
Maison >Java >javaDidacticiel >Quelle est la raison pour laquelle Java ne peut pas lire les fichiers binaires non textuels à l'aide de flux de caractères
Quelle est la raison pour laquelle Java ne peut pas lire les fichiers binaires non textuels à l'aide de flux de caractères

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-30 15:34:14884parcourir
Lire des fichiers
Quand j'ai appris pour la première fois la partie flux IO de Java, le livre disait que seuls les flux d'octets peuvent être utilisés pour lire des fichiers binaires non textuels tels que des images et des vidéos, et que les flux de caractères ne peuvent pas être utilisés, sinon les fichiers seront être endommagé. Je m'en suis donc toujours souvenu, mais la raison pour laquelle il ne peut pas être utilisé a toujours été un doute pour moi. Aujourd'hui, j'ai repensé à ce problème, alors autant le résoudre d'un seul coup.
Regardons d'abord un exemple de code sur la copie d'images : Remarque : Mon ordinateur a le chemin D:/DB. Si vous n'avez pas le dossier DB, vous devez en créer un.
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ReadImage {
public static void main(String[] args) throws IOException {
String imgPath = "D:/DB/husky/kkk.jpeg";
String byteImgCopyPath = "D:/DB/husky/byteCopykkk.jpeg";
String charImgCopyPath = "D:/DB/husky/charCopykkk.jpeg";
Path srcPath = Paths.get(imgPath);
Path desPath2 = Paths.get(byteImgCopyPath);
Path desPath3 = Paths.get(charImgCopyPath);
byteRead(srcPath.toFile(), desPath2.toFile());
System.out.println("字节复制执行成功!");
characterRead(srcPath.toFile(), desPath3.toFile());
System.out.println("字符复制执行成功!");
}
static void byteRead(File src, File des) throws IOException {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des))) {
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
}
}
static void characterRead(File src, File des) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new FileWriter(des))) {
int hasRead = 0;
char[] c = new char[1024];
while ((hasRead = reader.read(c)) != -1) {
writer.write(c, 0, hasRead);
}
}
}
}Résultat d'exécution : On peut voir que les fichiers binaires tels que les images ne peuvent pas être lus à l'aide de flux de caractères et que des flux d'octets doivent être utilisés.

Modifications de la taille de l'image : On peut voir que la taille de l'image change après l'utilisation du flux de caractères, mais pas lors de l'utilisation du flux d'octets.

Pourquoi ça ?
A travers l'exemple ci-dessus, nous pouvons voir qu'il est en effet impossible de copier des fichiers à l'aide de flux de caractères, et après avoir utilisé des flux de caractères pour copier des fichiers, la taille des fichiers changera également, ce qui conduit au titre dont nous allons discuter aujourd'hui.
Réfléchissons-y d'abord, pourquoi du texte peut-il être affiché lorsqu'un fichier texte est ouvert ? Nous savons tous que les fichiers traités par les ordinateurs, qu'ils soient texte ou non, sont finalement stockés sous forme binaire à l'intérieur de l'ordinateur.
Utilisez le mode hexadécimal de l'éditeur de texte pour ouvrir un fichier texte :
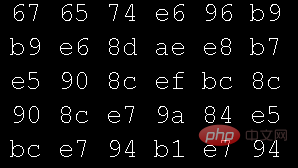
Utilisez le mode hexadécimal de l'éditeur pour ouvrir le fichier image utilisé par le programme ci-dessus :
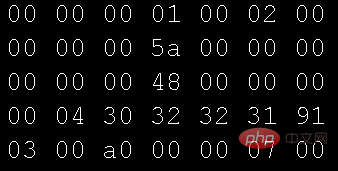
Comparez les deux images Il ne devrait y avoir aucune différence dans les données dans le texte, mais pourquoi les données textuelles peuvent-elles être affichées ? Il s'agit d'une question très fondamentale. Les cours de base dans les universités couvrent tous cet aspect - Tableau de codage des caractères. J'ai d'abord appris le langage C, et la première table de codage avec laquelle j'ai été en contact était ASCII (American Standard Code for Information Interchange). Plus tard, lorsque j'ai appris Java, je suis entré en contact avec Unicode (Universal Code). son origine. Le plus couramment utilisé à l'heure actuelle. Il s'agit de l'UTF-8, un codage de caractères de longueur variable pour Unicode.)
Remarque : L'utilisation d'UTF-8 est également divisée en deux formes : BOM (Byte Order Mark). ) et sans , et une utilisation mixte entraînera des erreurs. Si vous êtes intéressé, vous pouvez en savoir plus.

Le rôle de la table d'encodage des caractères se reflète dans l'encodage Citation de l'encyclopédie :
Le texte, les images et autres informations vues sur le moniteur ne sont en fait pas ce que nous voyons sur l'ordinateur, même si. vous savez tout Les informations sont stockées sur le disque dur, et si vous le démontez, vous ne pouvez rien voir à l'intérieur, juste quelques plateaux. Supposons que vous utilisiez un microscope pour agrandir le disque et que vous voyez que la surface du disque est inégale. Les endroits convexes sont magnétisés et les endroits concaves ne sont pas magnétisés. Les endroits convexes représentent le chiffre 1 et les endroits concaves représentent. le chiffre 0. Le disque dur ne peut utiliser que 0 et 1 pour représenter tous les textes, images et autres informations. Alors, comment la lettre « A » est-elle stockée sur le disque dur ? Peut-être que l'ordinateur de Xiao Zhang stocke la lettre « A » sous la forme 1100001, tandis que l'ordinateur de Xiao Wang stocke la lettre « A » sous la forme 11000010. De cette façon, les deux parties se comprendront mal lorsqu'elles échangeront des informations. Par exemple, Xiao Zhang a envoyé 1100001 à Xiao Wang. Xiao Wang ne pensait pas que 1100001 était la lettre « A », mais pensait probablement que c'était la lettre « X ». Ainsi, lorsque Xiao Wang a utilisé le Bloc-notes pour accéder à 1100001 stocké sur le disque dur. , un message d'erreur est apparu à l'écran. Ce qui est affiché est la lettre "X". En d’autres termes, Xiao Zhang et Xiao Wang ont utilisé des tables de codage différentes.
Ainsi, la table de codage des caractères est un mappage un à un entre les nombres binaires et les caractères, par exemple, 65 (nombre) représente A, donc le code suivant affichera A à l'écran.
char c = 65; System.out.println(c);
Utilisons une boucle pour le tester :
char c = 0;
for (int i = 9999; i < 10009; i++) {
c = (char) i;
System.out.print(c+" ");
}Résultat du test : (Bien sûr, cela dépend de votre table d'encodage de caractères actuelle. Si vous utilisez ASCII, ce sera probablement intéressant.)
这样就解释了前面那个问题(为什么文本文件打开可以显示文字?),我们之所以可以看见文本文件的字符是因为计算机按照我们文件的编码(ASCII、UTF-8或者GBK等),从字符编码表中找出来对应的字符。 所以,当我们使用记事本打开二进制文件会看到乱码,这就是原因。文件的复制过程也是复制的二进制数据,而不是真实的文字。
因此可以这样理解文件复制的过程:
字符流:二进制数据 --编码-> 字符编码表 --解码-> 二进制数据
字节流:二进制数据 —> 二进制数据
所以问题就是出现在编码和解码的过程中,既然是字符的编码表,那它就是包含所有的字符,但是字符的数量是有限的,这就意味着它不能表示一些超过编码表的字符,因为根本不存在表中。所以,JVM 会使用一些字符进行替换,基本上都是乱码(所以大小会发生变化),而且如果有一个数据恰好是-1,那么读取就会中断,引起数据丢失。
例如如下代码使用字符流读取就会错误:
String filename = "D:/DB/fos.txt"; //文件名
byte[] b = new byte[] {-1, -1}; //两个字节,127的二进制就是 1111 1111
//数据写入文件
try (FileOutputStream fos = new FileOutputStream(filename)) {
fos.write(b, 0, b.length); //将两个127连续写入,就是 1111 1111 1111 1111
}
File file = new File(filename);
//输出文件的大小
System.out.println("file length: " + file.length());
char[] c = new char[2];
//使用字符流读取文件
try (FileReader reader = new FileReader(filename)) {
int count = reader.read(c); //Java使用Unicode编码,读取的是从 0-65535 之间的数字。
System.out.println("以文本形式输出:" + new String(c, 0, count)+" "+count);
for (char d : c) {
System.out.println("字符为:" + d);
}
}
System.out.println("表示字符:" + c[0]);
//再写入文件
try (FileWriter writer = new FileWriter(filename)) {
writer.write(c, 0, 2);
}
File f = new File(filename);
System.out.println("file length: " + f.length());结果:

说明: 我将两个1字节的-1写入(字节流)了文本文件(注意是字节:-1,不是字符:-1),然后再读取(字符流),再写入(字符流)就已经出现了问题。读取出的字符显示了一个奇怪的符号,而且它的值为:65533,这个值如果用字节表示的话,一个字节是不够的,所以文件的大小就会变化。在非文本的二进制数据中,出现这种情况都是正常的,因为本来就不是按照字符编码的。
因为字符都是正数,而非字符编码的话,字节数可能是负数(很可能),但是负数在字符看来就是正数,这也是为什么-1,被读成 65533的原因。可以看出来,读取就已经错误了。
注意: 这里的重点是对于使用字符流读取非文本文件,在读取-写入的过程中的问题。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!