
Maison >développement back-end >Tutoriel Python >Comment utiliser des caractères génériques pour faire correspondre des chaînes en Python
Comment utiliser des caractères génériques pour faire correspondre des chaînes en Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-06 12:13:062218parcourir
Utilisez des caractères génériques pour faire correspondre les chaînes :
Utilisez la méthode
fnmatch.filter()pour obtenir une chaîne correspondant à un modèle dans une liste.fnmatch.filter()方法从列表中获取匹配模式的字符串。使用
fnmatch.fnmatch()方法检查字符串是否与模式匹配。
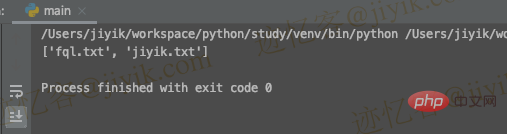
import fnmatch a_list = ['fql.txt', 'jiyik.txt', 'com.csv'] pattern = '*.txt' filtered_list = fnmatch.filter(a_list, pattern) print(filtered_list) # ????️ ['fql.txt', 'jiyik.txt']
如果我们更愿意使用正则表达式,请向下滚动到下一个副标题。
fnmatch.filter方法接受一个可迭代对象和一个模式,并返回一个新列表,该列表仅包含与提供的模式匹配的可迭代对象元素。
示例中的模式以任意一个或多个字符开头,以 .txt 结尾。
示例中的模式仅包含一个通配符,但您可以根据需要使用任意多个通配符。
请注意,星号
*匹配所有内容(一个或多个字符)。
如果要匹配任何单个字符,请将星号 * 替换为问号 ?。
*匹配所有内容(一个或多个字符)?匹配任何单个字符[sequence]匹配序列中的任意字符[!sequence]匹配任何不按顺序的字符
下面是使用问号匹配任何单个字符的示例。
import fnmatch a_list = ['abc', 'abz', 'abxyz'] pattern = 'ab?' filtered_list = fnmatch.filter(a_list, pattern) print(filtered_list) # ????️ ['abc', 'abz']
该模式匹配以 ab 开头后跟任何单个字符的字符串。
如果要使用通配符检查字符串是否与模式匹配,请使用 fnmatch.fnmatch() 方法。
import fnmatch
a_string = '2023_jiyik.txt'
pattern = '2023*.txt'
matches_pattern = fnmatch.fnmatch(a_string, pattern)
print(matches_pattern) # ????️ True
if matches_pattern:
# ????️ this runs
print('The string matches the pattern')
else:
print('The string does NOT match the pattern')该模式以 2023 开头,后跟任意一个或多个字符,并以 .txt 结尾。
fnmatch.fnmatch方法接受一个字符串和一个模式作为参数。如果字符串与模式匹配,则该方法返回 True,否则返回 False。只需将星号*替换为问号?如果您想匹配任何单个字符而不是任何一个或多个字符。
或者,我们可以使用正则表达式。
使用正则表达式使用通配符匹配字符串
使用通配符匹配字符串:
使用 re.match() 方法检查字符串是否匹配给定的模式。使用 .* 字符代替通配符。
import re
a_list = ['2023_fql.txt', '2023_jiyik.txt', '2023_com.csv']
regex = re.compile(r'2023_.*\.txt')
list_of_matches = [
item for item in a_list
if re.match(regex, item)
]
print(list_of_matches) # ????️ ['2023_fql.txt', '2023_jiyik.txt']re.compile 方法将正则表达式模式编译成一个对象,该对象可用于使用其 match() 或 search() 方法进行匹配。
这比直接使用 re.match 或 re.search 更有效,因为它保存并重用了正则表达式对象。
正则表达式以 2023_ 开头。
正则表达式中的
.*字符用作匹配任何一个或多个字符的通配符。
点
.匹配除换行符以外的任何字符。星号
*与前面的正则表达式(点.)匹配零次或多次。
我们使用反斜杠字符来转义点。 在扩展名中,因为正如我们之前看到的,点
.在正则表达式中使用时具有特殊含义。换句话说,我们使用反斜杠来处理点。 作为文字字符。
我们使用列表理解来迭代字符串列表。
列表推导用于对每个元素执行某些操作或选择满足条件的元素子集。
在每次迭代中,我们使用 re.match() 方法检查当前字符串是否与模式匹配。
import re
a_list = ['2023_fql.txt', '2023_jiyik.txt', '2023_com.csv']
regex = re.compile(r'2023_.*\.txt')
list_of_matches = [
item for item in a_list
if re.match(regex, item)
]
print(list_of_matches) # ????️ ['2023_fql.txt', '2023_jiyik.txt']如果提供的正则表达式在字符串中匹配,则 re.match 方法返回一个匹配对象。
如果字符串与正则表达式模式不匹配,则
match()方法返回 None。
新列表仅包含原始列表中与模式匹配的字符串。
如果只想匹配任何单个字符,请删除点后面的星号 *. 在正则表达式中。
import re
a_list = ['2023_a.txt', '2023_bcde.txt', '2023_z.txt']
regex = re.compile(r'2023_.\.txt')
list_of_matches = [
item for item in a_list
if re.match(regex, item)
]
print(list_of_matches) # ????️ ['2023_a.txt', '2023_z.txt']点 . 匹配除换行符以外的任何字符。
通过使用点
.在不转义的情况下,正则表达式匹配任何以 2023_ 开头,后跟任何单个字符并以 .txt 结尾的字符串。
如果大家在阅读或编写正则表达式时需要帮助,请参考我们的正则表达式教程。
该页面包含所有特殊字符的列表以及许多有用的示例。
如果想使用正则表达式检查字符串是否与模式匹配,我们可以直接使用 re.match()
fnmatch.fnmatch() pour vérifier si une chaîne correspond à un modèle. 🎜import re
a_string = '2023_fql.txt'
matches_pattern = bool(re.match(r'2023_.*\.txt', a_string))
print(matches_pattern) # ????️ True
if matches_pattern:
# ????️ this runs
print('The string matches the pattern')
else:
print('The string does NOT match the pattern')🎜🎜🎜Si nous préférons utiliser des expressions régulières, veuillez faire défiler jusqu'au sous-titre suivant. La méthode 🎜🎜fnmatch.filter accepte un itérable et un modèle et renvoie une nouvelle liste contenant uniquement les éléments de l'itérable qui correspondent au modèle fourni. 🎜🎜Le modèle dans l'exemple commence par un ou plusieurs caractères et se termine par .txt. 🎜🎜Le modèle de l'exemple ne contient qu'un seul caractère générique, mais vous pouvez utiliser autant de caractères génériques que vous le souhaitez. 🎜
🎜Veuillez noter que l'astérisque * correspond à tout (un ou plusieurs caractères). 🎜🎜Si vous souhaitez faire correspondre un seul caractère, remplacez l'astérisque * par le point d'interrogation ?. 🎜🎜🎜🎜* correspond à tout (un ou plusieurs caractères) 🎜🎜🎜? correspond à n'importe quel caractère 🎜🎜🎜[!sequence] Correspond à n'importe quel caractère hors séquence🎜🎜Voici un exemple d'utiliser un point d'interrogation pour correspondre à n'importe quel caractère. 🎜import re
a_string = '2023_ABC.txt'
matches_pattern = bool(re.match(r'2023_.\.txt', a_string))
print(matches_pattern) # ????️ False
if matches_pattern:
print('The string matches the pattern')
else:
# ????️ this runs
print('The string does NOT match the pattern')🎜Ce modèle correspond à une chaîne commençant par ab suivi d'un seul caractère. 🎜🎜Si vous souhaitez utiliser des caractères génériques pour vérifier si une chaîne correspond à un modèle, utilisez la méthode fnmatch.fnmatch(). 🎜rrreee🎜Le modèle commence par 2023, suivi d'un ou plusieurs caractères, et se termine par .txt. La méthode 🎜🎜🎜Alternativement, nous pouvons utiliser des expressions régulières. 🎜🎜Utilisez des expressions régulières pour faire correspondre les chaînes à l'aide de caractères génériques🎜🎜Faire correspondre les chaînes à l'aide de caractères génériques :🎜🎜Utilisez la méthodefnmatch.fnmatchaccepte une chaîne et un modèle comme paramètres. La méthode renvoie True si la chaîne correspond au modèle, False sinon. Remplacez simplement l'astérisque*par le point d'interrogation?si vous souhaitez faire correspondre un seul caractère au lieu d'un ou plusieurs caractères. 🎜
re.match() pour vérifier si une chaîne correspond à celle donnée. modèle. Utilisez des caractères .* au lieu de caractères génériques. 🎜rrreee🎜La méthode re.compile compile un modèle d'expression régulière en un objet qui peut être utilisé à l'aide de son match() ou de son search() méthode pour correspondre. 🎜🎜C'est plus efficace que d'utiliser directement re.match ou re.search car cela enregistre et réutilise l'objet d'expression régulière. 🎜🎜L'expression régulière commence par 2023_. 🎜🎜Les caractères .* dans les expressions régulières sont utilisés comme caractères génériques pour faire correspondre un ou plusieurs caractères. 🎜🎜🎜🎜Dot . correspond à n'importe quel caractère sauf la nouvelle ligne. 🎜🎜🎜L'astérisque * correspond à l'expression régulière précédente (point .) zéro ou plusieurs fois. 🎜🎜Nous utilisons le caractère barre oblique inverse pour échapper aux points. dans l'extension, car comme nous l'avons vu précédemment, le point . a une signification particulière lorsqu'il est utilisé dans des expressions régulières. En d’autres termes, nous utilisons des barres obliques inverses pour gérer les points. comme caractères littéraux. 🎜🎜Nous utilisons la compréhension de liste pour parcourir la liste de chaînes. 🎜🎜Les compréhensions de liste sont utilisées pour effectuer certaines opérations sur chaque élément ou sélectionner un sous-ensemble d'éléments qui satisfont une condition. 🎜🎜À chaque itération, nous utilisons la méthode re.match() pour vérifier si la chaîne actuelle correspond au modèle. 🎜rrreee🎜La méthode re.match renvoie un objet match si l'expression régulière fournie correspond à la chaîne. 🎜🎜Si la chaîne ne correspond pas au modèle d'expression régulière, la méthode match() renvoie Aucun. 🎜🎜La nouvelle liste contient uniquement les chaînes de la liste d'origine qui correspondent au modèle. 🎜🎜Si vous souhaitez uniquement faire correspondre un seul caractère, supprimez l'astérisque après le point *. dans l'expression régulière. 🎜rrreee🎜Dot . correspond à n'importe quel caractère sauf la nouvelle ligne. 🎜🎜En utilisant des points . sans s'échapper, l'expression régulière correspond à tout ce qui commence par 2023_ suivi de tout caractère se terminant par txt. La chaîne à la fin. 🎜🎜Si vous avez besoin d'aide pour lire ou écrire des expressions régulières, veuillez vous référer à notre tutoriel sur les expressions régulières. 🎜🎜Cette page contient une liste de tous les caractères spéciaux et de nombreux exemples utiles. 🎜🎜Si vous souhaitez utiliser des expressions régulières pour vérifier si une chaîne correspond à un modèle, nous pouvons directement utiliser la méthode re.match(). 🎜import re
a_string = '2023_fql.txt'
matches_pattern = bool(re.match(r'2023_.*\.txt', a_string))
print(matches_pattern) # ????️ True
if matches_pattern:
# ????️ this runs
print('The string matches the pattern')
else:
print('The string does NOT match the pattern')如果字符串与模式匹配,则
re.match()方法将返回一个匹配对象,如果不匹配,则返回 None 。
我们使用 bool() 类将结果转换为布尔值。
如果要对单个字符使用通配符,请删除星号 * 。
import re
a_string = '2023_ABC.txt'
matches_pattern = bool(re.match(r'2023_.\.txt', a_string))
print(matches_pattern) # ????️ False
if matches_pattern:
print('The string matches the pattern')
else:
# ????️ this runs
print('The string does NOT match the pattern')
请注意,点.我们没有使用反斜杠作为前缀用于匹配任何单个字符,而点.我们以反斜杠 \ 为前缀的被视为文字点。
示例中的字符串与模式不匹配,因此 matches_pattern 变量存储一个 False 值。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!