
Maison >Périphériques technologiques >IA >Résumé de huit méthodes de classification de séries chronologiques
Résumé de huit méthodes de classification de séries chronologiques

- 王林avant
- 2023-05-06 10:04:062256parcourir
La classification des séries chronologiques est l'une des tâches courantes où des modèles d'apprentissage automatique et profond sont appliqués. Cet article couvrira 8 types de méthodes de classification de séries chronologiques. Cela va des simples méthodes basées sur la distance ou la marge aux méthodes utilisant des réseaux de neurones profonds. Cet article est destiné à servir d'article de référence pour tous les algorithmes de classification de séries chronologiques. Avant d'aborder différents types de méthodes de classification de séries temporelles (TS), nous unifions d'abord le temps. Avec le concept de séquence, TS peut être divisé en TS univarié ou multivarié.
 Une seule variable TS est un ensemble ordonné de valeurs (généralement) réelles.
Une seule variable TS est un ensemble ordonné de valeurs (généralement) réelles.
Multivariate TS est un ensemble de TS univariées. Chaque horodatage est un vecteur ou un tableau de valeurs réelles.
Un ensemble de données de TS simples ou multivariés contient généralement un ensemble ordonné de TS simples ou multivariés. De plus, les ensembles de données contiennent généralement un vecteur d'étiquettes représenté par un seul codage, dont la longueur représente les étiquettes de différentes classes.- L'objectif de la classification TS est défini en entraînant n'importe quel modèle de classification sur un ensemble de données donné afin que le modèle puisse apprendre la distribution de probabilité de l'ensemble de données fourni. Autrement dit, le modèle doit apprendre à attribuer correctement des étiquettes de classe lorsqu'il reçoit un TS.
- Méthodes basées sur la distance
p norme (telle que la distance de Manhattan, la distance euclidienne, etc.)
Dynamic Time Warping (DTW)#🎜🎜 ## 🎜🎜#
Après avoir choisi la métrique, l'algorithme k-plus proche voisin (KNN) est généralement appliqué, qui mesure la distance entre un nouveau TS et tous les TS dans l'ensemble de données d'entraînement. Après avoir calculé toutes les distances, sélectionnez les k les plus proches. Enfin, le nouveau TS est affecté à la classe à laquelle appartiennent la majorité des k voisins les plus proches. Si les normes les plus populaires sont certainement la norme p, notamment la distance euclidienne, elles présentent deux inconvénients majeurs qui les rendent moins adaptées aux tâches de classification TS. Puisque la norme n’est définie que pour deux TS de même longueur, il n’est pas toujours possible d’obtenir en pratique des séquences d’égale longueur. La norme compare uniquement deux valeurs TS à chaque instant de manière indépendante, mais la plupart des valeurs TS sont corrélées les unes aux autres.- Et DTW peut résoudre les deux limitations de la norme p. Classic DTW minimise la distance entre deux points de séries chronologiques dont les horodatages peuvent être différents. Cela signifie que les TS légèrement décalés ou déformés sont toujours considérés comme similaires. La figure ci-dessous visualise la différence entre les métriques basées sur la norme p et le fonctionnement de DTW.
Combiné avec KNN, DTW est utilisé comme algorithme de base pour diverses évaluations de référence de la classification TS.
KNN peut également être implémenté à l'aide d'une méthode d'arbre de décision. Par exemple, l'algorithme de forêt voisine modélise une forêt d'arbres de décision qui utilise des mesures de distance pour partitionner les données TS.
Méthodes basées sur les intervalles et les fréquences
Les méthodes basées sur les intervalles divisent généralement le TS en plusieurs intervalles différents. Chaque sous-séquence est ensuite utilisée pour former un classificateur d'apprentissage automatique (ML) distinct. Un ensemble de classificateurs sera généré, chaque classificateur agissant sur son propre intervalle. Le calcul de la classe la plus courante parmi les sous-séries classées séparément renvoie l'étiquette finale pour l'ensemble de la série chronologique. 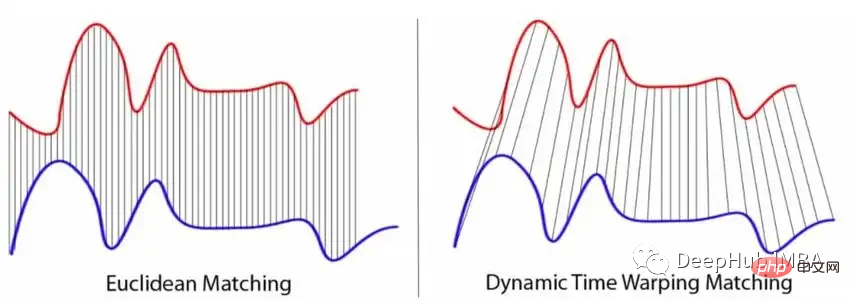
Chaque arbre utilise un seul intervalle TS
Il est entraîné en utilisant les caractéristiques spectrales extraites du TS (au lieu d'utiliser des statistiques récapitulatives comme moyenne, pente , etc.)
Dans la technologie RISE, chaque arbre de décision est construit sur un ensemble différent de fonctionnalités de Fourier, d'autocorrélation, d'autorégression et d'autocorrélation partielle. L'algorithme fonctionne comme suit :Sélectionnez les premiers intervalles aléatoires de TS et calculez les caractéristiques ci-dessus sur ces intervalles. Un nouvel ensemble de formation est ensuite créé en combinant les fonctionnalités extraites. Sur cette base, un classificateur d'arbre de décision est formé. Ces étapes sont finalement répétées en utilisant différentes configurations pour créer un modèle d'ensemble, qui est une forêt aléatoire d'un seul classificateur d'arbre de décision.
Méthode basée sur un dictionnaire
L'algorithme basé sur un dictionnaire est un autre type de classificateur TS, basé sur la structure du dictionnaire. Ils couvrent un grand nombre de classificateurs différents et peuvent parfois être utilisés en combinaison avec les classificateurs ci-dessus.
Voici une liste des méthodes basées sur un dictionnaire couvertes :
- Bag-of-Patterns (BOP)
- Symbolic Fourier Approximation ( SFA)
- BOSS individuel
- BOSS Ensemble
- BOSS dans l'espace vectoriel
- contractable BOSS # 🎜 🎜#Randomized BOSS
- WEASEL
- Exécuter une fenêtre coulissante d'une longueur spécifique sur TS Convertir chaque sous-séquence en un "WORDS" (avec une longueur spécifique et un ensemble fixe de lettres)
- Créez ces histogrammes
#🎜 🎜 #Algorithme de sac de modèles
L'algorithme de sac de modèles (BOP) fonctionne de la même manière que l'algorithme de sac de mots utilisé pour la classification des données textuelles. Cet algorithme compte le nombre de fois qu'un mot apparaît.
La technique la plus courante pour créer des mots à partir de nombres (ici du TS brut) s'appelle l'approximation d'agrégation symbolique (SAX). Le TS est d'abord divisé en différents blocs, chaque bloc est ensuite normalisé, ce qui signifie qu'il a une moyenne de 0 et un écart type de 1.
Habituellement, la longueur d'un mot est plus longue que le nombre de valeurs réelles dans la sous-séquence. Par conséquent, le regroupement est en outre appliqué à chaque bloc. La valeur réelle moyenne pour chaque bac est ensuite calculée et mappée à une lettre. Par exemple, toutes les valeurs inférieures à -1 reçoivent la lettre « a », toutes les valeurs supérieures à -1 et inférieures à 1 sont « b » et toutes les valeurs supérieures à 1 sont « c ». L'image ci-dessous visualise ce processus.
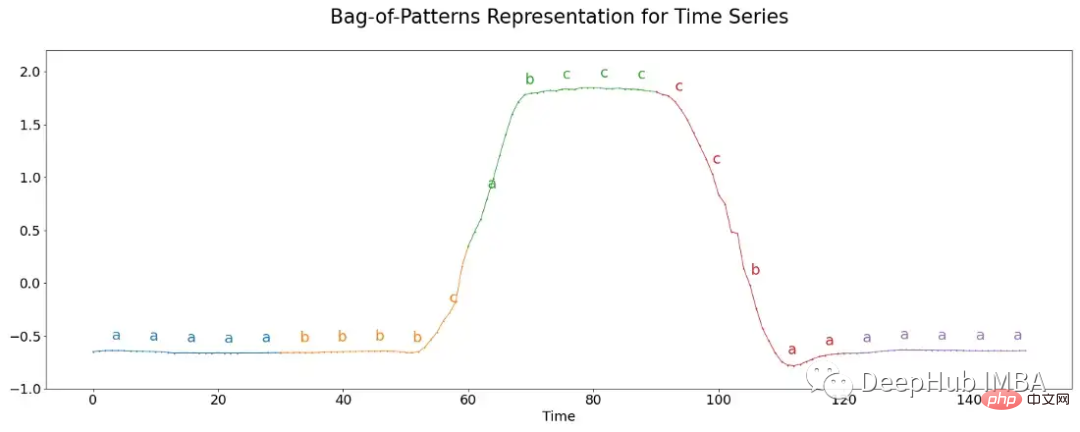 Ici chaque segment contient 30 valeurs, ces valeurs sont réparties en groupes de 6, à chaque groupe se voit attribuer trois lettres possibles, formant Un cinq- mot de lettre. Le nombre d'occurrences de chaque mot est finalement résumé et utilisé pour la classification en les insérant dans l'algorithme du plus proche voisin.
Ici chaque segment contient 30 valeurs, ces valeurs sont réparties en groupes de 6, à chaque groupe se voit attribuer trois lettres possibles, formant Un cinq- mot de lettre. Le nombre d'occurrences de chaque mot est finalement résumé et utilisé pour la classification en les insérant dans l'algorithme du plus proche voisin.
approximation symbolique de Fourier
Contrairement à l'idée de l'algorithme BOP ci-dessus, dans l'algorithme BOP, le TS original est discrétisé en lettres puis en mots, et le Fourier de TS peut être Une approche similaire s’applique aux coefficients.
L'algorithme le plus connu est l'approximation symbolique de Fourier (SFA), qui peut être divisée en deux parties.
Calcule la transformée de Fourier discrète de TS tout en préservant un sous-ensemble des coefficients calculés.
Supervisé : la sélection de caractéristiques univariées est utilisée pour sélectionner des coefficients de rang supérieur en fonction de statistiques (telles que les statistiques F ou les statistiques χ2)- Non supervisé : généralement un sous-ensemble du premier coefficient est pris, représentant la tendance de TS
- Chaque colonne de la matrice résultante est discrétisée indépendamment, convertissant les sous-séquences TS de TS en mots simples.
- Non supervisé : Calculez les bords des bacs en fonction des valeurs extrêmes des coefficients de Fourier (les bacs sont uniformes) ou en fonction des quantiles de ceux-ci (le nombre de coefficients dans chaque bac est le même)# 🎜🎜#
- Sur la base du prétraitement ci-dessus, divers algorithmes peuvent être utilisés pour traiter davantage les informations afin d'obtenir la prédiction de TS.
Extraction via un mécanisme de fenêtre coulissante Sous-séquences de TS
- Appliquer la transformation SFA sur chaque segment, renvoyant un ensemble ordonné de mots
- Calculer la fréquence de chaque mot, ce qui produit un histogramme de mots TS Figure
- est classé en appliquant des algorithmes tels que KNN combinés à une métrique BOSS personnalisée (petits changements dans la distance euclidienne).
- Les variantes de l'algorithme BOSS incluent de nombreuses variantes :
Contractable BOSS
L'algorithme Contractable BOSS (cBOSS) est beaucoup plus rapide en termes de calcul que la méthode BOSS classique.
L'accélération est obtenue non pas en recherchant sur une grille tout l'espace des paramètres, mais en recherchant sur une grille des échantillons sélectionnés au hasard. cBOSS utilise un sous-échantillon de données pour chaque classificateur de base. cBOSS améliore l'efficacité de la mémoire en considérant uniquement un nombre fixe de meilleurs classificateurs de base au lieu de tous les classificateurs au-dessus d'un certain seuil de performances.
BOSS randomisé
La prochaine variante de l'algorithme BOSS est le BOSS randomisé (RBOSS). Cette méthode ajoute un processus stochastique dans la sélection de la longueur de la fenêtre glissante et regroupe intelligemment les prédictions des classificateurs BOSS individuels. Ceci est similaire à la variante cBOSS, réduisant le temps de calcul tout en conservant les performances de base.
WEASE
L'algorithme TS Classifier Extraction (WEASEL) peut améliorer les performances de la méthode BOSS standard en utilisant des fenêtres glissantes de différentes longueurs dans la transformation SFA. Semblable à d'autres variantes de BOSS, il utilise des tailles de fenêtre de différentes longueurs pour convertir les TS en vecteurs de caractéristiques, qui sont ensuite évalués par un classificateur KNN.
WEASEL utilise une méthode de dérivation de caractéristiques spécifique effectuée en utilisant uniquement des sous-séquences non chevauchantes de chaque fenêtre glissante en appliquant un test χ2, en filtrant les caractéristiques les plus pertinentes.
Combinez WEASEL avec des symboles multivariés non supervisés (WEASEL+MUSE) pour extraire et filtrer les fonctionnalités multivariées de TS en codant des informations contextuelles dans chaque fonctionnalité.
Méthode basée sur les shapelets
La méthode basée sur les shapelets utilise l'idée desous-séquences de la série temporelle initiale (c'est-à-dire les shapelets). Les shapelets sont choisis afin de les utiliser comme représentants de classes, ce qui signifie que les shapelets contiennent les principales caractéristiques d'une classe qui peuvent être utilisées pour distinguer différentes classes. Dans le cas optimal, ils peuvent détecter des similitudes locales entre TS au sein d’une même classe.
La figure suivante montre un exemple de shapelet. C'est juste une sous-séquence de l'ensemble du TS.
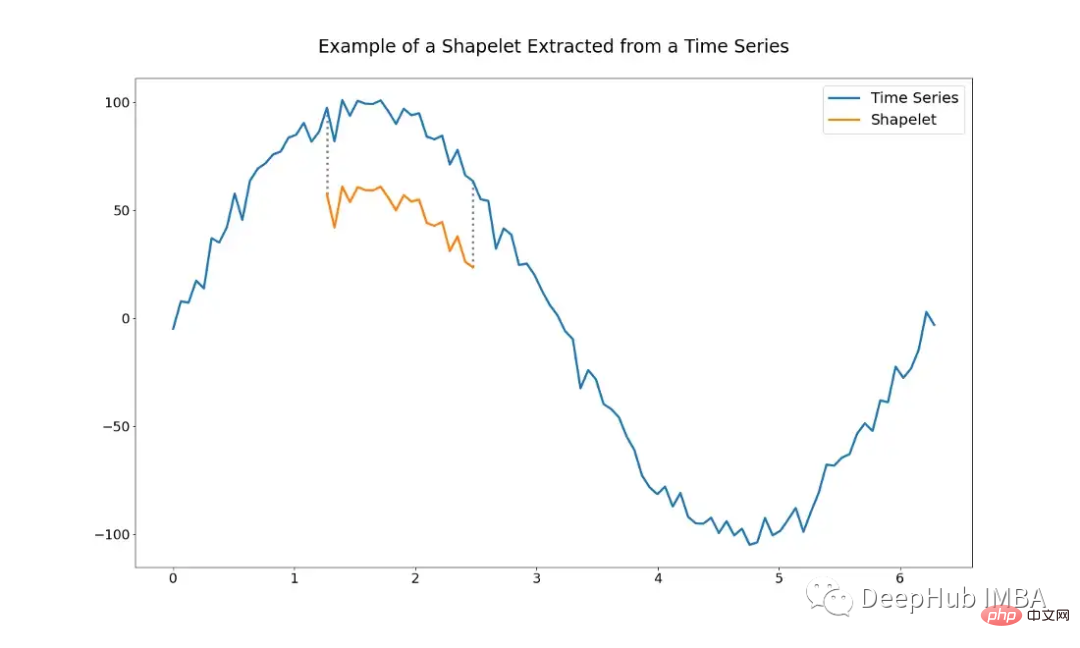
L'utilisation d'algorithmes basés sur des shapelets pose le problème de déterminer quelles shapelets utiliser. Il est possible de sélectionner à la main un ensemble de shapelets, mais cela peut être très difficile. Les shapelets peuvent également être sélectionnés automatiquement à l’aide de divers algorithmes.
Algorithme basé sur l'extraction Shapelet
Shapelet Transform est un algorithme basé sur l'extraction Shapelet proposé par Lines et al. C'est l'un des algorithmes les plus couramment utilisés à l'heure actuelle. Étant donné un TS de n observations à valeur réelle, une shapelet est définie par un sous-ensemble de TS de longueur l.
La distance minimale entre la forme et l'ensemble du TS peut être mesurée à l'aide de la distance euclidienne - ou de toute autre métrique de distance - entre la forme elle-même et toutes les formes de longueur l à partir du TS.
Ensuite, l'algorithme sélectionne les k meilleures shapelets dont les longueurs se situent dans une certaine plage. Cette étape peut être considérée comme une sorte d'extraction d'entités univariées, chaque entité étant définie par la distance entre la shapelet et tous les TS dans l'ensemble de données donné. Les shapelets sont ensuite classés sur la base de certaines statistiques. Il s'agit généralement de statistiques f ou de statistiques χ², qui classent les shapelets en fonction de leur capacité à distinguer les classes.
Après avoir terminé les étapes ci-dessus, tout type d'algorithme ML peut être appliqué pour classer le nouvel ensemble de données. Par exemple, les classificateurs basés sur knn prennent en charge les machines vectorielles ou les forêts aléatoires, etc.
Un autre problème lié à la recherche de shapelets idéaux est la terrible complexité temporelle, qui augmente de façon exponentielle avec le nombre d'échantillons d'entraînement.
Algorithme basé sur l'apprentissage Shapelet
L'algorithme basé sur l'apprentissage Shapelet tente de résoudre les limites de l'algorithme basé sur l'extraction Shapelet. L’idée est d’apprendre un ensemble de shapelets capables de distinguer des classes, plutôt que de les extraire directement d’un jeu de données donné.
Cela présente deux avantages principaux :
- Il permet d'obtenir des shapelets qui ne sont pas inclus dans le set d'entraînement mais sont fortement discriminants pour les catégories.
- Il n'est pas nécessaire d'exécuter l'algorithme sur l'ensemble des données, ce qui peut réduire considérablement le temps d'entraînement
Mais cette méthode a également certaines utilisations de minimisation différenciable fonctions et inconvénients découlant du choix du classificateur.
Pour remplacer la distance euclidienne, nous devons nous appuyer sur des fonctions différentiables, de sorte que les shapelets peuvent être apprises via des algorithmes de descente de gradient ou de rétropropagation. La plus courante repose sur la fonction LogSumExp, qui se rapproche en douceur du maximum en prenant le logarithme de la somme des exposants de ses arguments. Étant donné que la fonction LogSumExp n'est pas strictement convexe, l'algorithme d'optimisation peut ne pas converger correctement, ce qui signifie qu'il peut conduire à de mauvais minima locaux.
Et comme le processus d'optimisation lui-même est le composant principal de l'algorithme, plusieurs hyperparamètres doivent être ajoutés pour le réglage.
Mais cette méthode est très utile en pratique et peut générer de nouveaux insights sur les données. Une légère variation de l'algorithme basé sur les shapelets est l'algorithme basé sur le noyau. Apprenez et utilisez des noyaux de convolution aléatoire (l'algorithme de vision par ordinateur le plus courant), qui extraient les fonctionnalités d'un TS donné.
L'algorithme Random Convolution Kernel Transform (ROCKET) est spécialement conçu à cet effet. . Il utilise un grand nombre de noyaux qui varient en longueur, poids, biais, dilatation et rembourrage, et sont créés aléatoirement à partir d'une distribution fixe.
Après avoir sélectionné le noyau, vous avez également besoin d'un classificateur capable de sélectionner les fonctionnalités les plus pertinentes pour distinguer les classes. La régression Ridge (une variante régularisée L2 de la régression linéaire) a été utilisée dans l'article original pour effectuer des prédictions. Son utilisation présente deux avantages, d'une part son efficacité de calcul, même pour les problèmes de classification multi-classes, et d'autre part la simplicité d'affiner les hyperparamètres de régularisation uniques à l'aide de la validation croisée.
L'un des principaux avantages de l'utilisation d'algorithmes basés sur le noyau ou d'algorithmes ROCKET est que le coût de calcul de leur utilisation est assez faible.
Méthodes basées sur les fonctionnalités
Les méthodes basées sur les fonctionnalités peuvent généralement couvrir la plupart des algorithmes qui utilisent une sorte d'extraction de fonctionnalités pour une série temporelle donnée, qui est ensuite effectuée par un algorithme de classification prédire.
Concernant les fonctionnalités, des fonctionnalités statistiques simples aux fonctionnalités plus complexes basées sur Fourier. Un grand nombre de ces fonctionnalités peuvent être trouvées dans hctsa (https://github.com/benfulcher/hctsa), mais essayer et comparer chaque fonctionnalité peut être une tâche impossible, en particulier pour des ensembles de données plus volumineux. Par conséquent, l’algorithme typique de fonctionnalité de série chronologique (catch22) a été proposé.
algorithme catch22
Cette méthode vise à déduire un petit ensemble de fonctionnalités TS, qui nécessite non seulement de fortes performances de classification, mais minimise également davantage la redondance. catch22 a sélectionné un total de 22 fonctionnalités dans la bibliothèque hctsa (la bibliothèque fournit plus de 4000 fonctionnalités).
Les développeurs de cette méthode ont obtenu 22 fonctionnalités en entraînant différents modèles sur 93 ensembles de données différents et en évaluant les fonctionnalités TS les plus performantes sur ceux-ci, et ont obtenu une méthode qui maintient toujours d'excellentes performances de petits sous-ensembles. Le classificateur qu'il contient peut être librement choisi, ce qui en fait un autre hyperparamètre à régler.
Matrix Profile Classifier
Une autre méthode basée sur les fonctionnalités est le classificateur Matrix Profile (MP), qui est un classificateur TS interprétable basé sur MP qui peut être utilisé pour fournir des résultats interprétables. tout en conservant les performances de base.
Les concepteurs ont extrait un modèle nommé Matrix Profile à partir d'un classificateur basé sur des shapelets. Le modèle représente toutes les distances entre une sous-séquence d'un TS et ses voisins les plus proches. De cette manière, MP peut extraire efficacement les caractéristiques de TS, telles que les motifs et les discordes. Les motifs sont des sous-séquences de TS qui sont très similaires les unes aux autres, tandis que les discordes décrivent des séquences différentes les unes des autres.
En tant que modèle de classification théorique, n'importe quel modèle peut être utilisé. Les développeurs de cette méthode ont choisi des classificateurs d’arbres de décision.
En plus des deux méthodes mentionnées, sktime fournit également d'autres classificateurs TS basés sur les fonctionnalités.
Model Ensemble
Model Ensemble lui-même n'est pas un algorithme autonome, mais une technique qui combine divers classificateurs TS pour créer de meilleures prédictions combinées. Les ensembles de modèles réduisent la variance en combinant plusieurs modèles individuels, semblable à une forêt aléatoire utilisant un grand nombre d'arbres de décision. Et l’utilisation de différents types d’algorithmes d’apprentissage différents conduit à un ensemble plus large et plus diversifié de fonctionnalités apprises, ce qui conduit à une meilleure discrimination de classe.
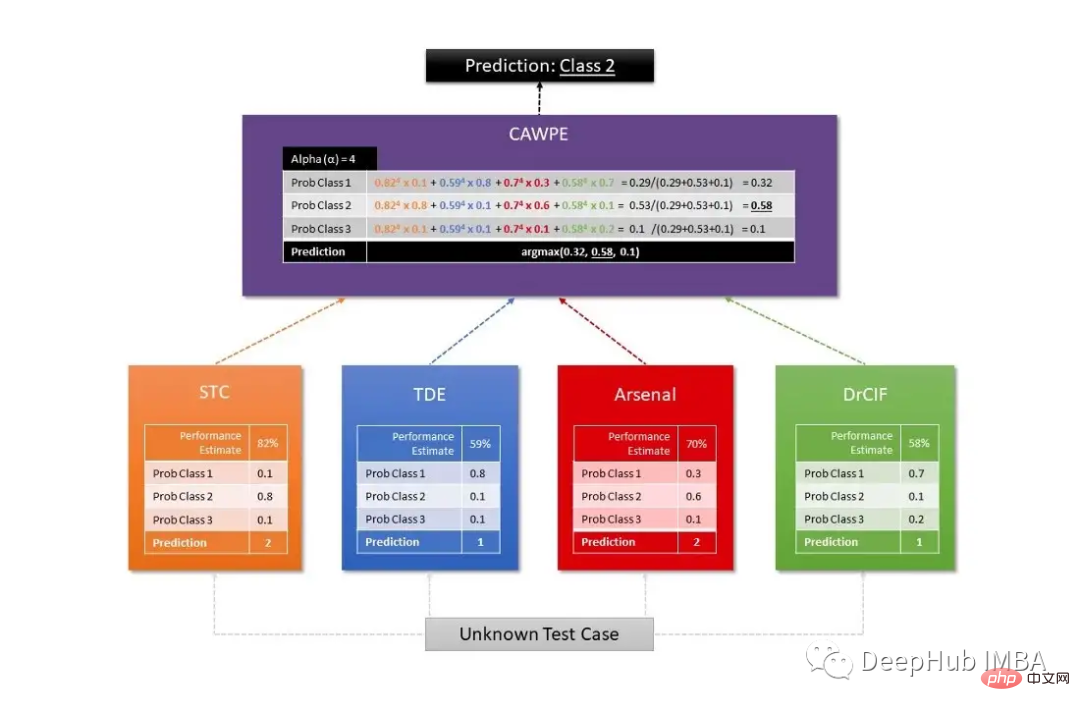
L'ensemble modèle le plus populaire est le Collectif de Vote Hiérarchique des Ensembles Basés sur la Transformation (HIVE-COTE). Il existe de nombreux types de versions similaires, mais ce qu'elles ont toutes en commun est la combinaison d'informations provenant de différents classificateurs, c'est-à-dire des prédictions, en utilisant une moyenne pondérée pour chaque classificateur.
Sktime utilise deux algorithmes HIVE-COTE différents, dont le premier combine la probabilité de chaque estimateur, dont un classificateur par transformation de formes (STC), une forêt TS, un RISE et un cBOSS. Le second est défini par une combinaison de STC, Diverse Canonical Interval Forest Classifier (DrCIF, une variante de TS Forest), Arsenal (une collection de modèles ROCKET) et TDE (une variante de l'algorithme BOSS).
La prédiction finale est obtenue par l'algorithme CAWPE, qui attribue des poids à chaque classificateur obtenu par la qualité relative estimée des classificateurs trouvés sur l'ensemble de données d'entraînement.
La figure suivante est un diagramme commun utilisé pour visualiser la structure de travail de l'algorithme HIVE-COTE :
Deep learning- méthode basée
Concernant les algorithmes basés sur le deep learning, vous pourriez écrire vous-même un long article pour expliquer tous les détails de chaque architecture. Cependant, cet article ne fournit que quelques modèles et techniques de référence de classification TS couramment utilisés.
Bien que les algorithmes basés sur le deep learning soient très populaires et largement étudiés dans des domaines tels que la vision par ordinateur et la PNL, ils sont moins courants dans le domaine de la classification TS. Fawaz et coll. Une étude exhaustive des méthodes existantes actuelles dans leur article sur l'apprentissage profond pour la classification TS : Résumé Plus de 60 modèles de réseaux de neurones (NN) avec six architectures ont été étudiés :
- Perceptron multicouche# 🎜🎜# NN entièrement convolutifs (CNN)
- Réseaux d'écho-état (basés sur des NN récurrents)
- Encoder
- # 🎜🎜#Multi- Scale Deep CNN
- Time CNN
- La plupart des modèles ci-dessus ont été développés à l'origine pour différents cas d'utilisation. Il faut donc le tester selon différents cas d’usage.
A également lancé le réseau InceptionTime en 2020. InceptionTime est un ensemble de cinq modèles d'apprentissage en profondeur, chacun ayant été créé par InceptionTime proposé pour la première fois par Szegedy et al. Ces modules initiaux appliquent simultanément plusieurs filtres de différentes longueurs au TS, tout en extrayant les caractéristiques et les informations pertinentes de sous-séquences de plus en plus longues du TS. La figure suivante montre le module InceptionTime.
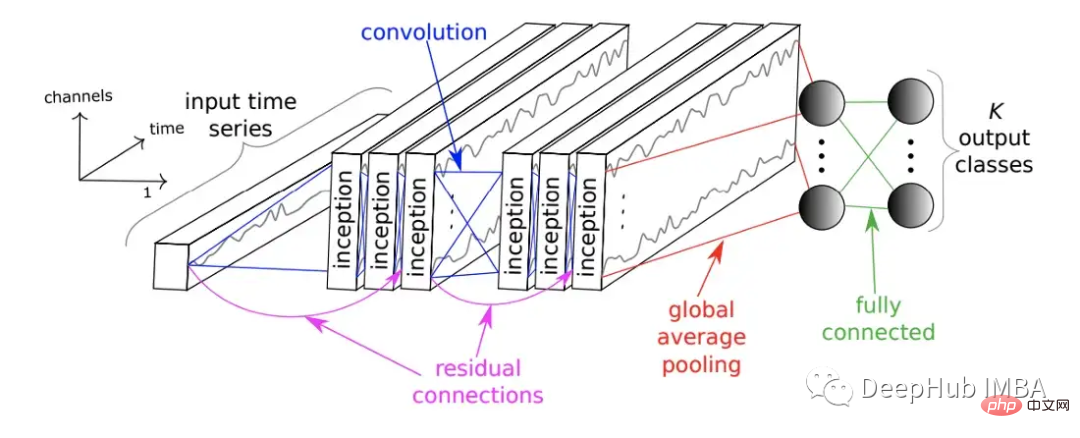
Il se compose de plusieurs modules initiaux empilés de manière anticipée et connectés aux résidus. Enfin, la mise en commun des moyennes mondiales et les réseaux de neurones entièrement connectés génèrent des résultats de prédiction.
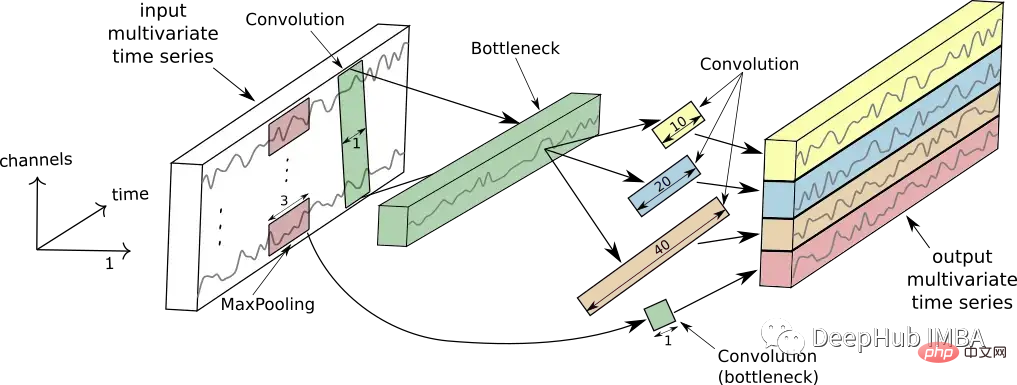
L'image ci-dessous montre le fonctionnement d'un seul module initial.
Résumé
La longue liste d'algorithmes, de modèles et de techniques résumés dans cet article peut non seulement aider à comprendre le vaste domaine des méthodes de classification des séries chronologiques, j'espère qu'il vous sera utile
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI