
Maison >Java >javaDidacticiel >Quel est le rôle de l'algorithme d'équilibrage de charge Java ?
Quel est le rôle de l'algorithme d'équilibrage de charge Java ?

- PHPzavant
- 2023-05-07 14:37:18898parcourir
Avant-propos
L'équilibrage de charge a des applications étendues et approfondies dans le domaine Java. Qu'il s'agisse du fameux nginx ou des composants de gouvernance des microservices tels que dubbo, feign, etc., les algorithmes d'équilibrage de charge y sont réellement utilisés
Le noyau. de l'équilibrage de charge L'idée réside dans l'idée d'algorithme sous-jacente. Par exemple, les algorithmes bien connus incluent l'interrogation, l'aléatoire, la connexion minimale, l'interrogation pondérée, etc. En réalité, quelle que soit la façon dont il est configuré, il ne peut pas se passer des principes de base. de son algorithme. Les éléments suivants seront combinés avec le code réel pour créer des résumés complets des algorithmes d'équilibrage de charge couramment utilisés.
Algorithme de sondage
Le sondage consiste à aligner une file d'attente et à se relayer l'un après l'autre. De la structure des données, il existe un nœud en forme d'anneau, recouvert de serveurs. Les serveurs sont connectés bout à bout et sont séquentiels. Lorsqu'une requête arrive, le serveur d'un certain nœud commence à répondre. Puis la prochaine fois que la requête arrive, les serveurs suivants répondront à leur tour et continueront à partir de là
Selon cette description, nous pouvons facilement imaginer que nous pouvons utiliser une structure de données de liste chaînée bidirectionnelle (extrémité bidirectionnelle) pour simuler et implémenter cet algorithme
1 Définir une classe de serveur pour identifier les nœuds de liste chaînée dans le serveur
class Server {
Server prev;
Server next;
String name;
public Server(String name) {
this.name = name;
}
}2. Combiné avec des commentaires pour comprendre le code, ceci L'explication de ce code est d'examiner les capacités sous-jacentes des listes chaînées à double extrémité, lors de l'exploitation de la structure de liste chaînée, la chose la plus importante est de clarifier le pointage vers l'avant et vers l'arrière des nœuds. ajouter et supprimer des nœuds, puis comprendre ce code. Il n'y a plus de difficulté. Exécutez le programme ci-dessous

- La machine est simple à mettre en œuvre. La liste peut être ajoutée ou soustraite librement. La complexité du temps de recherche des nœuds est o(1)
- Aucune personnalisation biaisée ne peut être effectuée pour les nœuds. Par exemple, certains serveurs avec de fortes capacités de traitement et des configurations élevées. Je veux supporter plus de demandes. Cela ne peut pas être fait
- algorithme aléatoire
de Une réponse est fournie au hasard à partir de la liste des serveurs disponibles.
Comme il s'agit d'un scénario d'accès aléatoire, il est facile de penser que l'utilisation d'un tableau peut effectuer une lecture aléatoire plus efficacement via des indices. La simulation de cet algorithme est relativement simple. Le code est directement affiché ci-dessous
Exécutez le code. et observez les résultats :
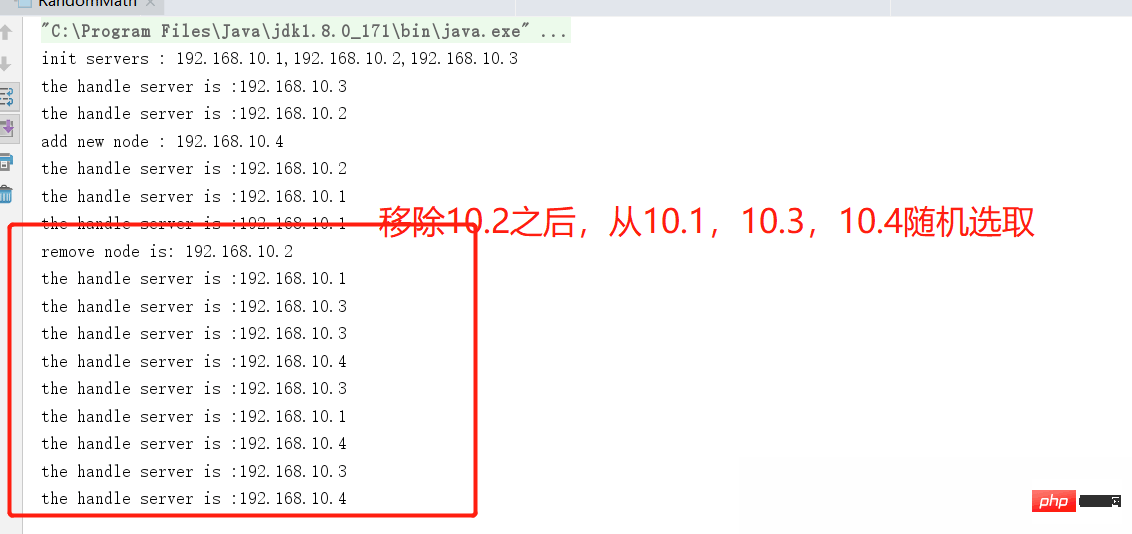 Résumé de l'algorithme aléatoire
Résumé de l'algorithme aléatoire
L'algorithme aléatoire est simple et efficace
- Il convient à un cluster de serveurs où la configuration de chaque machine est similaire comme le sondage. , il est impossible de faire des distinctions directionnelles basées sur la configuration de chaque serveur lui-même. Treat
- Algorithme aléatoire pondéré
/**
* 轮询
*/
public class RData {
private static Logger logger = LoggerFactory.getLogger(RData.class);
//标识当前服务节点,每次请求过来时,返回的是current节点
private Server current;
public RData(String serverName) {
logger.info("init servers : " + serverName);
String[] names = serverName.split(",");
for (int i = 0; i < names.length; i++) {
Server server = new Server(names[i]);
//当前为空,说明首次创建
if (current == null) {
//current就指向新创建server
this.current = server;
//同时,server的前后均指向自己
current.prev = current;
current.next = current;
} else {
//说明已经存在机器了,则按照双向链表的功能,进行节点添加
addServer(names[i]);
}
}
}
//添加机器节点
private void addServer(String serverName) {
logger.info("add new server : " + serverName);
Server server = new Server(serverName);
Server next = this.current.next;
//在当前节点后插入新节点
this.current.next = server;
server.prev = this.current;
//由于是双向链表,修改下一节点的prev指针
server.next = next;
next.prev = server;
}
//机器节点移除,修改节点的指向即可
private void removeServer() {
logger.info("remove current = " + current.name);
this.current.prev.next = this.current.next;
this.current.next.prev = this.current.prev;
this.current = current.next;
}
//请求。由当前节点处理
private void request() {
logger.info("handle server is : " + this.current.name);
this.current = current.next;
}
public static void main(String[] args) throws Exception {
//初始化两台机器
RData rr = new RData("192.168.10.0,192.168.10.1");
new Thread(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
rr.request();
}
}
}).start();
//3s后,3号机器加入清单
Thread.currentThread().sleep(2000);
rr.addServer("192.168.10.3");
//3s后,当前服务节点被移除
Thread.currentThread().sleep(3000);
rr.removeServer();
}
}
Autant ajuster la valeur de poids de 10,1 à une valeur plus grande, par exemple à 3, et l'exécuter à nouveau, l'effet sera plus évident
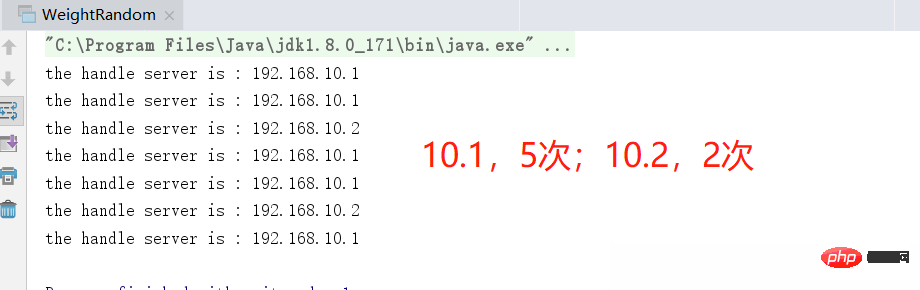

est la mise à niveau et l'optimisation de l'algorithme aléatoire
- Résolu le problème du biais des nœuds de serveur dans une certaine mesure et peut améliorer le biais de une certaine machine en spécifiant des poids
- Algorithme d'interrogation pondéréDans l'algorithme d'interrogation précédent, nous avons vu que l'interrogation n'est qu'une rotation mécanique qui se déplace continuellement dans une liste chaînée bidirectionnelle, tandis que l'interrogation pondérée compense les lacunes de toutes les machines étant traitées de la même manière. Sur la base du polling, lorsque le serveur est initialisé, chaque machine porte une valeur de poids
L'idée de l'algorithme du polling pondéré n'est pas très simple à comprendre, je vais l'expliquer avec un schéma ci-dessous :
.
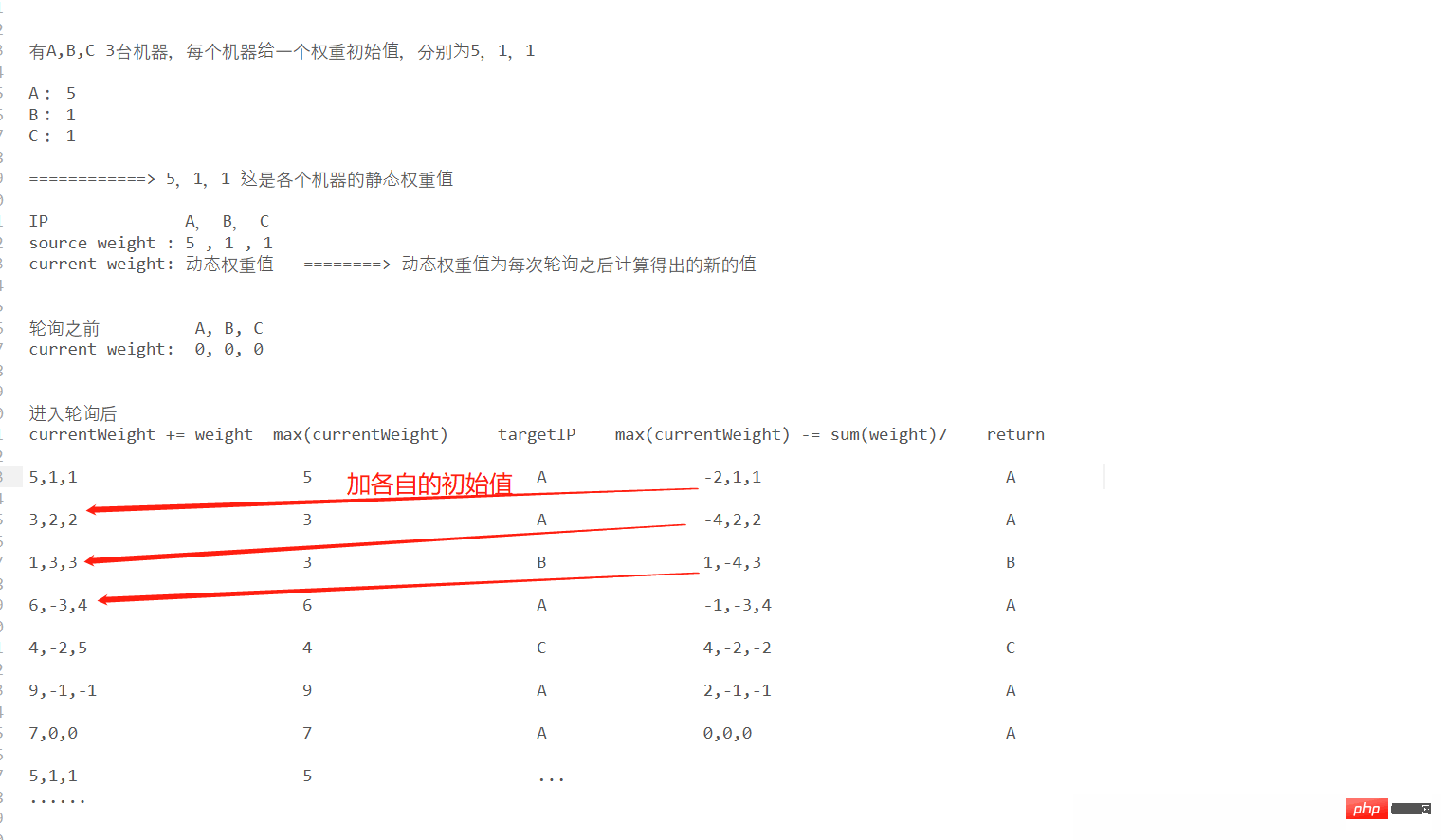
 L'intention initiale de l'algorithme d'interrogation pondéré est d'assurer la fluidité globale de la demande grâce à un tel ensemble d'algorithmes. On peut également constater à partir de la figure ci-dessus qu'après plusieurs séries de cycles, vous pouvez revenir au. résultat original, et dans un certain sondage, différentes machines ont des probabilités différentes de lecture des requêtes en fonction de différentes valeurs de poids
L'intention initiale de l'algorithme d'interrogation pondéré est d'assurer la fluidité globale de la demande grâce à un tel ensemble d'algorithmes. On peut également constater à partir de la figure ci-dessus qu'après plusieurs séries de cycles, vous pouvez revenir au. résultat original, et dans un certain sondage, différentes machines ont des probabilités différentes de lecture des requêtes en fonction de différentes valeurs de poids
实现思路和轮询差不多,整体仍然是链表结构,不同的是,每个具体的节点需加上权重值属性
1、节点属性类
class NodeServer {
int weight;
int currentWeight;
String ip;
public NodeServer(String ip, int weight) {
this.ip = ip;
this.weight = weight;
this.currentWeight = 0;
}
@Override
public String toString() {
return String.valueOf(currentWeight);
}
}2、核心代码
/**
* 加权轮询
*/
public class WeightRDD {
//所有机器节点列表
ArrayList<NodeServer> list;
//总权重
int total;
//机器节点初始化 , 格式:a#4,b#2,c#1,实际操作时可根据自己业务定制
public WeightRDD(String nodes) {
String[] ns = nodes.split(",");
list = new ArrayList<>(ns.length);
for (String n : ns) {
String[] n1 = n.split("#");
int weight = Integer.valueOf(n1[1]);
list.add(new NodeServer(n1[0], weight));
total += weight;
}
}
public NodeServer getCurrent() {
for (NodeServer node : list) {
node.currentWeight += node.weight;
}
NodeServer current = list.get(0);
int i = 0;
//从列表中获取当前的currentWeight最大的那个作为待响应的节点
for (NodeServer node : list) {
if (node.currentWeight > i) {
i = node.currentWeight;
current = node;
}
}
return current;
}
//请求,每次得到请求的节点之后,需要对当前的节点的currentWeight值减去 sumWeight
public void request() {
NodeServer node = this.getCurrent();
System.out.print(list.toString() + "‐‐‐");
System.out.print(node.ip + "‐‐‐");
node.currentWeight -= total;
System.out.println(list);
}
public static void main(String[] args) throws Exception {
WeightRDD wrr = new WeightRDD("192.168.10.1#4,192.168.10.2#2,192.168.10.3#1");
//7次执行请求,观察结果
for (int i = 0; i < 7; i++) {
Thread.currentThread().sleep(2000);
wrr.request();
}
}
}从打印输出结果来看,也是符合预期效果的,具有更大权重的机器,在轮询中被请求到的可能性更大

源地址hash算法
即对当前访问的ip地址做一个hash值,相同的key将会被路由到同一台机器去。常见于分布式集群环境下,用户登录 时的请求路由和会话保持
源地址hash算法可以有效解决在跨地域机器部署情况下请求响应的问题,这一特点使得源地址hash算法具有某些特殊的应用场景
该算法的核心逻辑是需要自定义一个能结合实际业务场景的hash算法,从而确保请求能够尽可能达到源IP机器进行处理
源地址hash算法的实现比较简单,下面直接上代码
/**
* 源地址请求hash
*/
public class SourceHash {
private static List<String> ips;
//节点初始化
public SourceHash(String nodeNames) {
System.out.println("init list : " + nodeNames);
String[] nodes = nodeNames.split(",");
ips = new ArrayList<>(nodes.length);
for (String node : nodes) {
ips.add(node);
}
}
//添加节点
void addnode(String nodeName) {
System.out.println("add new node : " + nodeName);
ips.add(nodeName);
}
//移除节点
void remove(String nodeName) {
System.out.println("remove one node : " + nodeName);
ips.remove(nodeName);
}
//ip进行hash
private int hash(String ip) {
int last = Integer.valueOf(ip.substring(ip.lastIndexOf(".") + 1, ip.length()));
return last % ips.size();
}
//请求模拟
void request(String ip) {
int i = hash(ip);
System.out.println("req ip : " + ip + "‐‐>" + ips.get(i));
}
public static void main(String[] args) throws Exception {
SourceHash hash = new SourceHash("192.168.10.1,192.168.10.2");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
Thread.sleep(3000);
System.out.println();
hash.addnode("192.168.10.3");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
Thread.sleep(3000);
System.out.println();
hash.remove("192.168.10.1");
for (int i = 1; i < 10; i++) {
String ip = "192.168.1." + i;
hash.request(ip);
}
}
}请关注核心的方法 hash(),我们模拟9个随机请求的IP,下面运行下这段程序,观察输出结果
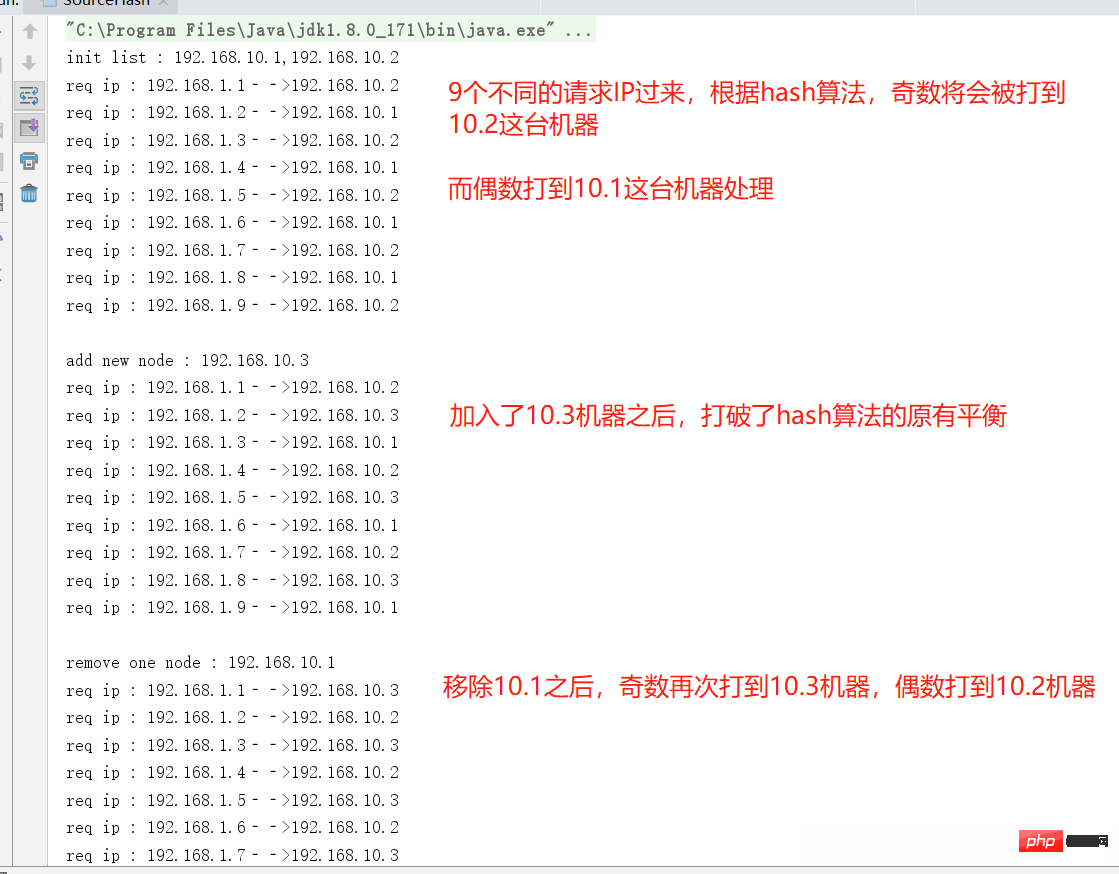
源地址hash算法小结
可以有效匹配同一个源IP从而定向到特定的机器处理
如果hash算法不够合理,可能造成集群中某些机器压力非常大
未能很好的解决新节点加入之后打破原来的请求平衡(一致性hash可解决)
最小请求数算法
即通过统计当前机器的请求连接数,选择当前连接数最少的机器去响应新请求。前面的各种算法是基于请求的维度,而最小 连接数则是站在机器的连接数量维度
从描述来看,实现这种算法需要定义一个链接表记录机器的节点IP,和机器连接数量的计数器
而为了比较并选择出最小的连接数的机器,内部采用最小堆做排序处理,请求响应时取堆顶节点即是 最小连接数(可以参考最小顶堆算法)
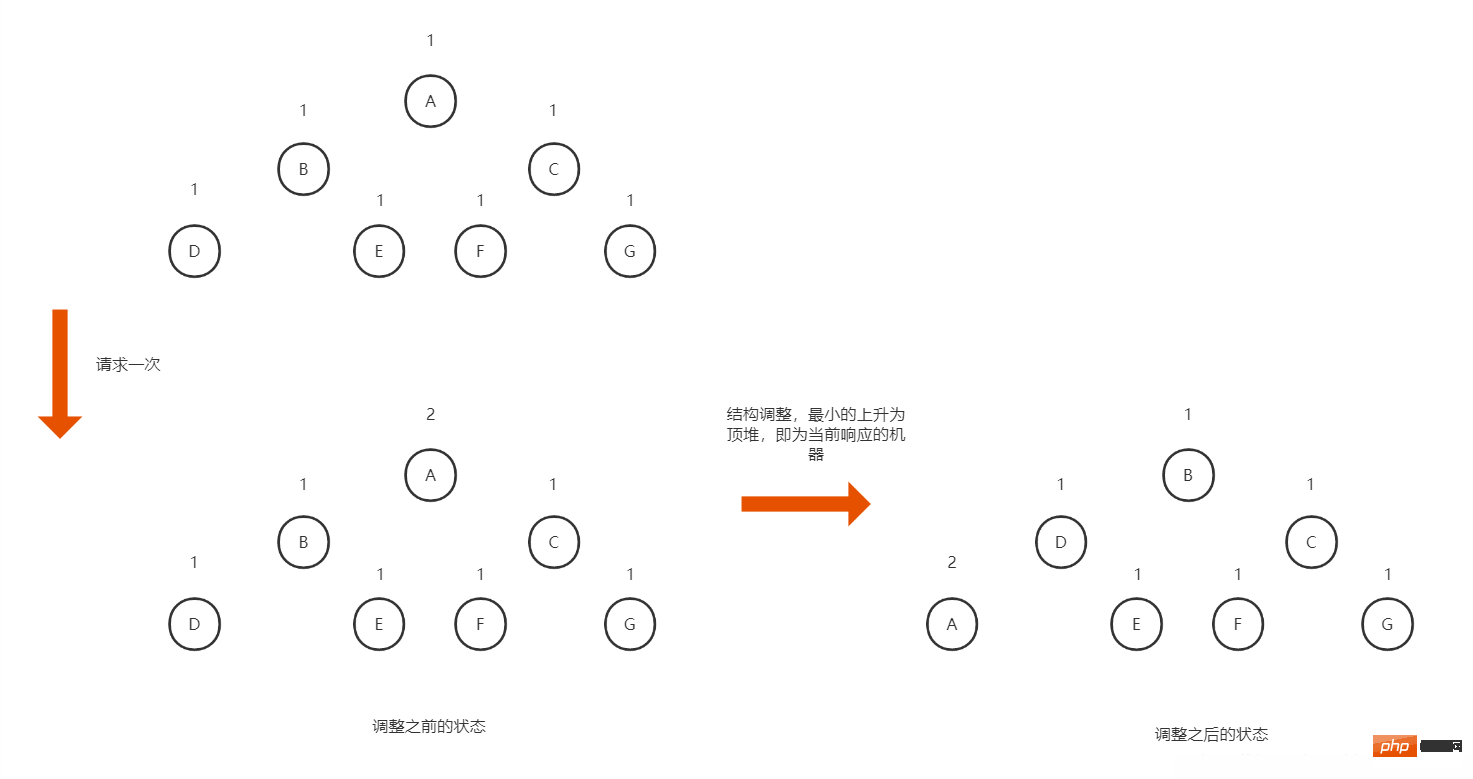
如图所示,所有机器列表按照类二叉树的结构进行组装,组装的依据按照不同节点的访问次数,某次请求过来时,选择堆顶的元素(待响应的机器)返回,然后堆顶机器的请求数量加1,然后通过算法将这个堆顶的元素下沉,把请求数量最小的元素上升为堆顶,以便下次响应最新的请求
1、机器节点
该类记录了节点的IP以及连接数
class Node {
String name;
AtomicInteger count = new AtomicInteger(0);
public Node(String name) {
this.name = name;
}
public void inc() {
count.getAndIncrement();
}
public int get() {
return count.get();
}
@Override
public String toString() {
return name + "=" + count;
}
}2、核心代码
/**
* 最小连接数算法
*/
public class LeastRequest {
Node[] nodes;
//节点初始化
public LeastRequest(String ns) {
String[] ns1 = ns.split(",");
nodes = new Node[ns1.length + 1];
for (int i = 0; i < ns1.length; i++) {
nodes[i + 1] = new Node(ns1[i]);
}
}
///节点下沉,与左右子节点比对,选里面最小的交换
//目的是始终保持最小堆的顶点元素值最小【结合图理解】
//ipNum:要下沉的顶点序号
public void down(int ipNum) {
//顶点序号遍历,只要到1半即可,时间复杂度为O(log2n)
while (ipNum << 1 < nodes.length) {
int left = ipNum << 1;
//右子,左+1即可
int right = left + 1;
int flag = ipNum;
//标记,指向 本节点,左、右子节点里最小的,一开始取自己
if (nodes[left].get() < nodes[ipNum].get()) {
flag = left;
}
//判断右子
if (right < nodes.length && nodes[flag].get() > nodes[right].get()) {
flag = right;
}
//两者中最小的与本节点不相等,则交换
if (flag != ipNum) {
Node temp = nodes[ipNum];
nodes[ipNum] = nodes[flag];
nodes[flag] = temp;
ipNum = flag;
} else {
//否则相等,堆排序完成,退出循环即可
break;
}
}
}
//请求,直接取最小堆的堆顶元素就是连接数最少的机器
public void request() {
System.out.println("‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐");
//取堆顶元素响应请求
Node node = nodes[1];
System.out.println(node.name + " accept");
//连接数加1
node.inc();
//排序前的堆
System.out.println("ip list before:" + Arrays.toString(nodes));
//堆顶下沉,通过算法将堆顶下层到合适的位置
down(1);
//排序后的堆
System.out.println("ip list after:" + Arrays.toString(nodes));
}
public static void main(String[] args) {
//假设有7台机器
LeastRequest lc = new LeastRequest("10.1,10.2,10.3,10.4,10.5,10.6,10.7");
//模拟10个请求连接
for (int i = 0; i < 10; i++) {
lc.request();
}
}
}请关注 down 方法,该方法是实现每次请求之后,将堆顶元素进行移动的关键实现,运行这段代码,结合输出结果进行理解


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- How do I create and use custom Java libraries (JAR files) with proper versioning and dependency management?
- Comment fonctionne le mécanisme de chargement de classe de Java, y compris différents chargeurs de classe et leurs modèles de délégation?
- Comment puis-je utiliser JPA (Java Persistance API) pour la cartographie relationnelle des objets avec des fonctionnalités avancées comme la mise en cache et le chargement paresseux?
- Comment implémenter la mise en cache à plusieurs niveaux dans les applications Java à l'aide de bibliothèques comme la caféine ou le cache de goyave?
- Comment utiliser Maven ou Gradle pour la gestion avancée de projet Java, la création d'automatisation et la résolution de dépendance?