
Maison >Périphériques technologiques >IA >À partir de GPT-3, continuez à écrire l'immense arbre généalogique de Transformer
À partir de GPT-3, continuez à écrire l'immense arbre généalogique de Transformer

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-30 23:34:10774parcourir
Récemment, le grand langage de la guerre des armes a occupé la majeure partie de la place dans le cercle d'amis. Il y a eu de nombreux articles discutant de ce que ces modèles peuvent faire et de leur valeur commerciale. Cependant, en tant que jeune chercheur immergé dans le domaine de l’intelligence artificielle depuis de nombreuses années, je suis davantage préoccupé par les principes techniques qui sous-tendent cette course aux armements et par la manière dont ces modèles sont conçus au profit de l’humanité. Plutôt que d'examiner comment ces modèles peuvent être rentables et conçus pour apporter des avantages à davantage de personnes, ce que je souhaite explorer est la raison de ce phénomène et ce que nous, chercheurs, pouvons faire pour parvenir à « être remplacés par l'IA » avant que l'IA ne remplace les humains. . Alors prenez votre retraite avec honneur » et faites quelque chose.
Il y a trois ans, lorsque GPT-3 a provoqué un tollé dans le monde de la technologie, j'ai tenté d'analyser la grande famille derrière GPT de manière historique. J'ai trié le contexte technique derrière GPT par ordre chronologique (Figure 1) et j'ai essayé d'expliquer les principes techniques derrière le succès de GPT. Cette année, ChatGPT, le fils cadet de GPT-3, semble être plus intelligent et peut communiquer avec les gens via le chat, ce qui sensibilise davantage de personnes aux derniers progrès dans le domaine du traitement du langage naturel. En ce moment historique, en tant qu’historiens de l’IA, nous devrions peut-être prendre un moment pour revenir sur ce qui s’est passé ces dernières années. Le premier article utilise GPT-3 comme point de départ, cette série est donc en fait un enregistrement de l'ère post-GPT (livre post-GPT). En explorant les changements dans la famille GPT, j'ai réalisé que la plupart des histoires sont liées. à Transformer, donc le nom de cet article est la famille Transformer.
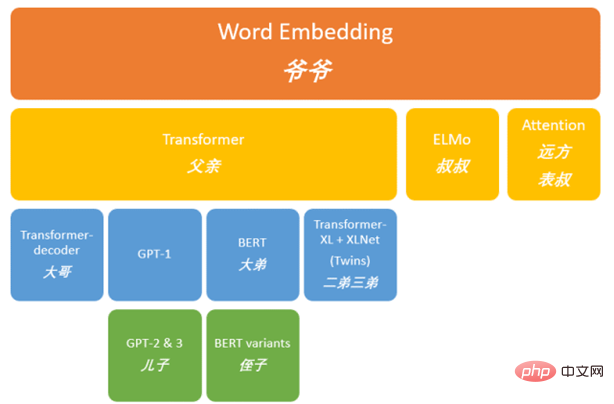
Figure 1. GPT ancienne généalogie
Revue précédente
Avant de commencer officiellement à présenter la famille Transformer, passons en revue ce qui s'est passé dans le passé selon la figure 1. A partir de Word Embedding [1,2], le vecteur (une chaîne de nombres) inclut la sémantique du texte d'une manière étrange mais efficace. La figure 2 montre une illustration de cette représentation : représentée par des nombres (Roi - Homme + femme =). reine). C’est sur cette base qu’a été créée cette immense famille du NLP (traitement du langage naturel).
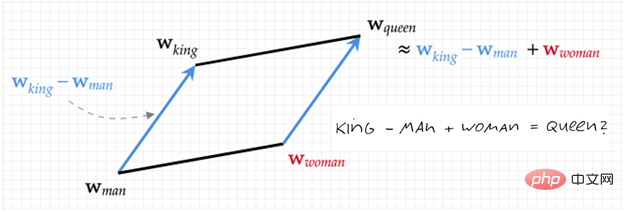
Figure 2. Diagramme Word2Vec (Roi - Homme + Femme = Reine)
Après cela, son fils aîné ELMo [3] a découvert l'importance du contexte, comme les deux phrases suivantes :
#🎜🎜 #"Oh ! Tu as acheté ma pizza préférée, je t'aime tellement !"
"Ah, je t'aime tellement ! Toi ! Vraiment frotter ma pizza préférée sur le sol ? ELMo a résolu ce problème avec succès en « donnant à un modèle une chaîne de mots, puis en demandant au modèle de prédire le mot suivant et le mot précédent (contexte) ».
Au même moment, un cousin éloigné de Word Embedding a découvert un autre problème : lorsque les gens comprennent une phrase, ils se concentrent sur certains mots, un phénomène évident. lorsque nous lisons notre langue maternelle, de nombreuses fautes de frappe seront facilement ignorées. C'est parce que nous n'y prêtons pas attention lors de la compréhension de ce passage. Par conséquent, il a proposé le mécanisme Attention [4], mais le mécanisme Attention à cette époque était très précoce et ne pouvait pas fonctionner seul, il ne pouvait donc être attaché qu'à des modèles de séquence tels que RNN et LSTM. La figure 3 montre le processus de combinaison du mécanisme d'attention et du RNN, et explique également pourquoi l'attention elle-même ne peut pas fonctionner seule. Parlons brièvement du processus de travail du modèle PNL. Tout d'abord, nous avons une phrase, telle que "Je t'aime Chine". Il s'agit de cinq caractères, qui peuvent être transformés en x_1-x_5 dans la figure 3, puis chaque caractère le sera. deviennent ce que nous venons de dire. Le mot intégration (une chaîne de nombres) est h_1-h_5 dans la figure 3, puis ils deviennent finalement une sortie, comme "J'aime la Chine" (tâche de traduction), qui est x_1'-x_3' dans Figure 3 . La partie restante de la figure 3 est le mécanisme d'attention, qui est A sur la figure 3. Cela équivaut à attribuer un poids à chaque h, afin que nous sachions quels mots sont les plus importants lors de la conversion du mot actuel. Pour des détails spécifiques, veuillez vous référer à l'article que j'ai écrit à l'origine (commençant par word2vec et parlant de l'immense arbre généalogique de GPT). On voit que la représentation numérique est ici la base de toute la tâche, c'est pourquoi le mécanisme Attention ne peut pas fonctionner seul.
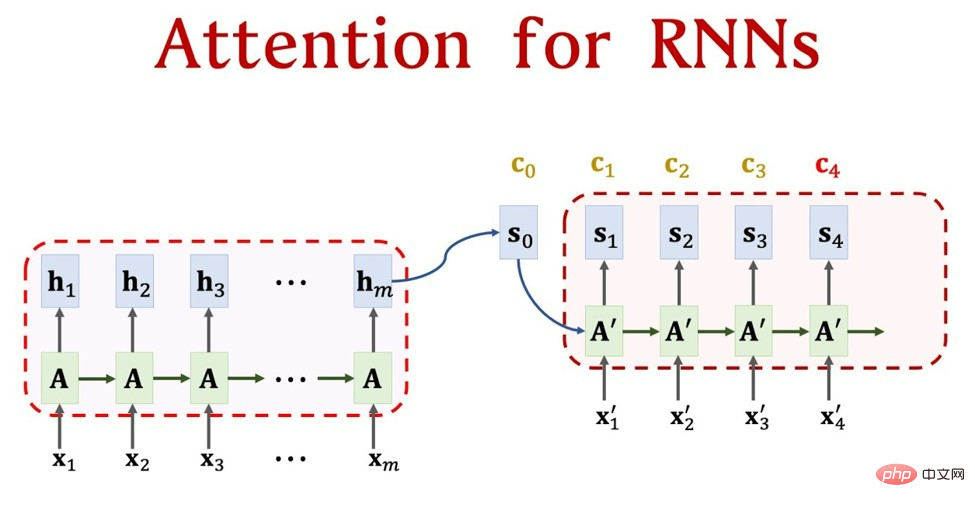
Figure 3. Premières photos - Combinaison puissante d'attention et de RNN (source : Attention pour les modèles RNN Seq2Seq (vitesse 1,25x recommandée) - YouTube)
En ce moment, en tant que fière ligne directe des proches de la famille royale, Transformer ne reconnaît pas cette dépendance à l'égard des autres. Dans l'article « L'attention est tout ce dont vous avez besoin » (vous n'avez besoin que du mécanisme d'attention) [5], Transformer a proposé sa propre méthode indépendante avec l'ajout de. un mot, il devient un « mécanisme d'auto-attention », qui peut générer la chaîne de nombres en utilisant uniquement le mécanisme d'attention. Nous utilisons la médecine traditionnelle chinoise pour expliquer ce changement. On peut dire que le mécanisme d'attention initial est le dosage de chaque matériau, mais lorsque vous allez finalement chercher le médicament, le médicament est entre les mains d'un préparateur de médicaments comme RNN ou LSTM. Bien sûr, l'ordonnance que nous prescrivons doit également l'être. basé sur la pharmacie (RNN, Quel médicament y a-t-il dans LSTM). Ce que fait Transformer, c'est simplement reprendre le droit de collecter des médicaments (ajouter la matrice de valeur), puis changer la façon de prescrire les médicaments (ajouter les matrices de clé et de requête). À l'heure actuelle, Source peut être considérée comme une boîte de stockage dans un magasin de médecine traditionnelle chinoise. Les médicaments dans la boîte de stockage sont composés de l'adresse Clé (nom du médicament) et de la valeur (médicament). Il existe actuellement une requête avec Clé = Requête. (prescription), et le but est de retirer la valeur correspondante (médicament) de la boîte de stockage, qui est la valeur Attention. L'adressage se fait en comparant la similitude entre la requête et l'adresse de l'élément clé dans la boîte de stockage. La raison pour laquelle on l'appelle adressage doux signifie que nous ne trouvons pas seulement un médicament dans la boîte de stockage, mais que nous pouvons également le trouver dans chaque. Clé. Le contenu sera récupéré à partir de l'adresse. L'importance du contenu récupéré (le montant) est déterminée en fonction de la similitude entre la requête et la clé. Ensuite, la valeur est pondérée et additionnée, de sorte que la valeur finale (une paire de valeurs traditionnelles). Médecine chinoise) peut être récupérée, ce qui est une valeur d'attention. Par conséquent, de nombreux chercheurs considèrent le mécanisme Attention comme un cas particulier d’adressage doux, ce qui est également très raisonnable [6].
À partir de ce moment-là, Transformer a officiellement commencé à mener la famille vers la prospérité.
Transformer réussit
En fait, on peut voir sur la figure 1 que Transformer est la lignée de descendants la plus prospère de la famille de grand-père, ce qui prouve également que le sujet « L'attention est tout ce dont vous avez besoin » à l'époque était en effet bien- fondé. Bien que je viens de parler de ce qu'est le mécanisme d'auto-attention qu'il a proposé, l'article précédent (commençant par word2vec, parlant de l'immense arbre généalogique de GPT) a déjà parlé en détail du processus d'évolution de Transformer. Voici un aperçu rapide. pour les nouveaux étudiants. Jetons un coup d’œil à ce qu’est l’architecture du transformateur.
Pour faire simple, on peut considérer le Transformer comme un "acteur". Pour cet "acteur", l'encodeur est comme la mémoire de l'acteur, chargé de convertir les lignes en une représentation intermédiaire (abstraite dans notre esprit) Je ne sais pas ce que c'est, c'est-à-dire la compréhension de l'acteur), et le décodeur est comme la performance de l'acteur, chargé de convertir la compréhension de l'esprit en un affichage sur l'écran. Le mécanisme d'auto-attention le plus important ici est la concentration de l'acteur, qui peut automatiquement ajuster son attention dans différentes positions, comprenant ainsi mieux toutes les lignes et lui permettant de jouer plus naturellement et plus facilement dans différentes situations.
Plus précisément, on peut considérer Transformer comme une grande « usine de traitement du langage ». Dans cette usine, chaque travailleur (encodeur) est responsable du traitement d'une position dans la séquence d'entrée (dire un mot), de son traitement et de sa transformation, puis de sa transmission au travailleur suivant (encodeur). Chaque travailleur dispose d'une description de poste détaillée (mécanisme d'auto-attention) qui détaille comment traiter les entrées de l'emplacement actuel et comment établir des associations avec les emplacements précédents. Dans cette usine, chaque travailleur peut travailler simultanément sur ses propres tâches, de sorte que l’ensemble de l’usine peut traiter efficacement de grandes quantités de données d’entrée.
Transformer a immédiatement remporté le trône sans aucun suspense grâce à sa grande force et ses deux fils ambitieux (BERT et GPT). BERT (Bidirectionnel Encoder Representations from Transformers) [1] a hérité de la partie Encoder de Transformer et a remporté la première moitié du concours, mais a perdu face à GPT en termes de polyvalence en raison de ses limites. L'honnête GPT (Generative Pre-trained Transformer) [7-10] a hérité de la partie décodeur, a honnêtement appris de zéro, a appris les méthodes de communication humaine et a finalement réussi à dépasser en seconde période.
Bien entendu, les ambitions de Transformer ne s’arrêtent évidemment pas là. « L’attention est tout ce dont vous avez besoin » ne fait pas référence uniquement au domaine de la PNL. Avant de présenter les rancunes entre GPT et BERT, jetons d’abord un coup d’œil à ce que leur père a fait.
Nouvelle Généalogie - Princes Linli
"Père, les temps ont changé. Notre famille obtiendra la vraie gloire grâce à mes efforts. »#🎜 🎜#
——Transformer
Après avoir compris le mécanisme de Transformer, nous pouvons y jeter un œil. fort développement de Transformer, dans quelle mesure la famille Transformer s'est-elle développée maintenant (nouvelle généalogie). Comme le montre l'exemple "acteur" précédent, Transformer représente une méthode d'apprentissage conforme à la logique humaine, il peut donc traiter non seulement du texte, mais également des images. La figure 2 résume la solide origine familiale de la famille Transformer. En plus de permettre à GPT et BERT de continuer à innover dans le domaine original du NLP (traitement du langage naturel), Transformer a également commencé à s'impliquer dans le domaine de la vision par ordinateur. Ses cadets (ViT proposé par Google, etc.) brillent également dans ce domaine. En 2021, Vision Transformer a marqué le début d'une grande explosion et un grand nombre de travaux basés sur Vision Transformer ont balayé les tâches de vision par ordinateur. Naturellement, en tant que famille, la famille Transformer communiquera toujours entre elle, et CLIP, qui relie le texte et les images (IA painting), a vu le jour. Fin 2022, Stable Diffusion était très populaire avant ChatGPT. De plus, CLIP ouvre également de nouvelles portes à la multimodalité pour la famille Transformer. En plus des mots et des images, les mots peuvent-ils aussi faire de la musique et peuvent-ils aussi dessiner des images ? Des transformateurs multimodaux et multitâches ont également vu le jour. Bref, chaque domaine est un prince. Un Transformateur parti de zéro dans le domaine de la PNL est devenu un « Roi de Zhou » qui peut confier des princes après avoir travaillé dur pour se développer.
Il y a beaucoup de princes, et cela devrait être un âge prospère.
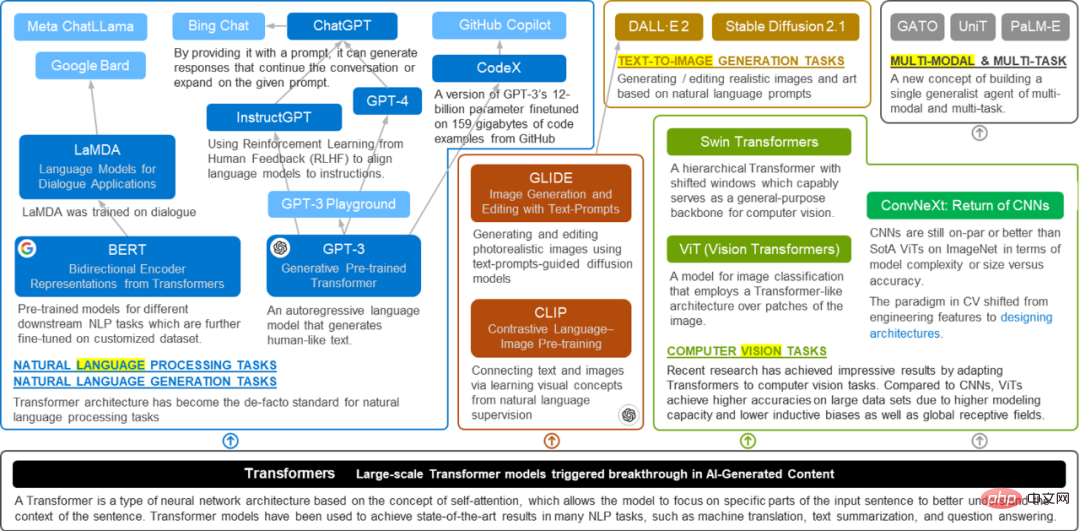
Figure 4. L'arbre généalogique de plus en plus prospère de la famille Transformer#🎜 🎜# Un petit test - Vision Transformer [12]
Avant de parler de GPT, il faut encore parler de la première chose faite par Transformer Une tentative audacieuse - c'est-à-dire laisser mon plus jeune fils s'impliquer dans le domaine du CV. Jetons d'abord un coup d'œil à la vie du plus jeune fils :
- Son père Transformer est né en 2017 dans un article intitulé Attention is All You Need.
- En 2019, Google a proposé une architecture Vision Transformer (ViT) capable de traiter directement les images sans utiliser de couche convolutive (CNN). Le titre de l'article est toujours aussi simple : « Une image vaut 16x16 mots ». Comme le montre la figure 5, son idée de base est de diviser l'image d'entrée en une série de petits blocs. Chaque petit bloc peut être compris comme un texte lors du traitement des articles dans le passé, puis convertir ces petits blocs en vecteurs, comme dans ordinaire Le Transformer gère le texte de la même manière. Si dans le domaine du traitement du langage naturel (NLP), le mécanisme d'attention de Transformer tente de capturer la relation entre les différents mots du texte, alors dans le domaine de la vision par ordinateur (CV), ViT tente de capturer la relation entre les différentes parties du texte. l'image.

Photo 5 . Comment ViT traite les images (source : Les Transformers sont-ils meilleurs que ceux de CNN en matière de reconnaissance d'images ? | par Arjun Sarkar | Towards Data Science) Depuis lors, divers modèles basés sur Transformer ont émergé les uns après les autres et ont obtenu des résultats au-delà de CNN sur les tâches correspondantes. Alors quels sont les avantages de Transformer ? Revenons à l'exemple du film et voyons la différence entre Transformer et CNN : Imaginez que vous êtes un réalisateur. Pour tourner un film, vous devez positionner les acteurs et placer différents éléments aux bons endroits. Par exemple, placez les acteurs sur le bon arrière-plan et utilisez la bonne lumière, pour donner un aspect à l'ensemble de l'image. harmonieux et beau. Pour CNN, c'est comme un photographe professionnel qui capture chaque image pixel par pixel, puis en extrait certaines caractéristiques de bas niveau telles que les bords et les textures. Ensuite, il combine ces fonctionnalités pour former des fonctionnalités de niveau supérieur, telles que des visages, des actions, etc., et obtient finalement un cadre. Au fur et à mesure que le film progresse, CNN répète ce processus jusqu'à ce que l'intégralité du film soit tournée. Pour ViT, c'est comme un directeur artistique, qui considérera l'image entière dans son ensemble, en tenant compte de facteurs tels que l'arrière-plan, la lumière, la couleur, etc., attribuera des positions et des angles appropriés à chaque acteur et créera a Une image parfaite. ViT regroupe ensuite ces informations dans un vecteur et les traite à l'aide d'un perceptron multicouche, ce qui donne lieu à une trame. Au fur et à mesure que le film progresse, ViT répète ce processus jusqu'à ce que le film entier soit créé. Retour à la tâche de traitement d'image, disons que nous avons une image de 224 x 224 pixels d'un chat et que nous voulons la classer à l'aide d'un réseau neuronal. Si nous utilisons un réseau neuronal convolutif traditionnel, il peut adopter plusieurs couches de convolution et de regroupement pour réduire progressivement la taille de l'image, et enfin obtenir un vecteur de caractéristiques plus petit, qui est ensuite classé via une couche entièrement connectée. Le problème avec cette méthode est que pendant le processus de convolution et de pooling, nous perdons progressivement des informations dans l'image car nous ne pouvons pas considérer la relation entre tous les pixels en même temps. De plus, en raison de la restriction d'ordre des couches de convolution et de pooling, nous ne pouvons pas effectuer d'échange d'informations global. En revanche, si nous utilisons le Transformer et le mécanisme d'auto-attention pour traiter cette image, nous pouvons directement traiter l'image entière comme une séquence et effectuer des calculs d'auto-attention sur elle. Cette méthode ne perd aucune relation entre les pixels et permet une interaction globale des informations. De plus, Étant donné que le calcul de l'auto-attention est parallélisable, nous pouvons traiter l'image entière en même temps, accélérant considérablement le calcul. Par exemple, supposons que nous ayons une phrase : « J'aime manger de la glace », qui contient 6 mots. En supposant maintenant que nous utilisons un modèle basé sur le mécanisme d'auto-attention pour comprendre cette phrase, le Transformer peut : Cependant, ViT nécessite des ensembles de données à grande échelle et des images haute résolution pour réaliser son plein potentiel. Par conséquent, bien que les Vision Transformers fonctionnent exceptionnellement bien dans le domaine du CV, l'application et la recherche de CNN dans le domaine de l'informatique. la vision est encore plus étendue et présente des avantages dans des tâches telles que la détection et la segmentation de cibles. Mais ce n'est pas grave, vous avez assez bien réussi, et l'intention initiale de votre père de s'impliquer dans CV n'était pas de remplacer CNN, il avait un objectif plus ambitieux. La base de cet objectif est le « en plus » dont j'ai parlé plus tôt. J'ai déjà dit que Transformer avait un objectif plus ambitieux, qui est un "grand modèle", un super super gros modèle. En plus de ce que j'ai dit dans l'article précédent, le transformateur peut mieux obtenir des informations globales, une complexité de calcul moindre et un meilleur parallélisme sont devenus la base de la prise en charge de grands modèles. En 2021, en plus des grands progrès de Vision Transformer, l'équipe GPT se prépare toujours intensivement pour GPT3.5, le travailleur modèle Transformer qui ne peut pas prendre de temps a conduit à un nouveau point culminant. - Lier le texte et les images. Ce point culminant a également donné le coup d’envoi du projet « grand modèle » en dehors du domaine de la PNL. À l'heure actuelle, les lacunes de Transformer dans les tâches visuelles se sont transformées en avantages. "ViT nécessite des ensembles de données à grande échelle et des images haute résolution pour atteindre son plein potentiel." En d'autres termes, "ViT peut gérer des ensembles de données à grande échelle et des images haute résolution". Anciennes règles, parlons d'abord de ce qu'est CLIP. Le nom complet du CLIP est Pré-Formation Contrastive Langue-Image. Évidemment, son idée de base est l'apprentissage contrastif dans le domaine du CV traditionnel. Lorsque nous apprenons de nouvelles connaissances, nous lisons différents livres et articles pour obtenir beaucoup d'informations. Cependant, nous ne nous contentons pas de mémoriser tous les mots et phrases de chaque livre ou article. Nous essayons plutôt de trouver des similitudes et des différences entre ces informations. Par exemple, nous pourrions remarquer que la façon dont un sujet est décrit et les concepts clés présentés peuvent différer dans différents livres, mais que les concepts qu'ils décrivent sont essentiellement les mêmes. Cette manière de trouver des similitudes et des différences est l’une des idées fondamentales de l’apprentissage contrastif. Nous pouvons considérer chaque livre ou article comme un échantillon différent, et les livres ou articles sur le même sujet peuvent être considérés comme des instances différentes de la même catégorie. Dans l'apprentissage contrastif, nous entraînons le modèle pour apprendre à distinguer ces différentes catégories d'échantillons afin d'apprendre leurs similitudes et leurs différences. Ensuite, de manière un peu plus académique, disons que vous souhaitez former un modèle à identifier les marques de voitures. Vous pouvez avoir un ensemble d'images de voitures étiquetées, chacune avec une étiquette de marque, telle que "Mercedes-Benz", "BMW", "Audi", etc. Dans l'apprentissage supervisé traditionnel, vous introduisez ensemble l'image et l'étiquette de marque dans le modèle et laissez le modèle apprendre à prédire l'étiquette de marque correcte. Mais dans l'apprentissage contrastif, vous pouvez utiliser des images non étiquetées pour entraîner le modèle. Supposons que vous disposiez d'un ensemble d'images de voitures non étiquetées, vous pouvez diviser ces images en deux groupes : les échantillons positifs et les échantillons négatifs. Les échantillons positifs sont des images de la même marque sous différents angles, tandis que les échantillons négatifs sont des images de marques différentes. Ensuite, vous pouvez utiliser l'apprentissage contrastif pour entraîner le modèle afin que les échantillons positifs de la même marque soient plus proches les uns des autres et que les échantillons négatifs de différentes marques soient plus éloignés les uns des autres. De cette façon, le modèle peut apprendre à extraire des images des caractéristiques spécifiques à la marque sans avoir à lui indiquer explicitement le label de marque de chaque image. Évidemment, il s'agit d'un modèle d'apprentissage auto-supervisé. CLIP est également un modèle d'apprentissage auto-supervisé similaire, sauf que son objectif est de connecter le langage et les images. permet à l'ordinateur de comprendre la relation entre le texte et les images. Imaginez que vous apprenez un ensemble de listes de vocabulaire où chaque mot a sa définition et l'image correspondante. Pour chaque mot et son image correspondante, vous pouvez les considérer comme une paire. Votre tâche consiste à trouver la corrélation entre ces mots et ces images, c'est-à-dire quels mots correspondent à quelles images et lesquels ne correspondent pas. Comme le montre la figure 6, pour l'algorithme d'apprentissage contrastif, ces paires de mots et d'images sont ce qu'on appelle « ancre » (échantillon d'ancre) et « positif » ( échantillon positif). « ancre » fait référence à l'objet que nous voulons apprendre, et « positif » est l'échantillon qui correspond à « ancre ». Le contraire est un échantillon « négatif », c'est-à-dire un échantillon qui ne correspond pas à « l'ancre ». Dans l'apprentissage contrastif, on associe « ancre » et « positif » et on essaie de les distinguer. Nous allons également associer « ancre » et « négatif » et essayer de les distinguer. Ce processus peut être compris comme la recherche de similitudes entre « ancre » et « positif » et l’élimination des similitudes entre « ancre » et « négatif ». Figure 6. Icône d'apprentissage contrasté [14] . L'ancre est l'image originale. Les positifs sont généralement des images originales recadrées et pivotées, ou des images connues de la même catégorie. Les négatifs peuvent être définis simplement et grossièrement comme des images inconnues (éventuellement de la même catégorie) ou des images déjà connues. . Pour atteindre cet objectif, CLIP pré-entraîne d'abord un grand nombre d'images et de textes, puis utilise le modèle pré-entraîné pour effectuer des tâches en aval telles que la classification, la récupération et la génération. Le modèle CLIP utilise une nouvelle méthode d'apprentissage auto-supervisé qui traite simultanément le texte et les images et apprend à les connecter grâce à la formation. Il partage un mécanisme d'attention entre le texte et les images et utilise un ensemble simple de paramètres réglables pour apprendre ce mappage. Il utilise un encodeur de texte basé sur un transformateur et un encodeur d'image basé sur CNN, puis calcule la similarité entre l'intégration d'image et de texte. CLIP apprend à associer des images et du texte en utilisant un objectif d'apprentissage contrastif qui maximise la cohérence entre les paires image-texte présentes dans les données et minimise la cohérence entre les paires image-texte échantillonnées aléatoirement. Figure 7. Illustration CLIP [13]. Par rapport à la figure 6, on peut simplement comprendre que le positif et le négatif de la figure 6 sont tous deux du texte. Par exemple, si nous voulons utiliser CLIP pour identifier si une image est une "plage rouge", nous pouvons saisir ce Donné une description textuelle et une image, CLIP générera une paire de vecteurs représentant leur connexion. Si la distance entre cette paire de vecteurs est très petite, cela signifie que l'image peut être une "plage rouge", et vice versa. Avec cette approche, CLIP permet des tâches telles que la classification d'images et la recherche d'images. Retour au nom complet, le dernier mot de CLIP est la pré-formation, son essence est donc toujours un modèle de pré-formation, mais il peut être utilisé pour diverses applications en aval impliquant des images et du texte correspondant à des tâches telles que la classification d'images, l'apprentissage sans tir et la génération de descriptions d'images. Par exemple, CLIP peut être utilisé pour classer les images en catégories données par des étiquettes en langage naturel, telles que « photos de chiens » ou « paysages ». CLIP peut également être utilisé pour générer des légendes d'images en utilisant un modèle de langage conditionné par les caractéristiques de l'image extraites par CLIP. De plus, CLIP peut être utilisé pour générer des images à partir de texte en utilisant des modèles génératifs conditionnés par les caractéristiques du texte extraites par CLIP. Avec l'aide de CLIP, un nouveau prince est apparu - son nom est AIGC (contenu généré par l'IA ). En fait, ChatGPT est essentiellement un type d’AIGC, mais dans cette section, nous parlons principalement de peinture IA. Jetons d'abord un coup d'œil à l'historique de développement de cette petite famille de peinture IA : La lignée de cette famille est visible en images et en texte connectés par le frère aîné, et son frère jumeau DALL-E en a profité pour proposer. la tâche du texte à l’image. Afin d'améliorer cette tâche, un cousin éloigné, Stable diffusion, a amélioré l'algorithme de génération d'images. Enfin, DALL-E-2 a appris les uns des autres et a combiné les avantages de GPT-3, CLIP et de diffusion stable pour compléter sa propre IA. système de peinture. Pour le DALL-E original, supposez que vous êtes un peintre et que DALL-E est votre boîte à outils. Dans cette métaphore, il y a deux outils principaux dans la boîte à outils : l’un est le pinceau et l’autre est la palette. Brush est le décodeur de DALL-E qui convertit une description textuelle donnée en image. La palette est l'encodeur de DALL-E, qui peut convertir n'importe quelle description textuelle en vecteur de caractéristiques. Lorsque vous obtenez une description textuelle, vous utiliserez d'abord la palette de couleurs pour générer un vecteur de caractéristiques. Vous pouvez ensuite prendre votre pinceau et utiliser les vecteurs de caractéristiques pour générer une image qui correspond à la description. Vous utiliserez un pinceau plus fin lorsque vous avez besoin de détails et un pinceau plus grossier lorsque vous en avez besoin. Contrairement aux peintres, DALL-E utilise des réseaux de neurones au lieu de pinceaux et de palettes. Ce réseau de neurones utilise une structure appelée Image Transformer Network. Lors de la génération d'images, DALL-E utilise le modèle GPT-3 mentionné précédemment pour générer des intégrations d'images CLIP correspondant à des descriptions textuelles. DALL-E utilise ensuite un algorithme de recherche de faisceaux pour générer une séquence d'images possibles qui correspondent à la description du texte saisi et les transmet à un décodeur pour générer l'image finale. Ce vecteur d'intégration est formé à l'aide d'une technique appelée apprentissage contrastif, qui intègre des images et du texte similaires dans des espaces adjacents afin qu'ils puissent être combinés plus facilement. Notez que DALLE ici n'inclut pas directement CLIP, mais il utilise les intégrations de texte et d'image de CLIP pour entraîner le transformateur et le VAE. Quant à l'algorithme de recherche de faisceau utilisé dans le processus de génération d'images, il s'agit en fait d'un algorithme de recherche glouton qui peut trouver la séquence optimale dans un ensemble de candidats limité. L'idée de base de la recherche de faisceau est que chaque fois que la séquence actuelle est étendue, seuls les k candidats ayant la probabilité la plus élevée sont retenus (k est appelé la largeur du faisceau) et les autres candidats à faible probabilité sont écartés. Cela réduit l’espace de recherche et améliore l’efficacité et la précision. Les étapes spécifiques d'utilisation de la recherche de faisceaux pour générer des images dans DALLE sont les suivantes : Le même tableau, comment dessiner une diffusion stable ? Lorsque nous voulons peindre une œuvre d’art, nous avons généralement besoin d’une bonne composition et de quelques éléments spécifiques à partir desquels la construire. La diffusion stable est une méthode de génération d'images qui divise le processus de génération d'images en deux parties : le processus de diffusion et le processus de reconstruction. Considérez le processus de diffusion comme le mélange d'un tas de pinceaux, de peintures et d'une toile dispersés, créant lentement de plus en plus d'éléments sur la toile. Au cours de ce processus, nous ne savions pas à quoi ressemblerait l’image finale et nous ne pouvions pas non plus déterminer la position finale de chaque élément. Cependant, nous pouvons progressivement ajouter et ajuster ces éléments jusqu’à ce que l’ensemble du tableau soit terminé. Ensuite, la description textuelle saisie est comme une description approximative de l'œuvre que nous voulons dessiner, et un algorithme de recherche de faisceau est utilisé pour effectuer une correspondance fine entre la description textuelle et l'image générée. Ce processus revient à modifier et à ajuster constamment les éléments pour qu'ils correspondent mieux à l'image que nous souhaitons. En fin de compte, l’image résultante correspondra étroitement à la description textuelle, rendant ainsi l’œuvre d’art que nous avons imaginée. Comme le montre la figure 8, le modèle de diffusion est ici un modèle génératif qui apprend les données en ajoutant progressivement du bruit aux données, puis en inversant le processus de restauration des données d'origine. . distribution. la diffusion stable utilise un auto-encodeur variationnel (VAE) pré-entraîné pour coder les images dans des vecteurs latents de basse dimension, et un modèle de diffusion basé sur un transformateur pour générer des images à partir des vecteurs latents. la diffusion stable utilise également un encodeur de texte CLIP gelé pour convertir les signaux de texte en intégrations d'images afin de conditionner le modèle de diffusion. Figure 8. Processus de diffusion stable. La première est la flèche supérieure. Le bruit est ajouté en continu à une image, et finalement, cela devient une image de bruit pur. Ensuite, la flèche inférieure est utilisée pour éliminer progressivement le bruit, puis reconstruire l'image originale. (Source de l'image : De DALL・E à Stable Diffusion : comment fonctionnent les modèles de génération de texte en image ? | Tryolabs) Il convient de noter que le processus de diffusion dans Stable Diffusion est un processus aléatoire, donc l'image générée sera différente à chaque fois, même avec la même description textuelle. Ce caractère aléatoire rend les images générées plus diversifiées et augmente également l'incertitude de l'algorithme. Afin de rendre les images générées plus stables, Stable Diffusion utilise certaines techniques, telles que l'ajout d'un bruit progressivement croissant pendant le processus de diffusion et l'utilisation de plusieurs processus de reconstruction pour améliorer encore la qualité de l'image. La diffusion stable a fait de grands progrès sur la base de DALL-E : C'est pourquoi DALL-E-2 ajoute également le modèle de diffusion à son modèle. Pendant que d'autres princes mènent des réformes en plein essor, l'équipe GPT a également travaillé tranquillement. Comme mentionné au début, GPT-3 avait déjà de fortes capacités lors de sa première sortie, mais sa méthode d'utilisation n'était pas si "non technique", donc les vagues qu'il a provoquées étaient toutes dans le monde technique, qui n'étaient pas très enthousiastes. en premier lieu, et il se dissipe de plus en plus en raison de ses frais élevés. Transformer est très insatisfait. GPT y a pensé et l'a réformé ! Le premier à répondre à l'appel à la réforme et à faire le premier pas a été GPT 3.5 : « Je suis stupide et je ne trouve pas de bonne façon de réformer, alors posons un une base solide d'abord. » Ainsi, GPT3.5 est basé sur GPT-3 et utilise un type de données d'entraînement appelé Text+Code, qui ajoute des données de code de programmation sur la base de données textuelles. En termes simples, un ensemble de données plus important est utilisé. Cela permet au modèle de mieux comprendre et générer du code, augmentant ainsi la diversité et la créativité du modèle. Text+Code sont des données de formation basées sur du texte et du code qui sont collectées et organisées à partir du Web par OpenAI. Il se compose de deux parties : le texte et le code. Le texte est un contenu décrit en langage naturel, tel que des articles, des commentaires, des conversations, etc. Le code est quelque chose d'écrit dans un langage de programmation comme Python, Java, HTML, etc. Les données d'entraînement Texte+Code peuvent permettre au modèle de mieux comprendre et générer du code, améliorant ainsi la diversité et la créativité du modèle. Par exemple, dans les tâches de programmation, le modèle peut générer un code correspondant basé sur des descriptions textuelles, et le code présente une exactitude et une lisibilité élevées. Dans la tâche de génération de contenu, le modèle peut générer le texte correspondant basé sur la description du code, et le texte est très cohérent et intéressant. Les données de formation Text+Code peuvent également permettre au modèle de mieux gérer les données et tâches multilingues, multimodales et multidomaines. Par exemple, dans les tâches de traduction linguistique, le modèle peut effectuer une traduction précise et fluide basée sur la correspondance entre différentes langues. Dans la tâche de génération d'images, le modèle peut générer des images correspondantes sur la base de descriptions de texte ou de code, et les images ont une clarté et une fidélité élevées. La deuxième personne à répondre à l'appel était Instruct GPT, qui a découvert un nouveau problème : "Si nous voulons être intégrés aux humains, nous devons écouter leurs opinions plus efficacement." C'est ainsi qu'est apparue la fameuse nouvelle aide étrangère, qui est la stratégie de formation du RLHF. RLHF est une stratégie de formation basée sur l'apprentissage par renforcement, et son nom complet est Reinforcement Learning from Human Feedback. Son idée principale est de fournir des instructions au modèle pendant le processus de formation et de le récompenser ou de le punir en fonction des résultats du modèle. Cela permet au modèle de mieux suivre les instructions et améliore la contrôlabilité et la crédibilité du modèle. En fait, GPT-3.5 a également du feedback humain. Alors, quels changements ont eu lieu après l'ajout de l'apprentissage par renforcement (apprentissage par renforcement) ? En d’autres termes, moins d’investissement humain est nécessaire, mais cela apporte de plus grands bénéfices au modèle. L r Figure 9. Processus RLHF (source : GPT-4 (openai.com)) comme le montre la figure 9, stratégie de formation RLHF Elle est divisée en deux étapes : la pré-formation et la mise au point. Dans la phase de pré-formation, le modèle utilise le même ensemble de données que GPT-3 pour un apprentissage non supervisé afin d'acquérir les connaissances de base et les règles de la langue. Dans la phase de réglage fin, le modèle utilise des données étiquetées manuellement pour l'apprentissage par renforcement afin d'apprendre à générer des résultats appropriés en fonction des instructions. Les données étiquetées manuellement comprennent deux parties : les instructions et les commentaires. Les instructions sont des tâches décrites en langage naturel, telles que « Écrivez un poème sur le printemps » ou « Racontez-moi une blague sur un chien ». Le feedback est une note numérique, telle que « 1 » pour médiocre ou « 5 » pour excellent. Les commentaires sont donnés par des annotateurs humains sur la base des résultats du modèle et reflètent la qualité et le caractère raisonnable des résultats du modèle. En phase de mise au point, le modèle utilise un algorithme appelé Acteur-Critique pour l'apprentissage par renforcement. L'algorithme Acteur-Critique se compose de deux parties : Acteur et Critique. Un acteur est un générateur qui produit une sortie basée sur des instructions. Critic est un évaluateur qui évalue la valeur de la récompense de sortie en fonction des commentaires. Les acteurs et les critiques collaborent et s'affrontent, mettant constamment à jour leurs paramètres pour augmenter la valeur des récompenses. La stratégie de formation RLHF peut permettre au modèle de mieux suivre les instructions et d'améliorer la contrôlabilité et la crédibilité du modèle. Par exemple, dans les tâches d'écriture, le modèle peut générer des textes de différents styles et thèmes selon les instructions, et les textes ont une cohérence et une logique élevées. Dans les tâches conversationnelles, le modèle peut générer des réponses avec différentes émotions et tons en fonction des instructions, et les réponses sont très pertinentes et polies. Enfin, après la réforme et l'accumulation de ses prédécesseurs, ChatGPT, le fils cadet le plus flexible de la famille GPT, a estimé qu'il était temps de lancer un mode de dialogue basé sur Instruct GPT, plus conforme à l'humain. méthodes de communication, déclenchant directement une énorme révolution dans la société humaine (des centaines de millions d'utilisateurs), et c'est gratuit Après plusieurs années de dormance, la famille GPT est finalement devenue un blockbuster et est devenue le prince le plus favorisé de la famille Transformer. .Il a directement gagné la bataille de succession et est devenu le prince. En même temps, pour ChatGPT, le prince n'est pas tout. ChatGPT a hérité de l'énorme ambition de Transformer : « Une dynastie puissante n'a pas besoin d'autant de princes. unifier " Unifier les princes - l'ère des grands modèles . Maintenant, ChatGPT est déjà basé sur GPT-4. Parce que GPT-4 a peur de la réaction rapide de ses concurrents, la plupart des détails techniques sont en réalité fermés. Cependant, à partir de ses fonctions, l'ambition de la famille GPT d'unifier différents princes a été mise en évidence. En plus du dialogue textuel, GPT-4 a également ajouté des fonctions de cartographie IA. La famille GPT a compris une vérité issue de son expérience latente de ces dernières années, à savoir que les grands modèles sont la justice et souhaite étendre cette vérité à divers domaines. Si vous approfondissez les fondements de cette vérité, c'est peut-être le moyen de former de grands modèles. GPT-3 est actuellement l'un des plus grands modèles de langage. Il compte 175 milliards de paramètres, 100 fois plus que son prédécesseur GPT-2 et 10 fois plus que le précédent plus grand modèle NLP similaire. grand modèle de prédiction ou. Voyons donc d'abord comment l'architecture du modèle et les méthodes de formation de GPT-3 atteignent une telle ampleur et de telles performances : "Les grands modèles sont en effet la tendance actuelle, mais l'échelle ne doit pas être aveuglément poursuivie uniquement pour la compétition. Avant de former de grands modèles, nous devons considérer plus de détails et de défis techniques pour garantir qu'ils peuvent fonctionner de manière stable. , efficacement et produire des résultats utiles. " "Tout d'abord, le choix des hyperparamètres d'entraînement et de l'initialisation du modèle appropriés est essentiel. a un impact significatif sur la vitesse de convergence, la stabilité et les performances du modèle, tandis que l'initialisation du modèle détermine la valeur de poids avant le début de l'entraînement, ce qui affectera la qualité des résultats finaux. L'analyse théorique est soigneusement ajustée pour garantir les meilleures performances du modèle. . « Deuxièmement, afin d'obtenir un débit élevé et d'éviter les goulots d'étranglement, nous devons optimiser divers aspects du processus de formation, tels que la configuration matérielle, la bande passante du réseau, la vitesse de chargement des données, l'architecture du modèle, etc. Optimisation ces aspects peuvent considérablement améliorer la vitesse de traitement et l'efficacité du modèle, par exemple, l'utilisation d'un périphérique de stockage ou d'un format de données plus rapide peut réduire le temps de chargement des données, l'utilisation d'une taille de lot plus grande ou l'accumulation de gradient peut réduire les frais de communication en utilisant un format plus simple ou plus clairsemé ; le modèle peut réduire le temps de calcul, etc. " "Enfin, vous pouvez rencontrer diverses situations d'instabilité et de défaillance lors de la formation de grands modèles, telles que des erreurs numériques, un surapprentissage, des pannes matérielles , problèmes de qualité des données, etc. Pour éviter ou récupérer de ces problèmes, nous devons surveiller de près le comportement et les performances du modèle et utiliser des outils et des techniques de débogage pour identifier et corriger les erreurs ou les défauts. . Mesures et mécanismes de protection, tels que le découpage, la régularisation, la suppression, l'injection de bruit, le filtrage des données, l'amélioration des données, etc., pour améliorer la robustesse et la fiabilité du modèle 🎜 #« À cette époque, les grands modèles sont certes importants, mais. la simple recherche d'échelle ne permet pas au modèle de produire des résultats utiles. Ce n'est que grâce à une formation et une optimisation réfléchies que les grands modèles peuvent réellement réaliser leur potentiel et apporter de meilleurs résultats à l'humanité. #Le prince a raison. Le déclin des princes forts - BERT En fin de compte, un chameau maigre est plus gros qu'un cheval bien que BERT ait été éclipsé. par GPT récemment, mais après tout, c'était autrefois un prince puissant. Sous le développement imparable de GPT, BERT conserve toujours son propre fief. Lorsqu'on parle de modèles de traitement du langage naturel, BERT (Bidirectionnel Encoder Representations from Transformers) était autrefois un modèle très populaire car il fonctionnait très bien sur de nombreuses tâches. Lors de sa première sortie, il était presque imbattable, encore plus réussi que GPT. En effet, BERT est conçu avec des objectifs et des avantages différents de ceux de GPT. Cependant, au fil du temps, l'émergence de la série de modèles GPT a permis à GPT-3 de surpasser BERT sur plusieurs tâches. Une raison possible est que les modèles de la série GPT sont conçus pour se concentrer davantage sur les tâches génératives, telles que la génération de texte et les systèmes de dialogue, tandis que BERT se concentre davantage sur les tâches de classification et de questions et réponses. De plus, les modèles de la série GPT utilisent des paramètres plus grands et plus de données pour l'entraînement, ce qui leur permet également d'obtenir de meilleures performances sur un plus large éventail de tâches. Bien sûr, BERT reste un modèle très utile, notamment pour certaines tâches qui nécessitent de classer du texte ou de répondre à des questions. La série de modèles GPT est plus adaptée aux tâches génératives, telles que la génération de texte et les systèmes de dialogue. Dans l’ensemble, les deux modèles ont leurs avantages et leurs limites uniques, et nous devons choisir le modèle approprié en fonction des besoins de la tâche spécifique. La bataille pour la prostituée - le menaçant Segment Anything Model (SAM) [20] Comme je l'ai déjà dit, je travaille dur tranquillement Dans Big Brother GPT À cette époque, le travailleur modèle Transformer a fait beaucoup de vagues dans le domaine CV (ViT) et dans le domaine multimodal (CLIP), mais à la fin, ils sont tous devenus des bébés expérimentés. père Transformateur au prince préféré GPT, et a finalement réussi La soi-disant unification de GPT-4. "Cependant, il est trop puissant dans le domaine de la PNL. champ de bataille." Donc, SAM est né. Sur le site officiel, ils le décrivent ainsi : Segment Anything Model (SAM) : un nouveau modèle d'IA de Meta AI qui peut "découper" n'importe quel objet, dans n'importe quelle image, d'un simple clic En termes simples, nous pouvons considérer SAM comme un « maître d'édition d'images » efficace qui peut identifier et segmenter avec précision divers objets dans les images via diverses invites de saisie. Par exemple, lorsque nous cliquons sur un point de l'image avec la souris, SAM découpera automatiquement l'objet où se trouve le point comme un peintre expérimenté ; lorsque nous saisissons le mot « chat », SAM se comportera comme un détective intelligent ; , nous trouvons et découpons automatiquement tous les chats dans l'image ; lorsque nous donnons à SAM un cadre de détection de cible, SAM découpera avec précision les objets dans le cadre comme un chirurgien expérimenté. La capacité de généralisation à échantillon zéro de SAM en fait un véritable « maître d’édition universel ». Cela signifie qu'il s'agit d'objets courants comme des voitures, des arbres et des bâtiments, ou d'objets rares comme des dinosaures, des extraterrestres et des baguettes magiques, SAM peut les identifier et les couper sans effort. Cette puissante capacité découle de sa conception de modèle avancée et de son vaste ensemble de données. J'ai sélectionné quatre exemples de scènes très complexes dans l'article original (Figure 10) pour illustrer ce que SAM peut faire. Figure 10. Exemple d'effet SAM. Vous pouvez éditer et extraire chaque couleur de l'image, ce qui équivaut à un maître PS (maître d'édition d'image) efficace. Pour faire simple, lorsque d'autres venaient nous voir avec enthousiasme pour nous faire des demandes, nous devions toujours demander, impuissants, attendez une minute, quel type de données pouvez-vous fournir ? Pas besoin maintenant, Au moins dans le domaine du CV, c'est plus proche de la compréhension de l'IA par les non-techniciens. Afin de réaliser les puissantes capacités mentionnées ci-dessus, jetons un coup d'œil à la façon dont ViT et CLIP conspirent bruyamment : ViT : « Bien que j'aie principalement effectué des tâches de classification d'images auparavant, mon architecture est également applicable à la segmentation des images. . Parce que j'utilise l'architecture Transformer pour décomposer l'image en une série de blocs puis les traiter en parallèle, si j'intègre mes avantages, SAM peut hériter de mes avantages de traitement parallèle et d'attention globale pour obtenir une segmentation d'image efficace . CLIP : "D'accord, alors j'investirai dans ma méthode de formation commune. Sur la base de cette idée, SAM peut également gérer différents types d'invites de saisie (invites de questions et invites visuelles)." est formé (Figure 11), ViT est utilisé comme encodeur d'image et CLIP est utilisé pour encoder les informations d'invite. L'idée est bonne, mais comment la faire - bien sûr, apprenez de Big Brother ! « Nous souhaitons utiliser des modèles de langage pré-entraînés pour les tâches de segmentation d'images, tout comme l'utilisation d'invites de texte (invites) pour permettre aux modèles de langage de générer ou de prédire du texte. Avec CLIP, nos invites peuvent être très riches, ce qui peut être le cas. des points, des boîtes, des masques et du texte, qui indiquent au modèle de langage ce qu'il faut segmenter dans l'image. Notre objectif est d'obtenir une représentation efficace compte tenu de toute indication (résultat de la segmentation) Un masque valide signifie que même si l'invite. est ambigu (par exemple, une chemise ou une personne), la sortie doit être un masque raisonnable pour l'un des objets. C'est comme le grand frère GPT (modèle de langage). Les invites peuvent également donner une réponse cohérente. tâche car elle nous permet de pré-entraîner le modèle de langage de manière naturelle et d'obtenir un transfert zéro vers différentes tâches de segmentation via des invites
Quant à. les résultats, ses puissantes capacités mentionnées précédemment ont confirmé la faisabilité de cette idée. Cependant, il faut mentionner que même si SAM n’a plus besoin de recycler le modèle, il présente encore certaines limites, comme lors du premier lancement de chatGPT. Dans la section Limitation de l'article, la page de l'auteur souligne clairement certaines limites et lacunes de SAM, telles que des défauts dans les détails, la connectivité, les limites, etc., ainsi que dans des tâches telles que la segmentation interactive, le temps réel, les invites textuelles. , la sémantique et la segmentation panoramique, tout en reconnaissant également les avantages de certains outils spécifiques à un domaine. Par exemple, j'ai fait deux tests simples dans la démo : l'un est la détection des lésions dans le domaine des images médicales, car les lésions sont trop petites et difficiles à détecter ; le second est la coupe en portrait, ça a l'air bien, mais les cheveux l'est. ce n'est toujours pas très naturel, et on peut encore voir les marques de coupe si on regarde bien. Bien sûr, c'est un bon début après tout. Ces deux gars viennent tout juste de démarrer leur entreprise et travaillent toujours dur. Quel type de vélo veulent-ils ? Alors attendons de voir quelle sera l’issue de cette bataille ! La grande famille des Transformer n'est évidemment pas quelque chose que cet article peut expliquer. En ce qui concerne les résultats basés sur Transformer, nous pouvons voir l'innovation continue dans ce domaine : Vision Transformer (ViT) démontre le rôle de. Transformateur en Application réussie dans le domaine de la vision par ordinateur, il peut traiter directement les données des pixels de l'image sans avoir besoin d'une ingénierie manuelle des fonctionnalités. DALL-E et CLIP ont appliqué Transformer aux tâches de génération et de classification d'images, démontrant ainsi ses performances supérieures en matière de compréhension sémantique visuelle. Stable Diffusion propose un processus de diffusion stable capable de modéliser des distributions de probabilité, qui peuvent être appliquées à des tâches telles que la segmentation et la génération d'images. Ces résultats révèlent ensemble les vastes perspectives d'application du modèle Transformer, et nous devons admettre qu'un jour dans le futur, « l'attention est tout ce dont vous avez besoin ». En bref, ces résultats nous permettent de constater la vitalité de l'innovation continue dans le domaine de l'intelligence artificielle. Qu'il s'agisse de GPT ou BERT, ou encore Vision Transformer, DALL-E, CLIP, Stable diffusion, etc., ces réalisations représentent les dernières avancées dans le domaine de l'intelligence artificielle. Maintenant que le grand examen (ChatGPT) a lieu, la situation actuelle est probablement la suivante : Les meilleurs étudiants ont bien suivi les cours ce semestre. Lorsque vous ouvrez le livre, vous pouvez vous rappeler la voix de. » le professeur lorsqu'il a parlé de ce point de connaissance dans cette classe. En souriant, j'ai même commencé à planifier mon plan d'études pour le semestre suivant. Les maîtres pseudo-académiques viennent en classe tous les jours, occupent le premier rang, et ouvrent les manuels mais sont confus ils commencent à "un livre par jour, un semestre par semaine" avec les mauvais élèves. La seule différence. c'est que les manuels ne sont pas tout neufs, j'ai encore un petit souvenir du contenu des manuels, qui n'est pas considéré comme un apprentissage complet de nouvelles connaissances. Quant aux vrais salopards... "La connaissance vient, la connaissance vient, la connaissance vient de toutes les directions" En fait, je pense que qu'ils soient de faux universitaires ou des salauds, ils devraient rester calmez-vous avant l'examen final, jetez un œil à ce qui a été enseigné ce semestre, empruntez des notes aux meilleurs étudiants, ou encore choisissez de reporter l'examen. Pour les universitaires de haut niveau, la vitesse vient naturellement. Pour les faux universitaires et les salauds, la vitesse est nocive. Dans la concurrence dans le domaine de l'intelligence artificielle, l'innovation continue est cruciale. Par conséquent, en tant que chercheurs, nous devons prêter une attention particulière aux derniers développements dans ce domaine et maintenir un esprit humble et ouvert pour promouvoir les progrès continus dans le domaine de l’intelligence artificielle.
Première apparition - CLIP [13]
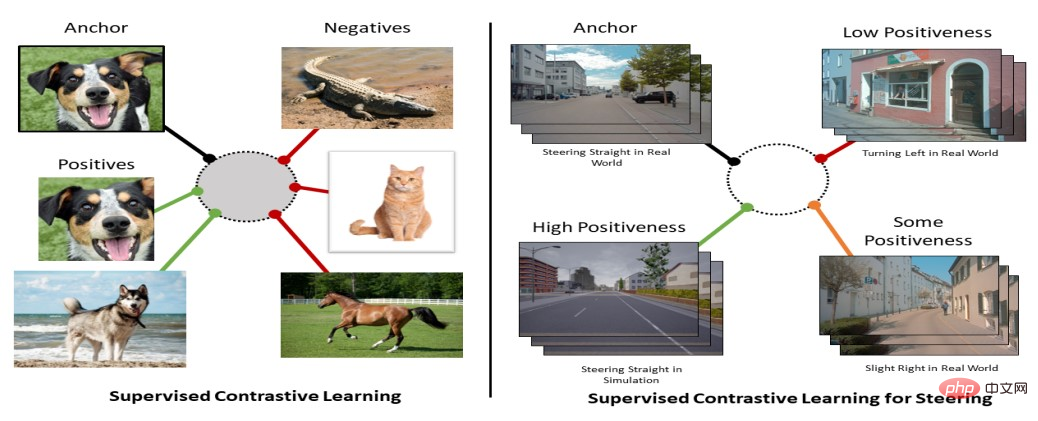
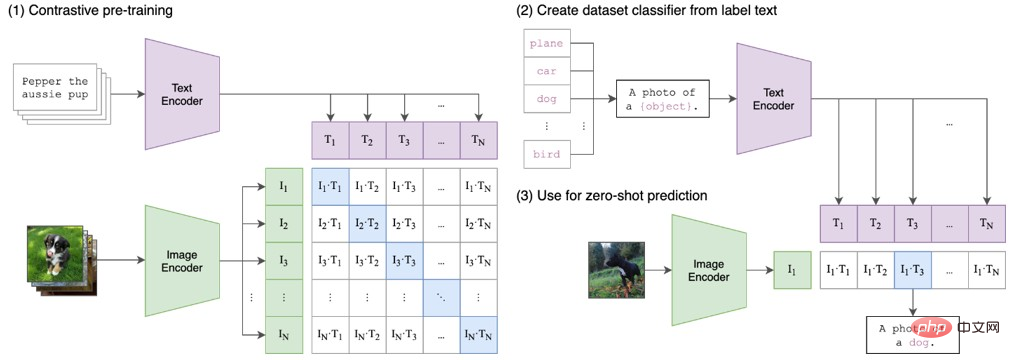
DALL-E & Stable Diffusion

La puissance latente - GPT3.5 [18]
& Instruire GPT [19]
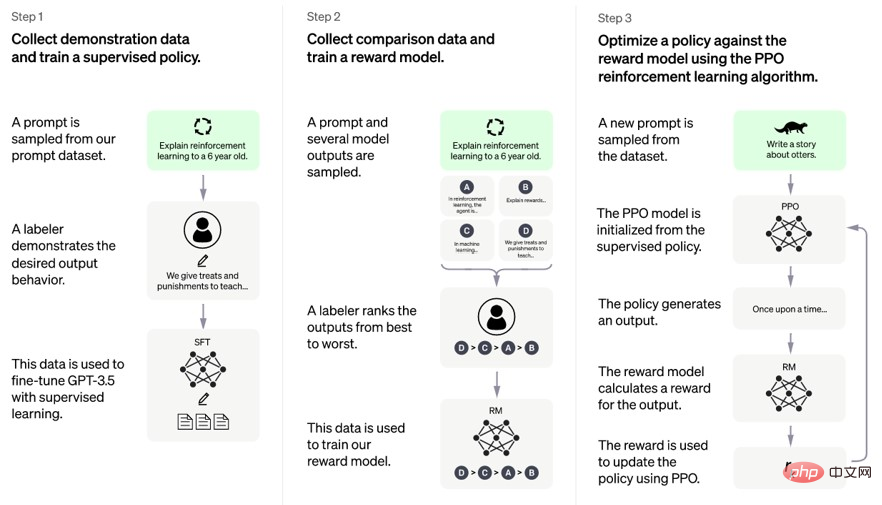
Voyant cela, ChatGPT fronça légèrement les sourcils et parut un peu insatisfait du plan de GPT-3 : "Ce n'est pas suffisant." 🎜#BERT L'objectif de BERT est de pousser les capacités de modélisation de contexte à un tout autre niveau pour mieux prendre en charge les tâches en aval telles que la classification de texte et la réponse aux questions. Il atteint cet objectif en entraînant un encodeur Transformer bidirectionnel. Cet encodeur est capable de prendre en compte à la fois les côtés gauche et droit de la séquence d'entrée, ce qui entraîne une meilleure représentation du contexte, afin que BERT puisse mieux modéliser le contexte, améliorant ainsi les performances du modèle dans les tâches en aval.
ViT et CLIP, qui ont du sang transformateur qui coule dans leurs os, ne sont bien sûr pas contents : « Le prince général Xiang Ning a-t-il le courage ? frère aîné apprend de nous ? Nous pouvons aussi apprendre de lui."

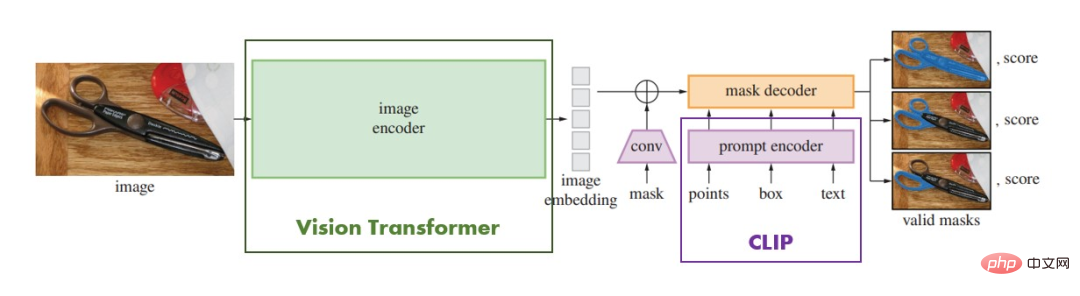 Figure 11. Architecture du modèle SAM
Figure 11. Architecture du modèle SAM Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI