
Maison >Périphériques technologiques >IA >Tant que le modèle et les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente !
Tant que le modèle et les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente !

- 王林avant
- 2023-04-29 15:25:061543parcourir
Il n'y a aucune différence de mécanisme mathématique entre le modèle d'IA et le cerveau humain.
Tant que le modèle est suffisamment grand et que les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente ! L’émergence du
chatGPT l’a effectivement prouvé.
1. Les détails sous-jacents de l'IA et du cerveau humain sont basés sur des instructions if else
opérations logiques, qui sont les opérations de base qui produisent l'intelligence.
La logique de base du langage de programmation est if else, qui divise le code en deux branches basées sur des expressions conditionnelles.
Sur cette base, les programmeurs peuvent écrire des codes très complexes et mettre en œuvre diverses logiques métier.
La logique de base du cerveau humain est aussi if else. Les deux mots if else viennent de l'anglais, et le vocabulaire chinois correspondant est if...else...
#🎜🎜 #cerveau humain C'est le même raisonnement logique lorsque l'on réfléchit à des problèmes. Ce n'est pas différent des ordinateurs à cet égard.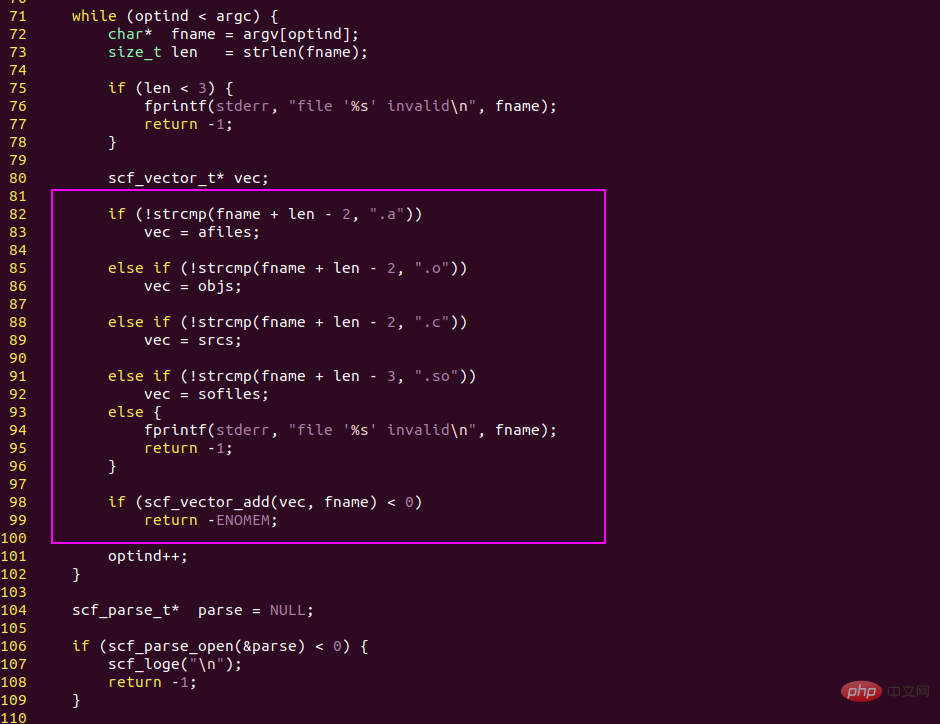
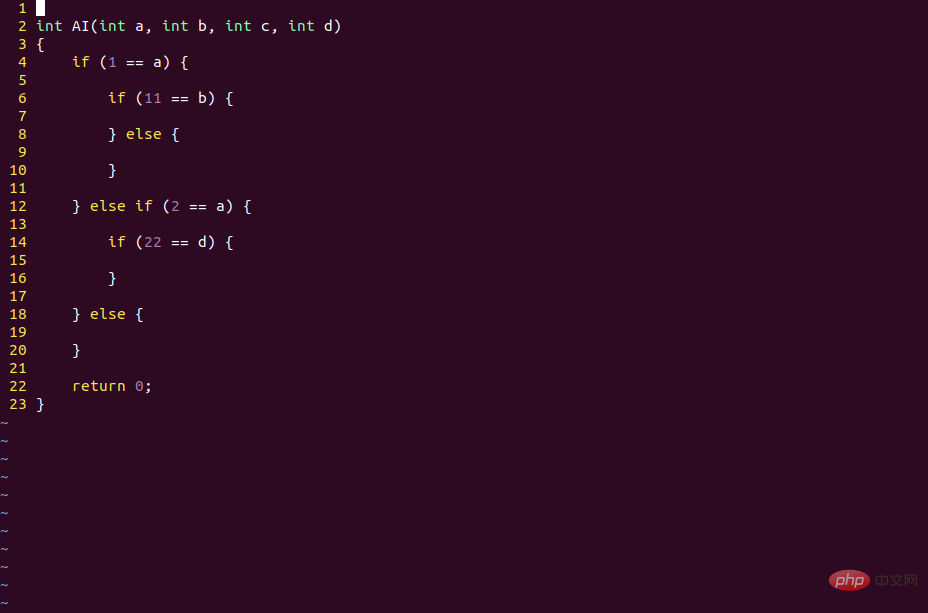
Mais ce n'est pas le cas des réseaux de neurones. Bien que son code soit écrit, il suffit de mettre à jour les données de poids pour changer le contexte logique du modèle.
En fait, tant que de nouveaux échantillons sont saisis en permanence, le modèle d'IA peut mettre à jour en permanence les données de poids à l'aide de l'algorithme BP (algorithme de descente de gradient) pour s'adapter aux nouveaux scénarios commerciaux.
La mise à jour du modèle d'IA ne nécessite pas de modifier le code, mais nécessite uniquement de modifier les données, de sorte que le même modèle CNN peut reconnaître différents objets s'il est entraîné avec différents échantillons.
Dans ce processus, le code du framework Tensorflow et la structure du réseau du modèle d'IA restent inchangés. Ce qui change, ce sont les données de poids de chaque nœud.
Théoriquement, tant qu'un modèle d'IA peut explorer les données à travers le réseau, il peut devenir plus intelligent.
Est-ce fondamentalement différent des gens qui regardent des choses via un navigateur (devenant ainsi plus intelligents) ? Il semble que non.
4. Tant que le modèle est suffisamment grand et que les échantillons sont suffisamment grands, ChatGPT peut peut-être vraiment défier le cerveau humain
Le cerveau humain possède 15 milliards de neurones, et les yeux et les oreilles humains lui fournissent de nouvelles données à chaque instant. Les modèles d’IA peuvent certainement le faire aussi.
Peut-être que par rapport à l'IA, l'avantage des humains est que la « chaîne industrielle » est plus courte
La naissance d'un bébé ne nécessite que ses parents, mais la naissance d'un modèle d'IA n'est évidemment pas quelque chose qu'un ou deux programmeurs peuvent faire .
La seule fabrication de GPU nécessite plus de dizaines de milliers de personnes.
Les programmes Cuda sur GPU ne sont pas difficiles à écrire, mais la chaîne industrielle de fabrication des GPU est trop longue, bien inférieure à la naissance et à la croissance des êtres humains.
C’est peut-être le véritable inconvénient de l’IA par rapport aux humains.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI