
Maison >Périphériques technologiques >IA >Pourquoi DeepMind est-il absent de la fête GPT ? Il s'est avéré que j'apprenais à un petit robot à jouer au football.
Pourquoi DeepMind est-il absent de la fête GPT ? Il s'est avéré que j'apprenais à un petit robot à jouer au football.

- 王林avant
- 2023-05-04 22:31:051258parcourir
De l'avis de nombreux chercheurs, l'intelligence incarnée est une direction très prometteuse vers l'AGI, et le succès de ChatGPT est également indissociable de la technologie RLHF basée sur l'apprentissage par renforcement. DeepMind vs OpenAI, qui peut atteindre l'AGI en premier ? La réponse ne semble pas encore avoir été révélée.
Nous savons que créer une intelligence incarnée universelle (c'est-à-dire des agents qui agissent dans le monde physique de manière agile et adroite et comprennent comme les animaux ou les humains) C'est l'un des les objectifs à long terme des chercheurs en IA et des experts en robotique. En termes de temps, la création d’agents incarnés intelligents dotés de capacités de locomotion complexes remonte à de nombreuses années, tant dans les simulations que dans le monde réel.
Le rythme des progrès s'est considérablement accéléré ces dernières années, les méthodes basées sur l'apprentissage jouant un rôle majeur. Par exemple, il a été démontré que l'apprentissage par renforcement profond est capable de résoudre des problèmes complexes de contrôle de mouvement de personnages simulés, y compris un contrôle complexe du corps entier basé sur la perception ou un comportement multi-agents. Dans le même temps, l'apprentissage par renforcement profond est de plus en plus utilisé dans les robots physiques. En particulier, les robots quadrupèdes de haute qualité largement utilisés sont devenus des cibles de démonstration pour apprendre à générer une gamme de comportements locomoteurs robustes.
Cependant, le mouvement dans des environnements statiques n'est qu'une partie des nombreuses façons dont les animaux et les humains déploient leur corps pour interagir avec le monde, et cette forme de mouvement a été utilisé dans de nombreuses études sur le contrôle du corps entier et a été démontré dans des travaux sur la manipulation du mouvement, en particulier pour les robots quadrupèdes. Des exemples de mouvements associés incluent l’escalade, les compétences de football telles que dribbler ou attraper un ballon et des manœuvres simples utilisant les jambes.
Parmi elles, pour le football, elle présente de nombreuses caractéristiques de l'intelligence sensorimotrice humaine. La complexité du football nécessite une variété de mouvements très agiles et dynamiques, notamment courir, se retourner, éviter, donner des coups de pied, passer, tomber et se relever, etc. Ces actions doivent être combinées de diverses manières. Les joueurs doivent prédire le ballon, leurs coéquipiers et les joueurs adverses, et ajuster leurs actions en fonction de l'environnement de jeu. Cette diversité de défis a été reconnue dans les communautés de la robotique et de l'IA, et RoboCup est née.
Cependant, il convient de noter que l'agilité, la flexibilité et la réactivité nécessaires pour bien jouer au football, ainsi que la transition en douceur entre ces éléments, sont très difficiles pour conception manuelle des robots. Et prend du temps. Récemment, un nouvel article de DeepMind (maintenant fusionné avec l'équipe Google Brain pour former Google DeepMind) explore l'utilisation de l'apprentissage par renforcement profond pour acquérir des compétences de football agiles pour les robots bipèdes. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # # :https://arxiv.org/pdf/2304.13653.pdf
Page d'accueil du projet : https://sites.google.com /view/op3-soccer
Dans cet article, les chercheurs étudient le contrôle complet du corps et le contrôle de petits robots humanoïdes dans des environnements multi-agents dynamiques. Interaction d'objet. Ils ont examiné un sous-ensemble du problème du football dans son ensemble, ont formé un robot humanoïde miniature à faible coût doté de 20 articulations contrôlables pour jouer à un match de football 1 contre 1 et ont observé les caractéristiques proprioceptives et l'état du jeu.
Grâce au contrôleur intégré, le robot se déplace lentement et maladroitement. Cependant, les chercheurs ont utilisé l'apprentissage par renforcement profond pour synthétiser des habiletés motrices dynamiques et agiles adaptées au contexte (telles que marcher, courir, tourner, taper dans un ballon et se relever après une chute) que l'agent combinait de manière naturelle et douce en des exercices longs complexes. -comportements à terme.Dans l'expérience, l'agent a appris à prédire le mouvement de la balle, le positionnement, le blocage et l'utilisation des balles rebondies. Les agents parviennent à ces comportements dans un environnement multi-agents grâce à une combinaison de réutilisation des compétences, de formation de bout en bout et de récompenses simples. Les chercheurs ont formé des agents à la simulation et les ont transférés vers des robots physiques, démontrant que le transfert de la simulation au réel est possible même pour des robots peu coûteux.
Laissez les données parler d'elles-mêmes. La vitesse de marche du robot a augmenté de 156 %, le temps pour se lever a été réduit de 63 % et la vitesse de frappe du ballon. a également augmenté de 24 % par rapport à la valeur de référence. Avant d'entrer dans l'interprétation technique, jetons un coup d'œil à quelques points forts des robots dans les matchs de football 1v1. Par exemple, tournage :

Penalty :

Tourner, dribbler et botter, tout en un seul coup

Bloquer :

Configuration expérimentale
Si vous souhaitez qu’un robot apprenne à jouer au football, vous avez d’abord besoin de quelques réglages de base.
En termes d'environnement, DeepMind simule et forme d'abord l'agent dans un environnement de football personnalisé, puis migre la stratégie vers l'environnement réel correspondant, comme le montre la figure 1. L'environnement était constitué d'un terrain de football de 5 m de long et 4 m de large, avec deux buts ayant chacun une largeur d'ouverture de 0,8 m. Dans les environnements simulés et réels, le terrain est délimité par des rampes pour maintenir le ballon dans les limites. Le vrai terrain est recouvert de dalles en caoutchouc pour réduire le risque d'endommager le robot en cas de chute et pour augmenter la friction au sol.
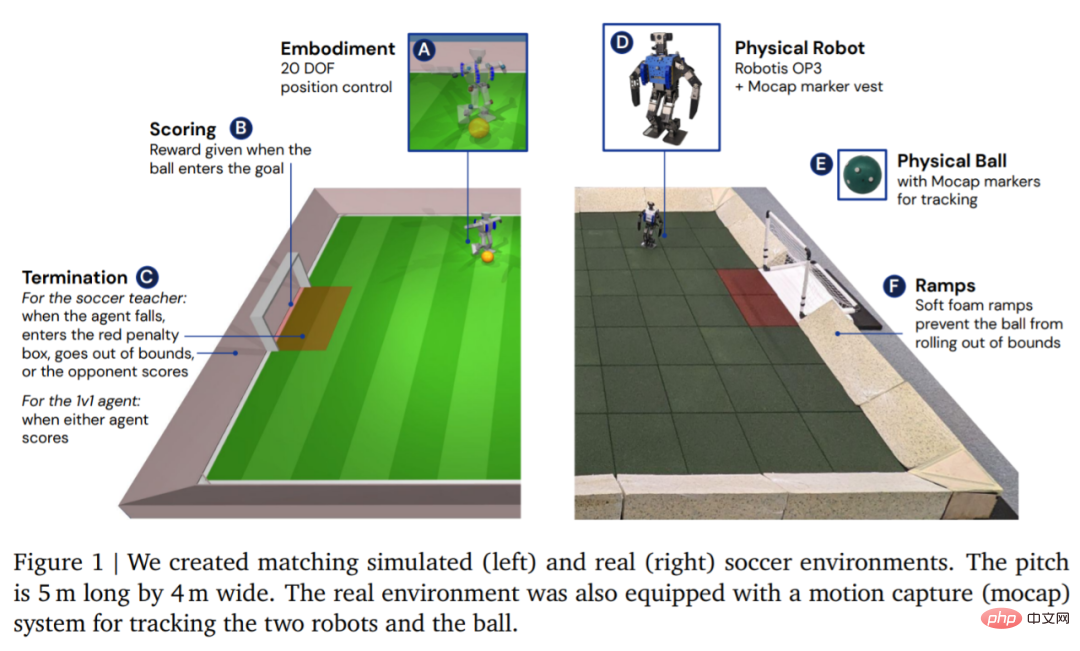
Une fois l'environnement configuré, l'étape suivante consiste à configurer le matériel et la capture de mouvement. DeepMind utilise un robot Robotis OP3, mesurant 51 cm de haut et pesant 3,5 kg, entraîné par 20 servomoteurs. Le robot n'a pas de GPU ou autre accélérateur dédié, donc tous les calculs du réseau neuronal s'exécutent sur le CPU. A la tête du robot se trouve une webcam Logitech C920, qui peut fournir en option un flux vidéo RVB à 30 images par seconde.

Méthode
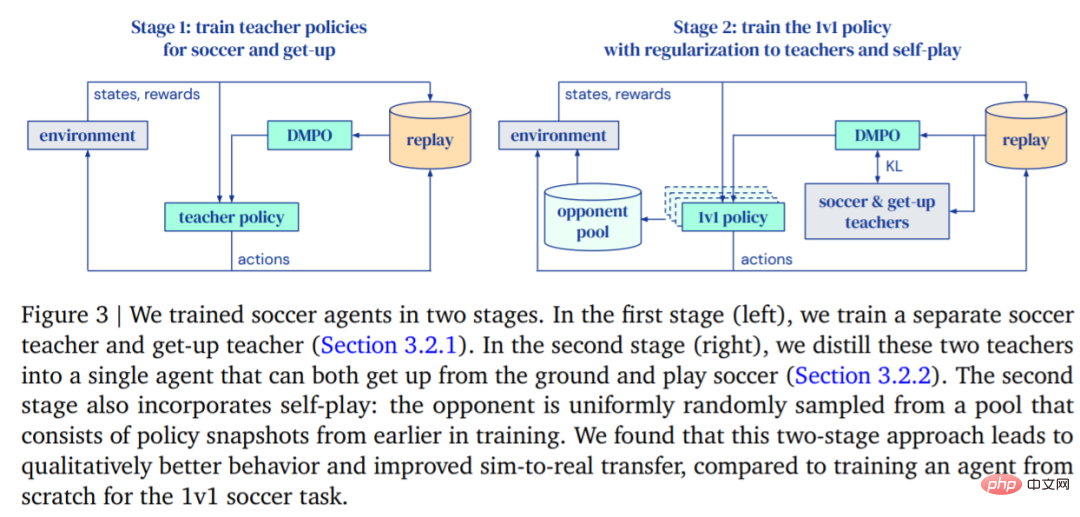
Le but de DeepMind est de former un agent capable de marcher, de taper dans un ballon, de se lever, de défendre et de savoir marquer, puis de transférer ces fonctions à un véritable robot. DeepMind divise la formation en deux étapes, comme le montre la figure 3.
- Dans la première phase, DeepMind forme les stratégies des enseignants pour deux compétences spécifiques, notamment celle de l'agent qui se relève du sol et marque des buts.
- Dans la deuxième étape, la stratégie de l'enseignant de la première étape est utilisée pour réguler l'agent, tandis que l'agent apprend à lutter efficacement contre des adversaires de plus en plus puissants.
Formation
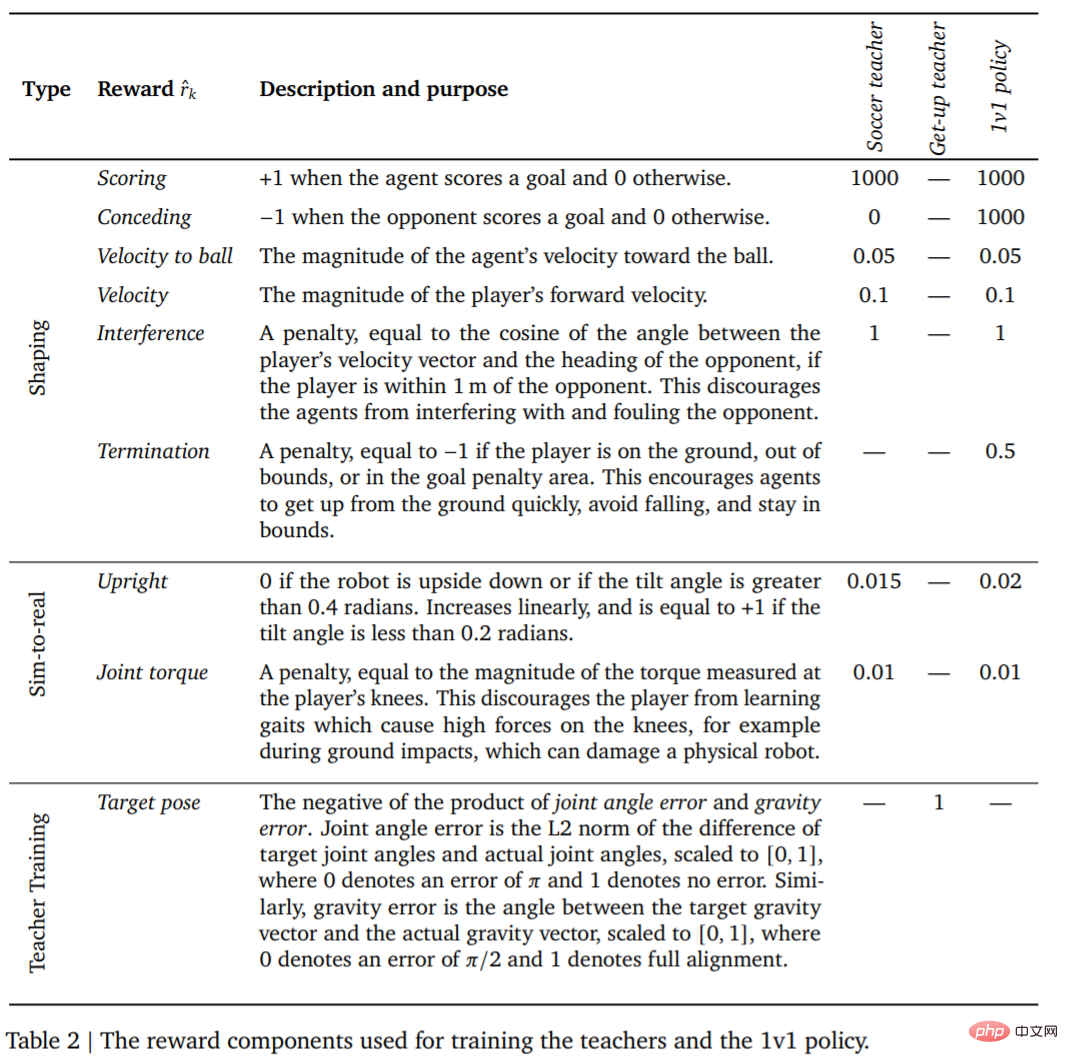
La première chose est la formation des enseignants. Les enseignants doivent recevoir autant de formation que possible sur la notation de buts. Ce tour (épisodes) se termine lorsque l'agent tombe, sort des limites, entre dans la zone réglementée (marquée en rouge sur la figure 1) ou lorsque l'adversaire marque. Au début de chaque tour, l'agent, l'autre camp et le ballon sont initialisés à des positions et des directions aléatoires sur le terrain. Les deux côtés sont initialisés à la position par défaut. L'adversaire est initialisé avec une politique non entraînée, de sorte que l'agent apprend à l'éviter à ce stade, mais aucune autre interaction complexe ne se produit. De plus, les récompenses et leurs pondérations pour chaque étape de formation sont présentées dans le tableau 2.
L'agent rivalise alors contre des adversaires de plus en plus puissants tout en régulant son comportement selon la politique de l'enseignant. De cette manière, l'agent peut maîtriser une série de compétences footballistiques : marcher, donner des coups de pied, se lever, marquer et défendre. Lorsque l'agent sort des limites ou se trouve à l'intérieur de la case de but, il reçoit une pénalité fixe à chaque pas de temps.
Une fois l'agent formé, l'étape suivante consiste à transférer la stratégie de coup de pied entraînée au robot réel avec zéro échantillon. Afin d'améliorer le taux de réussite du transfert zéro-shot, DeepMind réduit l'écart entre les agents simulés et les robots réels grâce à une identification simple du système, améliore la robustesse de la stratégie grâce à la randomisation du domaine et à la perturbation pendant la formation, et inclut l'élaboration de la stratégie de récompense pour obtenir résultats différents. Comportement trop susceptible de nuire au robot.
Expériences
Compétition 1v1 : L'agent de football peut gérer une variété de comportements émergents, y compris des capacités motrices flexibles telles que se lever du sol, se remettre rapidement d'une chute, courir et se retourner. Pendant le jeu, l’agent passe en douceur d’une compétence à l’autre.

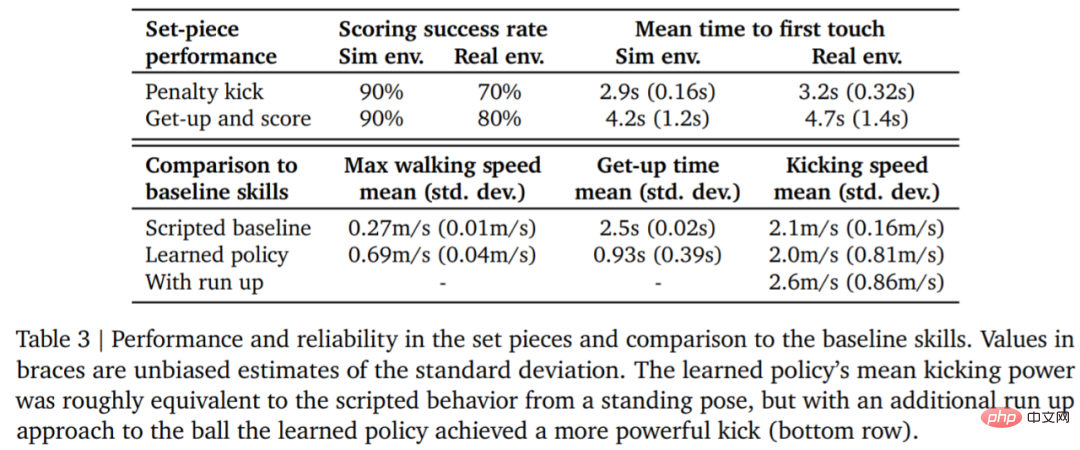
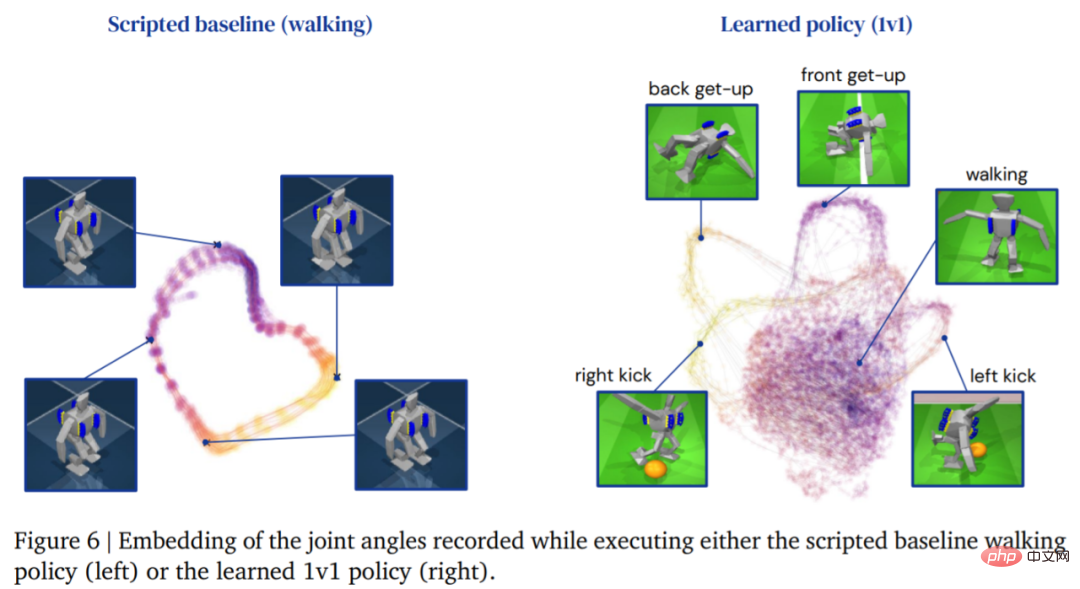
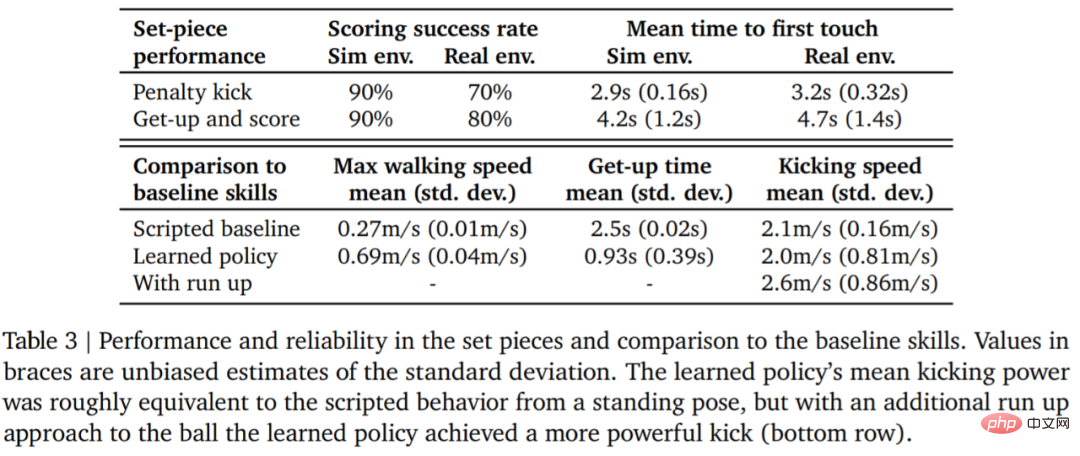
Le tableau 3 ci-dessous présente les résultats de l'analyse quantitative. Les résultats montrent que la stratégie d’apprentissage par renforcement est plus efficace que les compétences spécialisées conçues artificiellement, l’agent marchant 156 % plus vite et prenant 63 % de temps en moins pour se lever.
L'image ci-dessous montre la trajectoire de marche de l'agent En comparaison, la structure de trajectoire de l'agent générée par la stratégie d'apprentissage est plus riche :
Afin d'évaluer. la fiabilité de la stratégie d'apprentissage DeepMind a conçu des tirs au but et des coups de pied arrêtés, et les a mis en œuvre dans des environnements simulés et réels. La configuration initiale est illustrée à la figure 7.
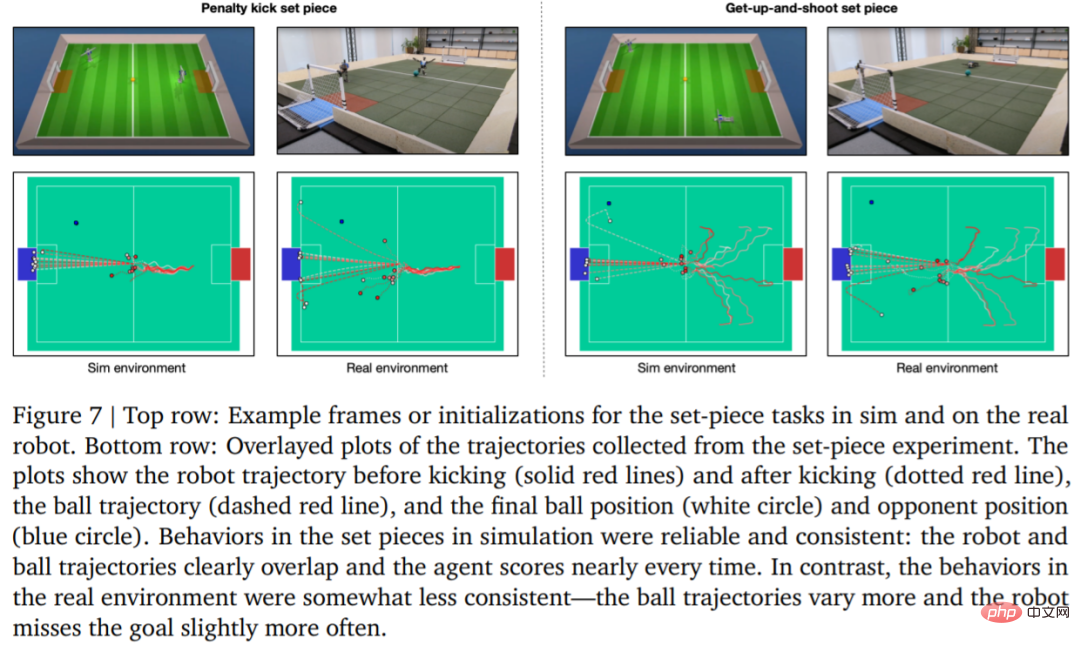
Dans un environnement réel, le robot a frappé 7 fois sur 10 (70%) dans la tâche de coup de pied de pénalité et 8 fois sur 10 (80%) dans la tâche de lancement. Dans l'expérience de simulation, les scores de l'agent dans ces deux tâches étaient plus cohérents, ce qui montre que la stratégie de formation de l'agent est transférée à l'environnement réel (y compris les vrais robots, balles, surfaces de sol, etc.), que les performances sont légèrement dégradées et les différences de comportement se sont accrues, mais le robot est toujours capable de se lever de manière fiable, de taper dans le ballon et de marquer. Les résultats sont présentés dans la figure 7 et le tableau 3.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI