
Maison >Périphériques technologiques >IA >GMMSeg, un nouveau paradigme de segmentation sémantique générative, peut gérer à la fois la reconnaissance d'ensembles fermés et ouverts
GMMSeg, un nouveau paradigme de segmentation sémantique générative, peut gérer à la fois la reconnaissance d'ensembles fermés et ouverts

- PHPzavant
- 2023-05-02 08:34:131745parcourir
L'algorithme de segmentation sémantique traditionnel actuel est essentiellement un modèle de classification discriminante basé sur le classificateur softmax, qui modélise directement p (classe|fonctionnalité de pixel) et ignore complètement la distribution des données de pixels sous-jacente, c'est-à-dire p (classe|fonctionnalité de pixel). Cela limite l'expressivité et la généralisation du modèle sur les données OOD (hors distribution).
Dans une étude récente, des chercheurs de l'Université du Zhejiang, de l'Université de technologie de Sydney et du Baidu Research Institute ont proposé un nouveau paradigme de segmentation sémantique : la segmentation sémantique générative basée sur le modèle de mélange gaussien (GMM) ModelGMMSeg.

- Lien papier : https://arxiv.org/abs/2210.02025
- Lien code : https://github.com/leonnnop/GMMSeg
GMMSeg Modélisez la distribution conjointe des pixels et des catégories, apprenez un classificateur de mélange gaussien (GMM Classifier) dans l'espace des caractéristiques des pixels via l'algorithme EM et utilisez un paradigme génératif pour capturer finement la distribution des caractéristiques des pixels de chaque catégorie. Pendant ce temps, GMMSeg adopte une perte discriminante pour optimiser de bout en bout les extracteurs de fonctionnalités approfondies. Cela donne à GMMSeg les avantages des modèles à la fois discriminatifs et génératifs.
Les résultats expérimentaux montrent que GMMSeg a obtenu des améliorations de performances sur une variété d'architectures de segmentation et de réseaux fédérateurs ; en même temps, GMMSeg peut être directement appliqué à la segmentation des anomalies sans aucun post-traitement ni réglage fin (segmentation des anomalies). tâches.
Jusqu'à présent, c'est la première fois qu'une méthode de segmentation sémantique peut utiliser une seule instance de modèle, avancement simultané dans des conditions d'ensemble fermé et de monde ouvert performances. C’est également la première fois que les classificateurs génératifs démontrent leurs avantages dans des tâches de vision à grande échelle.
Classificateur discriminant vs génératif
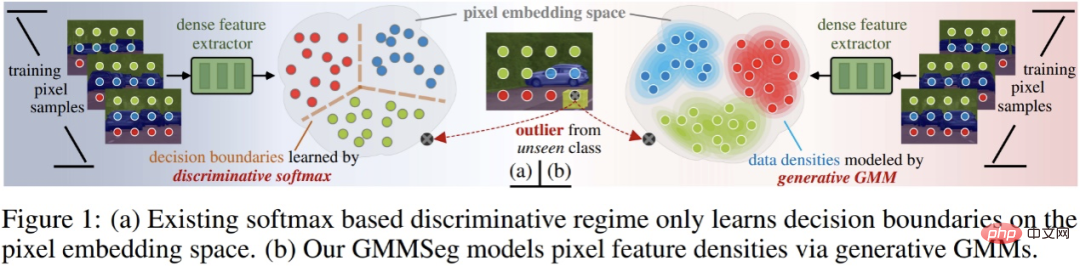
Avant d'approfondir les paradigmes de segmentation existants et les méthodes proposées, nous présentons ici brièvement les concepts de classificateurs discriminants et génératifs.
Supposons qu'il existe un ensemble de données D, qui contient des paires de paires échantillon-étiquette (x, y) ; le but ultime du classificateur est de prédire la probabilité de classification de l'échantillon p (y|x). Les méthodes de classification peuvent être divisées en deux catégories : les classificateurs discriminatifs et les classificateurs génératifs.
- Classificateur discriminant : modélise directement la probabilité conditionnelle p (y|x) ; il apprend uniquement la limite de décision optimale de classification sans tenir compte du tout de la distribution de l'échantillon lui-même, et ne peut donc pas refléter les caractéristiques de l'échantillon. échantillon .
- Classificateur génératif : modélisez d'abord la distribution de probabilité conjointe p (x, y), puis dérivez la probabilité conditionnelle de classification à l'aide du théorème de Bayes, il modélise explicitement la distribution des données elle-même, souvent un modèle correspondant sera ; construit pour chaque catégorie. Par rapport au classificateur discriminant, il prend pleinement en compte les informations caractéristiques de l'échantillon.
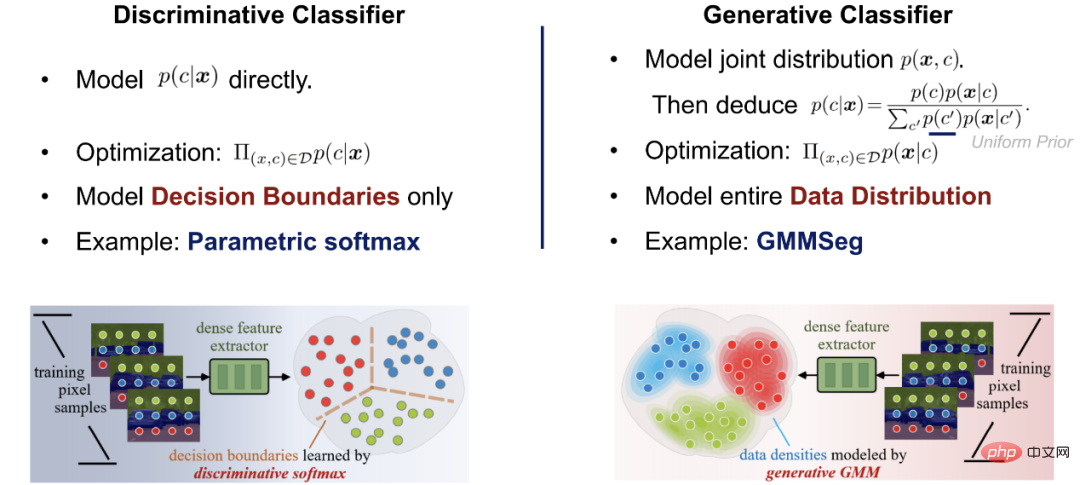
Paradigme de segmentation sémantique grand public : classificateur Softmax discriminant
Les modèles de segmentation pixel par pixel actuellement courants utilisent principalement des réseaux profonds pour extraire les caractéristiques des pixels, puis utilisent des classificateurs softmax pour classer les caractéristiques des pixels. Son architecture de réseau se compose de deux parties :
La première partie est l'extracteur de caractéristiques de pixels Son architecture typique est une paire encodeur-décodeur, qui mappe l'entrée de pixels de l'espace RVB à des dimensions D élevées. dimensionnel Obtenez spatialement les caractéristiques des pixels.
La deuxième partie est le classificateur de pixels, qui est le classificateur softmax traditionnel ; il code les caractéristiques des pixels d'entrée en sorties réelles de type C (logits), puis utilise la fonction softmax pour normaliser les sorties ( logits) Unifier et donner une signification probabiliste, c'est-à-dire utiliser des logits pour calculer la probabilité a posteriori de la classification des pixels :
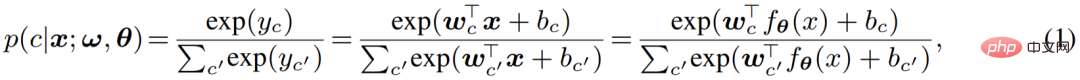
Enfin, le modèle complet composé de deux parties sera optimisé de bout en bout grâce à l'entropie croisée loss :
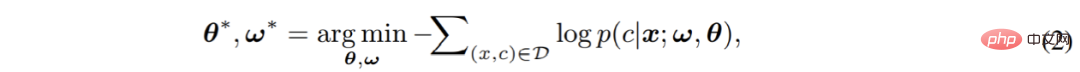
Dans ce processus, le modèle ignore la distribution des pixels eux-mêmes et estime directement la probabilité conditionnelle p (c|x) de la prédiction de classification des pixels. On peut voir que le classificateur softmax traditionnel est essentiellement un classificateur discriminant.
Le classificateur discriminant a une structure simple, et comme son objectif d'optimisation vise directement à réduire l'erreur de discrimination, il peut souvent atteindre d'excellentes performances discriminantes. Cependant, en même temps, il présente quelques défauts fatals qui n'ont pas attiré l'attention des travaux existants, ce qui affecte grandement les performances de classification et la généralisation du classificateur softmax :
- Tout d'abord, il ne modélise que la limite de décision La distribution des caractéristiques des pixels est complètement ignorée et, par conséquent, les caractéristiques spécifiques de chaque catégorie ne peuvent pas être modélisées et utilisées. Ses capacités de généralisation et d'expression sont affaiblies.
- Deuxièmement, il utilise une seule paire de paramètres (w,b) pour modéliser une catégorie ; en d'autres termes, le classificateur softmax s'appuie sur l'hypothèse d'unimodalité ; ne parviennent pas à tenir le coup, ce qui entraîne des performances sous-optimales.
- Enfin, la sortie du classificateur softmax ne peut pas refléter avec précision la véritable signification probabiliste ; sa prédiction finale ne peut être utilisée que comme référence lors d'une comparaison avec d'autres catégories. C’est également la raison fondamentale pour laquelle il est difficile pour un grand nombre de modèles de segmentation traditionnels de détecter les entrées OOD.
En réponse à ces problèmes, l'auteur estime que le paradigme discriminant dominant actuel devrait être repensé, et la solution correspondante est donnée dans cet article : Modèle de segmentation sémantique générative - GMMSeg.
Modèle de segmentation sémantique générative : GMMSeg
L'auteur a réorganisé le processus de segmentation sémantique du point de vue d'un modèle génératif. Par rapport à la modélisation directe de la probabilité de classification p (c|x), le classificateur génératif modélise la distribution conjointe p (x, c), puis utilise le théorème de Bayes pour dériver la probabilité de classification :
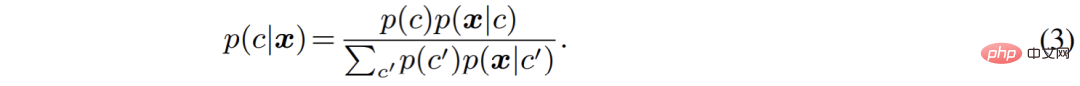
Parmi eux, pour des raisons de généralisation, la catégorie antérieure p (c) est souvent définie sur une distribution uniforme, et comment modéliser la distribution conditionnelle de catégorie p (x|c) des caractéristiques des pixels devient le principal problème actuel.
Dans cet article, c'est-à-dire dans GMMSeg, un modèle de mélange gaussien est utilisé pour modéliser p (x|c), dont la forme est la suivante :
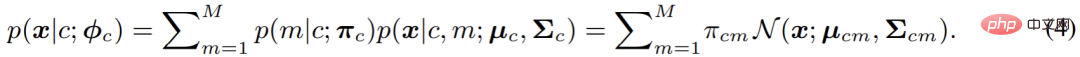
Le nombre de composants n'est pas limité Dans le cas de . Sur cette base, cet article utilise l'estimation du maximum de vraisemblance pour optimiser les paramètres du modèle :
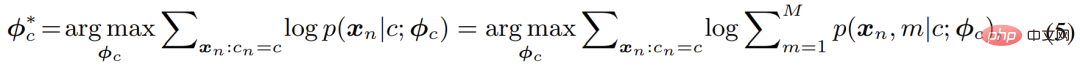
La solution classique est l'algorithme EM, c'est-à-dire en exécutant alternativement E-M - optimisation pas à pas en deux étapes de la fonction F - :
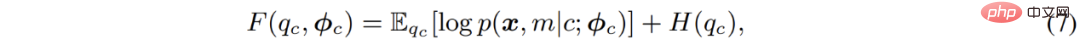
Spécifique à l'optimisation des modèles de mélange gaussien ; l'algorithme EM évalue en fait la probabilité des points de données appartenant à chaque sous-modèle dans l'étape E ; .Réestimer. En d’autres termes, cela équivaut à effectuer un clustering logiciel sur les pixels à l’étape E ; puis, à l’étape M, les résultats du clustering peuvent être utilisés pour mettre à jour à nouveau les paramètres du modèle.
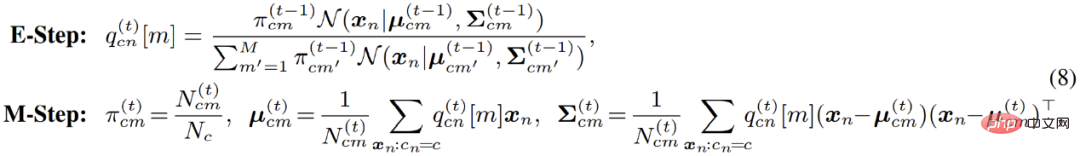
Cependant, dans les applications pratiques, l'auteur a constaté que l'algorithme EM standard convergeait lentement et que les résultats finaux étaient médiocres . L'auteur soupçonne que l'algorithme EM est trop sensible aux valeurs initiales d'optimisation des paramètres, ce qui rend difficile la convergence vers un meilleur point extrême local. Inspiré par une série d'algorithmes de clustering récents basés sur la théorie du transport optimal, l'auteur introduit un uniforme supplémentaire avant la distribution du modèle de mélange : #Correspondant, l'étape E du processus d'optimisation des paramètres se transforme en un problème d'optimisation contraint, comme suit : #
Ce processus peut être intuitivement compris comme introduisant une contrainte de distribution égale au processus de clustering : pendant le processus de clustering, les points de données peuvent être distribués uniformément à chaque sous-modèle. Après avoir introduit cette contrainte, ce processus d'optimisation est équivalent au problème de transmission optimale listé dans la formule suivante : Cette équation peut être résolue rapidement à l'aide de l'algorithme de Sinkhorn-Knopp. L'ensemble du processus d'optimisation amélioré est nommé Sinkhorn EM, qui a été prouvé par certains travaux théoriques comme ayant la même solution optimale globale que l'algorithme EM standard, et est moins susceptible de tomber dans la solution optimale locale.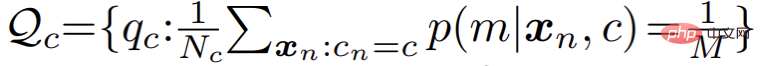
Après cela, dans le processus d'optimisation complet, un mode d'optimisation hybride en ligne (hybride en ligne) : via le Sinkhorn EM génératif , le classificateur de mélange gaussien est optimisé en permanence dans l'espace de fonctionnalités mis à jour progressivement tandis que pour une autre partie du cadre complet, la partie extracteur de caractéristiques de pixels, il est basé sur une classification générative. Les résultats de prédiction de la machine sont optimisés à l'aide d'une perte d'entropie croisée discriminante ; . Les deux parties sont optimisées alternativement et alignées l'une avec l'autre, ce qui rend l'ensemble du modèle étroitement couplé et capable d'un entraînement de bout en bout : #Dans ce processus, la partie extraction de caractéristiques n'est optimisée que par rétropropagation de gradient tandis que la partie classificateur génératif l'est ; uniquement optimisé via SinkhornEM. C'est cette conception d'optimisation alternée qui permet à l'ensemble du modèle d'être intégré de manière compacte et d'hériter des avantages des modèles discriminatifs et génératifs.
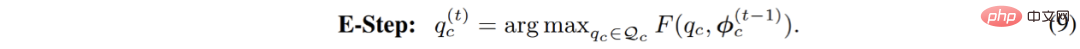
Au final, GMMSeg bénéficie de son architecture de classification générative et de sa stratégie de formation hybride en ligne pour démontrer des performances discriminantes. Avantages que le softmax le classificateur n'a pas :
- Tout d'abord, bénéficiant de son architecture universelle, GMMSeg est compatible avec la plupart des modèles de segmentation traditionnels, c'est-à-dire compatible avec les modèles qui utilisent softmax pour la classification : il vous suffit de remplacer le classificateur discriminant softmax pour améliorer sans douleur les performances du modèle existant.
- Deuxièmement, grâce à l'application du mode de formation hybride, GMMSeg combine les avantages des classificateurs génératifs et discriminatifs et résout dans une certaine mesure le problème selon lequel softmax ne peut pas modéliser les changements intra-classes, améliorant considérablement ses performances discriminantes ;
- Troisièmement, GMMSeg modélise explicitement la distribution des caractéristiques des pixels, c'est-à-dire p (x|c) ; GMMSeg peut directement donner la probabilité que l'échantillon appartienne à chaque catégorie, ce qui lui permet de traiter naturellement les données OOD invisibles. .
Résultats expérimentaux
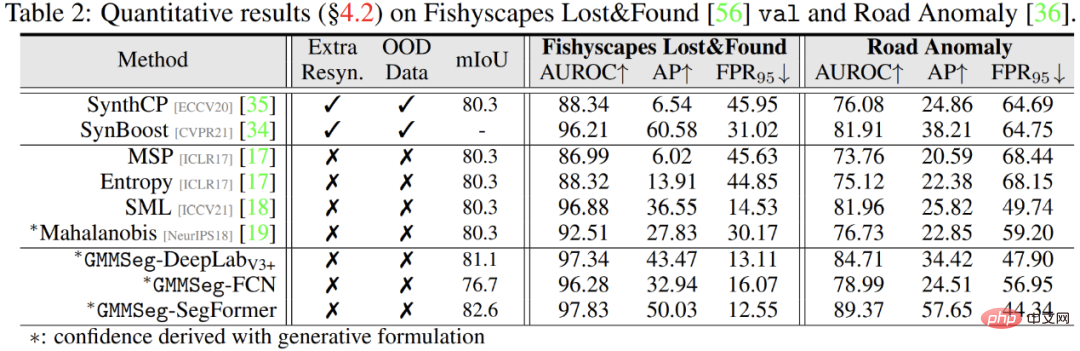
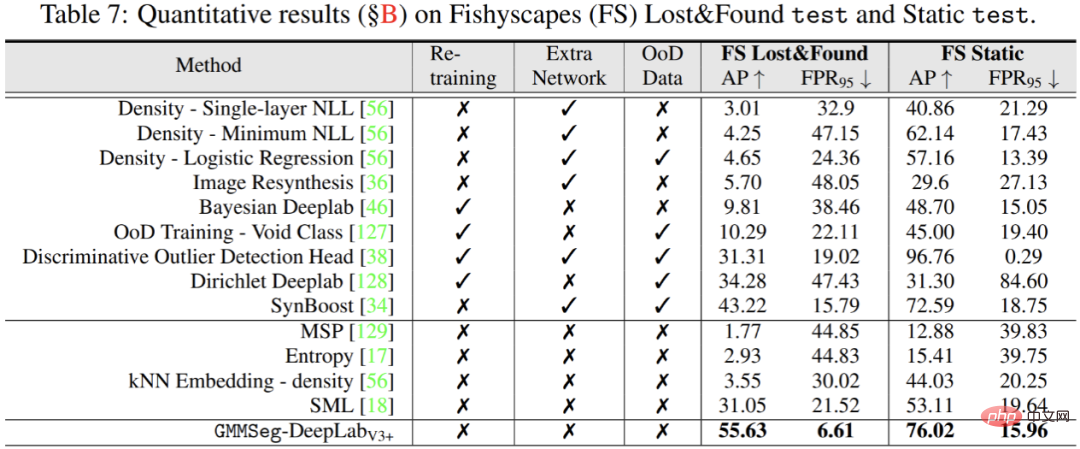
Les résultats expérimentaux montrent que, qu'il soit basé sur l'architecture CNN ou l'architecture Transformer, GMMSeg peut obtenir des résultats stables et évidents sur des ensembles de données de segmentation sémantique largement utilisés (ADE20K, Cityscapes, COCO-Stuff) en termes d'amélioration des performances. .
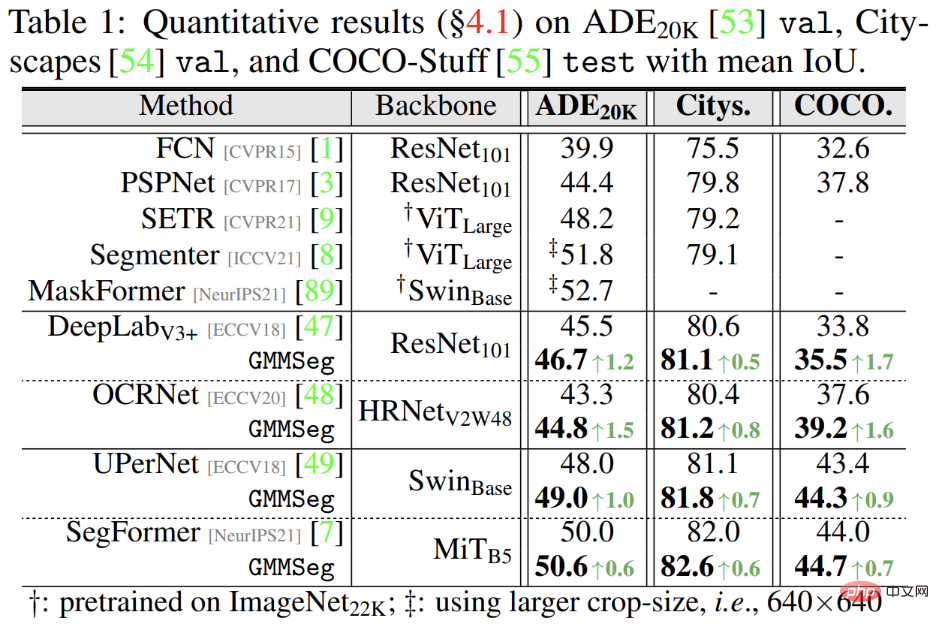

De plus, dans la tâche de segmentation des anomalies, il n'est pas nécessaire d'apporter des modifications au modèle formé dans la tâche d'ensemble fermé, c'est-à-dire que la tâche de segmentation sémantique régulière GMMSeg peut être utilisée. dans toutes les évaluations courantes En termes d'indicateurs, elle surpasse les autres méthodes qui nécessitent un post-traitement spécial.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI