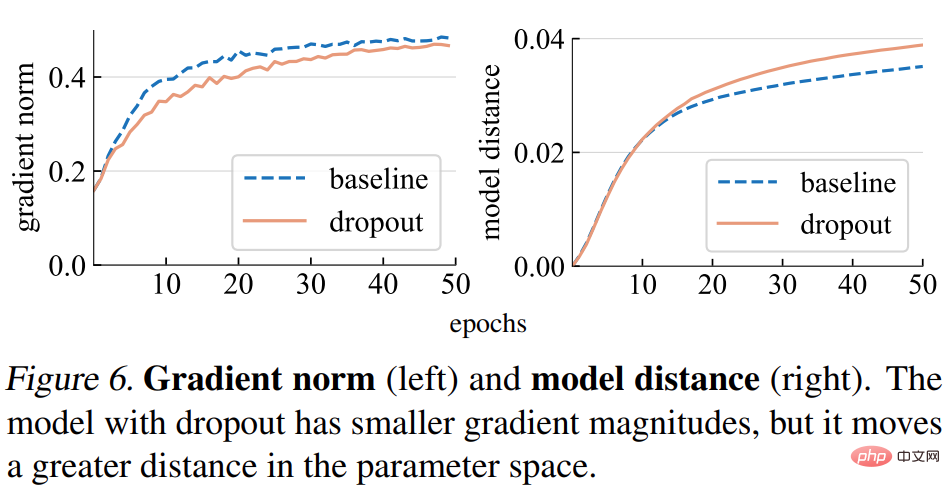
Norme de dégradé (norme). Cette étude analyse d’abord l’impact du décrochage scolaire sur la force du gradient g. Comme le montre la figure 6 (à gauche) ci-dessous, le modèle d'abandon produit des gradients avec des normes plus petites, indiquant qu'il effectue des étapes plus petites à chaque mise à jour du gradient.
Distance du modèle. Étant donné que la taille du pas de gradient est plus petite, nous nous attendons à ce que le modèle d'abandon se déplace sur une distance plus petite par rapport à son point initial que le modèle de base. Comme le montre la figure 6 (à droite) ci-dessous, l'étude a tracé la distance entre chaque modèle et son initialisation aléatoire. Cependant, de manière surprenante, le modèle d’abandon a en fait parcouru une plus grande distance que le modèle de base, contrairement à ce que l’étude attendait initialement sur la base de la norme de gradient.
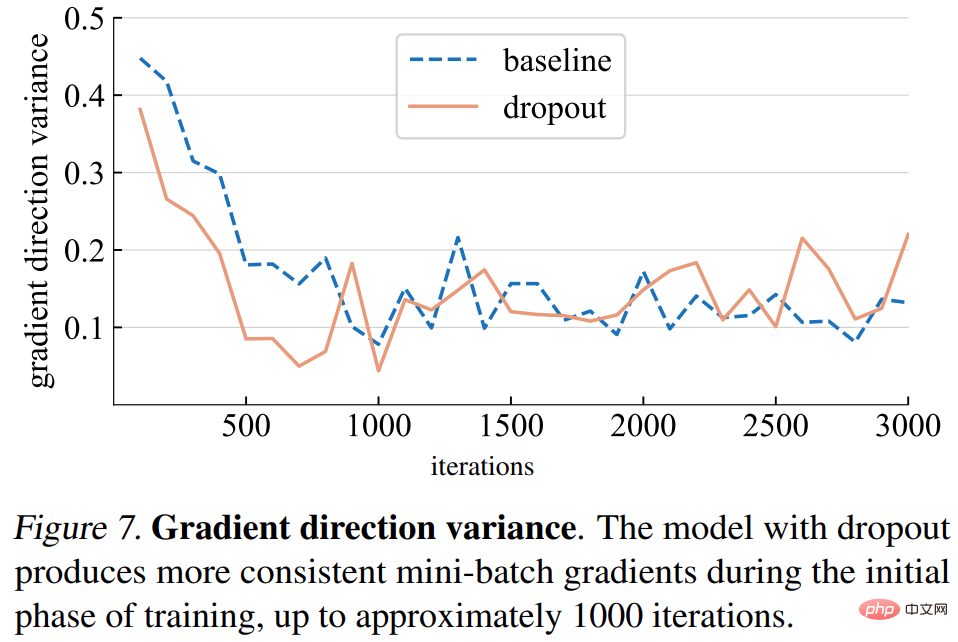
Variation de direction du dégradé. L’étude émet d’abord l’hypothèse que les modèles d’abandon produisent des directions de gradient plus cohérentes entre les mini-lots. Les écarts présentés dans la figure 7 ci-dessous sont généralement conformes aux hypothèses. Jusqu'à un certain nombre d'itérations (environ 1 000), les variances de gradient du modèle d'abandon et du modèle de base fluctuent à un faible niveau.
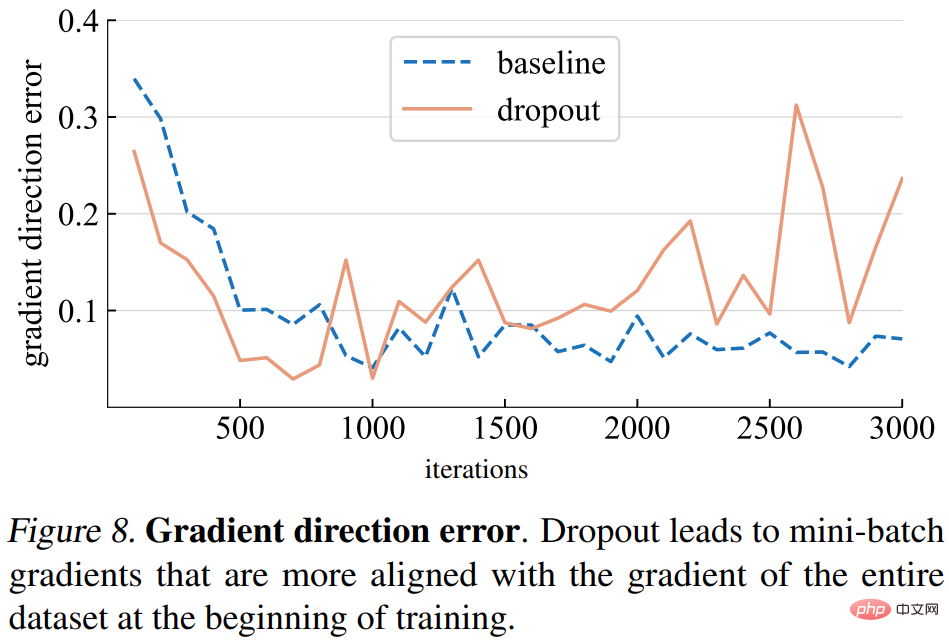
Erreur de direction du dégradé. Cependant, quelle devrait être la bonne direction du dégradé ? Pour adapter les données d'entraînement, l'objectif fondamental est de minimiser la perte de l'ensemble de l'entraînement, et pas seulement la perte d'un mini-lot. L'étude calcule le gradient d'un modèle donné sur l'ensemble de l'ensemble d'entraînement, avec un abandon défini en mode d'inférence pour capturer le gradient du modèle complet. L'erreur de direction du gradient est illustrée à la figure 8 ci-dessous.
Sur la base de l'analyse ci-dessus, cette étude a révélé que l'utilisation de l'abandon le plus tôt possible peut potentiellement améliorer la capacité du modèle à s'adapter aux données d'entraînement. La nécessité d'un meilleur ajustement aux données d'entraînement dépend du fait que le modèle soit sous-ajusté ou surajusté, ce qui peut être difficile à définir avec précision. L'étude a utilisé les critères suivants :
- Si un modèle se généralise mieux en cas d'abandon standard, il est considéré comme un surapprentissage ;
- Si le modèle fonctionne mieux sans abandon, alors il est considéré comme un sous-apprentissage ;
L'état du modèle dépend non seulement de l'architecture du modèle, mais également de l'ensemble de données utilisé et d'autres paramètres d'entraînement.
Ensuite, l'étude a proposé deux méthodes, l'abandon précoce et l'abandon tardif
l'abandon précoce. Par défaut, les modèles sous-équipés n'utilisent pas de décrochage. Pour améliorer sa capacité d'adaptation aux données d'entraînement, cette étude propose un abandon précoce : utiliser l'abandon avant une certaine itération, puis désactiver l'abandon pendant le reste du processus de formation. Les expériences de recherche montrent qu'un abandon précoce réduit la perte finale d'entraînement et améliore la précision.
abandon tardif. L'abandon standard est déjà inclus dans les paramètres de formation pour les modèles de surajustement. Aux premiers stades de la formation, l’abandon peut par inadvertance provoquer un surapprentissage, ce qui n’est pas souhaitable. Pour réduire le surapprentissage, cette étude propose un abandon tardif : l'abandon n'est pas utilisé avant une certaine itération, mais est utilisé dans le reste de la formation.
La méthode proposée dans cette étude est simple dans son concept et sa mise en œuvre, comme le montre la figure 2. L'implémentation nécessite deux hyperparamètres : 1) le nombre d'époques à attendre avant d'activer ou de désactiver l'abandon 2) le taux d'abandon p, qui est similaire au taux d'abandon standard ; Cette étude montre que ces deux hyperparamètres peuvent assurer la robustesse de la méthode proposée.
Expériences et résultats
Les chercheurs ont mené une évaluation empirique sur l'ensemble de données de classification ImageNet-1K avec 1 000 classes et 1,2 million d'images d'entraînement, et ont signalé une précision de validation de premier ordre.
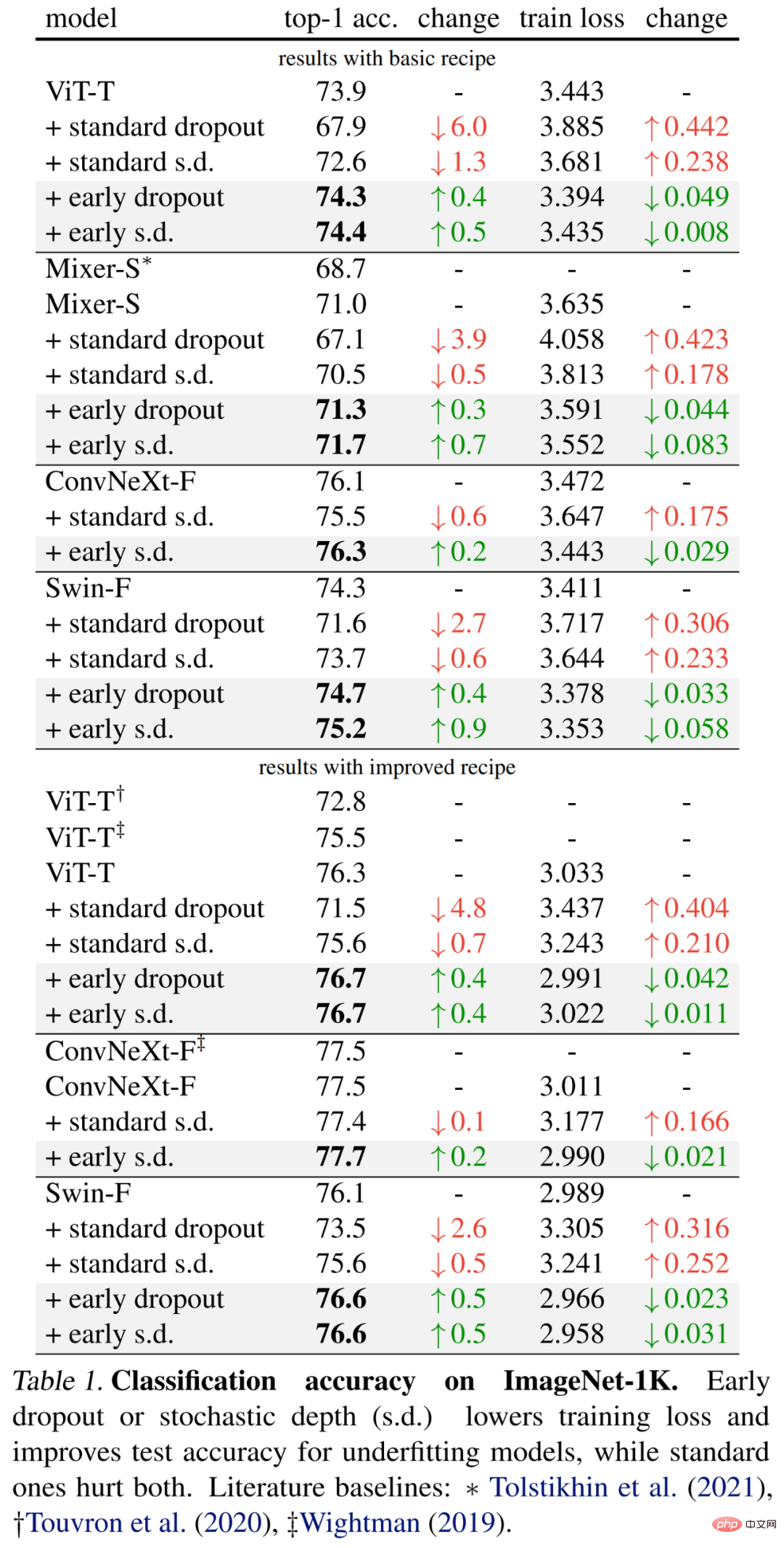
Les résultats spécifiques sont présentés pour la première fois dans le tableau 1 (partie supérieure) ci-dessous. L'abandon précoce continue d'améliorer la précision des tests et de réduire la perte d'entraînement, ce qui indique que l'abandon précoce aide le modèle à mieux s'adapter aux données. Les chercheurs montrent également des résultats de comparaison utilisant un taux de chute de 0,1 par rapport à la profondeur stochastique (SD) d’abandon standard, qui ont tous deux un impact négatif sur le modèle.
De plus, les chercheurs ont amélioré la méthode pour ces petits modèles en doublant les époques d'entraînement et en réduisant l'intensité du mixup et du cutmix. Les résultats du tableau 1 ci-dessous (en bas) montrent des améliorations significatives de la précision de base, dépassant parfois largement les résultats des travaux antérieurs.
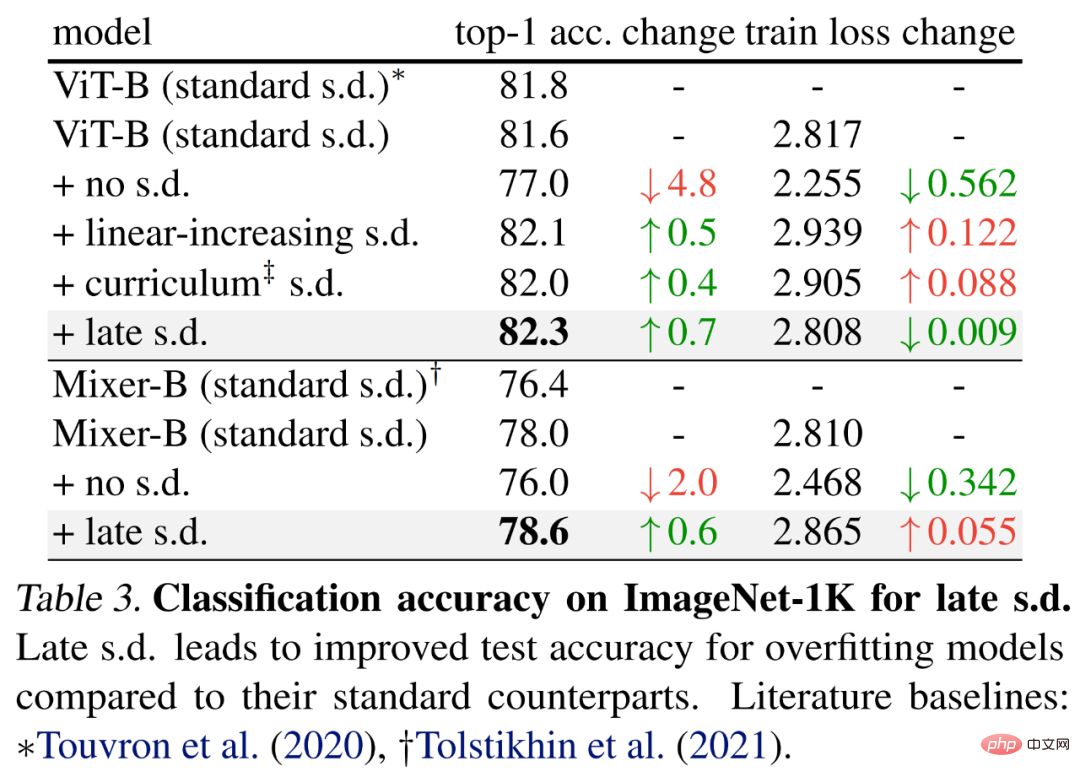
Pour évaluer l'abandon tardif, les chercheurs ont choisi des modèles plus grands, à savoir ViT-B et Mixer-B avec respectivement 59M et 86M de paramètres, en utilisant la méthode d'entraînement de base.
Les résultats sont présentés dans le tableau 3 ci-dessous. Par rapport au s.d. standard, le s.d tardif améliore la précision du test. Cette amélioration est obtenue tout en maintenant ViT-B ou en augmentant la perte d'entraînement du Mixer-B, ce qui indique que le sd tardif réduit efficacement le surapprentissage.
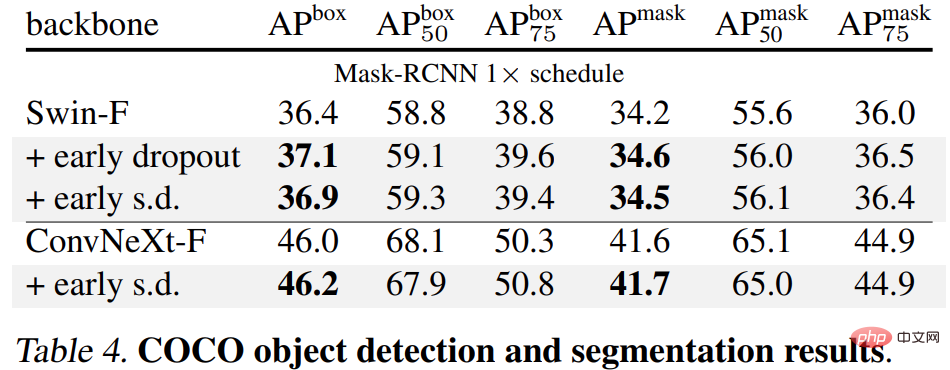
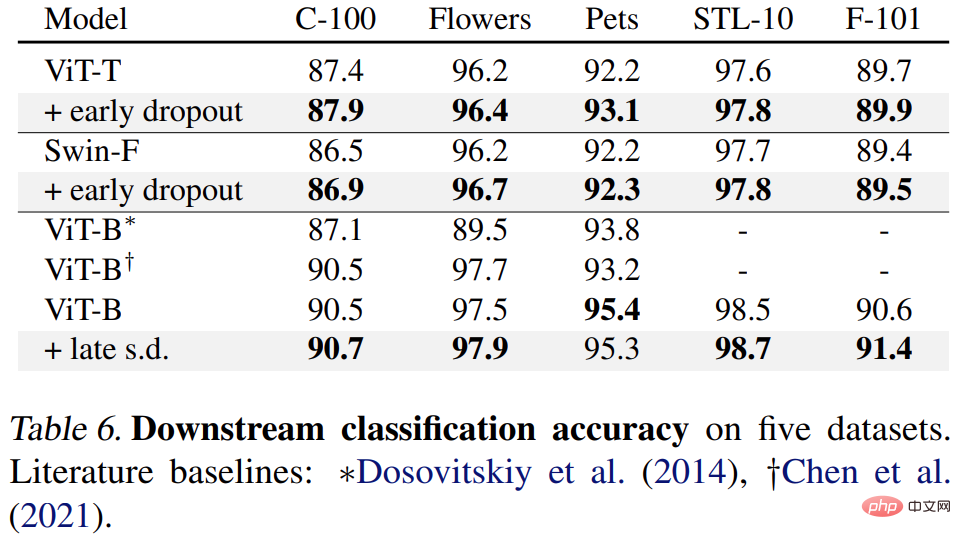
Enfin, les chercheurs ont affiné les modèles ImageNet-1K pré-entraînés sur les tâches en aval et les ont évalués. Les tâches en aval incluent la détection et la segmentation d'objets COCO, la segmentation sémantique ADE20K et la classification en aval sur cinq ensembles de données, dont C-100. L’objectif est d’évaluer la représentation apprise lors de la phase de réglage fin sans utiliser d’abandon précoce ou d’abandon tardif.
Les résultats sont présentés dans les tableaux 4, 5 et 6 ci-dessous. Premièrement, lorsqu'il est affiné sur COCO, le modèle pré-entraîné à l'aide d'un abandon précoce ou s.d. conserve toujours un avantage.
Deuxièmement, pour la tâche de segmentation sémantique ADE20K, le modèle pré-entraîné à l'aide de cette méthode est meilleur que le modèle de base.
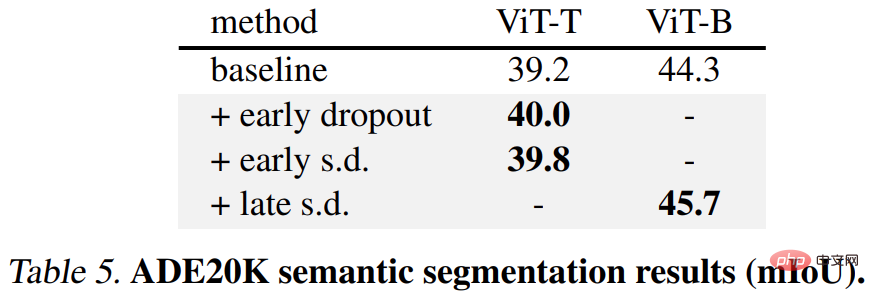
Enfin, il existe des tâches de classification en aval. Cette méthode améliore les performances de généralisation sur la plupart des tâches de classification.
Veuillez vous référer à l'article original pour plus de détails techniques et de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI