
Maison >Périphériques technologiques >IA >Plusieurs conseils pour éviter les pièges lors de l'utilisation de ChatGLM
Plusieurs conseils pour éviter les pièges lors de l'utilisation de ChatGLM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-02 13:58:062175parcourir
J'ai dit hier que j'avais déployé un ensemble de ChatGLM après mon retour du Data Technology Carnival et que j'avais prévu d'étudier l'utilisation de grands modèles de langage pour former la base de connaissances sur l'exploitation et la maintenance des bases de données. De nombreux amis n'y croyaient pas, disant que vous l'étiez déjà. Tu as ton âge, Lao Bai, et tu peux toujours le faire toi-même. Lancer ces choses ? Afin de dissiper les doutes de ces amis, je partagerai avec vous le processus de lancement de ChatGLM au cours des deux derniers jours d'aujourd'hui, et je partagerai également quelques conseils pour éviter les pièges pour les amis intéressés à lancer ChatGLM.
ChatGLM-6B est développé sur la base du modèle de langage GLM formé conjointement par le laboratoire KEG de l'Université Tsinghua et Zhipu AI en 2023. Il s'agit d'un modèle de langage à grande échelle qui fournit des réponses et une prise en charge appropriées aux questions et exigences des utilisateurs. La réponse ci-dessus est répondue par ChatGLM lui-même. GLM-6B est un modèle open source pré-entraîné avec 6,2 milliards de paramètres. Sa caractéristique est qu'il peut être exécuté localement dans un environnement matériel relativement petit. Cette fonctionnalité permet aux applications basées sur de grands modèles linguistiques d'entrer dans des milliers de foyers. L'objectif du laboratoire KEG est de permettre au plus grand modèle GLM-130B (130 milliards de paramètres, équivalent à GPT-3.5) d'être entraîné dans un environnement bas de gamme avec une RTX 3090 à 8 voies.
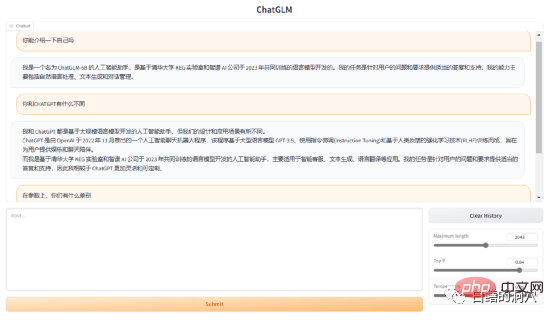
Si cet objectif peut vraiment être atteint, ce sera certainement une bonne nouvelle pour les personnes qui souhaitent créer des applications basées sur de grands modèles de langage. Le modèle FP16 actuel de ChatGLP-6B fait environ un peu plus de 13 Go et le modèle quantifié INT-4 fait moins de 4 Go. Il peut fonctionner sur un RTX 3060TI avec 6 Go de mémoire vidéo.
Je ne connaissais pas grand chose à ces situations avant le déploiement, j'ai donc acheté un RTX 3060 de 12 Go qui n'était ni haut ni bas, donc après avoir terminé l'installation et le déploiement, je ne pouvais toujours pas exécuter le modèle FP16. Si j'avais su qu'il valait mieux faire des tests et des vérifications à la maison, j'aurais simplement acheté un 3060TI moins cher. Si vous souhaitez exécuter un modèle FP16 sans perte, vous devez vous procurer un 3090 avec 24 Go de mémoire vidéo.
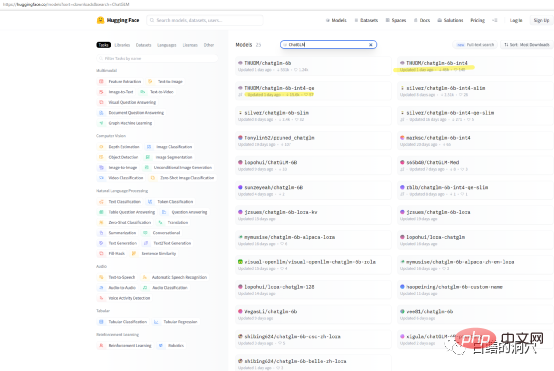
Si vous souhaitez simplement tester les capacités de ChatGLP-6B sur votre propre ordinateur, vous n'aurez peut-être pas besoin de télécharger directement le modèle THUDM/ChatGLM-6B. Il existe des modèles quantitatifs packagés sur huggingface. téléchargé. La vitesse de téléchargement du modèle est très lente, vous pouvez télécharger directement le modèle quantitatif int4.
J'ai réalisé cette installation sur un PC I7 8 cœurs avec une carte graphique RTX 3060 avec 12 Go de mémoire vidéo. Parce que cet ordinateur est mon ordinateur de travail, j'ai installé ChatGLM sur le sous-système WSL. Installer ChatGLM sur le sous-système WINDOWS WSL est plus compliqué que de l'installer directement dans un environnement LINUX. Le plus gros écueil est l’installation du pilote de la carte graphique. Lors du déploiement de ChatGLM directement sur Linux, vous devez installer directement le pilote NVIDIA et activer le pilote de la carte réseau via modprobe. L'installation sur WSL est assez différente.
ChatGLM peut être téléchargé sur github, et il existe quelques documents simples sur le site Web, comprenant même un document pour déployer ChatGLM sur WINDOWS WSL. Cependant, si vous êtes novice en la matière et que vous déployez entièrement selon ce document, vous rencontrerez d’innombrables écueils.
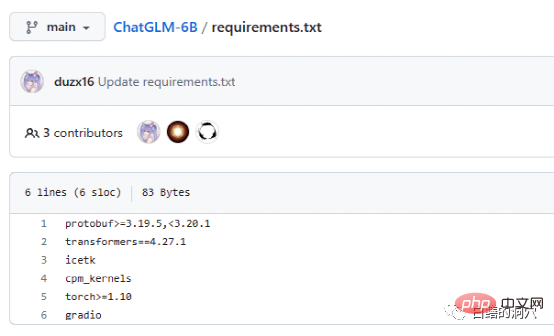
Le document Requriements.txt répertorie la liste et les numéros de version des principaux composants open source utilisés par ChatGLM. Le noyau est constitué de transformateurs, qui nécessitent la version 4.27.1. et c'est bien s'il est légèrement inférieur. C'est un gros problème, mais il vaut mieux utiliser la même version pour des raisons de sécurité. Icetk est destiné au traitement des jetons, cpm_kernels est l'appel principal du modèle de traitement chinois et de cuda, et protobuf est destiné au stockage de données structurées. Gradio est un framework permettant de générer rapidement des applications d'IA à l'aide de Python. Je n’ai pas besoin d’être présenté à Torch.
ChatGLM peut être utilisé dans un environnement sans GPU, en utilisant le processeur et 32 Go de mémoire physique pour fonctionner, mais la vitesse d'exécution est très lente et ne peut être utilisée qu'à des fins de vérification de démonstration. Si vous souhaitez jouer à ChatGLM, il est préférable de s'équiper d'un GPU.
Le plus gros piège lors de l'installation de ChatGLM sur WSL est le pilote de la carte graphique. La documentation de ChatGLM sur Git est très peu conviviale. Pour les personnes qui ne connaissent pas grand-chose à ce projet ou n'ont jamais fait un tel déploiement, la documentation est vraiment déroutante. En fait, le déploiement du logiciel n'est pas gênant, mais le pilote de la carte graphique est très délicat.
Parce qu'il est déployé sur le sous-système WSL, LINUX n'est qu'un système d'émulation, pas un LINUX complet. Par conséquent, le pilote graphique NVIDIA n'a besoin d'être installé que sur WINDOWS et n'a pas besoin d'être activé dans WSL. Cependant, CUDA TOOLS doit encore être installé dans l'environnement virtuel LINUX de WSL. Le pilote NVIDIA sous WINDOWS doit installer le dernier pilote du site officiel et ne peut pas utiliser le pilote de compatibilité fourni avec WIN10/11. Par conséquent, n'omettez pas de télécharger le dernier pilote depuis le site officiel et de l'installer.
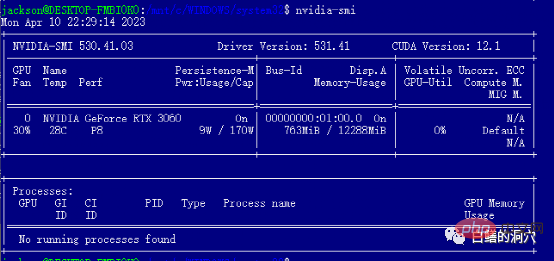
Après avoir installé le pilote WIN, vous pouvez installer les outils cuda directement dans WSL. Une fois l'installation terminée, exécutez nvidia-smi. Si vous voyez l'interface ci-dessus, félicitations, vous l'avez évitée avec succès. fosse. En fait, vous rencontrerez plusieurs pièges lors de l’installation des outils cuda. Autrement dit, votre système doit disposer des versions appropriées de gcc, gcc-dev, make et d'autres outils liés à la compilation. Si ces composants sont manquants, l'installation des outils cuda échouera.
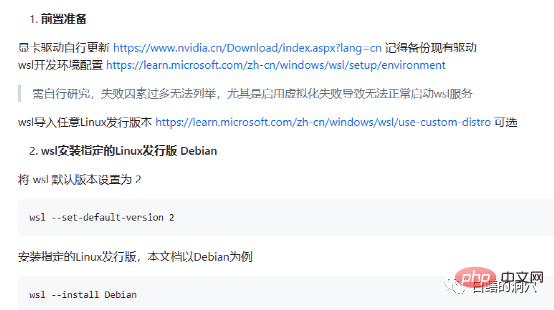
Ce qui précède est la préparation aux pièges. En fait, le piège du pilote NVIDIA est évité et l'installation ultérieure est toujours très fluide. En termes de sélection de système, je recommande toujours de choisir Ubuntu compatible Debian. La nouvelle version d'Aptitude d'Ubuntu est très intelligente et peut vous aider à résoudre les problèmes de compatibilité de version d'un grand nombre de logiciels et à réaliser une rétrogradation automatique de version de certains logiciels.
Le processus d'installation suivant peut être effectué en douceur en suivant complètement le guide d'installation. Il convient de noter que le travail de remplacement des sources d'installation dans /etc/apt/sources.list est mieux effectué selon le guide d'une part. , la vitesse d'installation sera beaucoup plus rapide. De plus, d'une part, cela évite également les problèmes de compatibilité des versions du logiciel. Bien entendu, ne pas le remplacer n’affectera pas nécessairement le processus d’installation ultérieur.
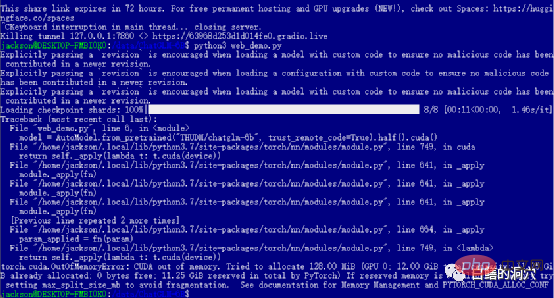
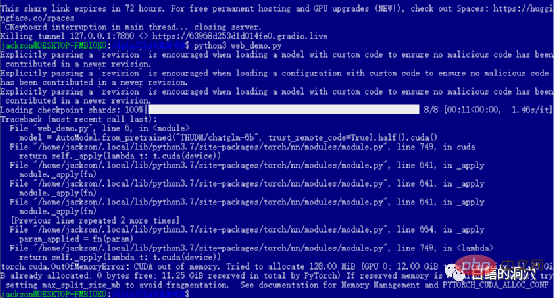
Si vous avez réussi les niveaux précédents, alors vous êtes entré dans la dernière étape et démarrez web_demo. L'exécution de python3 web_demo.py peut démarrer un exemple de conversation WEB. À l'heure actuelle, si vous êtes une personne pauvre et que vous ne disposez que d'un 3060 avec 12 Go de mémoire vidéo, vous verrez certainement l'erreur ci-dessus. Même si vous définissez PYTORCH_CUDA_ALLOC_CONF au minimum 21, vous ne pouvez pas éviter cette erreur. Pour le moment, vous ne pouvez pas être paresseux, vous devez simplement réécrire le script python.
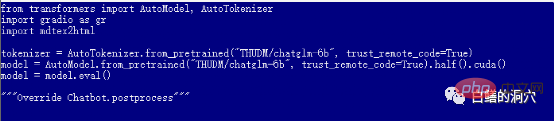
Le web_demo.py par défaut utilise le modèle pré-entraîné FP16. Un modèle avec plus de 13 Go ne sera certainement pas chargé dans les 12 Go existants, vous devez donc apporter un petit ajustement à ce code.

Vous pouvez passer à quantize(4) pour charger le modèle de quantification INT4, ou passer à quantize(8) pour charger le modèle de quantification INT8. De cette façon, la mémoire de votre carte graphique sera suffisante et elle pourra vous aider à faire diverses conversations.
Il est à noter que le téléchargement du modèle ne démarre vraiment qu'une fois web_demo.py lancé, le téléchargement du modèle 13 Go prendra donc beaucoup de temps. Vous pouvez faire ce travail au milieu de la nuit, ou vous-même. peut utiliser Thunder directement. Attendez que l'outil de téléchargement télécharge à l'avance le modèle de Hugging Face. Si vous ne connaissez rien au modèle et n'êtes pas très doué pour installer le modèle téléchargé, vous pouvez également modifier le nom du modèle dans le code, THUDM/chatglm-6b-int4, et télécharger directement le modèle quantifié INT4 avec moins de 4 Go depuis le Internet. Ce sera beaucoup plus rapide et votre carte graphique cassée ne peut de toute façon pas exécuter le modèle FP16.
À ce stade, vous pouvez parler à ChatGLM via la page Web, mais ce n'est que le début des ennuis. Ce n'est que lorsque vous pourrez entraîner votre modèle affiné que votre voyage dans ChatGLM pourra véritablement commencer. Jouer à ce genre de chose demande quand même beaucoup d'énergie et d'argent, alors soyez prudent en entrant dans le piège.
Enfin, je suis très reconnaissant envers mes amis du laboratoire KEG de l'Université Tsinghua. Leur travail permet à davantage de personnes d'utiliser de grands modèles de langage à faible coût.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI