
Maison >Java >javaDidacticiel >Comment assurer la cohérence du cache en Java
Comment assurer la cohérence du cache en Java

- 王林avant
- 2023-05-02 13:13:161286parcourir
Option 1 : Mettre à jour le cache, mettre à jour la base de données
Cette méthode peut être facilement éliminée, car si le cache est mis à jour avec succès en premier, mais que la mise à jour de la base de données échoue, cela entraînera certainement une incohérence des données.
Option 2 : Mettre à jour la base de données et mettre à jour le cache
Cette stratégie de mise à jour du cache est communément appelée double écriture. Le problème est le suivant : dans le scénario de mises à jour simultanées de la base de données, les données sales seront vidées dans le cache.
updateDB(); updateRedis();
Exemple : Si la base de données et le cache sont modifiés par des requêtes ultérieures entre deux opérations, la mise à jour du cache à ce moment sera déjà des données expirées.

Option 3 : Supprimer le cache et mettre à jour la base de données
Il y a un problème : #🎜🎜 #Avant de mettre à jour la base de données, s'il y a une demande de requête, les données sales seront vidées dans le cache
deleteRedis(); updateDB();
Par exemple : Si une requête de données se produit entre deux opérations , alors il y aura d'anciennes données dans le cache.

- Demande A pour effectuer une opération d'écriture et supprimer le cache
- Demande B pour interroger et découvrir Le cache n'existe pas
- Demande B pour interroger la base de données pour obtenir l'ancienne valeur
- Demande à B d'écrire l'ancienne valeur du Cache
- Demande à A d'écrire de nouvelles valeurs dans la base de données#🎜🎜 # La situation ci-dessus entraînera des incohérences. De plus, si vous ne définissez pas de stratégie de délai d’expiration pour le cache, les données seront toujours des données sales.
Option 4 : Mettre à jour la base de données et supprimer le cache
Il y a un problème :Il y a une demande de requête avant de mettre à jour la base de données, et le cache n'est pas valide, la requête va dans la base de données puis mettra à jour le cache. Si une opération de mise à jour de la base de données est effectuée entre l'interrogation de la base de données et la mise à jour du cache, les données sales seront vidées vers le cache. Si les données sont mises à jour et le cache est supprimé entre les deux opérations d'entrée dans le cache, les anciennes données seront placées dans le cache. la cache.
Supposons qu'il y ait deux requêtes, l'une demandant à A d'effectuer une opération de requête et l'autre demandant à B d'effectuer une opération de mise à jour, alors la situation suivante sera se produire
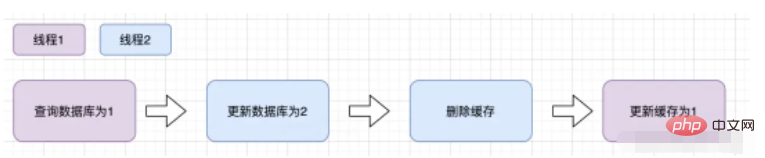 Le cache vient d'expirer
Le cache vient d'expirer
- Demander à A d'interroger la base de données et d'obtenir une ancienne valeur#🎜 🎜#
- #🎜 🎜#
Demande à B d'écrire la nouvelle valeur dans la base de données
-
Demande à B de supprimer le cache
Demander à A d'écrire l'ancienne valeur trouvée dans le cache
Si la situation ci-dessus se produit, des données sales se produiront effectivement . Cependant, il existe une condition congénitale pour que la situation ci-dessus se produise, c'est-à-dire que l'écriture d'une opération de base de données prend moins de temps que la lecture d'une opération de base de données
- Cependant, la vitesse des opérations de lecture de la base de données est beaucoup plus rapide que les opérations d'écriture#🎜🎜 #Cette situation est donc difficile à réaliser.
Les lacunes communes du plan 1 et du plan 2 :
Dans le scénario du concomitance lors de la mise à jour de la base de données, les données sales seront transférées dans le cache, mais en général, la probabilité de scénarios d'écriture simultanés est relativement faible Du point de vue de la sécurité des threads, des données sales seront générées, telles que : # 🎜🎜#Thread A a mis à jour la base de données
Thread B a mis à jour la base de données
# 🎜🎜#
Thread B a mis à jour le cache- Thread A a mis à jour le cache
- #🎜 🎜# Inconvénients courants des options 3 et 4 :
Peu importe l'ordre adopté, il y a quelques problèmes dans les deux méthodes :
- # 🎜🎜#Problème de délai maître-esclave : Qu'il soit supprimé en premier ou ultérieurement, le délai maître-esclave de la base de données peut conduire à la génération de données sales.
Idées de résolution de problèmes : retarder la double suppression et ajouter un mécanisme de nouvelle tentative, présenté ci-dessous !
- Mettre à jour le cache ou supprimer le cache ?
- 1. La mise à jour du cache cache nécessite un certain coût de maintenance, et il y aura des problèmes avec les mises à jour simultanées #🎜 🎜 # 2. Lorsqu'il y a plus d'écriture et moins de lecture, la demande de lecture n'est pas encore arrivée, et le cache a été mis à jour plusieurs fois, ce qui ne joue pas le rôle de cache
3. La valeur mise dans le cache peut être calculée de manière complexe Si la valeur écrite dans le cache est calculée à chaque mise à jour, ce sera un gaspillage de performances. Avantages de la suppression du cache : # 🎜🎜#Simple, peu coûteux, facile à développer ; Inconvénients : cela entraînera un échec du cacheSi le coût de mise à jour du cache est faible et qu'il y a plus de lectures et moins d'écritures, il y aura essentiellement pas de simultanéité d'écriture Vous pouvez mettre à jour le cache uniquement lorsque cela est nécessaire, sinon l'approche générale consiste à supprimer le cache.
总结
| 方案 | 问题 | 问题出现概率 | 推荐程度 |
|---|---|---|---|
| 更新缓存 -> 更新数据库 | 为了保证数据准确性,数据必须以数据库更新结果为准,所以该方案绝不可行 | 大 | 不推荐 |
| 更新数据库 -> 更新缓存 | 并发更新数据库场景下,会将脏数据刷到缓存 | 并发写场景,概率一般 | 写请求较多时会出现不一致问题,不推荐使用。 |
| 删除缓存 -> 更新数据库 | 更新数据库之前,若有查询请求,会将脏数据刷到缓存 | 并发读场景,概率较大 | 读请求较多时会出现不一致问题,不推荐使用 |
| 更新数据库 -> 删除缓存 | 在更新数据库之前有查询请求,并且缓存失效了,会查询数据库,然后更新缓存。如果在查询数据库和更新缓存之间进行了数据库更新的操作,那么就会把脏数据刷到缓存 | 并发读场景&读操作慢于写操作,概率最小 | 读操作比写操作更慢的情况较少,相比于其他方式出错的概率小一些。勉强推荐。 |
推荐方案
延迟双删
采用更新前后双删除缓存策略
public void write(String key,Object data){
redis.del(key);
db.update(data);
Thread.sleep(1000);
redis.del(key);
}先淘汰缓存
再写数据库
休眠1秒,再次淘汰缓存
大家应该评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
问题及解法:
1、同步删除,吞吐量降低如何处理
将第二次删除作为异步的,提交一个延迟的执行任务
2、解决删除失败的方式:
添加重试机制,例如:将删除失败的key,写入消息队列;但对业务耦合有些严重;
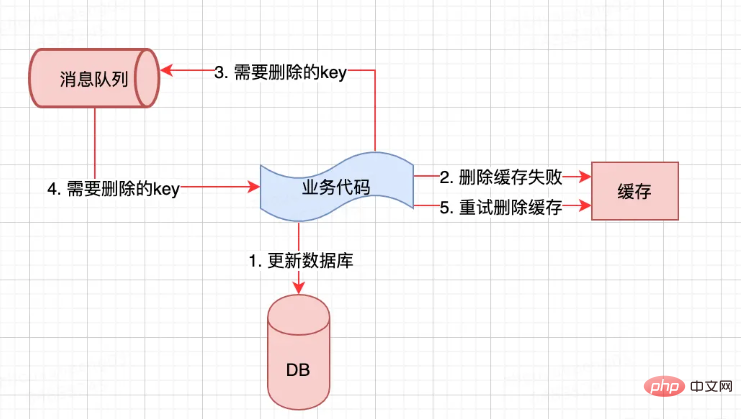
延时工具可以选择:
最普通的阻塞Thread.currentThread().sleep(1000);
Jdk调度线程池,quartz定时任务,利用jdk自带的delayQueue,netty的HashWheelTimer,Rabbitmq的延时队列,等等
实际场景
我们有个商品中心的场景,是读多写少的服务,并且写数据会发送MQ通知下游拿数据,这样就需要严格保证缓存和数据库的一致性,需要提供高可靠的系统服务能力。
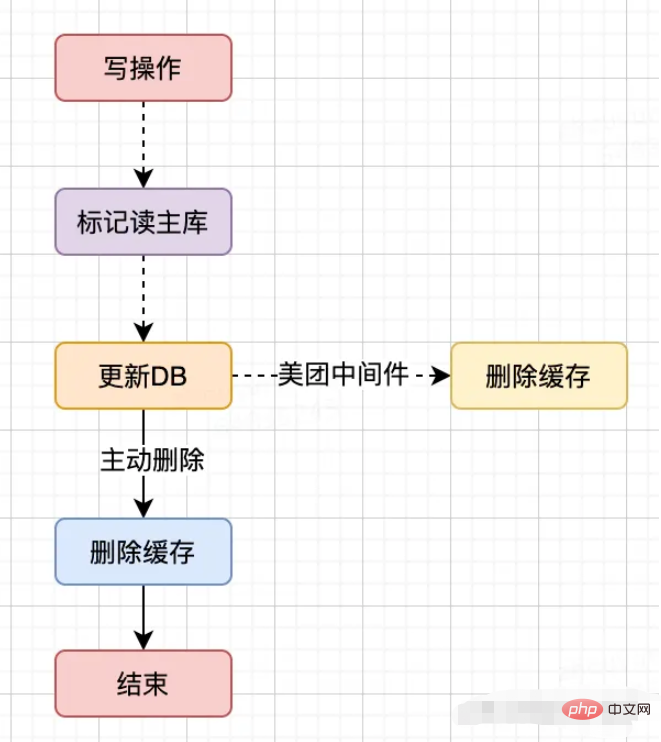
写缓存策略
缓存key设置失效时间
先DB操作,再缓存失效
写操作都标记key(美团中间件)强制走主库
接入美团中间件监听binlog(美团中间件)变化的数据在进行兜底,再删除缓存
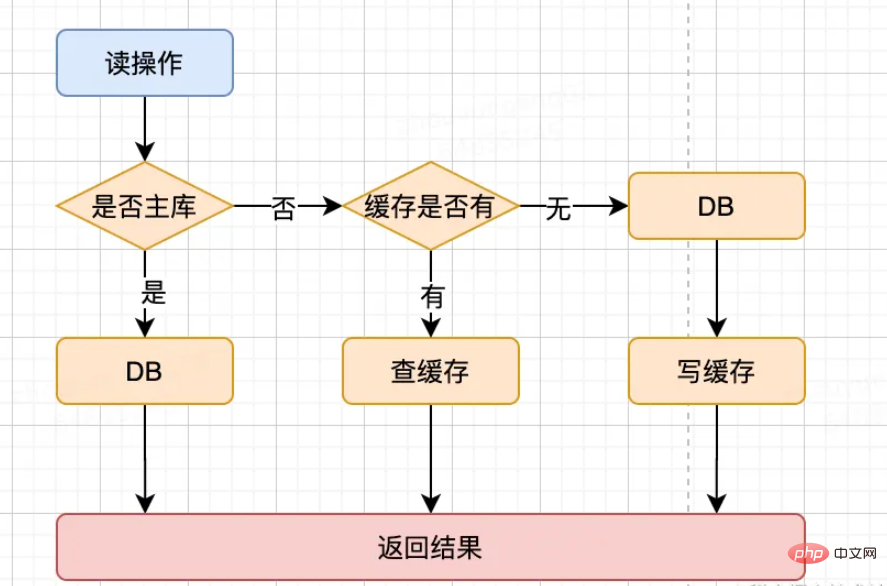
读缓存策略
先判断是否走主库
如果走主库,则使用标记(美团中间件)查主库
如果不是,则查看缓存中是否有数据
缓存中有数据,则使用缓存数据作为结果
如果没有,则查DB数据,再写数据到缓存
注意
关于缓存过期时间的问题
如果缓存设置了过期时间,那么上述的所有不一致情况都只是暂时的。
但是如果没有设置过期时间,那么不一致问题就只能等到下次更新数据时解决。
所以一定要设置缓存过期时间。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment fonctionne le mécanisme de chargement de classe de Java, y compris différents chargeurs de classe et leurs modèles de délégation?
- How do I create and use custom Java libraries (JAR files) with proper versioning and dependency management?
- Comment puis-je utiliser JPA (Java Persistance API) pour la cartographie relationnelle des objets avec des fonctionnalités avancées comme la mise en cache et le chargement paresseux?
- Comment implémenter la mise en cache à plusieurs niveaux dans les applications Java à l'aide de bibliothèques comme la caféine ou le cache de goyave?
- Comment utiliser Maven ou Gradle pour la gestion avancée de projet Java, la création d'automatisation et la résolution de dépendance?