
Maison >Périphériques technologiques >IA >Interpréter Toolformer
Interpréter Toolformer

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-05 20:10:051685parcourir
Les grands modèles de langage (LLM) ont montré des avantages incroyables dans la résolution de nouvelles tâches avec des données textuelles limitées. Cependant, malgré cela, ils ont d'autres limites, telles que :
- Manque d'accès à des informations à jour
- Tendance à fantasmer sur des faits
- Difficultés avec les langues à faibles ressources
- Manque de connaissances mathématiques compétences pour des calculs précis
- Imprécision avec la progression temporelle Comprendre
Comment utiliser de grands modèles pour résoudre plus de problèmes ? Dans l'article « Interprétation de TaskMatrix.AI », TaskMatrix.AI est une combinaison de Toolformer et de chatGPT, connectant le modèle de base à des millions d'API pour effectuer des tâches. Alors, qu’est-ce qu’un Toolformer ?
Toolformer est un nouveau modèle open source de Meta qui peut résoudre des problèmes nécessitant l'utilisation d'API, tels que des calculatrices, des recherches Wikipédia, des recherches dans des dictionnaires, etc. Toolformer reconnaît qu'il doit utiliser un outil, détermine quel outil utiliser et comment utiliser l'outil. Les cas d'utilisation de Toolformers pourraient être infinis, allant de la fourniture de résultats de recherche instantanés pour n'importe quelle question à des informations contextuelles, telles que les meilleurs restaurants de la ville.
1. Qu'est-ce que Toolformer ?
Qu'est-ce que Toolformer ? En bref, Toolformer est un modèle de langage qui peut apprendre tout seul à utiliser des outils.
Toolformer est basé sur un modèle GPT-J pré-entraîné avec 6,7 milliards de paramètres, entraîné à l'aide de méthodes d'apprentissage auto-supervisées. Cette approche implique d'échantillonner et de filtrer les appels d'API pour augmenter les ensembles de données textuelles existants.
Toolformer espère accomplir la tâche d'auto-apprentissage LLM sur l'utilisation des outils à travers les deux exigences suivantes :
- L'utilisation des outils doit être apprise de manière auto-supervisée sans avoir besoin d'un grand nombre d'annotations manuelles.
- LM ne doit pas perdre sa généralité et doit pouvoir décider lui-même quand et comment utiliser quel outil.
La figure suivante montre les prédictions de Toolformer (par exemple, les appels d'API intégrés dans des échantillons de données) :

2. L'architecture et l'approche de mise en œuvre de Toolformer
Une fonctionnalité essentielle de ChatGPT est l'apprentissage contextuel (en contexte). Learning) fait référence à une méthode d’apprentissage automatique dans laquelle le modèle apprend à partir d’exemples présentés dans un contexte ou un environnement spécifique. L’objectif de l’apprentissage contextuel est d’améliorer la capacité du modèle à comprendre et à générer un langage approprié à un contexte ou une situation donnée. Dans les tâches de traitement du langage naturel (NLP), des modèles de langage peuvent être entraînés pour générer des réponses à des invites ou des questions spécifiques. Alors, comment Toolformer tire-t-il parti de l’apprentissage en contexte ?
Toolformer est un grand modèle de langage qui permet l'utilisation de différents outils via des appels API. L'entrée et la sortie de chaque appel d'API doivent être formatées sous la forme d'une séquence de texte/conversation pour circuler naturellement au sein de la session.

Comme vous pouvez le voir sur l'image ci-dessus, Toolformer exploite d'abord les capacités d'apprentissage contextuel du modèle pour échantillonner un grand nombre d'appels d'API potentiels.
Exécutez ces appels API et vérifiez si la réponse obtenue peut aider à prédire les jetons dans le futur et être utilisée comme filtre. Après le filtrage, les appels d'API vers différents outils sont intégrés aux échantillons de données brutes, ce qui donne lieu à un ensemble de données amélioré sur lequel le modèle est affiné.
Plus précisément, l'image ci-dessus montre un modèle qui accomplit cette tâche à l'aide d'un outil de questions et réponses :
- L'ensemble de données LM contient un exemple de texte : saisissez l'invite "Pittsburgh est également connue sous le nom de The Steel City" pour "Pittsburgh est également connue comme".
- Afin de trouver la bonne réponse, le modèle doit effectuer un appel API et le faire correctement.
- Échantillonnage de certains appels API, en particulier « Sous quel autre nom Pittsburgh est-il connu ? » et « Dans quel pays se trouve Pittsburgh ? »
- Les réponses correspondantes sont « Steel City » et « United States ». Parce que la première réponse est meilleure, elle est incluse dans un nouvel ensemble de données LM avec l'appel API : "Pittsburgh est également connu sous le nom de [QA("Sous quel autre nom Pittsburgh est-il connu ?") -> Steel City] la Steel City" .
- Ceci contient les appels et réponses API attendus. Répétez cette étape pour générer de nouveaux ensembles de données LM à l'aide de divers outils (c'est-à-dire des appels API).
Ainsi, LM annote de grandes quantités de données à l'aide d'appels API intégrés dans le texte, puis utilise ces appels API pour affiner LM afin d'effectuer des appels API utiles. C'est ainsi que fonctionne la formation auto-supervisée, et les avantages de cette approche incluent :
- Moins besoin d'annotation manuelle.
- L'intégration des appels d'API dans le texte permet à LM d'utiliser plusieurs outils externes pour ajouter plus de contenu.
Toolformer apprend alors à prédire quel outil sera utilisé pour chaque tâche.
2.1 Échantillonnage des appels API
La figure suivante montre que Toolformer utilise et pour représenter le début et la fin des appels API en fonction des entrées de l'utilisateur. L'écriture d'une invite pour chaque API encourage le Toolformer à annoter l'exemple avec l'appel d'API approprié.

Toolformer attribue une probabilité à chaque jeton comme suite possible de la séquence donnée. Cette méthode échantillonne jusqu'à k positions candidates pour un appel d'API en calculant la probabilité attribuée par ToolFormer de lancer l'appel d'API à chaque position de la séquence. Les positions avec une probabilité supérieure à un seuil donné sont conservées, et pour chaque position, jusqu'à m appels d'API sont obtenus par échantillonnage à partir du Toolformer à l'aide d'une séquence préfixée par l'appel d'API et suffixée par le marqueur de fin de séquence.
2.2 Exécution des appels API
L'exécution des appels API dépend entièrement du client qui exécute l'appel. Le client peut être un autre type d'application, depuis un autre réseau neuronal jusqu'à un script Python, en passant par un système de récupération qui effectue une recherche dans un grand corpus. Il est important de noter que lorsque le client effectue un appel, l'API renvoie une seule réponse séquentielle de texte. Cette réponse contient des informations détaillées sur l'appel, notamment l'état de réussite ou d'échec de l'appel, l'heure d'exécution, etc.
Par conséquent, afin d'obtenir des résultats précis, le client doit s'assurer que les paramètres d'entrée corrects sont fournis. Si les paramètres d'entrée sont incorrects, l'API peut renvoyer des résultats incorrects, ce qui peut être inacceptable pour l'utilisateur. De plus, les clients doivent s'assurer que la connexion à l'API est stable pour éviter les interruptions de connexion ou d'autres problèmes de réseau pendant les appels.
2.3 Filtrage des appels API
Pendant le processus de filtrage, Toolformer calcule la perte d'entropie croisée pondérée de Toolformer via le jeton après l'appel API.
Ensuite, comparez deux calculs de perte différents :
(i) L'un est un appel API avec le résultat en entrée du Toolformer
(ii) L'un n'est pas un appel API ou un appel API mais aucun résultat n'est renvoyé.
Un appel API est considéré comme utile si l'entrée et la sortie fournies pour l'appel API permettent au Toolformer de prédire plus facilement les futurs jetons. Appliquez un seuil de filtrage pour conserver uniquement les appels d'API pour lesquels la différence entre les deux pertes est supérieure ou égale au seuil.
2.4 Affinement du modèle
Enfin, Toolformer fusionne les appels d'API restants avec l'entrée d'origine et crée un nouvel appel d'API pour augmenter l'ensemble de données. En d’autres termes, l’ensemble de données augmenté contient le même texte que l’ensemble de données d’origine, avec uniquement les appels API insérés.
Ensuite, utilisez le nouvel ensemble de données pour affiner ToolFormer à l'aide d'objectifs de modélisation de langage standard. Cela garantit que le réglage fin du modèle sur l'ensemble de données augmenté est exposé au même contenu que le réglage fin sur l'ensemble de données d'origine. Le réglage fin des données augmentées permet au modèle de langage de comprendre quand et comment utiliser les appels d'API en fonction de ses propres commentaires, en insérant des appels d'API à des emplacements précis et en utilisant des modèles d'aide pour prédire les futures entrées de jetons.
2.5 Inférence
Pendant l'inférence, le processus de décodage est interrompu lorsque le modèle de langage produit le jeton "→", qui indique la prochaine réponse attendue à l'appel d'API. Ensuite, appelez l'API appropriée pour obtenir la réponse et continuez le décodage après avoir inséré la réponse et le jeton.
À ce stade, nous devons nous assurer que la réponse que nous obtenons correspond à la réponse attendue du jeton précédent. Si cela ne correspond pas, nous devons ajuster l'appel API pour obtenir la réponse correcte. Avant de procéder au décodage, nous devons également effectuer un traitement des données pour préparer la prochaine étape du processus d'inférence. Ces processus de données comprennent l'analyse des réponses, la compréhension du contexte et la sélection de chemins d'inférence. Par conséquent, pendant le processus d'inférence, vous devez non seulement appeler l'API pour obtenir une réponse, mais vous devez également effectuer une série de traitements et d'analyses de données pour garantir l'exactitude et la cohérence du processus d'inférence.
2.6 Outils API
Chaque outil API pouvant être utilisé dans Toolformer doit remplir les deux conditions suivantes :
- L'entrée/sortie doit être représentée sous la forme d'une séquence de texte.
- Des démos sont disponibles montrant comment utiliser ces outils.
La mise en œuvre initiale de Toolformer prend en charge cinq outils API :
- Q&A : Ceci est un autre LM qui répond à des questions factuelles simples.
- Calculatrice : ne prend actuellement en charge que 4 opérations arithmétiques de base et l'arrondi à deux décimales.
- Recherche Wiki : un moteur de recherche qui renvoie un court texte extrait de Wikipédia.
- Système de traduction automatique : un LM capable de traduire des phrases dans n'importe quelle langue vers l'anglais.
- Calendrier : appel API au calendrier qui renvoie la date actuelle sans accepter aucune entrée.
La figure suivante montre les exemples d'entrée et de sortie de toutes les API utilisées :

3 Exemples d'application
Toolformer a d'excellentes performances dans des tâches telles que LAMA, les ensembles de données mathématiques, la résolution de problèmes et les ensembles de données temporelles. . Par rapport au modèle de base et à GPT-3, mais ses performances en matière de réponse aux questions multilingues ne sont pas aussi bonnes que les autres modèles. Toolformer utilise des appels d'API pour effectuer des tâches, telles que l'API LAMA, l'API Calculatrice et l'API de l'outil de recherche Wikipedia.
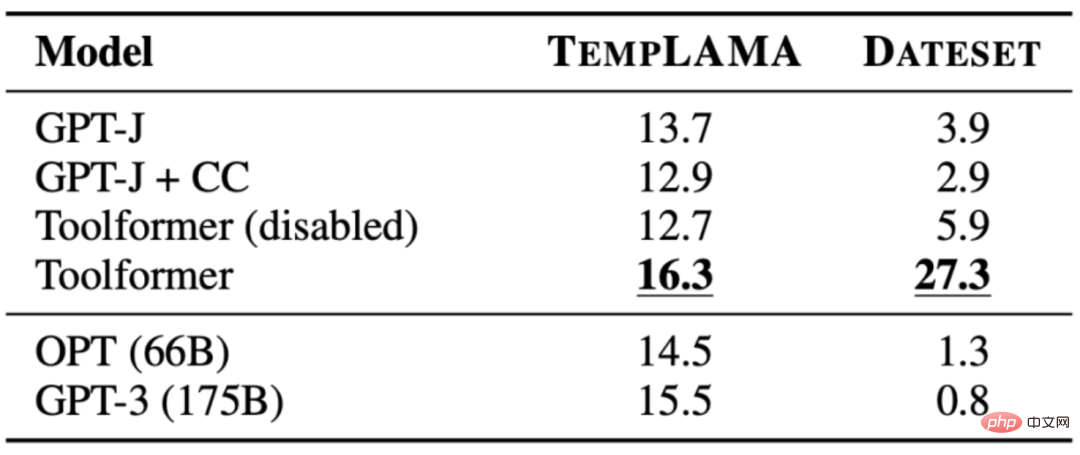
3.1 LAMA
La tâche est de compléter une déclaration qui manque de faits. Toolformer surpasse les modèles de base et même les modèles plus grands tels que GPT-3. Le tableau suivant montre les résultats obtenus grâce aux appels de l'API LAMA :
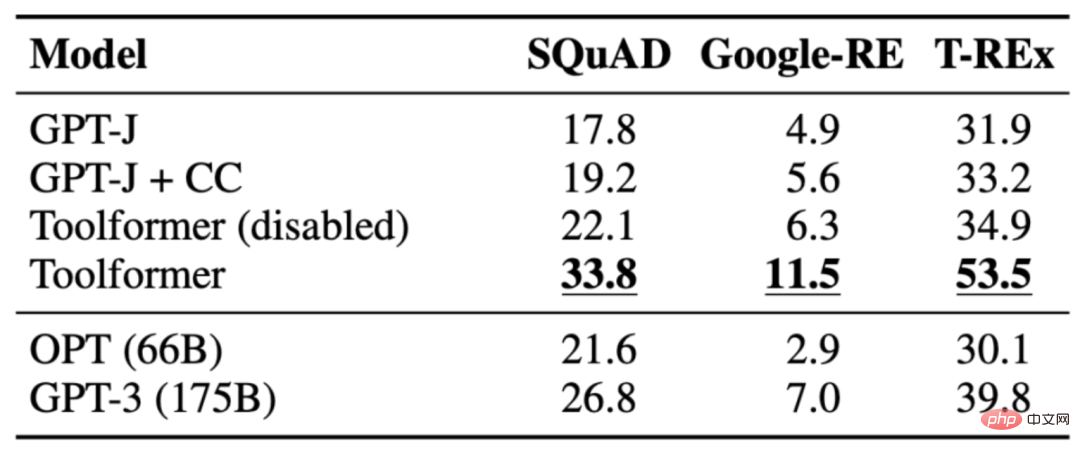
3.2 Ensemble de données mathématiques
La tâche consiste à évaluer les capacités de raisonnement mathématique de Toolformer par rapport à divers modèles de base. Toolformer fonctionne mieux que les autres modèles, probablement en raison de son réglage fin des exemples d'appels API. Permettre aux modèles d'effectuer des appels d'API améliore considérablement les performances de toutes les tâches et surpasse les modèles plus volumineux tels que OPT et GPT-3. Dans presque tous les cas, le modèle a décidé de demander de l’aide à l’outil de calcul.
Le tableau suivant montre les résultats obtenus via l'appel de l'API Calculator :
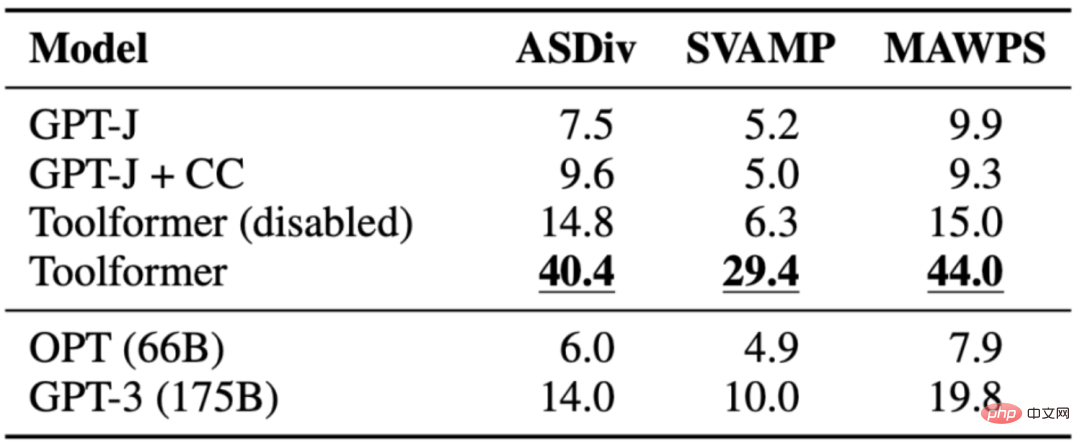
3.3 Question Réponse
La tâche consiste à répondre à la question Toolformer fonctionne mieux que le modèle de base de même taille, mais mieux que. GPT-3(175B). Toolformer utilise les outils de recherche de Wikipédia pour la plupart des exemples de cette tâche. Le tableau suivant montre les résultats obtenus via l'appel API de l'outil de recherche Wikipédia :
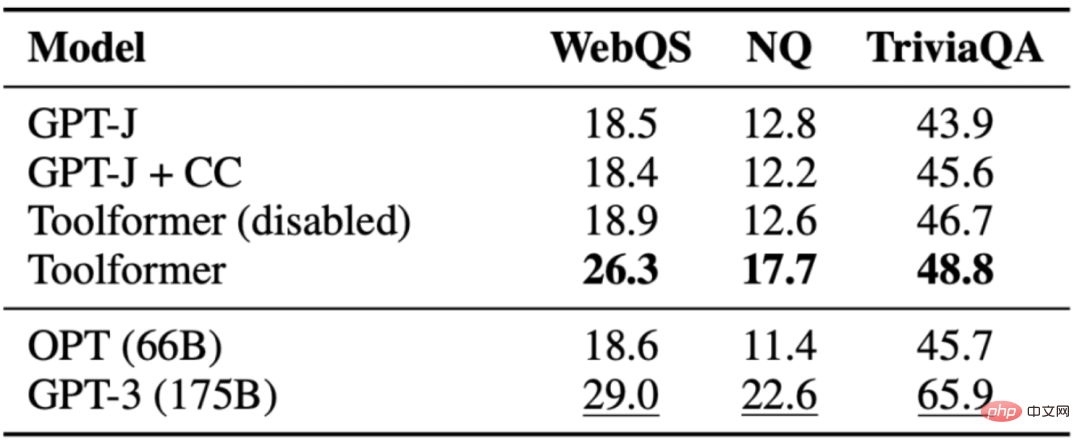
3.4 Réponses aux questions multilingues
L'ensemble de données de réponses aux questions est utilisé pour le test de réponse aux questions multilingues MLQA, qui contient des paragraphes de contexte en anglais et en arabe, Allemand, espagnol, hindi, vietnamien ou chinois simplifié. Toolformer n'est pas le plus performant ici, probablement en raison du manque de réglage de CCNet dans toutes les langues.
Le tableau suivant présente les résultats obtenus grâce à l'appel API de l'outil de recherche Wikipédia :
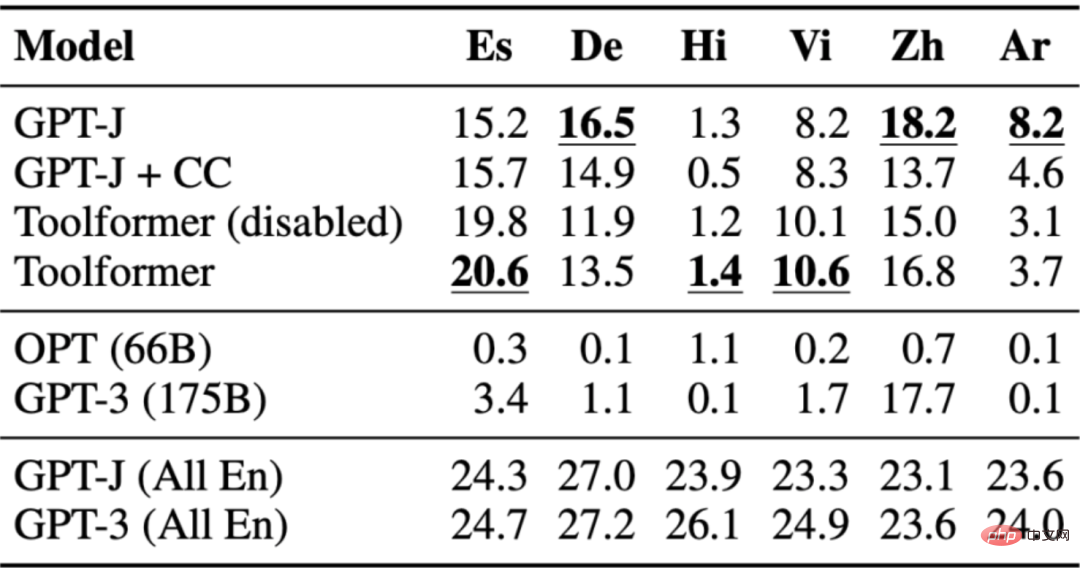
3.5 Ensemble de données temporelles
La tâche consiste à comprendre où la date actuelle est cruciale pour répondre à la question. Toolformer a réussi à surpasser la référence, mais il n'a clairement pas utilisé l'outil de calendrier à 100 % du temps. Au lieu de cela, il utilise une recherche Wikipédia. Le tableau suivant montre les résultats obtenus via l'appel API de l'outil de recherche Wikipédia :
4 Limites de ToolFormer
Toolformer présente encore certaines limitations, telles que l'impossibilité d'utiliser plusieurs outils en même temps et l'incapacité. pour gérer un trop grand nombre d'outils renvoyés, une sensibilité à la formulation d'entrée conduisant à une inefficacité, une incapacité à prendre en compte les coûts d'utilisation pouvant entraîner des coûts de calcul élevés, et d'autres problèmes. Les détails sont les suivants :
- Étant donné que les appels API pour chaque outil sont générés indépendamment, Toolformer ne peut pas utiliser plusieurs outils dans un seul processus.
- Surtout pour les outils qui peuvent renvoyer des centaines de résultats différents (comme les moteurs de recherche), Toolformer ne peut pas être utilisé de manière interactive.
- Les modèles formés à l'aide de Toolformer sont très sensibles à la formulation exacte de l'entrée, cette approche est inefficace pour certains outils et nécessite une documentation complète pour générer un petit nombre d'appels d'API utiles.
- Lors de la décision d'utiliser chaque outil, le coût de son utilisation n'est pas pris en compte, ce qui peut entraîner des coûts de calcul plus élevés.
5. Résumé
Toolformer est un modèle de langage à grande échelle qui utilise l'apprentissage en contexte pour améliorer la compréhension du modèle et générer un langage adapté à un contexte ou à un contexte donné. situation. Il utilise des appels d'API pour annoter de grandes quantités de données, puis utilise ces appels d'API pour affiner le modèle afin d'effectuer des appels d'API utiles. Toolformer apprend à prédire quel outil sera utilisé pour chaque tâche. Cependant, Toolformer présente encore certaines limites, telles que l'incapacité d'utiliser plusieurs outils dans un processus et l'incapacité d'utiliser de manière interactive des outils pouvant renvoyer des centaines de résultats différents.
【Références et lectures associées】
- Toolformer : les modèles de langage peuvent apprendre eux-mêmes à utiliser des outils, https://arxiv.org/pdf/2302.04761 pdf.
- Toolformer de Meta utilise des API pour surpasser GPT-3 sur les tâches Zero-Shot NLP, https://www.infoq.com/news/2023/04/meta-toolformer/ # 🎜 🎜#Toolformer : les modèles de langage peuvent apprendre eux-mêmes à utiliser des outils (2023), https://kikaben.com/toolformer-2023/
- Breaking Down Toolformer, https://www.formed.ai / blog/breaking-down-toolformer
- Toolformer : Meta réintègre la course ChatGPT avec un nouveau modèle utilisant Wikipedia, https://thechainsaw.com/business/meta-toolformer-ai/#🎜 🎜 #
- Le modèle de langage Toolformer utilise lui-même des outils externes , https://the-decoder.com/toolformer-lingual-model-uses-external-tools-on-its-own/ #🎜 🎜 #
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI