
Maison >Périphériques technologiques >IA >Améliorez les performances de l'IA de bout en bout grâce à une fusion d'opérateurs personnalisée
Améliorez les performances de l'IA de bout en bout grâce à une fusion d'opérateurs personnalisée

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-06 15:52:081223parcourir
L'optimisation des graphiques joue un rôle important dans la réduction du temps et des ressources utilisés par la formation et l'inférence des modèles d'IA. Une fonction importante de l'optimisation des graphes consiste à fusionner les opérateurs qui peuvent être fusionnés dans le modèle, améliorant ainsi l'efficacité du calcul en réduisant l'utilisation de la mémoire et le transfert de données dans la mémoire à faible vitesse. Cependant, il est très difficile de mettre en œuvre une solution back-end capable de fournir diverses fusions d'opérateurs, ce qui entraîne des fusions d'opérateurs très limitées pouvant être utilisées par les modèles d'IA sur le matériel réel.
La bibliothèque Composable Kernel (CK) a pour objectif de fournir un ensemble de solutions back-end pour la fusion d'opérateurs sur les GPU AMD. CK utilise le langage de programmation généraliste HIP C++ et est entièrement open source. Ses concepts de conception incluent :
- Hautes performances et haute productivité : le cœur de CK est un ensemble de modules de base soigneusement conçus, hautement optimisés et réutilisables. Tous les opérateurs de la bibliothèque CK sont implémentés en combinant ces modules de base. La réutilisation de ces modules de base raccourcit considérablement le cycle de développement des algorithmes back-end tout en garantissant des performances élevées.
- Maîtrisez les problèmes d'IA actuels et adaptez-vous rapidement aux problèmes d'IA futurs : CK vise à fournir un ensemble complet de solutions backend d'opérateur d'IA, ce qui rend possible la fusion d'opérateurs complexes, car cela permet à l'ensemble du backend d'être implémenté à l'aide de CK sans compter sur les bibliothèques d'opérateurs externes. Les modules de base réutilisables de CK sont suffisants pour mettre en œuvre différents opérateurs et leur fusion requis par les modèles d'IA courants (vision industrielle, traitement du langage naturel, etc.). Lorsque les modèles d’IA émergents nécessitent de nouveaux opérateurs, CK fournira également les modules de base requis.
- Un outil simple mais puissant pour les experts en systèmes d'IA : CK Tous les opérateurs sont implémentés à l'aide de modèles HIP C++. Les experts en systèmes d'IA peuvent personnaliser les propriétés de ces opérateurs via des modèles d'instanciation, tels que le type de données, le type de méta-opération, le format de stockage tensoriel, etc. Cela ne nécessite généralement que quelques lignes de code.
- Interface HIP C++ conviviale : les développeurs d'algorithmes HPC ont repoussé les limites de l'accélération informatique de l'IA. Un concept de conception important de CK est de permettre aux développeurs d’algorithmes HPC de contribuer plus facilement à l’accélération de l’IA. Par conséquent, tous les modules de base de CK sont implémentés en HIP C++ au lieu de la représentation intermédiaire (IR). Les développeurs d'algorithmes HPC peuvent écrire des algorithmes directement sous la forme avec laquelle ils sont habitués à écrire du code C++, sans avoir à écrire un Compiler Pass pour un algorithme spécifique, comme c'est le cas avec les bibliothèques d'opérateurs basées sur IR. Cela peut grandement améliorer la vitesse d’itération de l’algorithme.
- Portabilité : l'optimisation graphique d'aujourd'hui utilisant CK comme backend pourra être portée sur tous les futurs GPU AMD, et sera éventuellement portée sur les processeurs AMD [2].
- Code source de CK : https://github.com/ROCmSoftwarePlatform/composable_kernel
Core Concepts
CK introduit deux concepts pour améliorer la productivité des développeurs backend :
1 . l'introduction de la « transformation de coordonnées tensorielles » réduit la complexité de l'écriture des opérateurs d'IA. Cette recherche a été pionnière dans la définition d'un ensemble de modules de base réutilisables de transformation de coordonnées tensorielles et les a utilisés pour réexprimer des opérateurs d'IA complexes (tels que la convolution, la réduction de normalisation de groupe, Depth2Space, etc.) d'une manière mathématiquement rigoureuse dans l'IA la plus élémentaire. opérateurs (GEMM, réduction 2D, transfert tensoriel, etc.). Cette technologie permet aux algorithmes écrits pour les opérateurs d’IA de base d’être directement utilisés sur tous les opérateurs d’IA complexes correspondants sans avoir à réécrire l’algorithme.
2. Paradigme de programmation basé sur les tuiles : le développement de l'algorithme back-end pour la fusion d'opérateurs peut être considéré comme un premier démantèlement de chaque opérateur de pré-fusion (opérateur indépendant) en de nombreux "petits morceaux" d'opérations de données. " Les opérations sont ensuite regroupées en opérateurs fusionnés. Chacune de ces opérations de « petit bloc » correspond à un opérateur indépendant d'origine, mais les données exploitées ne sont qu'une partie (tuile) du tenseur d'origine, donc une telle opération de « petit bloc » est appelée un opérateur de tenseur de tuile. La bibliothèque CK contient un ensemble d'implémentations hautement optimisées de Tile Tensor Operator, et tous les opérateurs indépendants de l'IA et les opérateurs de fusion dans CK sont implémentés en les utilisant. Actuellement, ces opérateurs de tenseur de tuiles incluent Tile GEMM, Tile Reduction et Tile Tensor Transfer. Chaque opérateur Tile Tensor a des implémentations pour les blocs de threads GPU, les déformations et les threads.
La transformation des coordonnées du tenseur et l'opérateur du tenseur des tuiles forment ensemble le module de base réutilisable de CK.
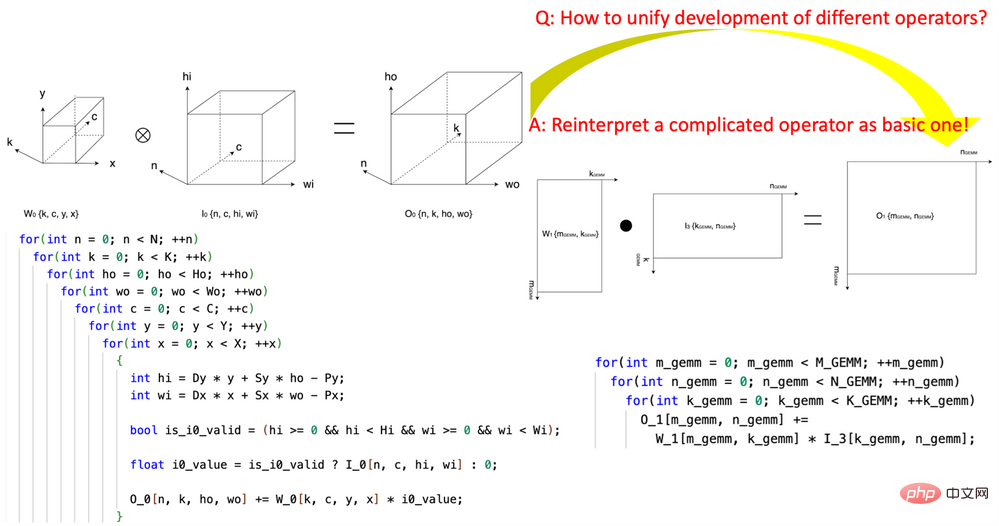
Figure 1, utilisant le module de base de transformation de coordonnées tensorielles de CK pour exprimer l'opérateur de convolution en un opérateur GEMM
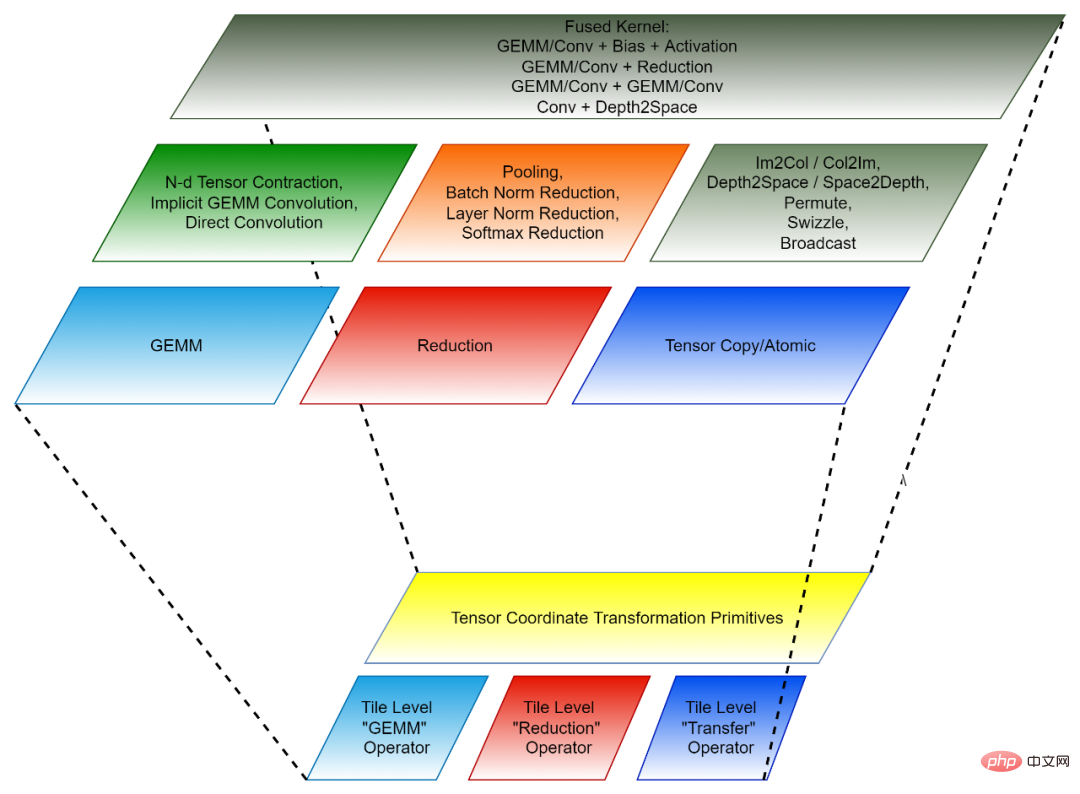
Figure 2, la composition de CK (en bas : réutilisable La base module de l'API Invoker et Client [3]. Chaque couche correspond à différents développeurs.
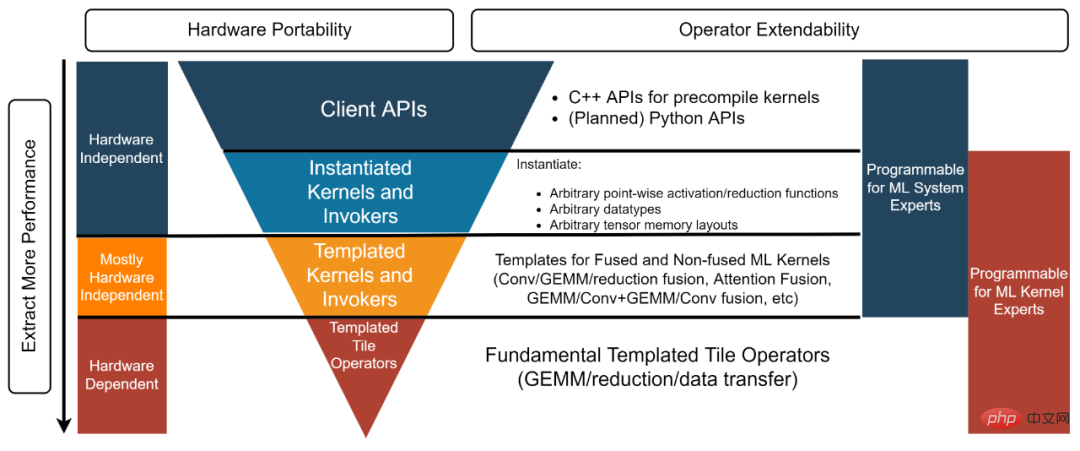
Expert en système IA : "J'ai besoin d'une solution back-end qui fournit des opérateurs indépendants et fusionnés performants que je peux utiliser directement." L'API client et le noyau instancié et l'invoker utilisés dans cet exemple [4] fournissent des objets pré-instanciés et compilés pour répondre aux besoins de ce type de développeur.
Expert en système d'IA : "Je réalise un travail d'optimisation de graphes de pointe pour un framework d'IA open source. J'ai besoin d'une solution backend capable de fournir un noyau hautes performances pour tous les opérateurs de fusion requis pour l'optimisation des graphes. En même temps, ces noyaux doivent être personnalisés, donc une solution boîte noire du type « à prendre ou à laisser » ne répond pas à mes besoins. Les couches Templated Kernel et Invoker satisfont ce type de développeur. Par exemple, dans cet exemple [5], les développeurs peuvent utiliser la couche Templated Kernel et Invoker pour instancier le noyau FP16 GEMM + Add + Add + FastGeLU requis.
- Expert en algorithmes HPC : « Mon équipe développe des algorithmes back-end hautes performances pour les modèles d'IA qui itèrent constamment au sein de l'entreprise. Nous avons des experts en algorithmes HPC dans l'équipe, mais nous espérons toujours les réutiliser et les améliorer. les algorithmes fournis par les fournisseurs de matériel. Code source hautement optimisé pour augmenter notre productivité et permettre à notre code d'être porté sur les futures architectures matérielles. Nous espérons pouvoir le faire sans avoir à partager notre code avec les fournisseurs de matériel. La couche Templated Tile Operator peut aider ce type de développeur. Par exemple, dans ce code [6], le développeur utilise Templated Tile Operator pour implémenter le pipeline d'optimisation GEMM.
- Figure 3, structure à quatre couches de la bibliothèque CK
Raisonnement de modèle de bout en bout basé sur AITemplate + CK AITemplate de Meta [7] (AIT) est un modèle unifié Système d'inférence AMD et AI pour les GPU Nvidia. AITemplate utilise CK comme backend sur les GPU AMD, en utilisant la couche Templated Kernel et Invoker de CK.
AITemplate + CK atteint des performances d'inférence de pointe sur plusieurs modèles d'IA importants sur AMD Instinct™ MI250. La définition des opérateurs de fusion les plus avancés dans CK est motivée par la vision de l'équipe AITemplate. De nombreux algorithmes d’opérateurs de fusion sont également conçus conjointement par les équipes CK et AITemplate.Cet article compare les performances de plusieurs modèles de bout en bout sur AMD Instinct MI250 et produits similaires [8]. Toutes les données de performances du modèle AMD Instinct MI250 AI dans cet article ont été obtenues à l'aide de AITemplate[9] + CK[10].
Expérience
ResNet-50
L'image ci-dessous montre AIT + CK sur AMD Instinct MI250 avec TensorRT v8.5.0.12 sur A100-PCIe-40GB et A100-DGX-80GB [11 ] ( TRT) comparaison des performances. Les résultats montrent que AIT + CK sur AMD Instinct MI250 a atteint une accélération de 1,08x par rapport à TRT sur A100-PCIe-40GB.
BERT
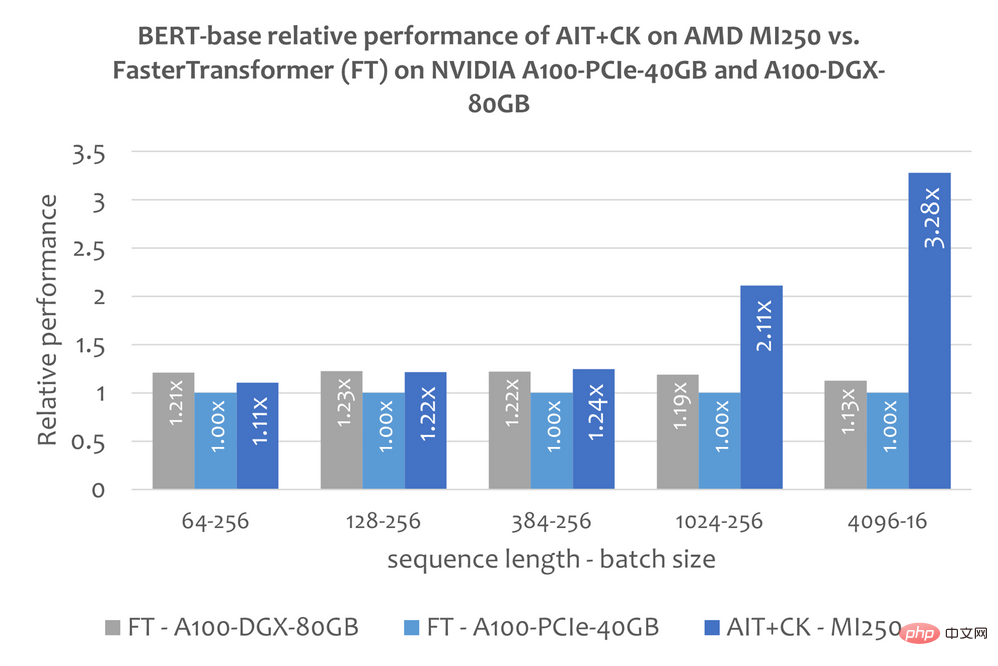
Un modèle d'opérateur de fusion Batched GEMM + Softmax + GEMM implémenté sur la base de CK, qui peut éliminer complètement le transfert de résultats intermédiaires entre l'unité de calcul GPU (Compute Unit) et HBM. En utilisant ce modèle d'opérateur de fusion, de nombreux problèmes dans la couche d'attention qui étaient à l'origine liés à la bande passante sont devenus des goulots d'étranglement informatiques (liés au calcul), qui peuvent mieux utiliser la puissance de calcul du GPU. Cette implémentation de CK est profondément inspirée de FlashAttention [12] et réduit davantage la gestion des données que l'implémentation originale de FlashAttention.
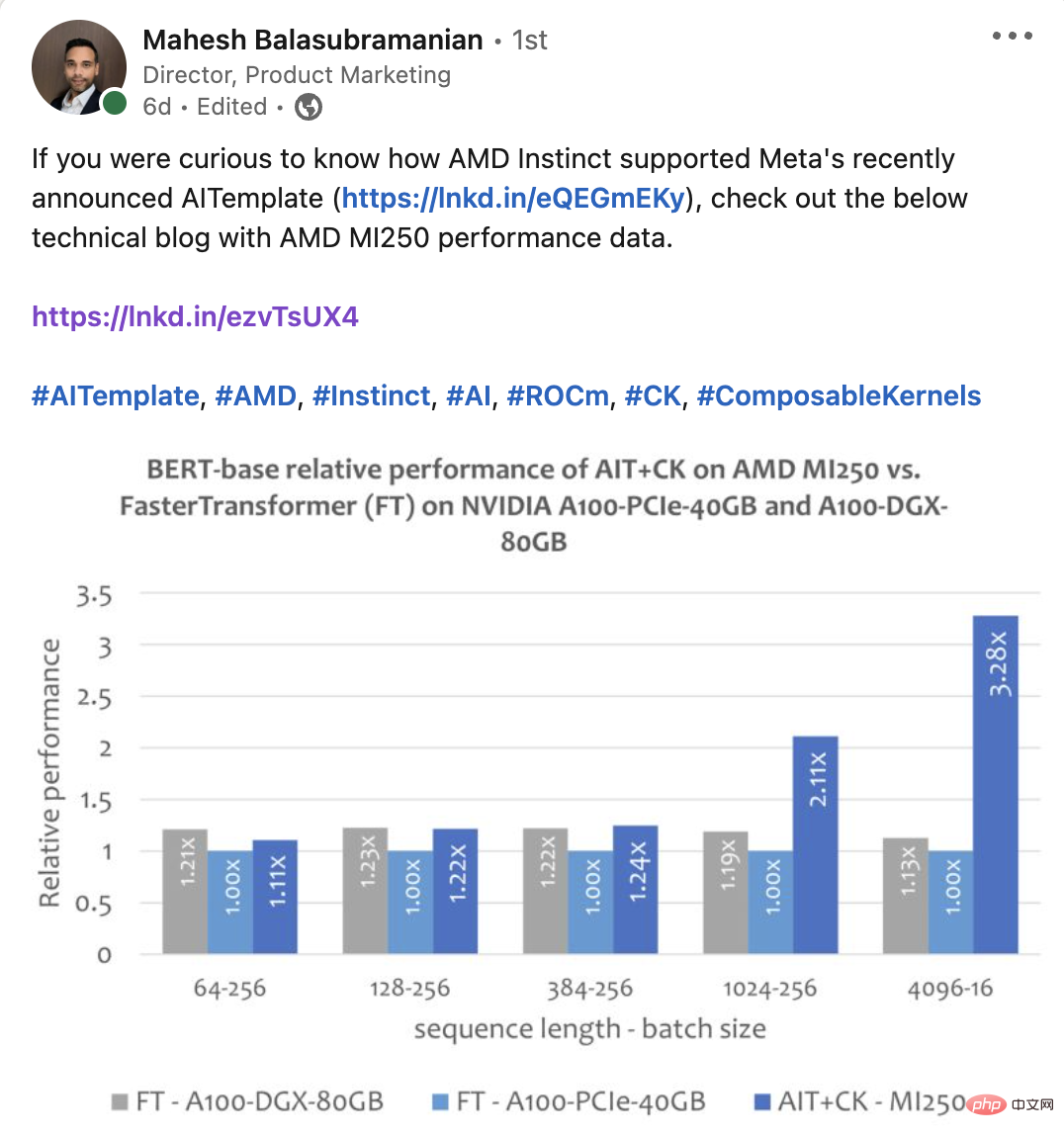
L'image ci-dessous montre le modèle Bert Base (non boîtier) d'AIT + CK sur AMD Instinct MI250 et la correction de bug FasterTransformer v5.1.1 [13] (FT) sur A100-PCIe-40GB et A100-DGX-80GB Comparaison des performances . FT débordera de la mémoire GPU au lot 32 sur A100-PCIe-40GB et A100-DGX-80GB lorsque la séquence est de 4096. Par conséquent, lorsque la séquence est 4 096, cet article affiche uniquement les résultats du lot 16. Les résultats montrent que AIT + CK sur AMD Instinct MI250 atteint une accélération FT de 3,28x par rapport à FT sur A100-PCIe-40GB et une accélération FT de 2,91x par rapport à A100-DGX-80GB.
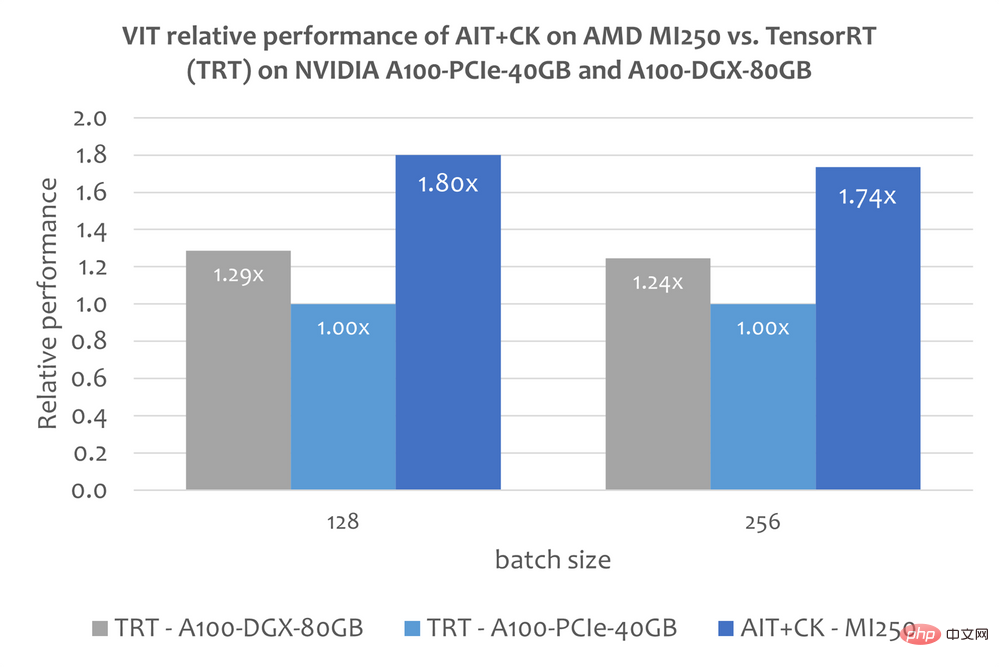
Vision Transformer (VIT)
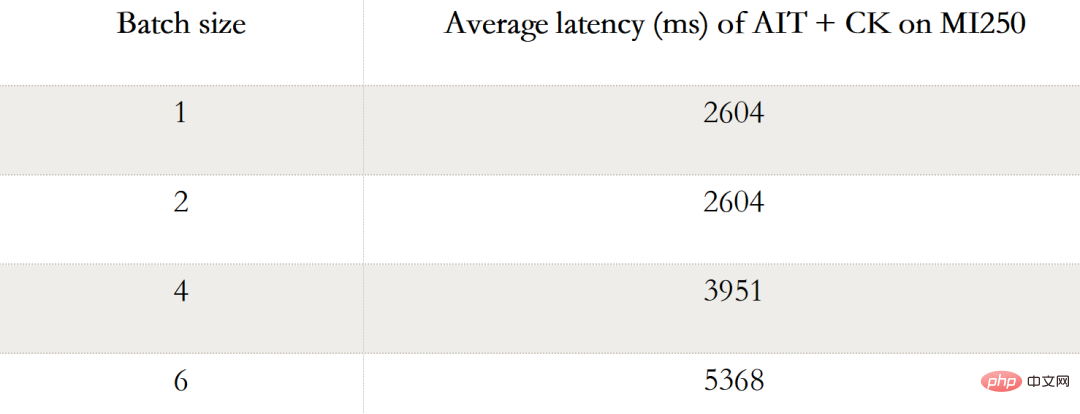
L'image ci-dessous montre AIT + CK sur AMD Instinct MI250 avec TensorRT v8.5.0.12 sur A100-PCIe-40GB et A100-DGX-80GB Comparaison des performances de Vision Transformer Base (image 224x224) de (TRT). Les résultats montrent que AIT + CK sur AMD Instinct MI250 atteint une accélération de 1,8x par rapport au TRT sur A100-PCIe-40GB et une accélération de 1,4x par rapport à TRT sur A100-DGX-80GB. DIFUSION STABLE DIFUSION-TO-TO-TO END Le tableau suivant montre la diffusion stable STABLE AIT + CK de bout en bout sur AMD Instinct MI250 (lot 1, 2, 4, 6 ) données de performances. Lorsque le lot est 1, un seul GCD est utilisé sur le MI250, tandis que dans les lots 2, 4 et 6, les deux GCD sont utilisés.
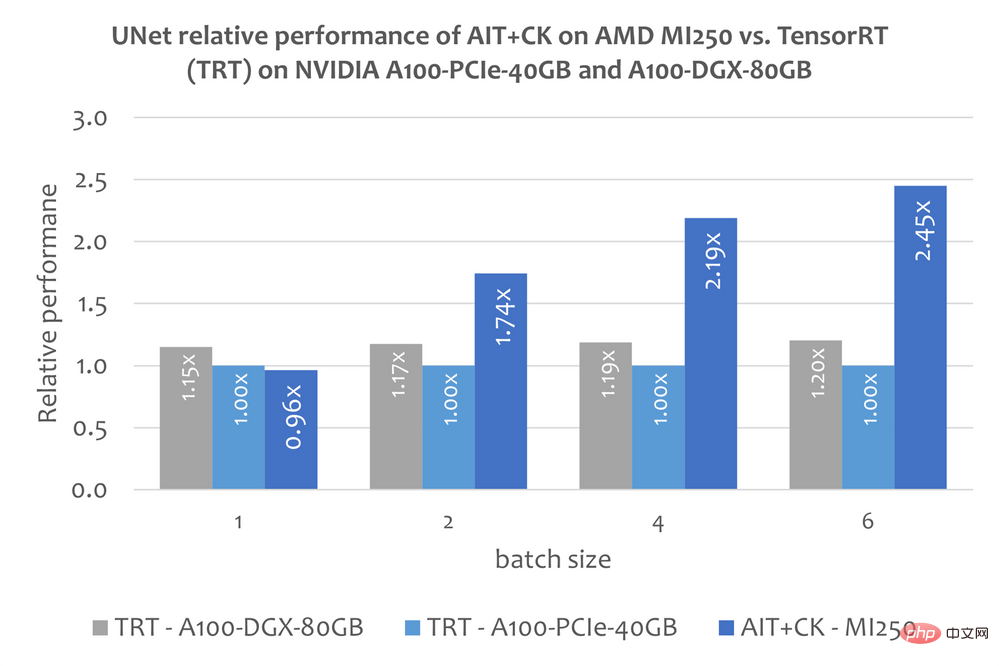
UNet en diffusion stable
Cependant, cet article ne contient pas d'informations publiques sur l'utilisation de TensorRT pour exécuter le modèle de bout en bout de diffusion stable. Mais cet article « Rendre la diffusion stable 25 % plus rapide avec TensorRT » [14] explique comment utiliser TensorRT pour accélérer le modèle UNet dans Stable Diffusion. UNet est la partie la plus importante et la plus longue de Stable Diffusion, de sorte que les performances de UNet reflètent à peu près les performances de Stable Diffusion.Le graphique ci-dessous montre la comparaison des performances de AIT + CK sur AMD Instinct MI250 avec UNet sur A100-PCIe-40GB et A100-DGX-80GB avec TensorRT v8.5.0.12 (TRT). Les résultats montrent que AIT + CK sur AMD Instinct MI250 atteint une accélération de 2,45x par rapport au TRT sur A100-PCIe-40GB et une accélération de 2,03x par rapport au TRT sur A100-DGX-80GB.
Plus d'informations
Page Web ROCm : Plateforme logicielle ouverte AMD ROCm™ | AMD
Portail d'informations ROCm : Documentation AMD - Portail
 Accélérateurs AMD Instinct : AMD Instinct™ Jing Zhang est ingénieur de développement logiciel SMTS chez AMD. Leurs publications représentent leurs propres opinions et ne peuvent pas représenter les positions, stratégies ou opinions d'AMD. Les liens vers des sites tiers sont fournis pour des raisons de commodité et, sauf indication explicite, AMD n'est pas responsable du contenu de. ces sites liés et aucune approbation n'est implicite." API client »pour l'opérateur fusionné GEMM + Add + Add + FastGeLU. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
Accélérateurs AMD Instinct : AMD Instinct™ Jing Zhang est ingénieur de développement logiciel SMTS chez AMD. Leurs publications représentent leurs propres opinions et ne peuvent pas représenter les positions, stratégies ou opinions d'AMD. Les liens vers des sites tiers sont fournis pour des raisons de commodité et, sauf indication explicite, AMD n'est pas responsable du contenu de. ces sites liés et aucune approbation n'est implicite." API client »pour l'opérateur fusionné GEMM + Add + Add + FastGeLU. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
5.Exemple de CK « Modèle de noyau et d'invocateur » de GEMM + Ajouter + Ajouter + Opérateur de fusibles eLU. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
6.Exemple d'utilisation des primitives CK « Templated Tile Operator » pour écrire un pipeline GEMM. https://github.com/ROCmSoftwarePlatform/composable_kernel/blob/685860c2a9483c9e909d2f8bfb95056672491...
7.Le référentiel AITemplate GitHub de Meta. https://github.com/facebookincubator/AITemplate
8.MI200-71 : Tests effectués par AMD MLSE 10.23.22 à l'aide d'AITemplate https://github.com/ROCmSoftwarePlatform/AITemplate, commit f940d9b) + Composable Kernel https://github.com/ROCmSoftwarePlatform/composable_kernel, commit 40942b9) avec ROCm™5.3 fonctionnant sur 2 serveurs à processeur AMD EPYC 7713 64 cœurs avec 4 processeurs AMD Instinct MI250 OAM (128 Go HBM2e) 560 W avec AMD Infinity Fabric ™ par rapport à TensorRT v8.5.0.12 et FasterTransformer (correction de bug v5.1.1) avec CUDA® 11.8 fonctionnant sur 2 serveurs à processeur AMD EPYC 7742 64 cœurs avec 4 GPU Nvidia A100-PCIe-40 Go (250 W) et TensorRT v8. 5.0.12 et FasterTransformer (correction de bug v5.1.1) avec CUDA® 11.8 fonctionnant sur un serveur à processeur 2xAMD EPYC 7742 64 cœurs avec 8x GPU NVIDIA A100 SXM 80 Go (400 W). Les fabricants de serveurs peuvent varier les configurations, donnant des résultats différents. Les performances peuvent varier en fonction de facteurs tels que l'utilisation des derniers pilotes et optimisations.
9.https://github.com/ROCmSoftwarePlatform/AITemplate/tree/f940d9b7ac8b976fba127e2c269dc5b368f30e4e
10.https://github.com/ROCmSoftwarePlatform/composable_kernel/tree/40942b909801dd721769834fc61ad201b5795 ...
11.Référentiel TensorRT GitHub. https://github.com/NVIDIA/TensorRT
12.FlashAttention : Attention exacte rapide et économe en mémoire avec IO-Awareness. https://arxiv.org/abs/2205.14135
13.Dépôt GitHub de FasterTransformer. https://github.com/NVIDIA/FasterTransformer
14. Rendre la diffusion stable 25 % plus rapide grâce à TensorRT. https://www.photoroom.com/tech/stable-diffusion-25-percent-faster-and-save-seconds/
15.Pendant leur séjour chez AMD
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI