
Maison >développement back-end >Tutoriel Python >Comment implémenter l'inspection automatique de l'interface de déclenchement de tâches planifiées Python Apscheduler Cron
Comment implémenter l'inspection automatique de l'interface de déclenchement de tâches planifiées Python Apscheduler Cron

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-01 10:40:061804parcourir
python cron interface de déclenchement de tâches planifiées inspection automatisée
Il existe plusieurs types de méthodes de déclenchement de tâches planifiées, qui sont utilisées dans travail quotidien, la méthode cron que les étudiants en R&D utilisent le plus souvent
J'ai vérifié que le framework APScheduler prend en charge plusieurs méthodes de tâches planifiées
Installez d'abord le module apscheduler
$ pip install apscheduler# 🎜 🎜#Le code est le suivant : (Les définitions et plages des différents paramètres temporels sont annotées dans la méthode)
from apscheduler.schedulers.blocking import BlockingScheduler
class Timing:
def __init__(self, start_date, end_date, hour=None):
self.start_date = start_date
self.end_date = end_date
self.hour = hour
def cron(self, job, *value_list):
"""cron格式 在特定时间周期性地触发"""
# year (int 或 str) – 年,4位数字
# month (int 或 str) – 月 (范围1-12)
# day (int 或 str) – 日 (范围1-31)
# week (int 或 str) – 周 (范围1-53)
# day_of_week (int 或 str) – 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun)
# hour (int 或 str) – 时 (范围0-23)
# minute (int 或 str) – 分 (范围0-59)
# second (int 或 str) – 秒 (范围0-59)
# start_date (datetime 或 str) – 最早开始日期(包含)
# end_date (datetime 或 str) – 分 最晚结束时间(包含)
# timezone (datetime.tzinfo 或str) – 指定时区
scheduler = BlockingScheduler()
scheduler.add_job(job, 'cron', start_date=self.start_date, end_date=self.end_date, hour=self.hour,
args=[*value_list])
scheduler.start()
def interval(self, job, *value_list):
"""interval格式 周期触发任务"""
# weeks (int) - 间隔几周
# days (int) - 间隔几天
# hours (int) - 间隔几小时
# minutes (int) - 间隔几分钟
# seconds (int) - 间隔多少秒
# start_date (datetime 或 str) - 开始日期
# end_date (datetime 或 str) - 结束日期
# timezone (datetime.tzinfo 或str) - 时区
scheduler = BlockingScheduler()
# 在 2019-08-29 22:15:00至2019-08-29 22:17:00期间,每隔1分30秒 运行一次 job 方法
scheduler.add_job(job, 'interval', minutes=1, seconds=30, start_date=self.start_date,
end_date=self.end_date, args=[*value_list])
scheduler.start()
@staticmethod
def date(job, *value_list):
"""date格式 特定时间点触发"""
# run_date (datetime 或 str) - 作业的运行日期或时间
# timezone (datetime.tzinfo 或 str) - 指定时区
scheduler = BlockingScheduler()
# 在 2019-8-30 01:00:01 运行一次 job 方法
scheduler.add_job(job, 'date', run_date='2019-8-30 01:00:00', args=[*value_list])
scheduler.start()La méthode d'encapsulation n'est pas très universelle, et le code sera optimisé plus tard, mais au moins, il peut être utilisé maintenant, hahahahahaha Après avoir réfléchi à l'idée, l'inspection déclenche la tâche, puis déclenche DingTalk, donc la tâche planifiée doit être regroupée dans le DingTalk partagé auparavant sur la couche supérieure Continuer à améliorer le bas du code if __name__ == '__main__':
file_list = ["test_shiyan.py", "MeetSpringFestival.py"]
# run_py(file_list)
case_list = ["test_case_01", "test_case_02"]
# run_case(test_sample, case_list)
dingDing_list = [2, case_list, test_sample]
# run_dingDing(*dingDing_list)
Timing('2022-02-15 00:00:00', '2022-02-16 00:00:00', '0-23').cron(run_dingDing, *dingDing_list) On met la fonction de run_dingDing() dans le Timing().cron(run_dingDing, *dingDing_list) déjà packagé, puis nous passons les paramètres dans run_dingDing() Passer dans le tuple c'est ce que nous avons écrit ci-dessus Vous pouvez le voir ici def cron(self, job, *value_list):
"""cron格式 在特定时间周期性地触发"""
scheduler.add_job(job, 'cron', start_date=self.start_date, end_date=self.end_date, hour=self.hour,
args=[*value_list]) J'ai mis le remplissage dans la plage horaire dans le. Initialisation de Timing(), ce qui rend la visualisation plus confortable. Vous pouvez déclencher le timing après avoir exécuté Timing().cron(), mais vous devez allumer l'ordinateur lorsque vous commencez la recherche. plus tard, ce sera bien de le stocker sur le serveur ~# 🎜🎜#erreur apscheduler : heure d'exécution du travail …… prochaine exécution à : ……)" a été manqué par
apscheduler Une erreur similaire à la suivante s'est produite pendant le processus en cours : #🎜 🎜#
Durée d'exécution du travail "9668_hack (déclencheur : intervalle[1:00:00], prochaine exécution à : 2018-10-29 22:00:00 CST)" a été manqué par 0 : 01:47.387821Heure d'exécution du travail "9668_index (déclencheur : intervalle[0:30:00], prochaine exécution à : 2018-10-29 21 :30:00 CST)" a été manqué par 0:01:47.392574Heure d'exécution de la tâche "9669_deep (déclencheur : intervalle[1:00:00], prochaine exécution à : 2018-10-29 22:00:00 CST)" a été manqué par 0:01:47.397622L'heure d'exécution du travail "9669_hack (déclencheur : intervalle [1:00:00], prochaine exécution à : 2018-10-29 22:00:00 CST)" a été manquée par 0:01 : 47.402938L'heure d'exécution de la tâche "9669_index (déclencheur : intervalle[0:30:00], prochaine exécution à : 2018-10-29 21:30:00 CST)" a été manquée par 0:01:47.407996
#🎜 🎜#Baidu ne peut fondamentalement pas signaler ce problème, Google La configuration de la clé a été atteinte, mais l'erreur s'est toujours produite, j'ai donc continué à chercher des informations et découvert ce qui causait ce problème.paramètre misfire_grace_time
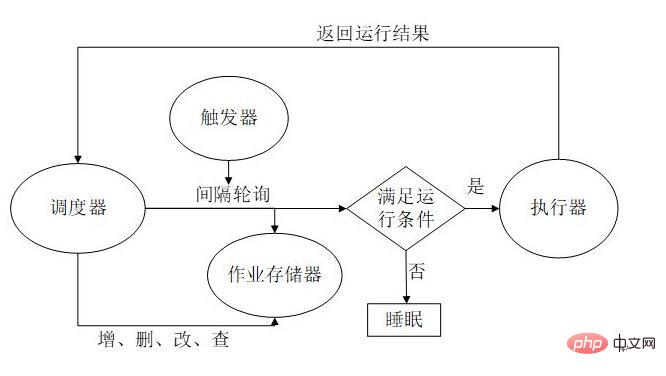 Il y a un paramètre mentionné : misfire_grace_time, mais à quoi sert ce paramètre j'ai trouvé une explication ? quelque part, ce qui implique plusieurs autres paramètres, mais je vais le résumer en fonction de ma propre compréhension
Il y a un paramètre mentionné : misfire_grace_time, mais à quoi sert ce paramètre j'ai trouvé une explication ? quelque part, ce qui implique plusieurs autres paramètres, mais je vais le résumer en fonction de ma propre compréhension
coalesce : Quand pour certains Pour cette raison, un travail s'accumule plusieurs fois et ne s'exécute pas réellement (par exemple, le système se bloque pendant 5 minutes puis récupère, et une tâche est exécutée toutes les minutes. Logiquement parlant, ces 5 minutes étaient initialement "prévues" pour s'exécuter. 5 fois , mais pas réellement exécuté). Si coalesce est True, la prochaine fois que le travail sera soumis à l'exécuteur, il ne sera exécuté qu'une seule fois, si c'est False, il sera exécuté 5 fois (pas nécessairement). , Parce qu'il y a d'autres conditions, voir l'explication de misfire_grace_time plus tard)
max_instance: C'est-à-dire que le même travail peut avoir à La plupart des instances en même temps. Exécutez, par exemple, un travail qui prend 10 minutes est désigné pour s'exécuter une fois par minute. Si notre valeur max_instance est 5, alors entre la 6e et la 10e minute, la nouvelle instance en cours d'exécution ne sera pas exécutée. car il y a déjà 5 instances. Après avoir exécutécoalesce:当由于某种原因导致某个job积攒了好几次没有实际运行(比如说系统挂了5分钟后恢复,有一个任务是每分钟跑一次的,按道理说这5分钟内本来是“计划”运行5次的,但实际没有执行),如果coalesce为True,下次这个job被submit给executor时,只会执行1次,也就是最后这次,如果为False,那么会执行5次(不一定,因为还有其他条件,看后面misfire_grace_time的解释)max_instance:就是说同一个job同一时间最多有几个实例再跑,比如一个耗时10分钟的job,被指定每分钟运行1次,如果我们max_instance值为5,那么在第6~10分钟上,新的运行实例不会被执行,因为已经有5个实例在跑了misfire_grace_time
misfire_grace_time : Imaginez un scénario similaire à la fusion ci-dessus si un travail était initialement exécuté à. Il est maintenant 14h00, mais en raison d'une certaine raison, il n'a pas été planifié. Lorsque cette instance en cours d'exécution à 14h00 est soumise, elle vérifie la différence entre son heure d'exécution planifiée et l'heure actuelle. (ici 1 minute) est supérieur à la limite de 30 secondes que nous avons fixée, alors cette instance en cours d'exécution ne sera pas exécutée.
Exemple :
Pour une tâche toutes les 15 minutes, misfire_grace_time est réglé sur 100 secondes, à 0:06 Invite lors de la division :
Heure d'exécution du travail "9392_index (déclencheur : intervalle[0:15:00], prochaine exécution à : 2018-10-27 00:15 : 00 CST )" a été manqué par 0:06:03.931026. La tâche exécutée à 0:00 n'a pas été planifiée pour une raison quelconque, et il a été demandé que l'exécution suivante (0:15) soit différente de 6 minutes de celle en cours (seuil 100). secondes), donc il ne s'exécutera pas à 0:15
- Ce paramètre peut donc être communément compris comme la configuration de tolérance aux pannes de délai d'attente de la tâche. Donnez à l'exécuteur un délai d'attente. Si dans ce délai, ce qui doit être exécuté n'est pas terminé, vous devez arrêter TNDing Run.
- J'ai donc modifié la configuration comme suit :
class Config(object): SCHEDULER_JOBSTORES = { 'default': RedisJobStore(db=3,host='0.0.0.0', port=6378,password='******'), } SCHEDULER_EXECUTORS = { 'default': {'type': 'processpool', 'max_workers': 50} #用进程池提升任务处理效率 } SCHEDULER_JOB_DEFAULTS = { 'coalesce': True, #积攒的任务只跑一次 'max_instances': 1000, #支持1000个实例并发 'misfire_grace_time':600 #600秒的任务超时容错 } SCHEDULER_API_ENABLED = True我本以为这样应该就没什么问题了,配置看似完美,但是现实是残忍的,盯着apscheduler日志看了一会,熟悉的“was missed by”又出现了,这时候就需要怀疑这个配置到底有没有生效了,然后发现果然没有生效,从/scheduler/jobs中可以看到任务:
{ "id": "9586_site_status", "name": "9586_site_status", "func": "monitor_scheduler:monitor_site_status", "args": [ 9586, "http://sl.jxcn.cn/", 1000, 100, 200, "", 0, 2 ], "kwargs": {}, "trigger": "interval", "start_date": "2018-09-14T00:00:00+08:00", "end_date": "2018-12-31T00:00:00+08:00", "minutes": 15, "misfire_grace_time": 10, "max_instances": 3000, "next_run_time": "2018-10-24T18:00:00+08:00" }可以看到任务中默认就有misfire_grace_time配置,没有改为600,折腾一会发现修改配置,重启与修改任务都不会生效,只能修改配置后删除任务重新添加(才能把这个默认配置用上),或者修改任务的时候把这个值改掉
scheduler.modify_job(func=func, id=id, args=args, trigger=trigger, minutes=minutes,start_date=start_date,end_date=end_date,misfire_grace_time=600)
然后就可以了?图样图森破,missed 依然存在。
其实从后来的报错可以发现这个容错时间是用上的,因为从执行时间加上600秒后才出现的报错。
找到任务超时的根本原因
那么还是回到这个超时根本问题上,即使容错时间足够长,没有这个报错了,但是一个任务执行时间过长仍然是个根本问题,所以终极思路还在于如何优化executor的执行时间上。
当然这里根据不同的任务处理方式是不一样的,在于各自的代码了,比如更改链接方式、代码是否有冗余请求,是否可以改为异步执行,等等。
而我自己的任务解决方式为:由接口请求改为python模块直接传参,redis链接改为内网,极大提升执行效率,所以也就控制了执行超时问题。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!