
Maison >Périphériques technologiques >IA >Les médias américains révèlent un vaste ensemble de données de formation de modèles : certains contenus sont un peu 'sales'
Les médias américains révèlent un vaste ensemble de données de formation de modèles : certains contenus sont un peu 'sales'

- PHPzavant
- 2023-05-01 16:07:061352parcourir

Nouvelle du 20 avril, les chatbots d'intelligence artificielle sont devenus de plus en plus populaires au cours des quatre derniers mois. Leur capacité à accomplir diverses tâches, telles que rédiger des articles académiques complexes et mener des conversations intenses, est impressionnante.
Les chatbots ne pensent pas comme les humains, ils ne savent même pas de quoi ils parlent. Ils peuvent imiter la parole humaine parce que l’intelligence artificielle qui les anime a absorbé de grandes quantités de texte, dont une grande partie récupérée sur Internet.
Ces textes sont la principale source d’informations de l’IA sur le monde lors de sa construction, et ils peuvent avoir un impact profond sur la façon dont l’IA réagit. Si l’intelligence artificielle obtient d’excellents résultats à l’examen judiciaire, c’est peut-être parce que ses données de formation contiennent des milliers d’informations LSAT (Law School Admission Test, American Law School Admission Test).
Les entreprises technologiques restent toujours secrètes sur les informations qu'elles fournissent à l'intelligence artificielle. Le Washington Post a donc entrepris d’analyser l’un de ces ensembles de données importants, révélant les types de sites Web propriétaires, personnels et souvent offensants utilisés pour entraîner l’IA.
Pour explorer la composition interne des données de formation à l'intelligence artificielle, le Washington Post a collaboré avec des chercheurs de l'Allen Institute for Artificial Intelligence pour analyser l'ensemble de données C4 de Google. Cet ensemble de données est un instantané massif de plus de 15 millions de sites Web, dont le contenu est utilisé pour former de nombreuses IA anglophones de haut niveau, telles que le T5 de Google et le LLaMA de Facebook. OpenAI n'a pas divulgué le type d'ensemble de données utilisé pour former le modèle qui prend en charge le chatbot ChatGPT.
Dans cette enquête, les chercheurs ont utilisé les données de la société d'analyse Web Similarweb pour classer les sites Web. Environ un tiers de ces sites n'ont pu être classés et ont été exclus, principalement parce qu'ils n'existent plus sur Internet. Les chercheurs ont ensuite classé les 10 millions de sites Web restants en fonction du nombre de « jetons » apparaissant sur chaque site Web dans l'ensemble de données. Un jeton est un petit élément d'information de traitement de texte, généralement un mot ou une phrase, utilisé pour entraîner des modèles d'IA.
De Wikipédia à WoWhead
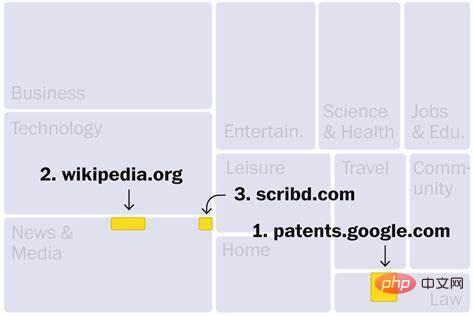
Les sites Web de l'ensemble de données C4 proviennent principalement de secteurs tels que l'actualité, le divertissement, le développement de logiciels, la médecine et la création de contenu. Cela pourrait expliquer pourquoi ces domaines pourraient être menacés par une nouvelle vague d’intelligence artificielle. Les trois principaux sites Web sont : le premier est Google Patent Search, qui contient des textes de brevets publiés dans le monde entier ; le deuxième est Wikipédia et le troisième est Scribd, une bibliothèque numérique qui n'accepte que les abonnements payants. En outre, parmi d’autres sites Web de haut rang, citons Library (n° 190), un marché de livres électroniques piratés, qui a été fermé par le ministère américain de la Justice pour activités illégales. En outre, l'ensemble de données contient au moins 27 sites Web identifiés par le gouvernement américain comme des marchés de produits piratés et contrefaits.
Il existe également des sites de premier plan, tels que le forum des joueurs de World of Warcraft wowhead (n° 181) et Thriveglobal (n° 181), un site fondé par Arianna Huffington pour aider à lutter contre le burn-out 175 bits). De plus, il existe au moins 10 sites Internet vendant des bennes à ordures, dont la benne à ordures (n° 183), mais celle-ci ne semble plus accessible.
Bien que la plupart des sites Web soient sûrs, certains présentent de sérieux problèmes de confidentialité. Par exemple, deux sites Web classés dans la liste des 100 premiers hébergeaient en privé des copies des bases de données nationales d’inscription des électeurs. Bien que les données des électeurs soient publiques, ces modèles peuvent utiliser ces informations personnelles de manière inconnue.
Les sites Web industriels et commerciaux occupent la plus grande catégorie (représentant 16% des tokens de la catégorie). En tête de liste se trouve The Motley Fool (n°13), qui fournit des conseils en investissement. Vient ensuite Kickstarter (n° 25), un site Web qui permet aux utilisateurs de financer des projets créatifs. Patreon, qui se classe plus bas au n°2 398, aide les créateurs à percevoir des frais mensuels auprès des abonnés pour du contenu exclusif.
Cependant, Kickstarter et Patreon peuvent permettre à l'intelligence artificielle d'accéder aux idées et aux textes marketing des artistes, et l'on craint que l'IA puisse copier ces œuvres lorsqu'elle fournit des suggestions aux utilisateurs. Les artistes, qui ne reçoivent actuellement aucune compensation lorsque leur travail est inclus dans les données de formation de l'IA, ont déposé des plaintes pour contrefaçon contre les générateurs de texte en image Stable Diffusion, MidJourney et DeviantArt.
Selon cette analyse du Washington Post, d'autres contestations juridiques pourraient survenir : il y a plus de 200 millions d'occurrences du symbole de droit d'auteur (indiquant les œuvres enregistrées comme propriété intellectuelle) dans l'ensemble de données C4.
Les sites Web techniques constituent la deuxième catégorie en importance, représentant 15 % des jetons de la catégorie. Cela inclut de nombreuses plateformes qui aident les gens à créer des sites Web, comme Google Sites (n° 85), qui contient des pages couvrant tout, depuis un club de judo à Reading, en Angleterre, jusqu'à un jardin d'enfants dans le New Jersey.
L'ensemble de données C4 contient également plus de 500 000 blogs personnels, représentant 3,8 % des contenus classifiés. La plateforme de publication Medium se classe 46e et est le cinquième site Web technologique en termes de taille, avec des dizaines de milliers de blogs sous son nom de domaine. De plus, il existe des blogs rédigés sur des plateformes telles que WordPress, Tumblr, Blogpot et Live Journal.
Ces blogs vont du professionnel au personnel, comme celui intitulé "Grumpy Rumblings" co-écrit par deux universitaires anonymes, dont l'un a récemment écrit sur leur partenaire Comment le chômage affecte les impôts d'un couple. En outre, l'ensemble de données C4 contient certains des meilleurs blogs axés sur les jeux de rôle en direct.
Le contenu des réseaux sociaux tels que Facebook et Twitter (qui sont considérés comme le cœur du Web moderne) ne peut pas être exploré, ce qui signifie que la plupart des ensembles de données utilisés pour entraîner l'intelligence artificielle ne peuvent pas y accéder. Les géants de la technologie comme Facebook et Google disposent de grandes quantités de données conversationnelles, mais ils ne savent pas encore comment utiliser les informations personnelles des utilisateurs pour former des modèles d’intelligence artificielle destinés à un usage interne ou pour les vendre en tant que produits.
Les sites d'information et de médias ont été classés troisièmes dans toutes les catégories, et la moitié des dix premiers sites étaient des médias d'information : le site Web du New York Times s'est classé quatrième et le site Web du Los Angeles Times s'est classé sixième, le site Web du Guardian le site Web de Forbes s'est classé septième, le site Web de Forbes s'est classé huitième, le site Web du Huffington Post s'est classé neuvième et le site Web du Washington Post s'est classé 11e. À l’instar des artistes et des créateurs, plusieurs organes de presse ont critiqué les entreprises technologiques pour avoir utilisé leur contenu sans autorisation ni compensation.
Dans le même temps, le "Washington Post" a également constaté que plusieurs médias étaient moins bien classés dans les évaluations de crédibilité indépendantes de NewsGuard : comme le russe RT (65ème), les sites d'information d'extrême droite breitbart (n°159). et le site Internet anti-immigration Vdare (n° 993), qui a été associé à la suprématie blanche.
Il a été prouvé que les chatbots partagent des informations erronées. Des données de formation non fiables peuvent les amener à propager des préjugés et à promouvoir la désinformation sans que les utilisateurs puissent les retracer jusqu'à leur source d'origine.
Les sites communautaires représentent environ 5% des contenus classés, principalement les sites religieux.
Quels poissons passent à travers le filtre ?
Comme la plupart des entreprises, Google filtre et examine les données avant de les transmettre à l'IA. En plus de supprimer les textes dénués de sens et répétitifs, la société utilise également une « liste de mauvais mots » open source qui comprend 402 termes anglais et un emoji. Les entreprises utilisent souvent des ensembles de données de haute qualité pour affiner leurs modèles afin de bloquer les contenus que les utilisateurs ne souhaitent pas voir.
Bien que de telles listes visent à empêcher les modèles d'être exposés à des insultes racistes et à des contenus inappropriés pendant leur formation, beaucoup de choses passent le filtre. Le Washington Post a trouvé des centaines de sites Web pornographiques et plus de 72 000 exemples de « nazis » sur la liste des mots interdits.
Pendant ce temps, le Washington Post a constaté que les filtres n'avaient pas réussi à supprimer certains contenus inquiétants, notamment les sites Web suprémacistes blancs, les sites Web anti-trans et les organisations ciblant les individus à des fins de harcèlement. Le célèbre forum de discussion anonyme 4chan. L’étude a également découvert des sites Web faisant la promotion de théories du complot.
Votre site internet est-il utilisé pour former l'IA ?
Le Web scraping peut ressembler à une copie de l'intégralité d'Internet, mais il s'agit en fait simplement de collecter des instantanés, un échantillon d'une page Web à un moment précis. L'ensemble de données C4 a été initialement créé par l'organisation à but non lucratif CommonCrawl pour l'exploration de contenu Web en avril 2019 et constitue une ressource populaire pour la formation de modèles d'intelligence artificielle. CommonCrawl a déclaré que l'organisation essaie de donner la priorité aux sites Web les plus importants et les plus réputés, mais ne fait aucune tentative pour éviter le contenu sous licence ou protégé par le droit d'auteur.
Le Washington Post estime qu'il est essentiel de présenter le contenu complet des données dans des modèles d'intelligence artificielle qui ont le potentiel de gérer de nombreux aspects de la vie moderne des gens. Cependant, de nombreux sites Web de cet ensemble de données contiennent un langage très offensant, et même si le modèle est entraîné à masquer ces mots, un contenu répréhensible peut toujours être présent.
Les experts affirment que même si l'ensemble de données C4 est énorme, les grands modèles de langage peuvent utiliser des ensembles de données encore plus volumineux. Par exemple, OpenAI a publié des données de formation GPT-3 en 2020, qui contiennent 40 fois la quantité de données Web récupérées dans C4. Les données de formation de GPT-3 comprennent l'intégralité de Wikipédia en anglais, une collection de romans gratuits d'auteurs inédits fréquemment utilisés par les grandes entreprises technologiques et une compilation de textes liés très appréciés par les utilisateurs de Reddit.
Les experts affirment que de nombreuses entreprises n'enregistrent même pas le contenu de leurs données de formation (même en interne) de peur de découvrir des informations personnellement identifiables, du matériel protégé par le droit d'auteur et d'autres données volées sans consentement. Alors que les entreprises soulignent la difficulté d’expliquer comment les chatbots prennent leurs décisions, il s’agit d’un domaine dans lequel les dirigeants doivent donner des réponses transparentes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI