
Maison >Périphériques technologiques >IA >La prédiction hiérarchique du cerveau rend les grands modèles plus efficaces !
La prédiction hiérarchique du cerveau rend les grands modèles plus efficaces !

- 王林avant
- 2023-05-03 14:37:061802parcourir
100 milliards de neurones, chaque neurone possède environ 8 000 synapses. La structure complexe du cerveau inspire la recherche sur l'intelligence artificielle.
Actuellement, l'architecture de la plupart des modèles d'apprentissage profond est un réseau de neurones artificiels inspiré des neurones biologiques du cerveau.
L'explosion de l'IA générative montre que les algorithmes d'apprentissage profond deviennent de plus en plus puissants pour générer, résumer, traduire et classer du texte.
Cependant, ces modèles de langage ne peuvent toujours pas correspondre aux capacités du langage humain.
La théorie du codage prédictif fournit une explication préliminaire de cette différence :
Bien que les modèles linguistiques puissent prédire les mots proches, le cerveau humain prédira constamment les mots à travers plusieurs niveaux de représentation à l'échelle de temps.
Pour tester cette hypothèse, les scientifiques de Meta AI ont analysé les signaux cérébraux d'IRMf de 304 personnes qui écoutaient des histoires courtes.
Conclu que le codage prédictif hiérarchique joue un rôle essentiel dans le traitement du langage.
Des recherches illustrent comment la synergie entre les neurosciences et l'intelligence artificielle peut révéler les bases informatiques de la cognition humaine.
La dernière recherche a été publiée dans la sous-revue Nature Nature Human Behaviour.

Adresse papier : https://www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f
GPT-2 a été utilisé pendant l'expérience en disant, avenir incertain Cette recherche peut inspirer les modèles non ouverts d'OpenAI.
ChatGPT ne serait-il pas encore plus fort d'ici là ?
Brain Predictive Coding Layered
En moins de 3 ans, le deep learning a fait des progrès significatifs dans la génération de texte, la traduction, etc., grâce à un algorithme bien entraîné : prédire les mots en fonction du contexte proche.
Il a été démontré que l'activation de ces modèles correspond de manière linéaire aux réponses cérébrales à la parole et au texte.
De plus, cette cartographie dépend principalement de la capacité de l'algorithme à prédire les mots futurs, suggérant ainsi que cet objectif est suffisant pour qu'ils convergent vers des calculs de type cérébral.
Cependant, un écart existe encore entre ces algorithmes et le cerveau : malgré de grandes quantités de données d'entraînement, les modèles de langage actuels rencontrent des défis en matière de génération d'histoires longues, de dialogue résumant et cohérent et de récupération d'informations.
Parce que l'algorithme ne peut pas capturer certaines structures syntaxiques et propriétés sémantiques, et que la compréhension du langage est également très superficielle.
Par exemple, les algorithmes ont tendance à attribuer de manière incorrecte des verbes aux sujets dans des phrases imbriquées.
「les clés que l'homme détient SONT ici」
De même, lorsque la génération de texte est optimisée uniquement pour la prédiction du mot suivant, les modèles de langage profond généreront une séquence de texte fade et incohérente, ou resteront bloqués. dans une boucle infiniment répétitive.
Actuellement, la théorie du codage prédictif fournit une explication potentielle à ce défaut :
Bien que les modèles de langage profond soient principalement conçus pour prédire le mot suivant, ce cadre montre que le cerveau humain peut fonctionner sur plusieurs échelles de temps et corticales. représentations à plusieurs niveaux.
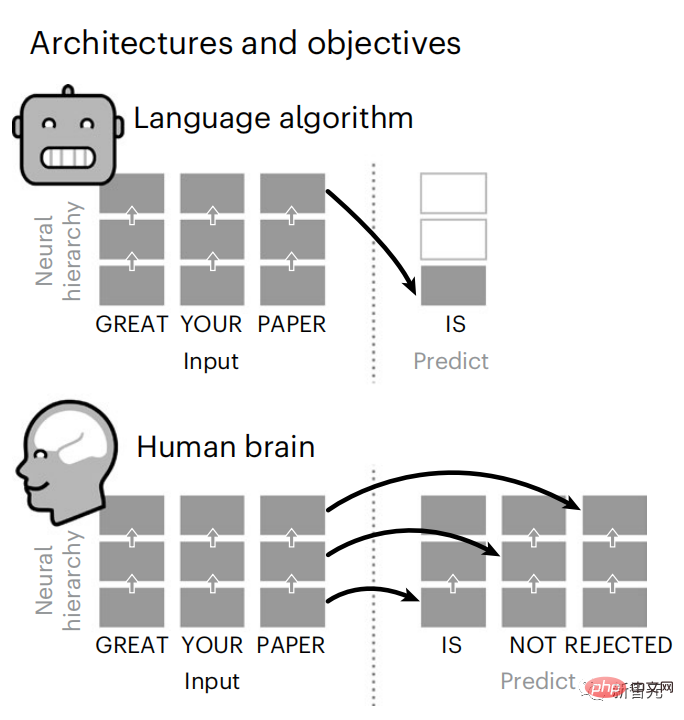
Des recherches antérieures ont démontré la prédiction de la parole dans le cerveau, c'est-à-dire un mot ou un phonème, corrélée à l'imagerie par résonance magnétique fonctionnelle (IRMf), à l'électroencéphalographie, à la magnétoencéphalographie et à l'électrocorticographie.
Un modèle entraîné à prédire le prochain mot ou phonème peut réduire sa sortie à un seul nombre, la probabilité du prochain symbole.
Cependant, la nature et l'échelle temporelle des représentations prédictives sont largement inconnues.
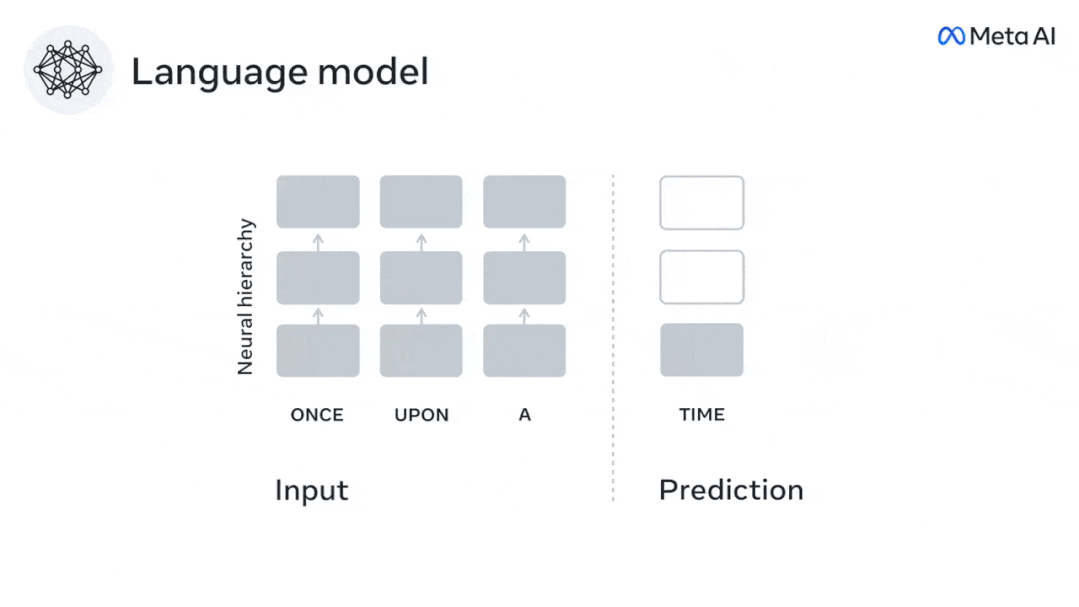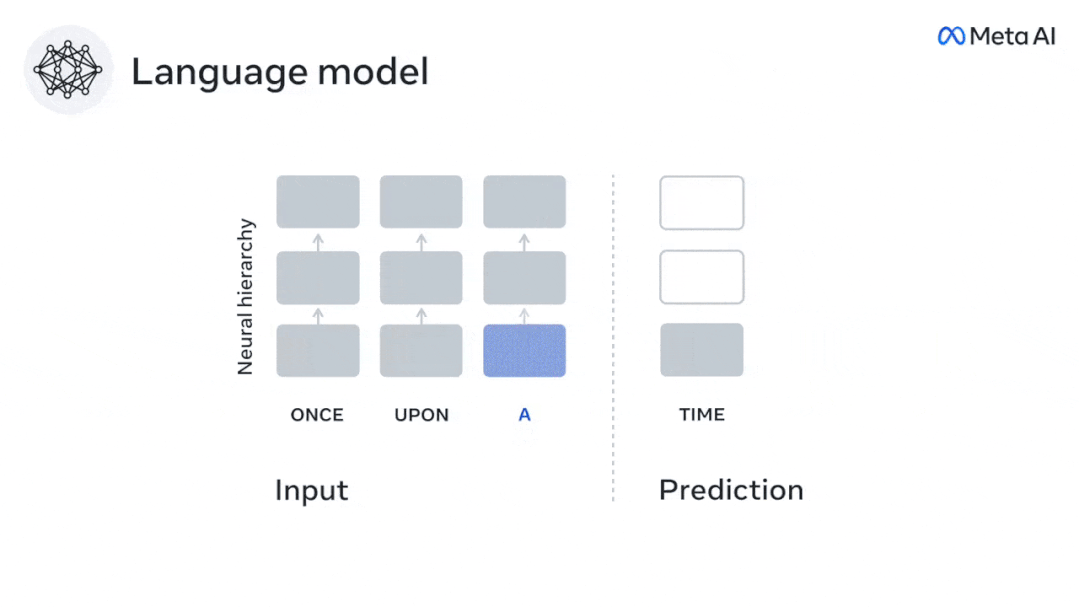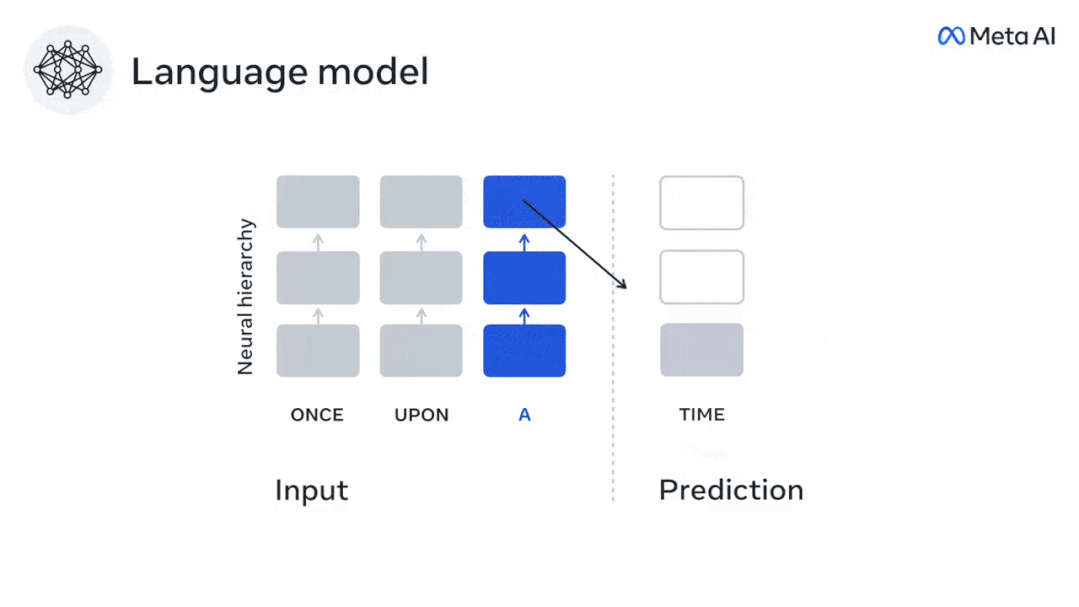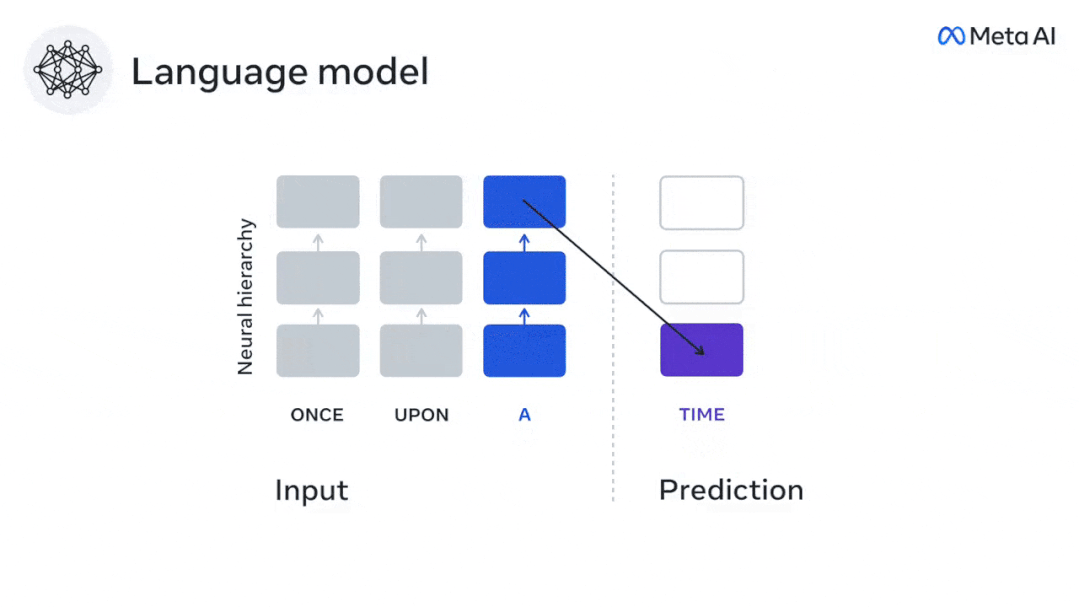
Dans cette étude, les chercheurs ont extrait les signaux IRMf de 304 personnes, ont demandé à chaque personne d'écouter une nouvelle (Y) pendant environ 26 minutes et de saisir le même contenu pour activer l'algorithme de langage ( X).
Ensuite, la similarité entre X et Y est quantifiée par le « score cérébral », qui est le coefficient de corrélation de Pearson (R) après la meilleure cartographie linéaire W.
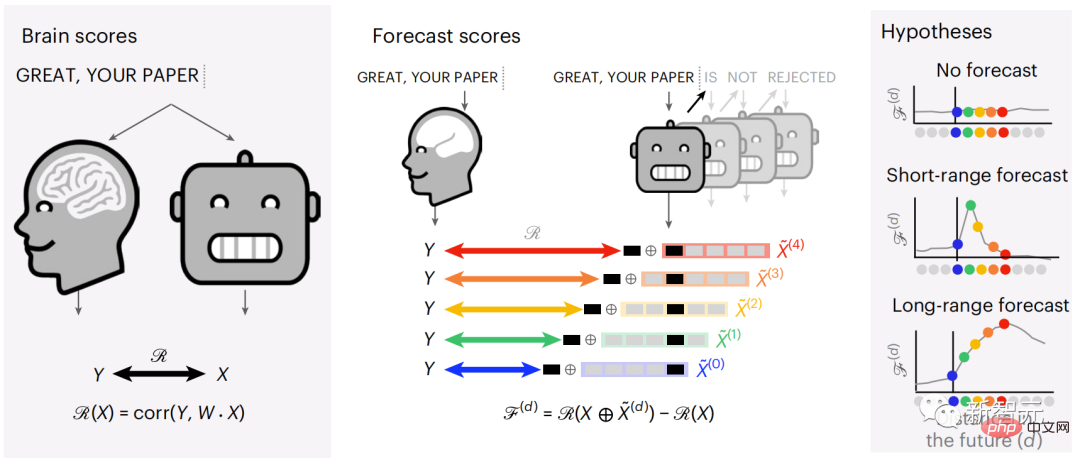
Pour tester si l'ajout d'une représentation du mot prédit améliore cette corrélation, connectez l'activation du réseau (rectangle noir X) à la fenêtre de prédiction (rectangle coloré ~X), puis utilisez PCA pour diviser la fenêtre de prédiction La dimensionnalité de est réduite à la dimensionnalité de X.
Finalement F quantifie le gain de score cérébral obtenu en améliorant l'activation de cette fenêtre de prédiction par l'algorithme du langage. Nous répétons cette analyse (d) avec différentes fenêtres de distance.
Il a été constaté que cette cartographie cérébrale pouvait être améliorée en augmentant ces algorithmes avec des prédictions qui s'étendent sur plusieurs échelles de temps, c'est-à-dire des prédictions à long terme et des prédictions hiérarchiques.
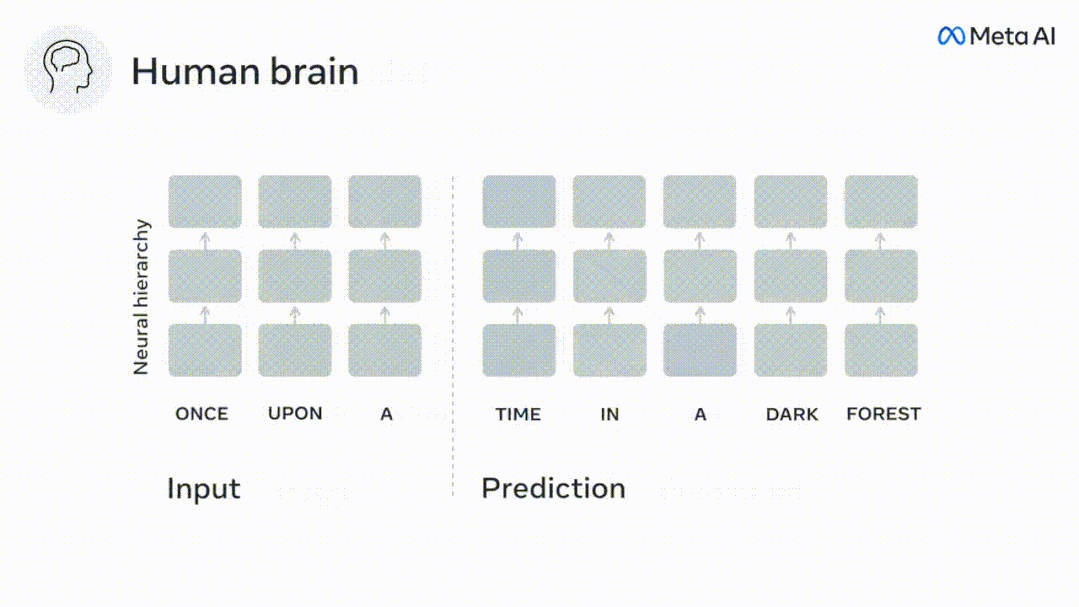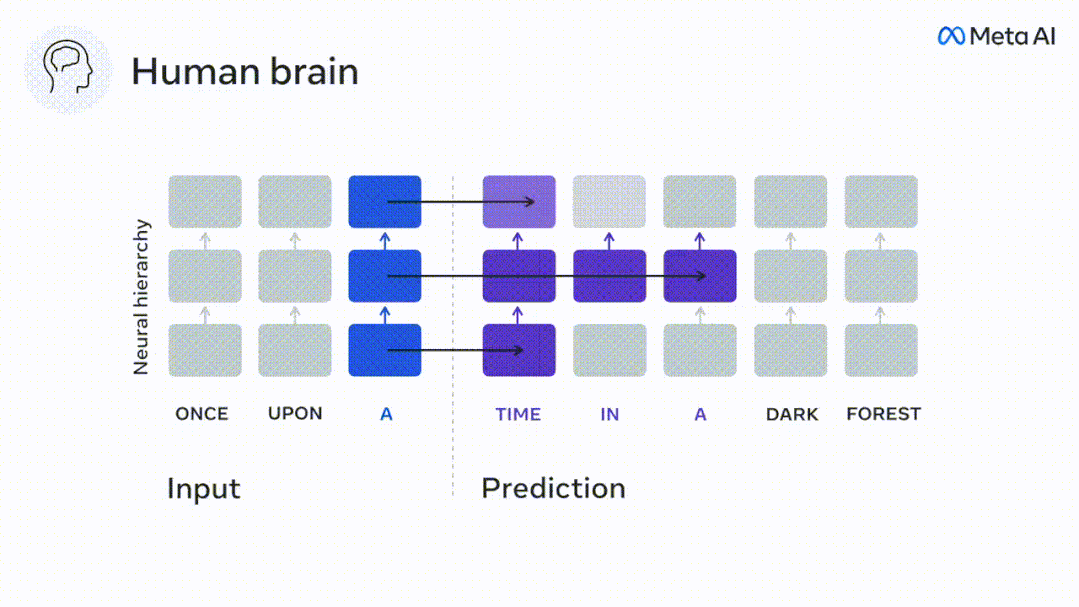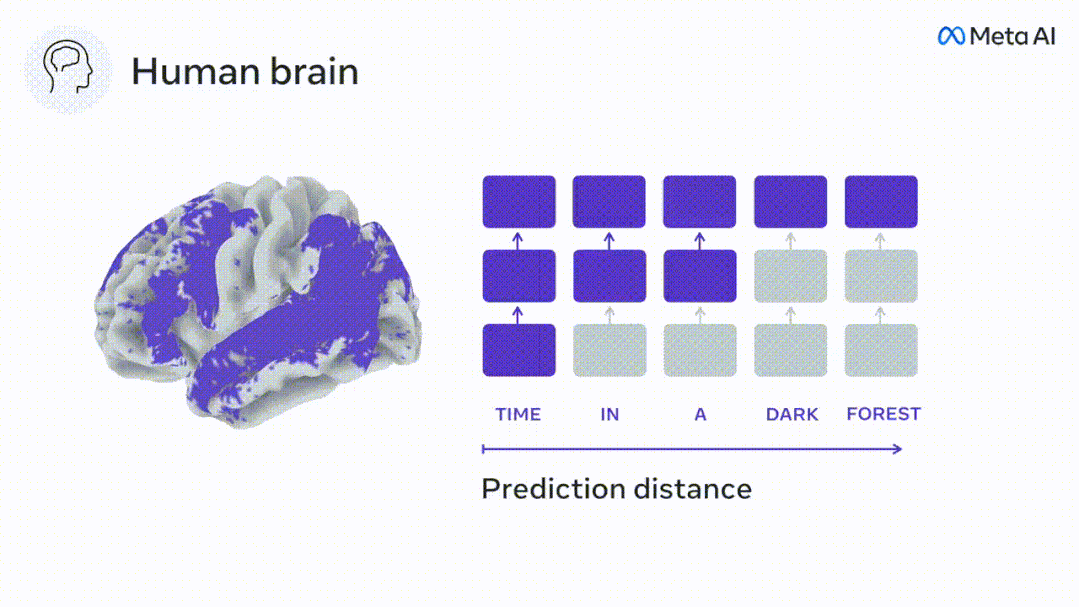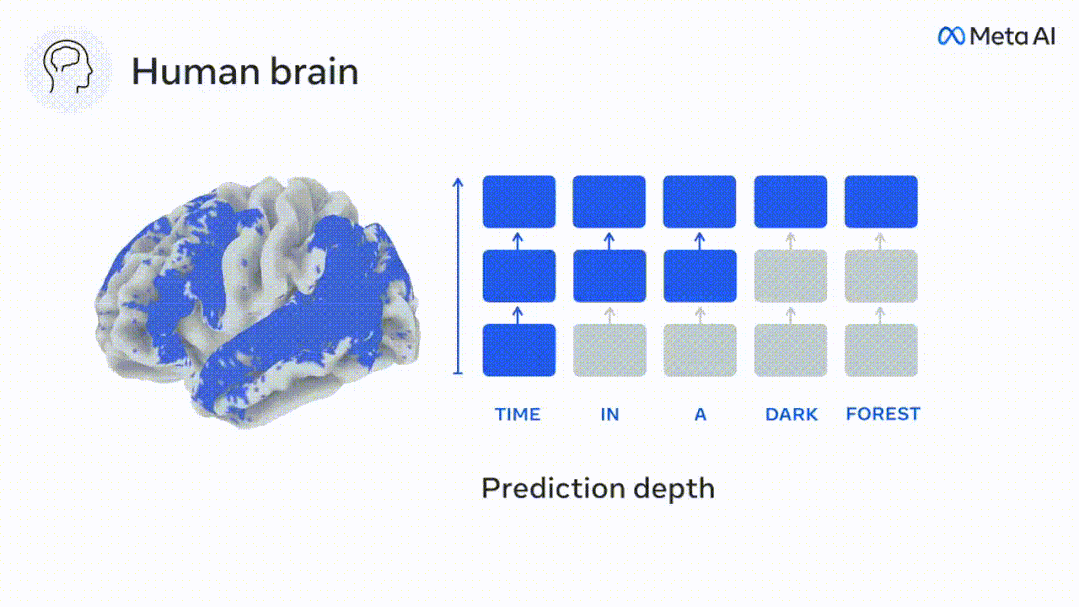
Enfin, des résultats expérimentaux ont montré que ces prédictions sont organisées hiérarchiquement : le cortex frontal prédit des représentations de niveau supérieur, à plus grande échelle et plus contextuelles que le cortex temporal. Les chercheurs ont étudié quantitativement la similitude entre le modèle de langage profond et le cerveau lorsque le contenu d'entrée est le même.
Effectuez une régression de crête linéaire indépendante sur les résultats de chaque voxel et de chaque individu expérimental pour prédire le signal IRMf résultant de l'activation de plusieurs modèles de langage profond.
À l'aide des données conservées, nous avons calculé le « score cérébral » correspondant, c'est-à-dire la corrélation entre le signal IRMf et les résultats de prédiction de régression de crête obtenus en saisissant le stimulus du modèle de langage spécifié.
Pour plus de clarté, concentrez-vous d'abord sur les activations de la huitième couche de GPT-2, un réseau neuronal profond causal à 12 couches alimenté par HuggingFace2 qui prédit le mieux l'activité cérébrale.
Conformément aux études précédentes, les résultats de l'activation de GPT-2 ont été cartographiés avec précision sur un ensemble distribué de régions cérébrales bilatérales, les scores cérébraux atteignant le cortex auditif et les régions temporales antérieures et supérieures.
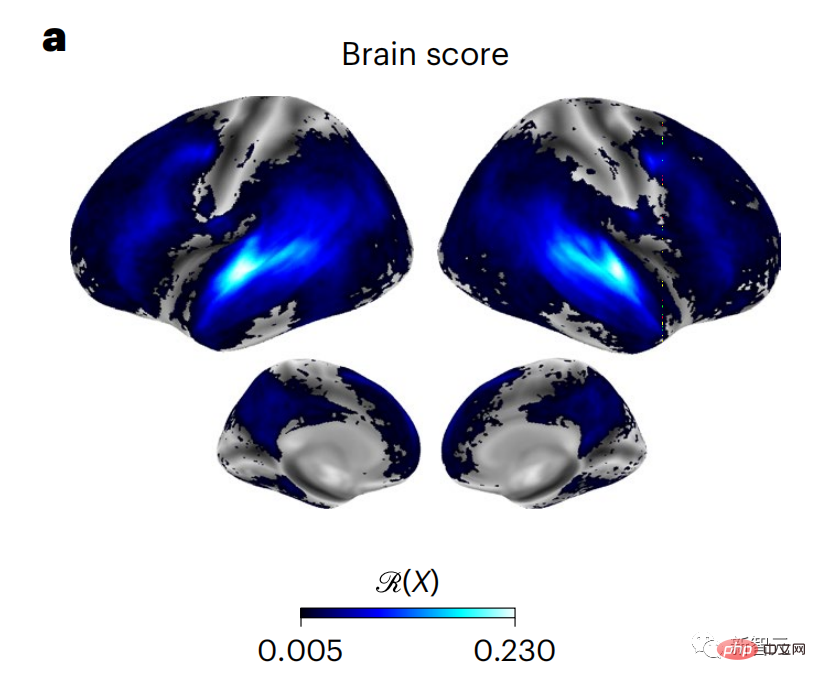
L'équipe Meta a ensuite testé si une stimulation croissante du modèle de langage avec des capacités de prédiction à longue portée pouvait conduire à des scores cérébraux plus élevés.
Pour chaque mot, les chercheurs ont connecté le modèle d'activation du mot actuel à une « fenêtre de prédiction » composée de mots futurs. Les paramètres de représentation de la fenêtre de prédiction incluent d, qui représente la distance entre le mot actuel et le dernier mot futur dans la fenêtre, et w, qui représente le nombre de mots concaténés. Pour chaque d, comparez les scores cérébraux avec et sans la représentation prédictive et calculez le « score de prédiction ».
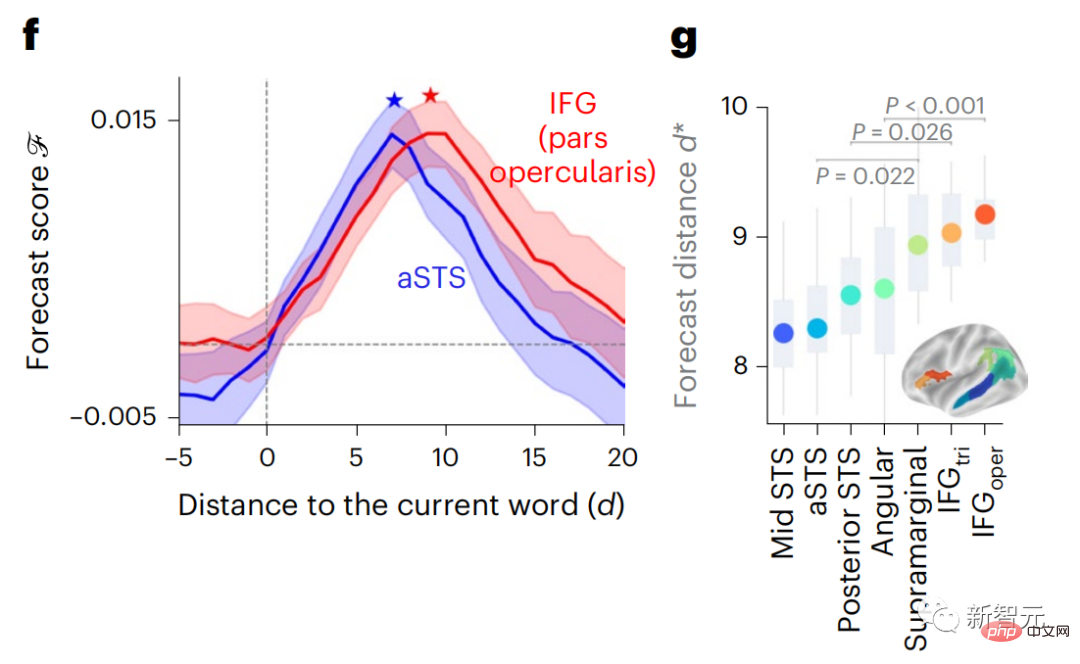
Les résultats ont montré que le score de prédiction était le plus élevé lorsque d=8, et la valeur maximale apparaissait dans la zone du cerveau liée à traitement du langage.
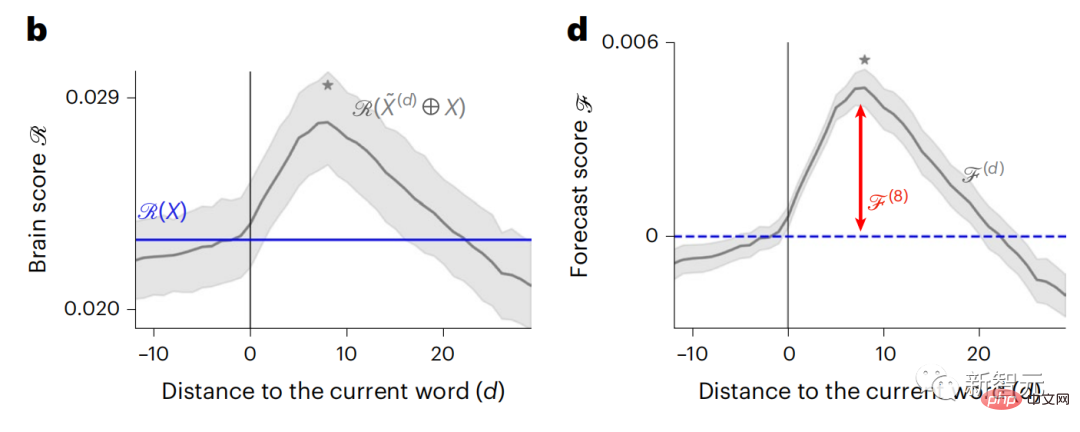
d=8 correspond à 3,15 secondes d'audio, soit deux consécutif L’heure de l’analyse IRMf. Les scores de prédiction étaient distribués bilatéralement dans le cerveau, sauf dans les gyri frontaux inférieurs et supramarginaux.
Grâce à une analyse supplémentaire, l'équipe a également obtenu les résultats suivants : (1) Chaque mot futur avec une distance de 0 à 10 de le mot actuel contribue de manière significative aux résultats de prédiction ; (2) Les représentations prédictives sont mieux capturées avec une taille de fenêtre d'environ 8 mots ; (3) Les représentations de prédiction aléatoires ne peuvent pas améliorer les scores cérébraux (4) Par rapport aux mots futurs réels, GPT-2 ; Les mots générés obtiennent des résultats similaires mais avec des scores inférieurs.
Le délai prévu change selon les niveaux du cerveau
#🎜🎜 ## 🎜🎜#Des études anatomiques et fonctionnelles ont montré que le cortex cérébral est stratifié. Les fenêtres temporelles de prédiction sont-elles les mêmes pour les différents niveaux de cortex ? Les chercheurs ont estimé le score de prédiction maximal de chaque voxel et ont exprimé la distance correspondante sous la forme d.
Les résultats ont montré que le d correspondant à l'apparition du pic prédit dans la zone préfrontale était en moyenne plus grand que dans la zone temporale Dans la zone du lobe (Figure 2e), le d du gyrus temporal inférieur est plus grand que le sillon temporal supérieur.
La meilleure distance de prédiction change le long de l'axe temporal-pariétal-frontal dans Les deux hémisphères du cerveau sont fondamentalement symétriques.
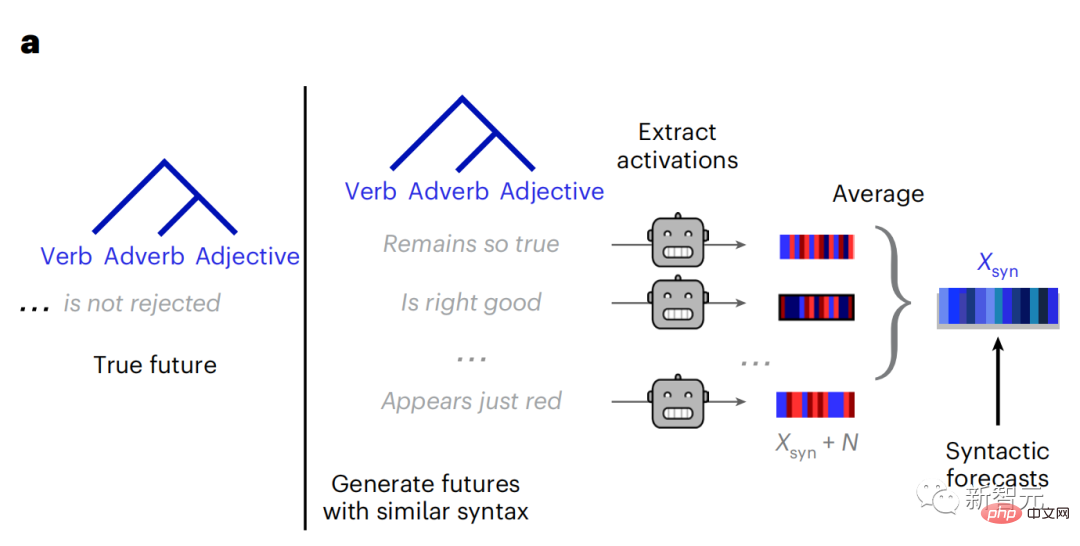
Pour chaque mot et son contexte précédent, générer dix mots futurs possibles qui correspondent à la syntaxe des mots futurs réels. Pour chaque mot futur possible, l'activation GPT-2 correspondante est extraite et moyennée. Cette approche est capable de décomposer l'activation d'un modèle de langage donné en composants syntaxiques et sémantiques, calculant ainsi leurs scores de prédiction respectifs.
Les résultats montrent que la prédiction sémantique est longue distance (d = 8), implique un réseau distribué culminant dans les lobes frontaux et pariétaux, alors que la prédiction syntaxique a une portée plus courte (d = 5) et est concentrée dans les zones temporales supérieures et frontales gauches.
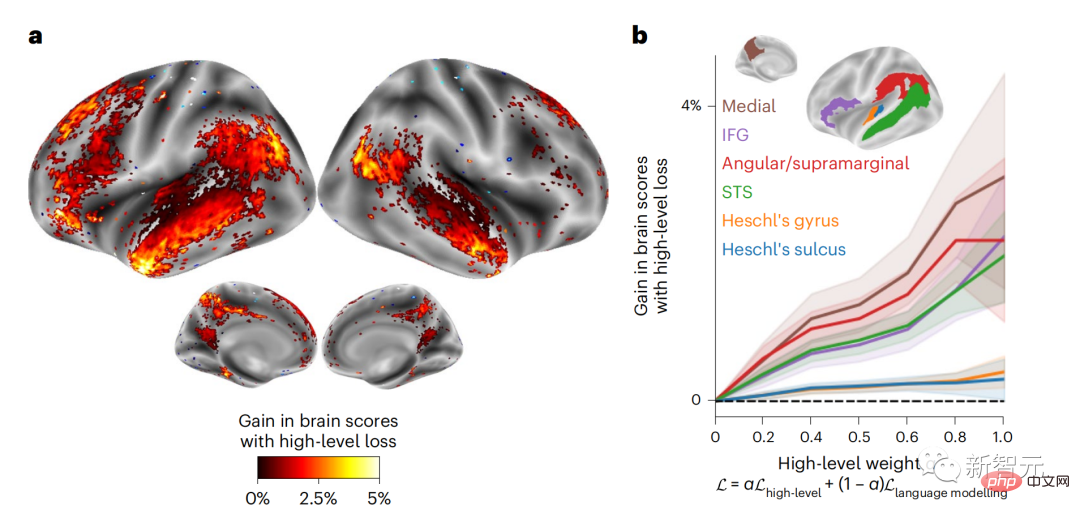
Ces résultats révèlent de multiples niveaux de prédiction dans le cerveau, où le cortex temporal supérieur prédit principalement les représentations à court terme, superficielles et syntaxiques, tandis que les régions frontales et pariétales inférieures prédisent principalement les représentations à long terme, contextuelles, de haut niveau et sémantiques. représentations. L'arrière-plan prédit devient plus complexe le long de la hiérarchie cérébrale Toujours en calculant le score de prédiction comme avant, mais en changeant la couche d'utilisation de GPT-2 pour déterminer k pour chaque voxel, c'est-à-dire la profondeur à lequel le score de prédiction est maximisé. Nos résultats montrent que la profondeur de prédiction optimale varie le long de la hiérarchie corticale attendue, le cortex associatif ayant le meilleur modèle pour des prédictions plus profondes que les zones linguistiques de niveau inférieur. Les différences entre les régions, bien que faibles en moyenne, sont très visibles selon les individus. En général, l'arrière-plan de prédiction à long terme du cortex frontal est plus complexe et de niveau supérieur que l'arrière-plan de prédiction à court terme des zones cérébrales de bas niveau. Ajustez GPT-2 à une structure de codage prédictive La concaténation des représentations de GPT-2 des mots actuels et des mots futurs peut conduire à de meilleurs modèles d'activité cérébrale, en particulier dans la zone frontale. Le réglage fin de GPT-2 pour prédire les représentations à de plus grandes distances, avec un contexte plus riche et à des niveaux plus élevés peut-il améliorer la cartographie cérébrale dans ces régions ? Dans l'ajustement, non seulement la modélisation du langage est utilisée, mais également des cibles de haut niveau et à longue portée. La cible de haut niveau ici est la 8ème couche du modèle GPT-2 pré-entraîné. Les résultats ont montré que le réglage fin du GPT-2 avec des paires de modélisation de haut niveau et à longue portée améliorait au mieux la réponse du lobe frontal, tandis que les zones auditives et les zones cérébrales de niveau inférieur ne bénéficiaient pas de ce niveau élevé. ciblage à plusieurs niveaux L'avantage évident reflète en outre le rôle des zones frontales dans la prédiction des représentations du langage à longue portée, contextuelles et de haut niveau. Référence : https://www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f 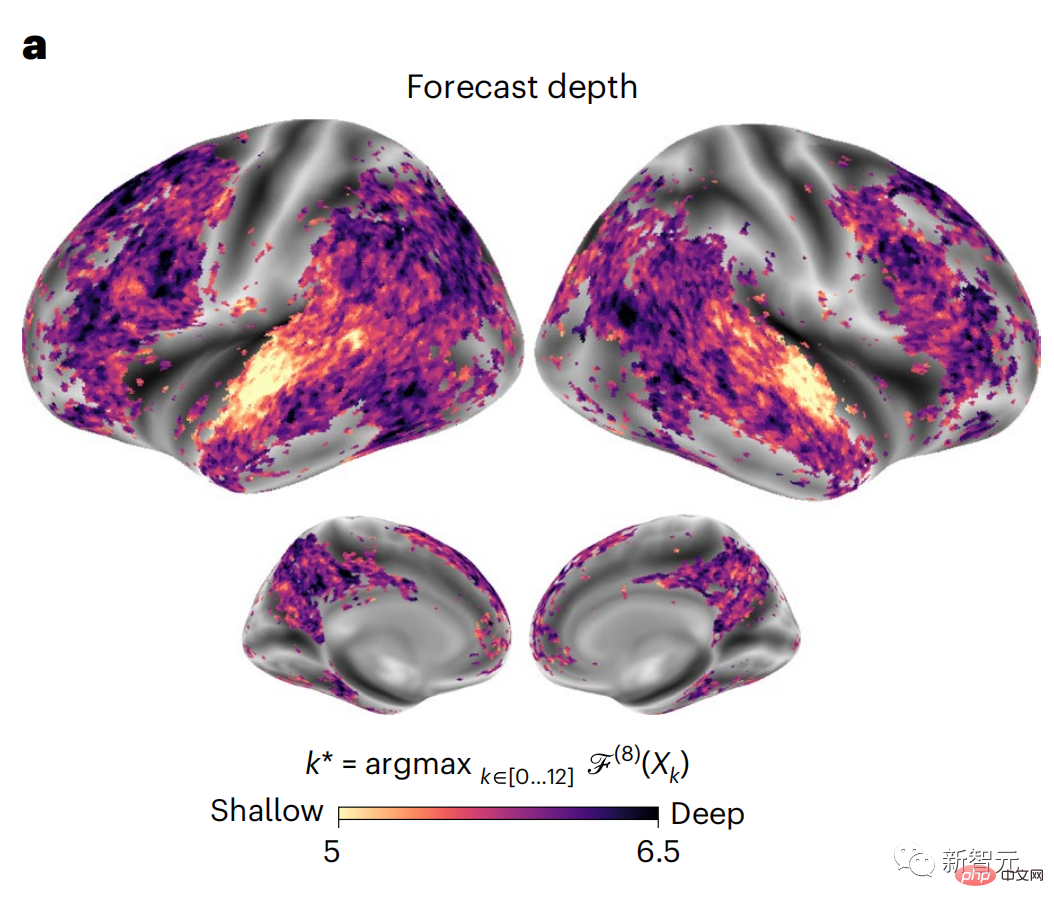
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI