
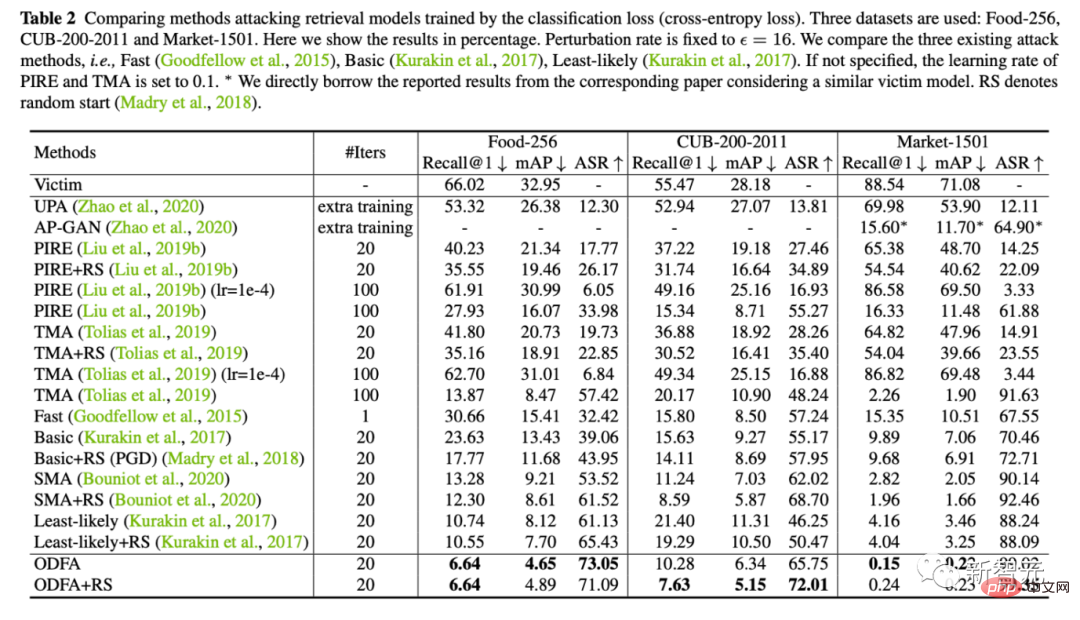
Maison >Périphériques technologiques >IA >La fonction d'inversion fait passer le modèle de ré-identification de 88,54 % à 0,15 %
La fonction d'inversion fait passer le modèle de ré-identification de 88,54 % à 0,15 %

- 王林avant
- 2023-05-04 15:52:061235parcourir
La première version de cet article a été rédigée en mai 2018, et elle a été récemment publiée en décembre 2022. J'ai reçu beaucoup de soutien et de compréhension de la part de mes patrons au cours des quatre dernières années.
(J'espère aussi que cette expérience encouragera les étudiants qui soumettent des articles. Si vous rédigez bien l'article, vous gagnerez certainement, n'abandonnez pas facilement !)
La première version de arXiv est : Attaque de requête via la fonctionnalité de direction opposée : vers une récupération d'images robuste

Lien papier : https://link.springer.com/article/10.1007/s11263-022-01737-y
Lien de sauvegarde papier : https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
Code : https://github.com/layumi/U_turn
Thor : Zhedong Zheng, Liang Zheng, Yi Yang et Fei Wu
Par rapport aux versions précédentes,
- Nous avons apporté quelques ajustements à la formule
- Ajout de nombreuses nouvelles discussions sur les travaux connexes ; Attaque de requête multi-échelle/attaque par boîte noire / Défendre les expériences sous trois angles différents ;
- Ajouter de nouvelles méthodes et de nouvelles méthodes de visualisation sur Food256, Market-1501, CUB, Oxford, Paris et d'autres ensembles de données.
- Attaqué la structure PCB dans reid et WiderResNet dans Cifar10.
- Cas réels
En utilisation réelle. Par exemple, nous voulons attaquer le système de récupération d'images de Google ou de Baidu pour faire de la grande actualité (brouillard). Nous pouvons télécharger une image d'un chien, calculer les caractéristiques via le modèle imagenet (ou d'autres modèles, de préférence un modèle proche du système de récupération), et calculer le bruit adverse plus en retournant les caractéristiques (la méthode dans cet article). Revenons au chien. Utilisez ensuite la fonction de recherche d'images pour le chien après l'attaque. Vous pouvez voir que Baidu et le système de Google ne peuvent pas renvoyer de contenu lié au chien. Bien que nous, les humains, puissions toujours reconnaître qu’il s’agit d’une image d’un chien.
P.S. J'ai également essayé d'attaquer Google pour rechercher des images. Les gens peuvent toujours reconnaître qu'il s'agit d'une image de chien, mais Google renvoie souvent des images liées à une « mosaïque ». J'estime que Google n'utilise pas tous des fonctionnalités profondes, ou alors c'est assez différent du modèle imagenet. Du coup, après une attaque, on a souvent tendance à être "mosaïque" à la place d'autres catégories d'entités (avions, etc.). Bien sûr, la mosaïque peut être considérée dans une certaine mesure comme une réussite !
Quoi
1. L'intention initiale de cet article est en fait très simple. Le modèle Reid existant ou modèle de récupération de paysage a atteint un taux de rappel Rappel-1 de plus de 95 %, pouvons-nous donc concevoir un moyen d'attaquer. récupération ? D'une part, explorons le contexte du modèle REID. D'autre part, l'attaque vise une meilleure défense.
2. La différence entre le modèle de récupération et le modèle de classification traditionnel est que le modèle de récupération utilise les caractéristiques extraites pour comparer les résultats (tri), ce qui est assez différent du modèle de classification traditionnel, comme le montre le tableau ci-dessous.
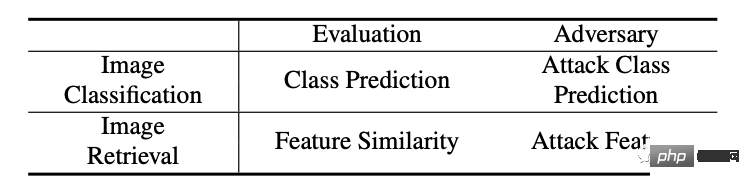
4. Lors du test du modèle de récupération, il y a deux parties de données : l'une est la requête d'image et l'autre est la galerie d'images (la quantité de données est importante et généralement inaccessible). Compte tenu de la faisabilité pratique, notre méthode ciblera principalement l’image de la requête d’attaque pour provoquer des résultats de récupération erronés.
Comment
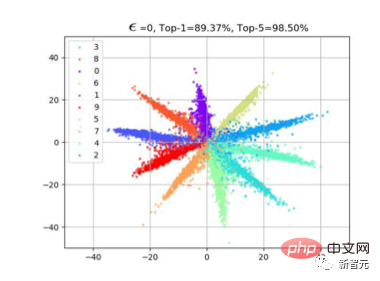
1. Une idée naturelle est celle des caractéristiques d'attaque. Alors comment attaquer les fonctionnalités ? Sur la base de nos observations précédentes sur la perte d'entropie croisée (veuillez vous référer à l'article Perte softmax à grande marge). Souvent, lorsque nous utilisons la perte de classification, la caractéristique f aura une distribution radiale. En effet, la similarité cos est calculée entre la caractéristique et le poids W de la dernière couche de classification lors de l'apprentissage. Comme le montre la figure ci-dessous, une fois l'apprentissage du modèle terminé, les échantillons de la même classe seront distribués près de W de cette classe, afin que f*W puisse atteindre la valeur maximale.
2 Nous avons donc trouvé une méthode très simple, qui consiste à inverser les fonctionnalités. Comme le montre la figure ci-dessous, il existe en fait deux méthodes d'attaque de classification courantes qui peuvent également être visualisées ensemble. Par exemple (a), il s'agit de supprimer la catégorie avec la probabilité de classification la plus élevée (telle que Fast Gradient), en donnant -Wmax, il y a donc une direction de propagation du gradient rouge le long de l'inverse de Wmax, comme (b), il y en a une autre ; moyen de supprimer la catégorie la moins probable. Les caractéristiques des catégories possibles sont affichées (telles que la moins probable), de sorte que le dégradé rouge est le long de Wmin.
3. Ces deux méthodes d'attaque de classification sont bien entendu très directes et efficaces dans les problèmes de classification traditionnels. Cependant, puisque les ensembles de tests dans le problème de récupération sont tous des catégories invisibles (espèces d'oiseaux invisibles), la distribution de f naturelle ne correspond pas étroitement à Wmax ou Wmin. Par conséquent, notre stratégie est très simple. Puisque nous avons f, alors nous pouvons simplement. déplacez f vers -f, comme le montre la figure (c).
De cette façon, dans l'étape de correspondance des caractéristiques, les résultats avec un classement élevé, idéalement, seront classés les plus bas lorsqu'ils sont calculés en tant que similarité cos avec -f, de proche de 1 à proche de -1.
Obtention de l'effet de notre tri de récupération d'attaque.
4. Une petite rallonge. Dans les problèmes de récupération, nous utilisons également souvent le multi-échelle pour l'augmentation des requêtes, nous avons donc également étudié comment maintenir l'effet d'attaque dans ce cas. (La principale difficulté est que l'opération de redimensionnement peut atténuer certaines instabilités petites mais critiques.)
En fait, notre méthode pour y faire face est également très simple, tout comme l'ensemble de modèles, nous faisons la moyenne des gradients contradictoires de plusieurs échelles. dans un ensemble. Très bien.
Expérience
1. Sous trois ensembles de données et trois indicateurs, nous avons fixé l'amplitude de gigue, qui est l'epsilon de l'abscisse, et comparé quelle méthode peut amener le modèle de récupération à commettre plus d'erreurs sous la même amplitude de gigue. Notre méthode est que les lignes jaunes sont toutes en bas, ce qui signifie que l'effet d'attaque est meilleur.
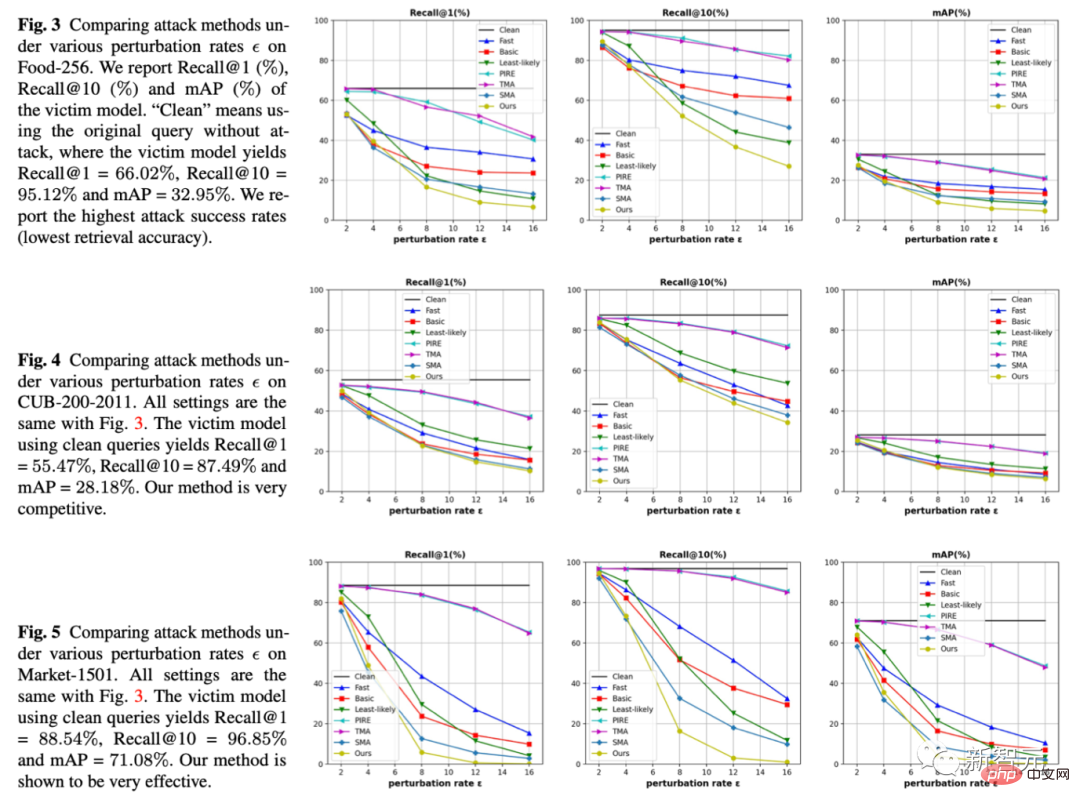
2. Nous fournissons également des résultats expérimentaux quantitatifs sur 5 ensembles de données (Alimentation, CUB, Marché, Oxford, Paris)
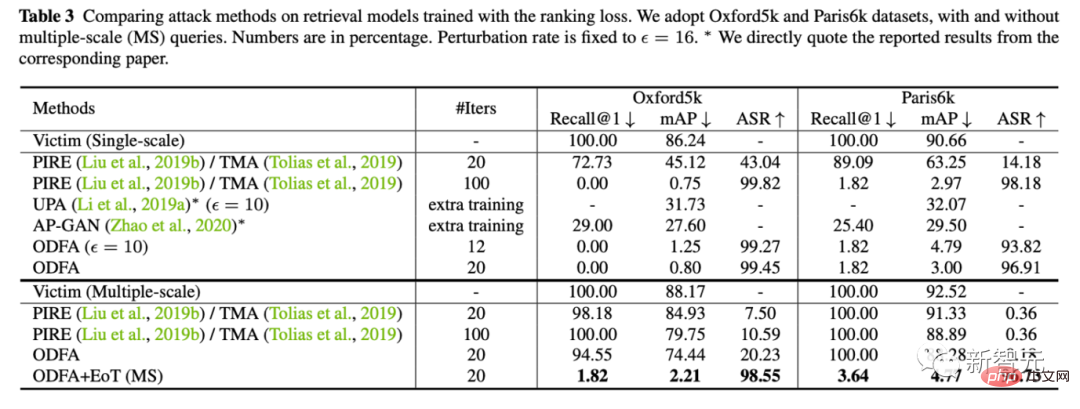
3. Pour démontrer le mécanisme du modèle, nous avons également essayé d'attaquer le modèle de classification sur Cifar10.
Vous pouvez voir que notre stratégie de modification de la dernière couche de fonctionnalités a également un fort pouvoir de suppression contre le top 5. Pour le top-1, puisqu’il n’y a pas de catégorie candidate, ce sera légèrement inférieur au moins probable, mais c’est presque pareil.
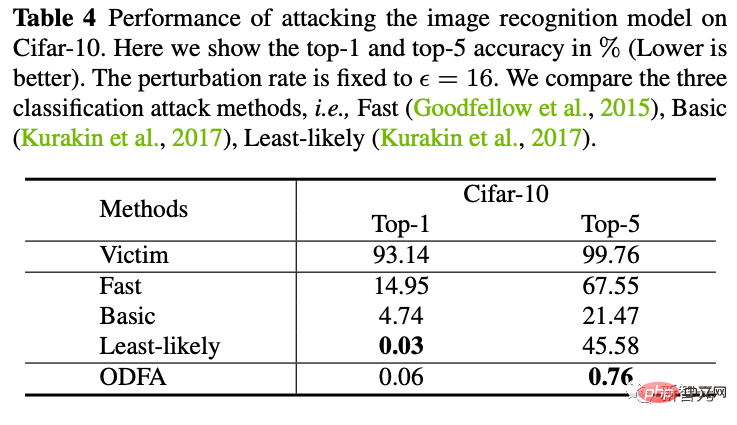
4. Attaque de boîte noire
Nous avons également essayé d'utiliser l'échantillon d'attaque généré par ResNet50 pour attaquer un modèle DenseNet de boîte noire (les paramètres de ce modèle ne nous sont pas disponibles). Il s’avère que de meilleures capacités d’attaque par migration peuvent également être obtenues.
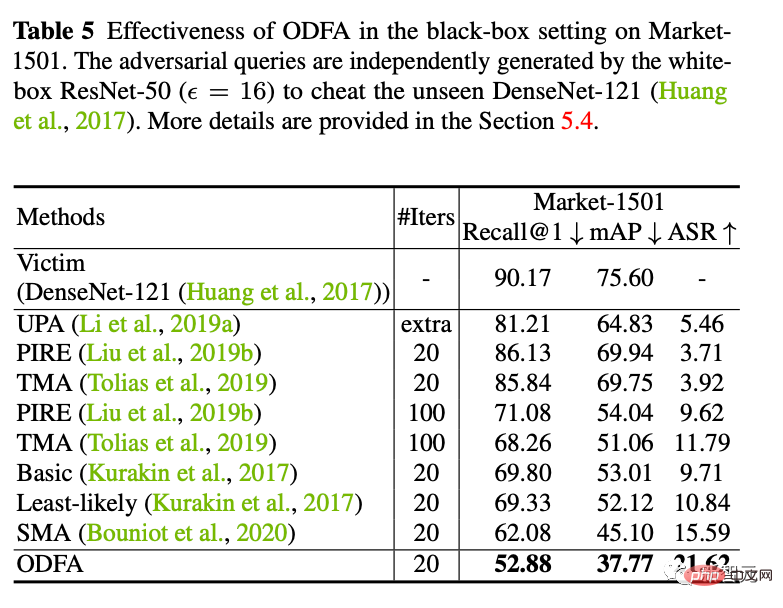
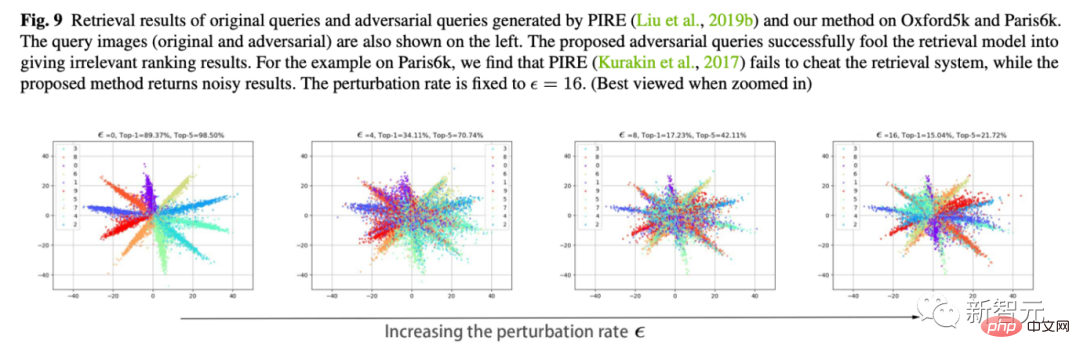
5. Nous utilisons la formation contradictoire en ligne pour former un modèle de défense. Nous avons constaté qu'il est toujours incapable d'accepter de nouvelles attaques en boîte blanche, mais il est plus stable dans les petites secousses (perd moins de points) qu'un modèle complètement sans défense. 6. Visualisation du mouvement des fonctionnalités C'est aussi mon expérience préférée. Nous utilisons Cifar10 pour changer la dimension de la dernière couche de classification à 2 afin de tracer les changements dans les caractéristiques de la couche de classification. Comme le montre la figure ci-dessous, à mesure que l'amplitude de gigue epsilon augmente, nous pouvons voir que les caractéristiques de l'échantillon "se retournent" lentement. Par exemple, la plupart des entités oranges se sont déplacées vers le côté opposé. 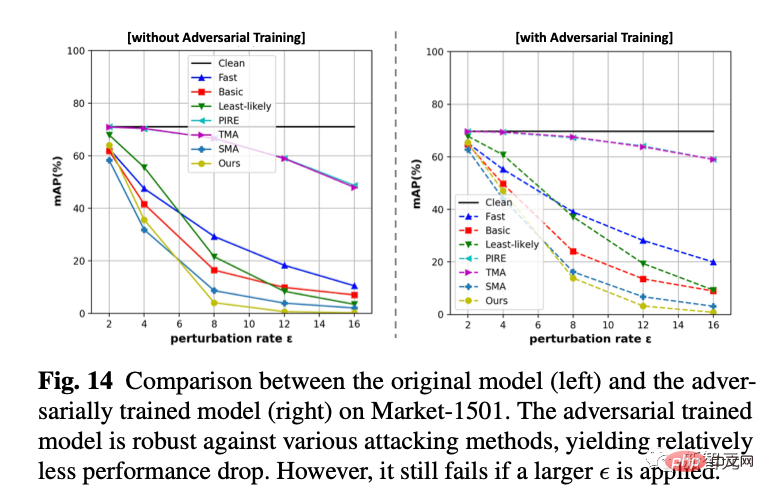
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI