
Maison >Périphériques technologiques >IA >Les utilisateurs ont dépassé le million en 5 jours, quel est le mystère derrière ChatGPT ?
Les utilisateurs ont dépassé le million en 5 jours, quel est le mystère derrière ChatGPT ?

- PHPzavant
- 2023-05-04 10:19:061265parcourir
Traducteur | Li Rui
Reviewer | Sun Shujuan
OpenAI est à nouveau populaire ! Récemment, de nombreuses personnes ont trouvé dans leur cercle d'amis un personnage impitoyable qui est à la fois aimé et craint, à tel point que StackOverflow a dû le retirer des étagères en toute hâte.
Récemment, OpenAI a lancé le chat AI ChatGPT En quelques jours seulement, sa base d'utilisateurs a atteint le million, et le serveur était même surchargé d'utilisateurs enregistrés.
Comment ce genre d'artefact dont les internautes s'émerveillent "dépasse la recherche Google" fait-il ? Est-ce fiable ?
1. Revue de l'événement
OpenAI a récemment publié ChatGPT, un autre grand modèle de langage (LLM) basé sur la série phare GPT, spécialement conçu pour le modèle d'interaction conversationnelle. Les utilisateurs peuvent télécharger la version démo gratuite de l'entreprise.
Comme la plupart des grands modèles de langage (LLM) publiés, la sortie de ChatGPT a également suscité une certaine controverse. Quelques heures seulement après sa sortie, le nouveau modèle linguistique a fait sensation sur Twitter, les utilisateurs téléchargeant des captures d'écran des réalisations impressionnantes ou des échecs catastrophiques de ChatGPT.
Cependant, vu dans la perspective large des grands modèles de langage, ChatGPT reflète l'histoire courte mais riche du domaine, représentant les progrès qui ont été réalisés en quelques années seulement et les questions fondamentales qui restent à résoudre. être résolu.
2. Le rêve de l'apprentissage non supervisé
L'apprentissage non supervisé est toujours l'un des objectifs poursuivis par la communauté de l'intelligence artificielle, et il existe de nombreuses connaissances et informations précieuses sur le Internet. Mais jusqu’à récemment, une grande partie de ces informations n’étaient pas accessibles aux systèmes d’apprentissage automatique. La plupart des applications d'apprentissage automatique et d'apprentissage profond sont supervisées, ce qui signifie que les humains doivent collecter un grand nombre d'échantillons de données et annoter chaque échantillon pour entraîner le système d'apprentissage automatique.
Avec l'avènement de l'architecture Transformer, composant clé des grands modèles de langage, cette situation a changé. Les modèles de transformateur peuvent être entraînés à l'aide de grands corpus de texte non étiqueté. Ils masquent aléatoirement des parties du texte et tentent de prédire les parties manquantes. En effectuant cette opération à plusieurs reprises, le Transformer ajuste ses paramètres pour représenter la relation entre les différents mots de la grande séquence.
Cela s'est avéré être une stratégie très efficace et évolutive. De très grands corpus de formation peuvent être collectés sans nécessiter d'étiquetage humain, permettant la création et la formation de modèles Transformer de plus en plus grands. Les recherches et les expériences montrent qu'à mesure que la taille des modèles Transformer et des grands modèles de langage (LLM) augmente, ils peuvent générer des séquences de texte cohérentes plus longues. Les grands modèles linguistiques (LLM) démontrent également des capacités d'urgence à grande échelle.
3. Apprentissage supervisé par régression ?
Les grands modèles de langage (LLM) sont généralement composés uniquement de texte, ce qui signifie qu'ils n'ont pas la riche expérience multisensorielle des humains qu'ils essaient d'acquérir. imiter. Bien que les grands modèles de langage (LLM) tels que GPT-3 obtiennent des résultats impressionnants, ils souffrent de certains défauts fondamentaux qui les rendent imprévisibles dans les tâches qui nécessitent du bon sens, de la logique, de la planification, du raisonnement et d'autres connaissances généralement omises du texte. Les grands modèles de langage (LLM) sont connus pour produire des réponses illusoires, générer un texte cohérent mais factuellement faux et interpréter souvent mal l'intention apparente des invites des utilisateurs.
En augmentant la taille du modèle et de son corpus de formation, les scientifiques ont pu réduire la fréquence des erreurs apparentes dans les grands modèles de langage. Mais le problème fondamental ne disparaît pas : même les plus grands modèles de langage (LLM) peuvent commettre des erreurs stupides avec très peu de pression.
Cela ne serait peut-être pas un gros problème si les grands modèles de langage (LLM) n'étaient utilisés que dans les laboratoires de recherche scientifique pour suivre les performances sur des benchmarks. Cependant, à mesure que l’intérêt pour l’utilisation de grands modèles de langage (LLM) dans des applications réelles augmente, il devient plus important de résoudre ces problèmes et d’autres encore. Les ingénieurs doivent s’assurer que leurs modèles d’apprentissage automatique restent robustes dans diverses conditions et répondent aux besoins et exigences des utilisateurs.
Pour résoudre ce problème, OpenAI utilise la technologie d'apprentissage par renforcement à partir de la rétroaction humaine (RLHF), qui a été précédemment développée pour optimiser les modèles d'apprentissage par renforcement. Plutôt que de laisser un modèle d'apprentissage par renforcement explorer aléatoirement son environnement et son comportement, l'apprentissage par renforcement avec feedback humain (RLHF) utilise le feedback occasionnel d'un superviseur humain pour guider l'agent dans la bonne direction. L’avantage de l’apprentissage par renforcement avec feedback humain (RLHF) est qu’il améliore la formation des agents d’apprentissage par renforcement avec un minimum de feedback humain.
OpenAI a ensuite appliqué l'apprentissage par renforcement avec feedback humain (RLHF) à InstructGPT, une famille de grands modèles de langage (LLM) conçus pour mieux comprendre et répondre aux instructions contenues dans les invites utilisateur. InstructGPT est un modèle GPT-3 affiné en fonction des commentaires humains.
C'est évidemment un compromis. L'annotation humaine peut devenir un goulot d'étranglement dans le processus de formation évolutif. Mais en trouvant le bon équilibre entre l’apprentissage non supervisé et supervisé, OpenAI est en mesure d’obtenir des avantages importants, notamment une meilleure réponse aux instructions, une réduction des résultats nuisibles et une optimisation des ressources. Selon les résultats de la recherche d’OpenAI, le modèle InstructionGPT à 1,3 milliard de paramètres surpasse généralement le modèle GPT-3 à 175 milliards de paramètres en matière de suivi d’instructions.
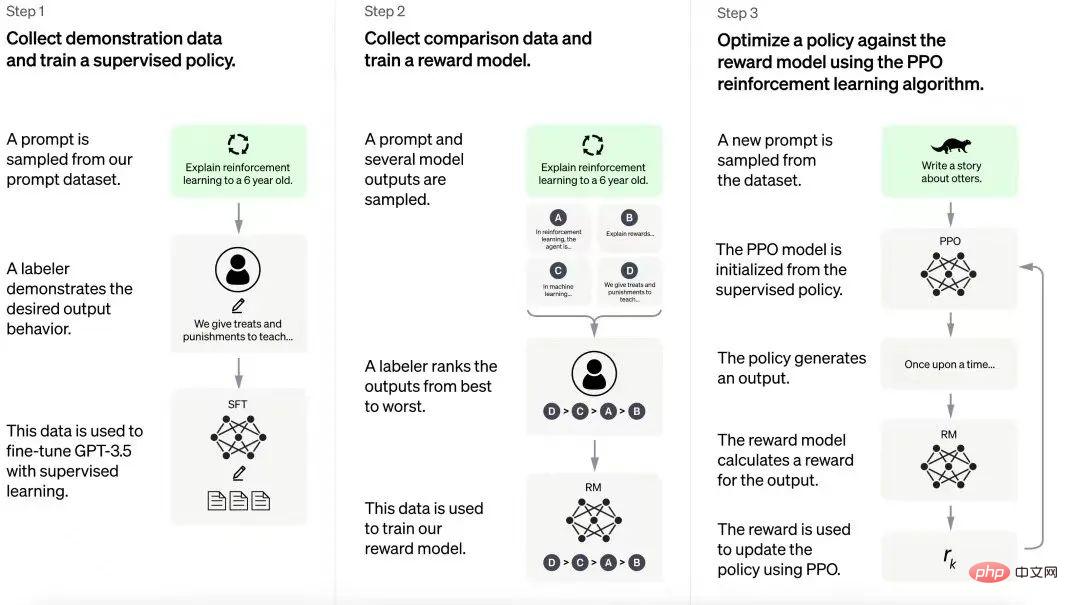
Processus de formation ChatGPT
ChatGPT s'appuie sur l'expérience acquise grâce au modèle InstructGPT. L'annotateur humain crée un ensemble d'exemples de conversations qui incluent des invites utilisateur et des réponses modèles. Ces données sont utilisées pour affiner le modèle GPT-3.5 sur lequel ChatGPT est construit. À l’étape suivante, le modèle affiné reçoit de nouvelles invites et plusieurs réponses. Les annotateurs classent ces réponses. Les données générées à partir de ces interactions sont ensuite utilisées pour former des modèles de récompense, ce qui permet d'affiner davantage les grands modèles de langage (LLM) dans les pipelines d'apprentissage par renforcement.
OpenAI n'a pas divulgué tous les détails du processus d'apprentissage par renforcement, mais les gens sont curieux de connaître le « coût non évolutif » de ce processus, c'est-à-dire la quantité de main-d'œuvre nécessaire.
4. Dans quelle mesure pouvez-vous faire confiance à ChatGPT ?
Les résultats de ChatGPT sont impressionnants. Le modèle a accompli diverses tâches, notamment fournir des commentaires sur le code, écrire de la poésie, expliquer des concepts techniques sur différents tons et générer des invites pour des modèles d'intelligence artificielle générative.
Cependant, ce modèle est également sujet à des erreurs similaires à celles commises par les grands modèles linguistiques (LLM), telles que la citation d'articles et de livres inexistants, une mauvaise compréhension de la physique intuitive et un échec en matière de composition.
Les gens ne sont pas surpris par ces échecs. ChatGPT ne fonctionne pas par magie et devrait souffrir des mêmes problèmes que son prédécesseur. Cependant, où et dans quelle mesure peut-on lui faire confiance dans les applications du monde réel ? Il y a clairement une certaine valeur ici, comme on peut le voir dans le Codex et GitHubCopilot que les grands modèles linguistiques (LLM) peuvent être utilisés très efficacement.
Ici, ce qui détermine si ChatGPT est utile ou non, c'est le type d'outils et de protection mis en œuvre avec celui-ci. Par exemple, ChatGPT pourrait devenir une très bonne plateforme pour créer des chatbots pour les entreprises, tels que des compagnons numériques pour le codage et la conception graphique. Premièrement, s'il suit l'exemple d'InstructGPT, vous devriez pouvoir obtenir les performances de modèles complexes avec moins de paramètres, ce qui le rendrait rentable. De plus, si OpenAI fournit des outils permettant aux entreprises de mettre en œuvre leur propre apprentissage par renforcement avec retour humain (RLHF), il peut être encore optimisé pour des applications spécifiques, qui dans la plupart des cas seront plus utiles que les chatbots. à propos de n'importe quoi. Enfin, si les développeurs d'applications disposent des outils nécessaires pour intégrer ChatGPT aux scénarios d'application et mapper ses entrées et sorties à des événements et actions d'application spécifiques, ils seront en mesure de définir les garde-fous appropriés pour empêcher les modèles de fonctionner de manière instable.
Fondamentalement, OpenAI a créé un outil d'intelligence artificielle puissant, mais avec des défauts évidents. Cela nécessite désormais de créer le bon écosystème d'outils de développement pour garantir que les équipes produit peuvent exploiter la puissance de ChatGPT. GPT-3 ouvre la voie à de nombreuses applications imprévisibles, il sera donc intéressant de savoir ce que ChatGPT nous réserve.
Lien original : https://bdtechtalks.com/2022/12/05/openai-chatgpt/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI