
Maison >Périphériques technologiques >IA >Vous souhaitez déplacer la moitié de « A Dream of Red Mansions » dans la zone de saisie ChatGPT ? Résolvons d'abord ce problème
Vous souhaitez déplacer la moitié de « A Dream of Red Mansions » dans la zone de saisie ChatGPT ? Résolvons d'abord ce problème

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-01 21:01:05907parcourir

Au cours des deux dernières années, le laboratoire de recherche Hazy de l'université de Stanford s'est engagé dans un travail important : augmenter la longueur des séquences.
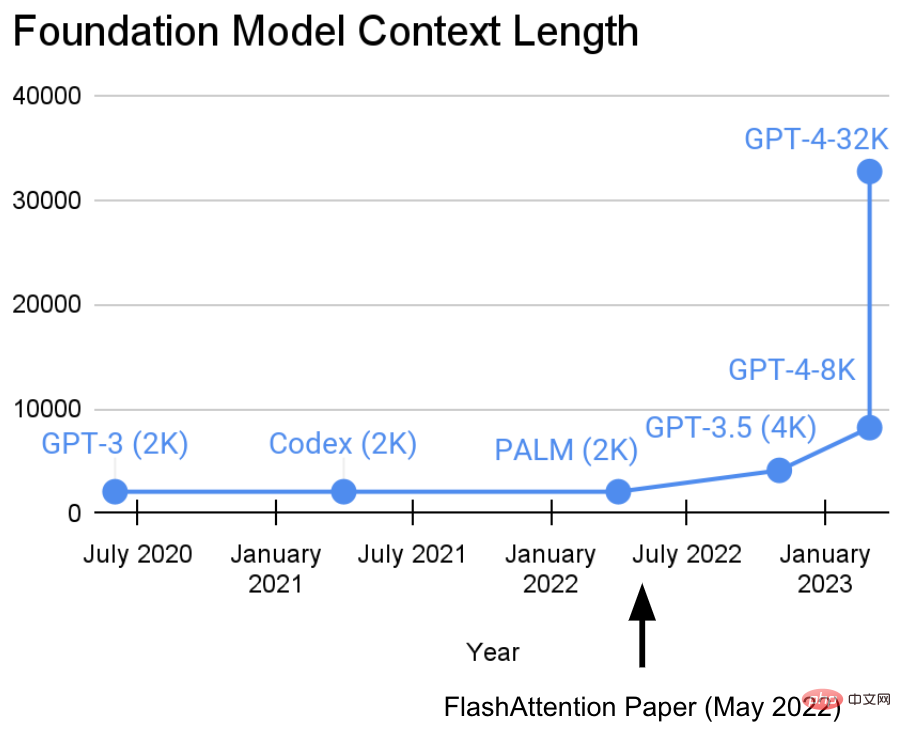
Ils ont un point de vue : des séquences plus longues inaugureront une nouvelle ère de modèles d'apprentissage automatique de base - des modèles capables d'apprendre à partir de contextes plus longs, de sources multimédias multiples, de démonstrations complexes, etc.Actuellement, cette recherche a fait de nouveaux progrès. Tri Dao et Dan Fu du laboratoire Hazy Research ont dirigé la recherche et la promotion de l'algorithme FlashAttention. Ils ont prouvé qu'une longueur de séquence de 32 Ko est possible et sera largement utilisée dans l'ère actuelle des modèles de base (OpenAI, Microsoft, NVIDIA et d'autres sociétés). les modèles utilisent l’algorithme FlashAttention).
- Adresse papier : https://arxiv.org/abs/2205.14135
- Adresse code : https://github.com/HazyResearch/flash-attention
Dans cet article, l'auteur présente de nouvelles méthodes pour augmenter la longueur des séquences à un niveau élevé et fournit un « pont » vers un nouvel ensemble de primitives.
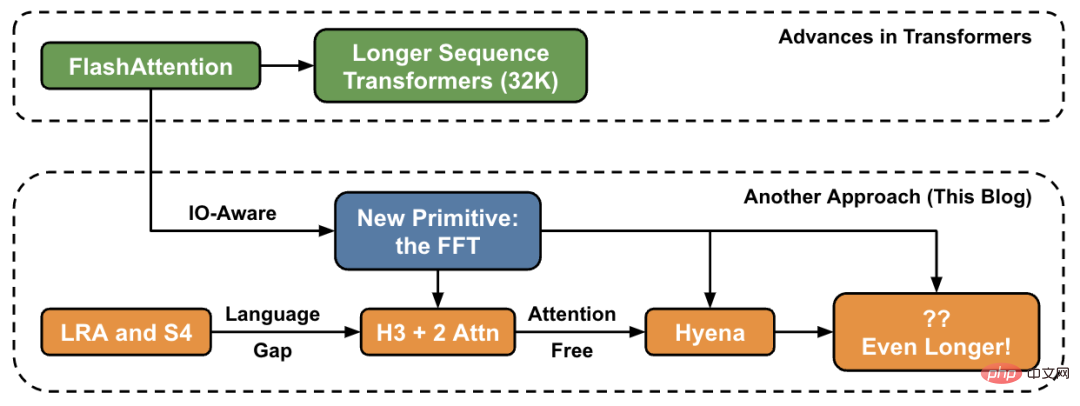
Dans le laboratoire Hazy Research, ce travail a commencé avec Hippo, puis S4, H3 et maintenant Hyena. Ces modèles ont le potentiel de gérer des longueurs de contexte se chiffrant en millions, voire en milliards.
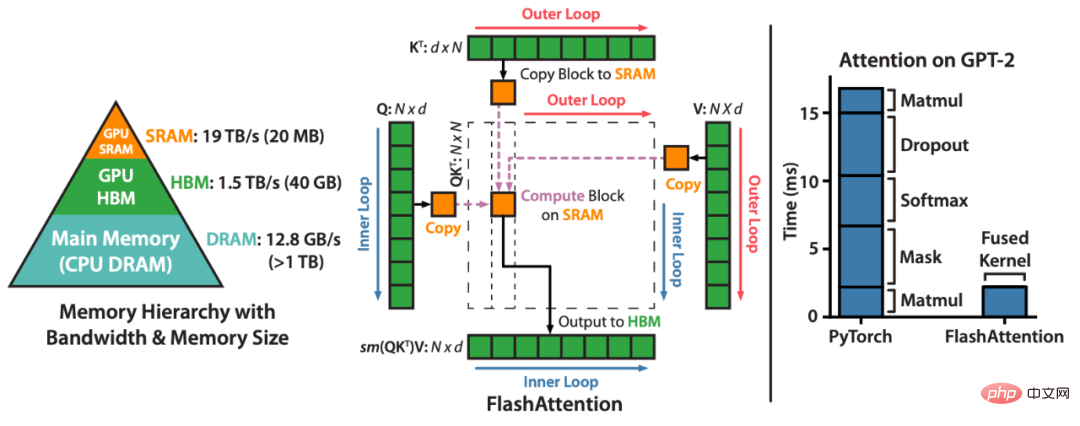
FlashAttention accélère l'attention et réduit son empreinte mémoire - sans aucune approximation. « Depuis que nous avons publié FlashAttention il y a 6 mois, nous sommes ravis de voir de nombreuses organisations et laboratoires de recherche adopter FlashAttention pour accélérer leur formation et leur inférence », peut-on lire sur le blog.FlashAttention est un algorithme qui réorganise les calculs d'attention et exploite des techniques classiques (pavage, recalcul) pour accélérer et réduire l'utilisation de la mémoire de quadratique à linéaire en termes de longueur de séquence. Pour chaque tête d'attention, afin de réduire les lectures/écritures de mémoire, FlashAttention utilise des techniques de mosaïque classiques pour charger les blocs de requêtes, de clés et de valeurs du GPU HBM (sa mémoire principale) vers SRAM (son cache rapide), en calculant l'attention et en réécrivant la sortie dans HBM. Cette réduction des lectures/écritures de mémoire entraîne des accélérations significatives (2 à 4x) dans la plupart des cas.
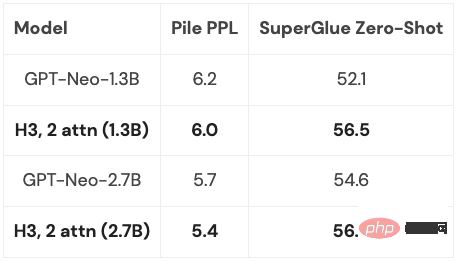
Des chercheurs de Google ont lancé le benchmark Long Range Arena (LRA) en 2020 pour évaluer dans quelle mesure différents modèles gèrent les dépendances à longue portée. LRA est capable de tester une gamme de tâches couvrant de nombreux types et modalités de données différents, tels que du texte, des images et des expressions mathématiques, avec des longueurs de séquence allant jusqu'à 16 Ko (Path-X : Classification des images dépliées en pixels sans aucun biais de généralisation spatiale). De nombreux travaux ont été réalisés pour adapter Transformers à des séquences plus longues, mais une grande partie semble sacrifier la précision (comme le montre l'image ci-dessous). Notez la colonne Path-X : toutes les méthodes Transformer et leurs variantes fonctionnent encore moins bien que la supposition aléatoire. Faisons maintenant connaissance avec le S4, qui a été développé sous la houlette d'Albert Gu. Inspiré par les résultats du benchmark LRA, Albert Gu a voulu découvrir comment mieux modéliser les dépendances à long terme. Sur la base de recherches à long terme sur la relation entre les polynômes orthogonaux et les modèles récursifs et convolutifs, il a lancé S4—— Un nouveau modèle de séquence. basé sur des modèles d'espace d'état structurés (SSM). Le point clé est que la complexité temporelle du SSM lors de l'extension d'une séquence de longueur N à 2N est de De plus, lorsque Hazy Research a sorti FlashAttention, il était déjà possible d'augmenter la longueur de séquence de Transformer. Ils ont également constaté que Transformer atteignait également des performances supérieures sur Path-X (63 %) simplement en augmentant la longueur de la séquence à 16 Ko. Mais l'écart de qualité de S4 dans la modélisation du langage atteint 5% de perplexité (pour le contexte, c'est l'écart entre le modèle 125M et le modèle 6.7B). Pour combler cette lacune, les chercheurs ont étudié les langages synthétiques tels que le rappel associatif afin de déterminer quelles propriétés un langage devrait posséder. La conception finale était H3 (Hungry Hungry Hippos) : une nouvelle couche qui empile deux SSM et multiplie leurs sorties avec une porte de multiplication. En utilisant H3, les chercheurs de Hazy Research ont remplacé presque toutes les couches d'attention dans un transformateur de style GPT et ont pu faire correspondre le transformateur en termes de perplexité et d'évaluation en aval lors de la formation sur 400 milliards de jetons de Pile. Long Range Arena Benchmark et S4
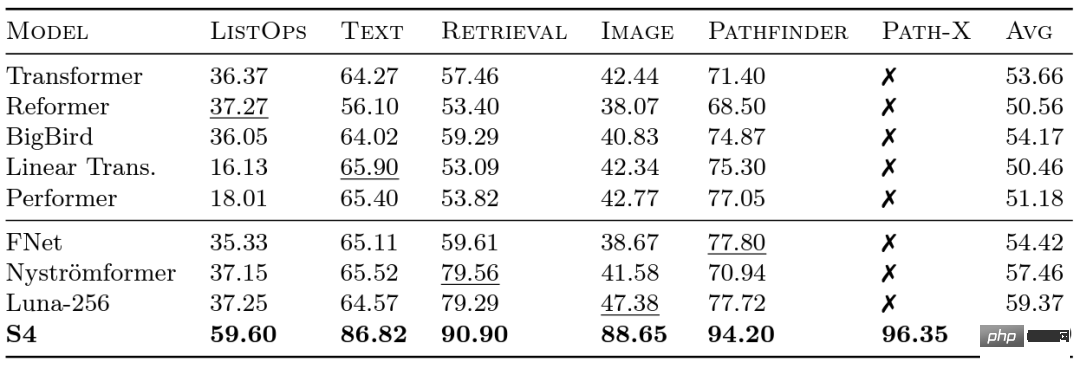
 , contrairement au mécanisme d'attention, qui augmente au niveau du carré ! S4 modélise avec succès les dépendances à longue portée dans LRA et devient le premier modèle à atteindre des performances supérieures à la moyenne sur Path-X (atteignant désormais une précision de 96,4 % !). Depuis la sortie de S4, de nombreux chercheurs ont développé et innové sur cette base, avec de nouveaux modèles tels que le modèle S5 de l'équipe de Scott Linderman, le DSS d'Ankit Gupta (et le S4D ultérieur du laboratoire Hazy Research), le Liquid-S4 de Hasani et Lechner, etc. Modèle.
, contrairement au mécanisme d'attention, qui augmente au niveau du carré ! S4 modélise avec succès les dépendances à longue portée dans LRA et devient le premier modèle à atteindre des performances supérieures à la moyenne sur Path-X (atteignant désormais une précision de 96,4 % !). Depuis la sortie de S4, de nombreux chercheurs ont développé et innové sur cette base, avec de nouveaux modèles tels que le modèle S5 de l'équipe de Scott Linderman, le DSS d'Ankit Gupta (et le S4D ultérieur du laboratoire Hazy Research), le Liquid-S4 de Hasani et Lechner, etc. Modèle. Défauts de modélisation
Étant donné que la couche H3 est construite sur SSM, sa complexité de calcul augmente également à un rythme de  en termes de longueur de séquence. Les deux couches d'attention rendent encore la complexité de l'ensemble du modèle
en termes de longueur de séquence. Les deux couches d'attention rendent encore la complexité de l'ensemble du modèle
 Cette question sera discutée en détail plus tard.
Cette question sera discutée en détail plus tard.
Bien sûr, Hazy Research n'est pas le seul à envisager cette direction : GSS a également découvert que SSM avec des portes peut bien fonctionner avec de l'attention dans la modélisation du langage (cela a inspiré H3), Meta a publié le modèle Mega, il combine également SSM et attention, le modèle BiGS remplace l'attention dans le modèle de style BERT, et RWKV a travaillé sur une approche entièrement en boucle.
Nouveau progrès : Hyena
Sur la base d'une série de travaux antérieurs, les chercheurs de Hazy Research ont été inspirés pour développer une nouvelle architecture : Hyena. Ils ont essayé de se débarrasser des deux dernières couches d’attention dans H3 et d’obtenir un modèle qui croît presque linéairement pour des séquences plus longues. Il s'avère que deux idées simples sont la clé pour trouver la réponse :
- Chaque SSM peut être considéré comme un filtre convolutif de la même longueur que la séquence d'entrée. Par conséquent, le SSM peut être remplacé par une convolution de taille égale à la séquence d’entrée pour obtenir un modèle plus puissant avec le même effort de calcul. Plus précisément, le filtre convolutif est implicitement paramétré par un autre petit réseau neuronal, s'appuyant sur des méthodes puissantes issues de la littérature sur le domaine neuronal et des travaux sur CKConv/FlexConv. De plus, la convolution peut être calculée en un temps O (NlogN), où N est la longueur de la séquence, obtenant une mise à l'échelle presque linéaire ; le comportement de déclenchement dans
- H3 peut être résumé comme suit : H3 prend trois projections de l'entrée, et de manière itérative. effectuer des convolutions et appliquer le gate. Dans Hyena, le simple fait d’ajouter plus de projections et plus de portes permet de généraliser à des architectures plus expressives et de combler l’écart avec attention.
Hyena a proposé pour la première fois un modèle de convolution temporelle complètement quasi-linéaire, qui peut correspondre à Transformer sur la perplexité et les tâches en aval, et a obtenu de bons résultats dans les expériences. Et les modèles de petite et moyenne taille ont été formés sur un sous-ensemble de PILE, et leurs performances étaient comparables à celles de Transformer :
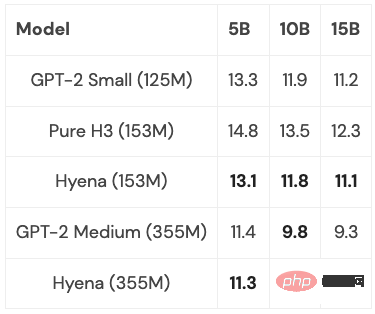
Avec quelques optimisations (plus ci-dessous), lorsque la longueur de la séquence est de 2K, Hyena Le modèle est légèrement plus lent qu'un Transformer de même taille, mais plus rapide sur des séquences plus longues.
La prochaine chose à considérer est la suivante : dans quelle mesure ces modèles peuvent-ils être généralisés ? Est-il possible de les adapter à la taille réelle de PILE (400 milliards de jetons) ? Que se passerait-il si vous combiniez le meilleur des idées de H3 et de Hyena, et jusqu’où cela pourrait-il aller ?
FFT ou une approche plus basique ?
Dans tous ces modèles, une opération de base commune est la FFT, qui est un moyen efficace de calculer la convolution et ne prend que du temps O (NlogN). Cependant, FFT est mal pris en charge sur le matériel moderne où l'architecture dominante est constituée d'unités de multiplication matricielles spécialisées et de GEMM (par exemple, les cœurs tenseurs sur les GPU NVIDIA).
L'écart d'efficacité peut être comblé en réécrivant la FFT comme une série d'opérations de multiplication matricielle. Les membres de l’équipe de recherche ont atteint cet objectif en utilisant des matrices papillon pour explorer la formation clairsemée. Récemment, les chercheurs de Hazy Research ont exploité cette connexion pour créer des algorithmes de convolution rapides tels que FlashConv et FlashButterfly, en utilisant la décomposition papillon pour transformer les calculs FFT en une série d'opérations de multiplication matricielle.
De plus, des liens plus profonds peuvent être établis en s'appuyant sur des travaux antérieurs : notamment en laissant apprendre ces matrices, ce qui prend également le même temps mais ajoute des paramètres supplémentaires. Les chercheurs ont commencé à explorer ce lien sur quelques petits ensembles de données et ont obtenu de premiers résultats. Nous pouvons clairement voir ce que cette connexion peut apporter (par exemple, comment la rendre adaptée aux modèles de langage) :

Cette extension mérite d'être explorée plus en profondeur : cette extension apprend quel type de conversion et qu'est-ce que ça te permet de faire ? Que se passe-t-il lorsque vous l'appliquez à la modélisation du langage ?
Ce sont des directions passionnantes, et ce qui suivra sera des séquences de plus en plus longues et de nouvelles architectures qui nous permettront d'explorer davantage ce nouveau domaine. Nous devons accorder une attention particulière aux applications qui peuvent bénéficier de modèles de séquences longues, telles que l'imagerie haute résolution, les nouveaux formats de données, les modèles de langage capables de lire des livres entiers, etc. Imaginez donner un livre entier à un modèle de langage à lire et lui faire résumer le scénario, ou demander à un modèle de génération de code de générer un nouveau code basé sur le code que vous avez écrit. Il y a tellement de scénarios possibles, et ils sont tous très excitants.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI