
Maison >développement back-end >Tutoriel Python >Comment utiliser Jieba pour les statistiques de fréquence des mots et l'extraction de mots clés en Python
Comment utiliser Jieba pour les statistiques de fréquence des mots et l'extraction de mots clés en Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-02 19:46:054564parcourir
1 Statistiques de fréquence des mots
1.1 Statistiques de fréquence des mots simples
1. Importez la bibliothèque jieba et définissez le textejieba库并定义文本
import jieba text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
2.对文本进行分词
words = jieba.cut(text)
这一步会将文本分成若干个词语,并返回一个生成器对象words,可以使用for循环遍历所有的词语。
3. 统计词频
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1这一步通过遍历所有的词语,统计每个词语出现的次数,并保存到一个字典word_count中。在统计词频时,可以通过去除停用词等方式进行优化,这里只是简单地过滤了长度小于2的词语。
4. 结果输出
for word, count in word_count.items():
print(word, count)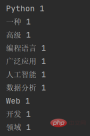
1.2 加入停用词
为了更准确地统计词频,我们可以在词频统计中加入停用词,以去除一些常见但无实际意义的词语。具体步骤如下:
定义停用词列表
import jieba # 停用词列表 stopwords = ['是', '一种', '等']
对文本进行分词,并过滤停用词
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
统计词频并输出结果
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)加入停用词后,输出的结果是:
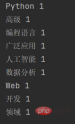
可以看到,被停用的一种这个词并没有显示出来。
2 关键词提取
2.1 关键词提取原理
与对词语进行单纯计数的词频统计不同,jieba提取关键字的原理是基于TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF算法是一种常用的文本特征提取方法,可以衡量一个词语在文本中的重要程度。
具体来说,TF-IDF算法包含两个部分:
Term Frequency(词频):指一个词在文本中出现的次数,通常用一个简单的统计值表示,例如词频、二元词频等。词频反映了一个词在文本中的重要程度,但是忽略了这个词在整个语料库中的普遍程度。
Inverse Document Frequency(逆文档频率):指一个词在所有文档中出现的频率的倒数,用于衡量一个词的普遍程度。逆文档频率越大,表示一个词越普遍,重要程度越低;逆文档频率越小,表示一个词越独特,重要程度越高。
TF-IDF算法通过综合考虑词频和逆文档频率,计算出每个词在文本中的重要程度,从而提取关键字。在jieba中,关键字提取的具体实现包括以下步骤:
对文本进行分词,得到分词结果。
统计每个词在文本中出现的次数,计算出词频。
统计每个词在所有文档中出现的次数,计算出逆文档频率。
综合考虑词频和逆文档频率,计算出每个词在文本中的TF-IDF值。
对TF-IDF值进行排序,选取得分最高的若干个词作为关键字。
举个例子:
F(Term Frequency)指的是某个单词在一篇文档中出现的频率。计算公式如下:
T F = ( 单词在文档中出现的次数 ) / ( 文档中的总单词数 )
例如,在一篇包含100个单词的文档中,某个单词出现了10次,则该单词的TF为
10 / 100 = 0.1
IDF(Inverse Document Frequency)指的是在文档集合中出现某个单词的文档数的倒数。计算公式如下:
I D F = l o g ( 文档集合中的文档总数 / 包含该单词的文档数 )
例如,在一个包含1000篇文档的文档集合中,某个单词在100篇文档中出现过,则该单词的IDF为 l o g ( 1000 / 100 ) = 1.0
TFIDF是将TF和IDF相乘得到的结果,计算公式如下:
T F I D F = T F ∗ I D F
需要注意的是,TF-IDF算法只考虑了词语在文本中的出现情况,而忽略了词语之间的关联性。因此,在一些特定的应用场景中,需要使用其他的文本特征提取方法,例如词向量、主题模型等。
2.2 关键词提取代码
import jieba.analyse
# 待提取关键字的文本
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
# 使用jieba提取关键字
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 输出关键字和对应的权重
for keyword, weight in keywords:
print(keyword, weight)在这个示例中,我们首先导入了jieba.analyse模块,然后定义了一个待提取关键字的文本text。接着,我们使用jieba.analyse.extract_tags()函数提取关键字,其中topK参数表示需要提取的关键字个数,withWeightrrreee
2 Segmentez le texte
Cette étape divisera le texte en plusieurs. mots, et renvoie un objet générateur mots, qui peut être utilisé pour parcourir tous les mots en utilisant for. 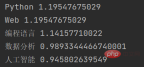
word_count. Lors du comptage des fréquences de mots, l'optimisation peut être effectuée en supprimant les mots vides. Ici, les mots d'une longueur inférieure à 2 sont simplement filtrés. 🎜🎜4. Sortie du résultat🎜rrreee🎜🎜🎜1.2 Ajouter des mots vides🎜🎜Afin de compter la fréquence des mots avec plus de précision, nous pouvons ajouter des mots vides aux statistiques de fréquence des mots pour supprimer certains mots courants mais dénués de sens. Les étapes spécifiques sont les suivantes : 🎜🎜 Définir la liste des mots vides 🎜rrreee🎜 Segmenter le texte et filtrer les mots vides 🎜rrreee🎜 Compter la fréquence des mots et afficher les résultats 🎜rrreee🎜 Après avoir ajouté les mots vides, le résultat de sortie est : 🎜🎜 🎜🎜Vous pouvez le constater, le mot désactivé a n'est pas affiché. 🎜🎜2 Extraction de mots-clés🎜🎜2.1 Principe d'extraction de mots-clés🎜🎜 Différent des statistiques de fréquence des mots qui comptent simplement les mots, le principe d'extraction de mots-clés de Jieba est basé sur l'algorithme TF-IDF (Term Frequency-Inverse Document Frequency). L'algorithme TF-IDF est une méthode d'extraction de caractéristiques de texte couramment utilisée qui peut mesurer l'importance d'un mot dans le texte. 🎜🎜Plus précisément, l'algorithme TF-IDF contient deux parties : 🎜- 🎜Fréquence du terme : fait référence au nombre de fois qu'un mot apparaît dans le texte, généralement utilisé. Un simple représentation de valeurs statistiques, telles que la fréquence des mots, la fréquence des mots bigrammes, etc. La fréquence des mots reflète l’importance d’un mot dans le texte, mais ignore la prévalence du mot dans l’ensemble du corpus. 🎜
- 🎜Inverse Document Frequency (fréquence inverse des documents) : désigne l'inverse de la fréquence d'un mot apparaissant dans tous les documents, utilisée pour mesurer la prévalence d'un mot. Plus la fréquence inverse du document est élevée, plus un mot est courant et plus son importance est faible ; plus la fréquence inverse du document est faible, plus le mot est unique et plus son importance est élevée. 🎜
- 🎜 Effectuer une segmentation de mots sur le texte et obtenir les résultats de la segmentation de mots. 🎜
- 🎜Comptez le nombre de fois où chaque mot apparaît dans le texte et calculez la fréquence des mots. 🎜
- 🎜Comptez le nombre de fois que chaque mot apparaît dans tous les documents et calculez la fréquence inverse des documents. 🎜
- 🎜Considération complète de la fréquence des mots et de la fréquence inverse des documents, calculez la valeur TF-IDF de chaque mot dans le texte. 🎜
- 🎜 Triez les valeurs TF-IDF et sélectionnez les mots avec les scores les plus élevés comme mots-clés. 🎜
🎜Par exemple : 🎜F (Term Frequency) fait référence à la fréquence à laquelle un mot apparaît dans un document. La formule de calcul est la suivante : 🎜T F = (le nombre de fois qu'un mot apparaît dans le document) / (le nombre total de mots dans le document) 🎜Par exemple, dans un document contenant 100 mots, si un certain mot apparaît 10 fois, alors le mot Le TF est 🎜10 / 100 = 0,1 🎜IDF (Inverse Document Frequency) fait référence à l'inverse du nombre de documents dans lesquels un certain mot apparaît dans la collection de documents. La formule de calcul est la suivante : 🎜I D F = log (nombre total de documents dans la collection de documents / nombre de documents contenant le mot) 🎜Par exemple, dans une collection de documents contenant 1 000 documents, un certain mot apparaît dans 100 documents, puis le L'IDF d'un mot est l o g (1000 / 100) = 1,0🎜TFIDF est le résultat de la multiplication de TF et IDF La formule de calcul est la suivante :🎜T F I D F = T F ∗ TF-IDF L'algorithme considère uniquement l'occurrence des mots dans le texte et ignore la corrélation entre les mots. Par conséquent, dans certains scénarios d'application spécifiques, d'autres méthodes d'extraction de caractéristiques de texte doivent être utilisées, telles que des vecteurs de mots, des modèles de sujets, etc. 🎜🎜2.2 Code d'extraction de mots clés🎜rrreee🎜Dans cet exemple, nous avons d'abord importé le modulejieba.analyse, puis défini un textetextpour les mots-clés à extraire. Ensuite, nous utilisons la fonctionjieba.analyse.extract_tags()pour extraire des mots-clés, où le paramètretopKindique le nombre de mots-clés à extraire,withWeight code> Le paramètre indique s'il faut renvoyer la valeur de poids du mot-clé. Enfin, nous parcourons la liste de mots-clés et affichons chaque mot-clé et la valeur de poids correspondante. 🎜Le résultat de sortie de cette fonction est : 🎜🎜🎜🎜<p>Comme vous pouvez le voir, jieba a extrait plusieurs mots-clés dans le texte d'entrée sur la base de l'algorithme TF-IDF et a renvoyé la valeur de poids de chaque mot-clé. </p>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!